Recognition: unknown
EA-WM: Event-Aware Generative World Model with Structured Kinematic-to-Visual Action Fields
Pith reviewed 2026-05-08 13:46 UTC · model grok-4.3
The pith
EA-WM projects kinematic actions directly into camera views as structured fields to guide video generation and preserve robot geometry plus interaction details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
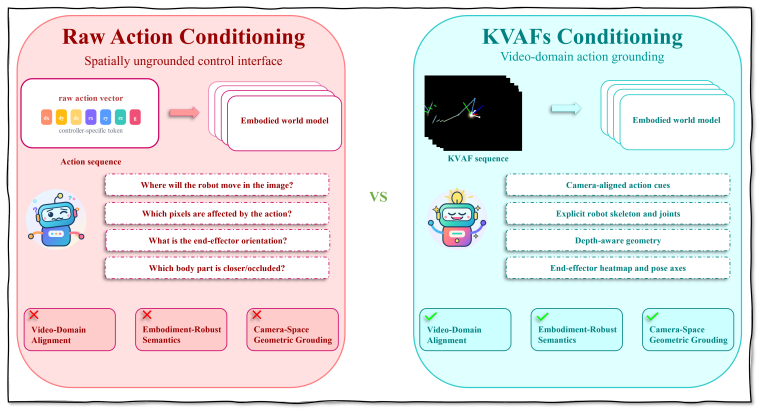
Rather than injecting joint or end-effector actions as abstract, low-dimensional tokens, EA-WM projects actions and kinematic states directly into the target camera view as Structured Kinematic-to-Visual Action Fields. To fully exploit this geometrically grounded representation, the model introduces event-aware bidirectional fusion blocks that modulate cross-branch attention, capturing object state changes and interaction dynamics. Evaluated on the comprehensive WorldArena benchmark, EA-WM achieves state-of-the-art performance, outperforming existing baselines by a significant margin.
What carries the argument
Structured Kinematic-to-Visual Action Fields, which embed kinematic actions and states as spatially aligned visual maps in the camera view to supply geometric conditioning, together with event-aware bidirectional fusion blocks that adjust attention between visual and action branches.
If this is right
- Future videos preserve precise robot spatial geometry more reliably than token-conditioned models.
- Fine-grained robot-object interaction dynamics are captured with fewer distortions across time steps.
- The model reaches state-of-the-art scores on the WorldArena benchmark.
- Kinematic control and visual perception are linked more tightly inside the generative loop.
- Rollouts become usable for longer-horizon planning because geometry errors accumulate more slowly.
Where Pith is reading between the lines
- The same projection technique could be tested on non-robot domains like autonomous driving where camera-aligned control signals matter.
- Extending the fields to multi-camera setups might reduce viewpoint-specific errors without retraining the full diffusion backbone.
- Policy learning that queries the model for imagined outcomes could show faster convergence if the geometry is truly more accurate.
Load-bearing premise
Projecting kinematic actions and states straight into the camera view as visual fields, then fusing them with event-aware blocks, will keep precise robot positions and object contact details intact better than treating actions as abstract tokens.
What would settle it
Running EA-WM and token-based baselines side-by-side on WorldArena rollouts and measuring pixel-level or pose-level error in robot configuration and object contacts; if the new model shows no clear reduction in those errors, the advantage claim is falsified.
Figures









read the original abstract
Pretrained video diffusion models provide powerful spatiotemporal generative priors, making them a natural foundation for robotic world models. While recent world-action models jointly optimize future videos and actions, they predominantly treat video generation as an auxiliary representation for policy learning. Consequently, they insufficiently explore the inverse problem: leveraging action signals to guide video synthesis, thereby often failing to preserve precise robot spatial geometry and fine-grained robot-object interaction dynamics in the generated rollouts. To bridge this gap, we present EA-WM, an Event-Aware Generative World Model that effectively closes the loop between kinematic control and visual perception. Rather than injecting joint or end-effector actions as abstract, low-dimensional tokens, EA-WM projects actions and kinematic states directly into the target camera view as Structured Kinematic-to-Visual Action Fields. To fully exploit this geometrically grounded representation, we introduce event-aware bidirectional fusion blocks that modulate cross-branch attention, capturing object state changes and interaction dynamics. Evaluated on the comprehensive WorldArena benchmark, EA-WM achieves state-of-the-art performance, outperforming existing baselines by a significant margin.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EA-WM, an Event-Aware Generative World Model for robotics that projects kinematic actions and states directly into the target camera view as Structured Kinematic-to-Visual Action Fields (instead of abstract tokens) and uses event-aware bidirectional fusion blocks to modulate cross-branch attention for capturing interaction dynamics. It claims this yields state-of-the-art performance on the WorldArena benchmark, outperforming baselines by a significant margin in preserving robot spatial geometry and fine-grained dynamics.
Significance. If the empirical results hold under scrutiny, the work would be significant for robotic world models by offering a geometrically grounded alternative to token-based action conditioning in pretrained video diffusion models. This could improve rollout fidelity for planning and control, addressing a noted limitation in current approaches.
major comments (2)
- [Method (projection and fusion)] Method section on Structured Kinematic-to-Visual Action Fields: the central claim that direct projection into camera-view feature maps preserves precise 3D pose and contact information better than token conditioning lacks any quantitative check (e.g., reprojection error, 3D keypoint consistency, or invertibility analysis under occlusion/fast motion). This is load-bearing for the superiority argument over token-based methods.
- [Experiments] Experiments section: the abstract asserts SOTA results with a significant margin on WorldArena, yet no specific metrics, baseline comparisons, ablation studies on the fusion blocks, or implementation details are referenced to allow verification of the performance gains.
minor comments (1)
- [Introduction] The term 'event-aware' in the fusion blocks should be defined more precisely in the introduction or method, including how events are detected or triggered from the kinematic states.
Simulated Author's Rebuttal
We thank the referee for the careful review and valuable comments. We address each major comment below and indicate the revisions we will make to improve the manuscript.
read point-by-point responses
-
Referee: [Method (projection and fusion)] Method section on Structured Kinematic-to-Visual Action Fields: the central claim that direct projection into camera-view feature maps preserves precise 3D pose and contact information better than token conditioning lacks any quantitative check (e.g., reprojection error, 3D keypoint consistency, or invertibility analysis under occlusion/fast motion). This is load-bearing for the superiority argument over token-based methods.
Authors: We agree that quantitative validation of the geometric fidelity of the Structured Kinematic-to-Visual Action Fields would strengthen the central claim. The current manuscript supports the approach primarily through qualitative visualizations of preserved robot geometry and improved interaction dynamics, plus downstream task metrics. We will add a dedicated analysis subsection that reports reprojection error for projected 3D keypoints, 3D consistency scores under occlusion and fast motion, and direct comparisons against token-based conditioning baselines. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts SOTA results with a significant margin on WorldArena, yet no specific metrics, baseline comparisons, ablation studies on the fusion blocks, or implementation details are referenced to allow verification of the performance gains.
Authors: The experiments section and appendix of the manuscript contain the requested elements: tables with concrete metrics (e.g., PSNR, SSIM, LPIPS, and task success rates), comparisons against multiple baselines, ablations isolating the event-aware bidirectional fusion blocks, and implementation details. However, we acknowledge that the abstract could better guide readers to these results. We will revise the abstract to include key quantitative highlights and add explicit cross-references to Section 4 and the appendix. revision: partial
Circularity Check
No significant circularity in the architectural proposal
full rationale
The paper describes an independent architectural design: projecting kinematic actions and states into camera-view Structured Kinematic-to-Visual Action Fields, combined with event-aware bidirectional fusion blocks. No equations, derivations, or self-citations are shown that reduce the claimed SOTA performance or geometric preservation to a fitted quantity defined by the same model, a self-referential prediction, or a load-bearing self-citation chain. The WorldArena benchmark evaluation is presented as external empirical validation rather than a constructed result. This matches the provided reader's assessment of an independent proposal with no reduction to inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- Diffusion model and fusion block parameters
- Action-to-visual projection parameters
axioms (2)
- domain assumption Pretrained video diffusion models provide powerful spatiotemporal generative priors
- domain assumption Visual projection of actions preserves geometry and dynamics better than abstract tokens
invented entities (2)
-
Structured Kinematic-to-Visual Action Fields
no independent evidence
-
event-aware bidirectional fusion blocks
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review arXiv 2025
-
[2]
Lumiere: A space-time diffusion model for video generation
Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Guanghui Liu, Amit Raj, Yuanzhen Li, Michael Rubinstein, Tomer Michaeli, Oliver Wang, Deqing Sun, Tali Dekel, and Inbar Mosseri. Lumiere: A space-time diffusion model for video generation.arXiv preprint arXiv:2401.12945, 2024
-
[3]
Motus: A Unified Latent Action World Model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, Hongyan Zhao, Hanyu Liu, Zhizhong Su, Lei Ma, Hang Su, and Jun Zhu. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review arXiv 2023
-
[5]
Wan-s2v: Audio-driven cinematic video generation.arXiv preprint arXiv:2508.18621, 2025
Xin Gao, Li Hu, Siqi Hu, Mingyang Huang, Chaonan Ji, Dechao Meng, Jinwei Qi, Penchong Qiao, Zhen Shen, Yafei Song, Ke Sun, Linrui Tian, Guangyuan Wang, Qi Wang, Zhongjian Wang, Jiayu Xiao, Sheng Xu, Bang Zhang, Peng Zhang, Xindi Zhang, Zhe Zhang, Jingren Zhou, and Lian Zhuo. Wan-S2V: Audio-driven cinematic video generation.arXiv preprint arXiv:2508.18621, 2025
-
[6]
Joel Jang, Seonghyeon Ye, Zongyu Lin, Jiannan Xiang, Johan Bjorck, Yu Fang, Fengyuan Hu, Spencer Huang, Kaushil Kundalia, Yen-Chen Lin, et al. Dreamgen: Unlocking generalization in robot learning through video world models.arXiv preprint arXiv:2505.12705, 2025
-
[7]
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, and Jinwei Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163, 2026
work page internal anchor Pith review arXiv 2026
-
[8]
Multi-View Video Diffusion Policy: A 3D Spatio-Temporal-Aware Video Action Model
Peiyan Li, Yixiang Chen, Yuan Xu, Jiabing Yang, Xiangnan Wu, Jun Guo, Nan Sun, Long Qian, Xinghang Li, Xin Xiao, Jing Liu, Nianfeng Liu, Tao Kong, Yan Huang, Liang Wang, and Tieniu Tan. Multi-view video diffusion policy: A 3d spatio-temporal-aware video action model.arXiv preprint arXiv:2604.03181, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
Worldeval: World model as real-world robot policies evaluator,
Yaxuan Li, Yichen Zhu, Junjie Wen, Chaomin Shen, and Yi Xu. Worldeval: World model as real-world robot policies evaluator.arXiv preprint arXiv:2505.19017, 2025
-
[11]
Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
Junbang Liang, Pavel Tokmakov, Ruoshi Liu, Sruthi Sudhakar, Paarth Shah, Rares Ambrus, and Carl V ondrick. Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
-
[12]
Video generation models as world simulators
OpenAI. Video generation models as world simulators. https://openai.com/index/ video-generation-models-as-world-simulators/, 2024. Technical report/blog post
2024
-
[13]
Jonas Pai, Liam Achenbach, Victoriano Montesinos, Benedek Forrai, Oier Mees, and Elvis Nava. mimic-video: Video-action models for generalizable robot control beyond vlas.arXiv preprint arXiv:2512.15692, 2025
-
[14]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, and Xuelong Li. SpatialVLA: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review arXiv 2025
-
[15]
Worldgym: World model as an environment for policy evaluation, 2025
Julian Quevedo, Ansh Kumar Sharma, Yixiang Sun, Varad Suryavanshi, Percy Liang, and Sherry Yang. Worldgym: World model as an environment for policy evaluation.arXiv preprint arXiv:2506.00613, 2025. 10
-
[16]
A VID: Adapting video diffusion models to world models.arXiv preprint arXiv:2410.12822, 2024
Marc Rigter, Tarun Gupta, Agrin Hilmkil, and Chao Ma. A VID: Adapting video diffusion models to world models.arXiv preprint arXiv:2410.12822, 2024
-
[17]
arXiv preprint arXiv:2511.07732 (2025)
Sandeep Routray, Hengkai Pan, Unnat Jain, Shikhar Bahl, and Deepak Pathak. Vipra: Video prediction for robot actions.arXiv preprint arXiv:2511.07732, 2025
-
[18]
arXiv preprint arXiv:2602.08971 (2026)
Yu Shang, Zhuohang Li, Yiding Ma, Weikang Su, Xin Jin, Ziyou Wang, Lei Jin, Xin Zhang, Yinzhou Tang, Haisheng Su, Gao Chen, Wei Wu, Xihui Liu, Dhruv Shah, Zhaoxiang Zhang, Zhibo Chen, Jun Zhu, Yonghong Tian, Tat-Seng Chua, Wenwu Zhu, and Yong Li. WorldArena: A unified benchmark for evaluating perception and functional utility of embodied world models. arX...
-
[19]
Videovla: Video generators can be generalizable robot manipulators.arXiv preprint arXiv:2512.06963,
Yichao Shen, Fangyun Wei, Zhiying Du, Yaobo Liang, Yan Lu, Jiaolong Yang, Nanning Zheng, and Baining Guo. Videovla: Video generators can be generalizable robot manipulators.arXiv preprint arXiv:2512.06963, 2025
-
[20]
Mohit Shridhar, Yat Long Lo, and Stephen James. Generative image as action models.arXiv preprint arXiv:2407.07875, 2024
-
[21]
Yue Su, Sijin Chen, Haixin Shi, Mingyu Liu, Zhengshen Zhang, Ningyuan Huang, Weiheng Zhong, Zhengbang Zhu, Yuxiao Liu, and Xihui Liu. World guidance: World modeling in condition space for action generation.arXiv preprint arXiv:2602.22010, 2026
-
[22]
Scalable policy evaluation with video world models.arXiv preprint arXiv:2511.11520, 2025
Wei-Cheng Tseng, Jinwei Gu, Qinsheng Zhang, Hanzi Mao, Ming-Yu Liu, Florian Shkurti, and Yen-Chen Lin. Scalable policy evaluation with video world models.arXiv preprint arXiv:2511.11520, 2025
-
[23]
Vitalis V osylius, Younggyo Seo, Jafar Uruç, and Stephen James. Render and diffuse: Aligning image and action spaces for diffusion-based behaviour cloning.arXiv preprint arXiv:2405.18196, 2024
-
[24]
Wan2.2: Open and advanced large-scale video generative models
Wan Team. Wan2.2: Open and advanced large-scale video generative models. https:// github.com/Wan-Video/Wan2.2, 2025. GitHub repository and model release
2025
-
[25]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan Team. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
iVideoGPT: Interactive videogpts are scalable world models
Jialong Wu, Shaofeng Yin, Ningya Feng, Xu He, Dong Li, Jianye Hao, and Mingsheng Long. iVideoGPT: Interactive videogpts are scalable world models. InAdvances in Neural Information Processing Systems, 2024
2024
-
[27]
CogVideoX: Text-to- video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Xiaotao Gu, Yuxuan Zhang, Weihan Wang, Yean Cheng, Ting Liu, Bin Xu, Yuxiao Dong, and Jie Tang. CogVideoX: Text-to- video diffusion models with an expert transformer. InInternational Conference on Learning Representati...
2025
-
[28]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review arXiv 2026
-
[29]
Action Images: End-to-End Policy Learning via Multiview Video Generation
Haoyu Zhen, Zixian Gao, Qiao Sun, Yilin Zhao, Yuncong Yang, Yilun Du, Pengsheng Guo, Tsun-Hsuan Wang, Yi-Ling Qiao, and Chuang Gan. Action images: End-to-end policy learning via multiview video generation.arXiv preprint arXiv:2604.06168, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Universal actions for enhanced embodied foundation models
Jinliang Zheng, Jianxiong Li, Dongxiu Liu, Yinan Zheng, Zhihao Wang, Zhonghong Ou, Yu Liu, Jingjing Liu, Ya-Qin Zhang, and Xianyuan Zhan. Universal actions for enhanced embodied foundation models.arXiv preprint arXiv:2501.10105, 2025
-
[31]
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets.arXiv preprint arXiv:2504.02792, 2025
work page internal anchor Pith review arXiv 2025
-
[32]
IRASim: A fine-grained world model for robot manipulation
Fangqi Zhu, Hongtao Wu, Song Guo, Yuxiao Liu, Chilam Cheang, and Tao Kong. IRASim: A fine-grained world model for robot manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025. 11 A Appendix A.1 Detailed Network Architecture Pipeline This section describes the full EA-WM network pipeline. We focus on how RGB videos, K...
2025
-
[33]
+λ evtLEDLS 16:returnL 12 Algorithm 2Event-aware bidirectional fusion at layerℓ Require:Video tokensH v ℓ−1, KV AF tokens¯Hk ℓ 1:Predict event gate and event latent: Gℓ, ˆEℓ ←Φ ℓ(Hv ℓ−1, ¯Hk ℓ ) 2:Video reads KV AF: Rv ℓ ←CA v←k(Hv ℓ−1, ¯Hk ℓ ) 3:KV AF reads video: Rk ℓ ←CA k←v( ¯Hk ℓ ,H v ℓ−1) 4:Apply event-gated residual fusion: ˜Hv ℓ−1 =H v ℓ−1 +G ℓ ⊙R...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.