Recognition: unknown
PairAlign: A Framework for Sequence Tokenization via Self-Alignment with Applications to Audio Tokenization
Pith reviewed 2026-05-08 12:22 UTC · model grok-4.3
The pith
PairAlign generates compact audio token sequences by training each view's output to be likely under the other's encoder while contrasting unrelated examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
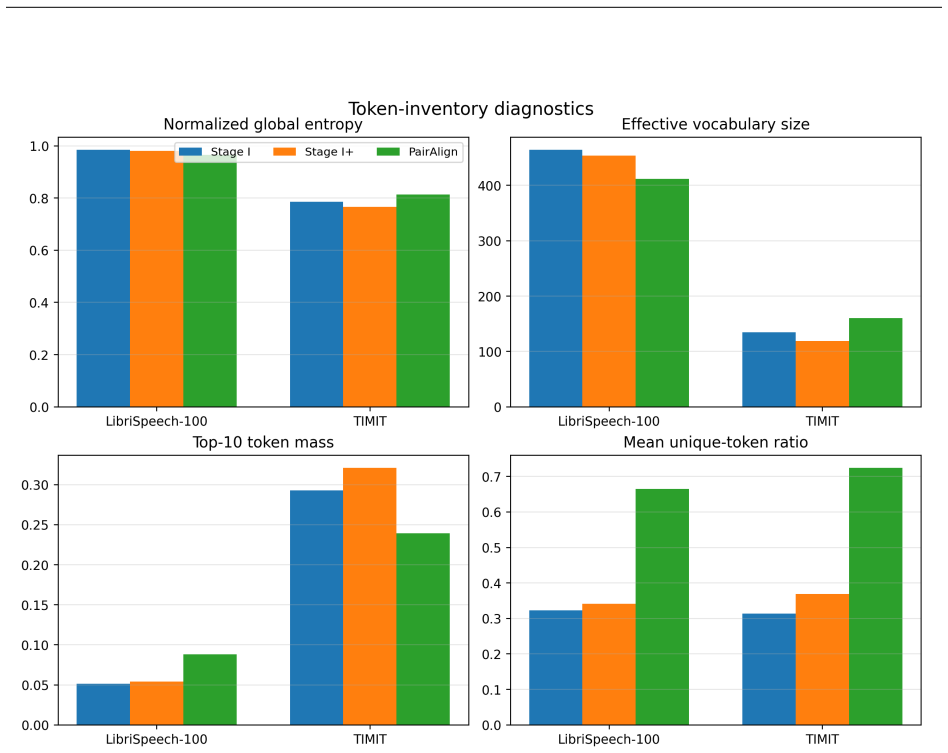
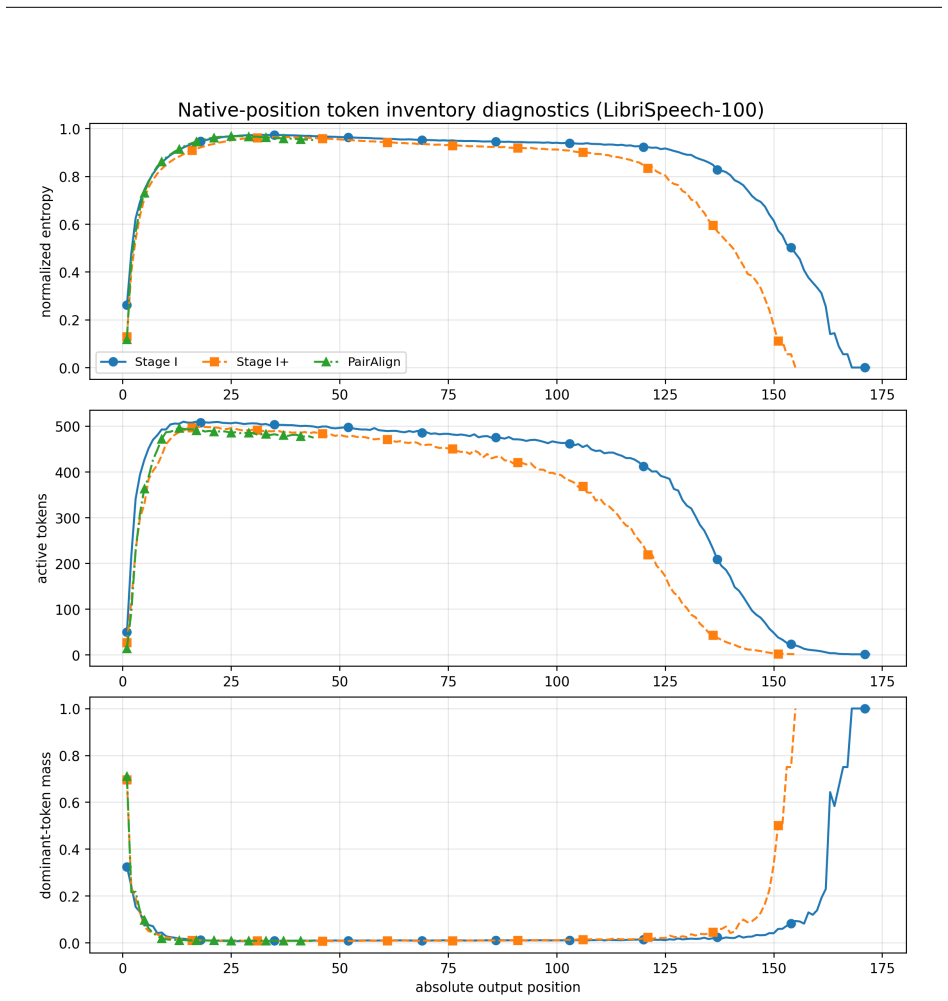
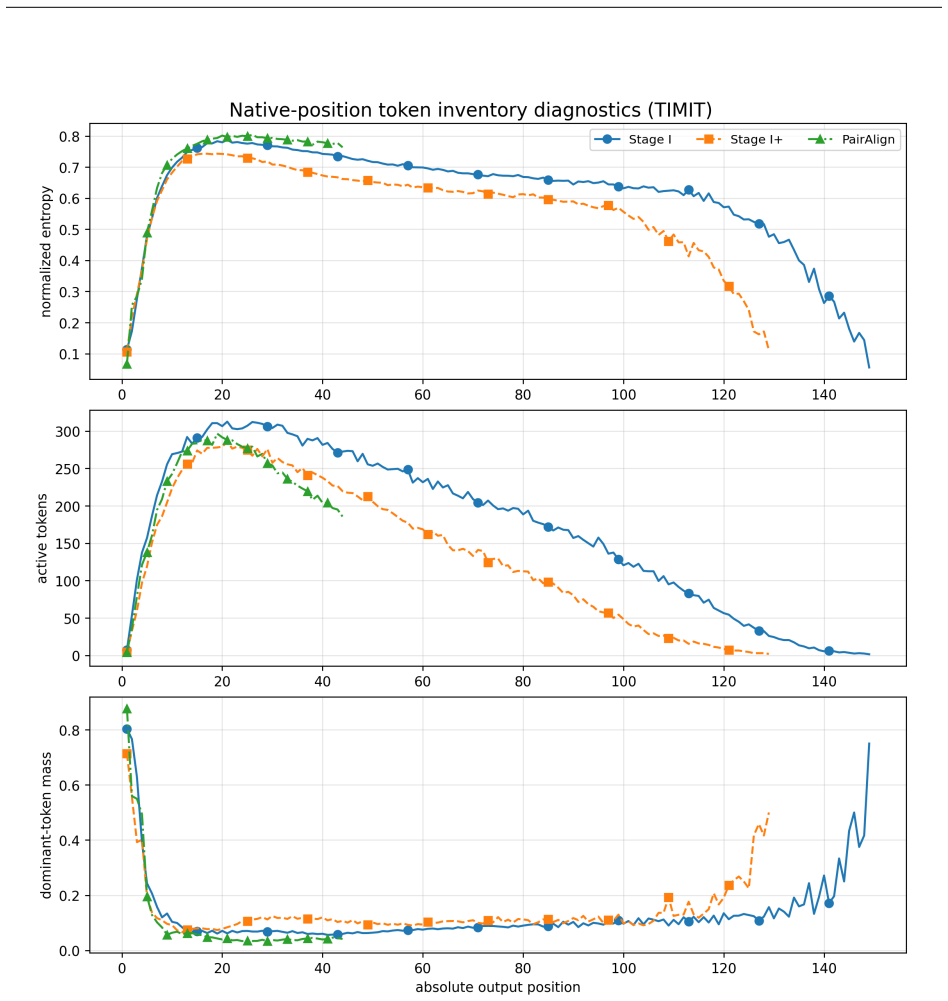
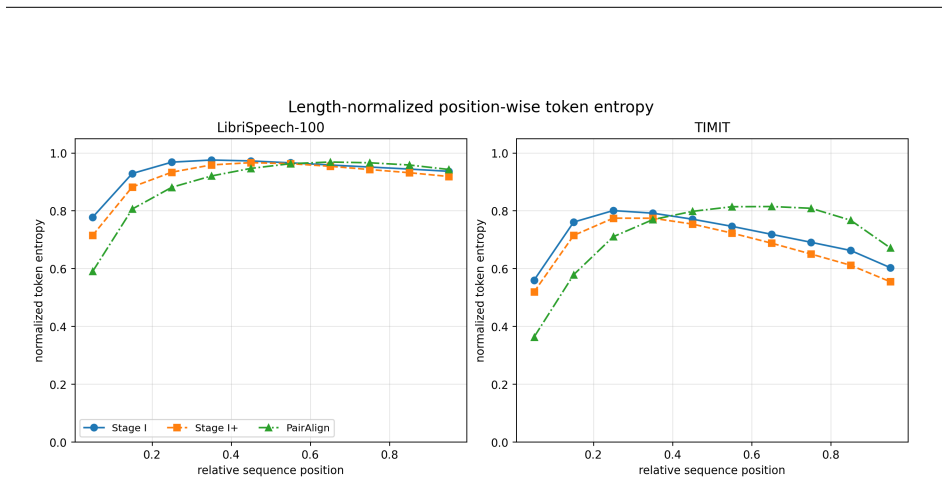
PairAlign treats tokenization as conditional sequence generation: an encoder maps speech to a continuous condition vector, and an autoregressive decoder generates a token sequence from BOS, learning identity, order, length, and EOS placement. Given paired content-preserving views, each view's sequence is optimized to be likely under the other's representation while unrelated examples provide competing negative sequences. This objective serves as a scalable surrogate for edit-distance preservation. On 3-second speech segments the resulting sequences show broad vocabulary usage and cross-view consistency; on TIMIT retrieval they maintain edit-distance search performance while reducing total 55
What carries the argument
Cross-view sequence likelihood contrast that trains an autoregressive decoder to produce tokens from one view that maximize probability under the encoder of the paired view, using negatives to prevent many-to-one collapse.
If this is right
- Token sequences exhibit bounded edit-distance trajectories under continuous time shifts of up to 100 ms.
- The method achieves stronger control over sequence length than dense geometric tokenizers while using a wider range of vocabulary items.
- Local token overlap is lower than in dense baselines, yet cross-view consistency is high enough to preserve retrieval utility.
- The same objective discourages degenerate many-to-one mappings without requiring explicit reconstruction losses.
Where Pith is reading between the lines
- The sequence-symbolic predictive style could be applied to other modalities such as video frames or time-series sensor readings where compact symbolic representations would aid memory and comparison.
- If edit-distance preservation holds across domains, downstream systems that already rely on string algorithms could adopt these tokens with minimal change to their pipelines.
- Length control and termination signals learned here might transfer to tasks that require deciding when a symbolic description should end.
Load-bearing premise
That optimizing cross-view sequence likelihood with unrelated negatives produces token sequences whose edit-distance properties generalize to downstream tasks without direct supervision on edit metrics.
What would settle it
Run the TIMIT retrieval experiment and check whether edit-distance search accuracy remains within a few percent of a standard VQ baseline after the reported 55% token reduction; a large drop would falsify the generalization claim.
Figures



read the original abstract
Many operations on sensory data -- comparison, memory, retrieval, and reasoning -- are naturally expressed over discrete symbolic structures. In language this interface is given by tokens; in audio, it must be learned. Existing audio tokenizers rely on quantization, clustering, or codec reconstruction, assigning tokens locally, so sequence consistency, compactness, length control, termination, and edit similarity are rarely optimized directly. We introduce PairAlign, a framework for compact audio tokenization through sequence-level self-alignment. PairAlign treats tokenization as conditional sequence generation: an encoder maps speech to a continuous condition, and an autoregressive decoder generates tokens from BOS, learning token identity, order, length, and EOS placement. Given two content-preserving views, each view's sequence is trained to be likely under the other's representation, while unrelated examples provide competing sequences. This gives a scalable surrogate for edit-distance preservation while discouraging many-to-one collapse. PairAlign starts from VQ-style tokenization and refines it with EMA-teacher targets, cross-paired teacher forcing, prefix corruption, likelihood contrast, and length control. On 3-second speech, PairAlign learns compact, non-degenerate sequences with broad vocabulary usage and strong cross-view consistency. On TIMIT retrieval, it preserves edit-distance search while reducing archive token count by 55%. A continuous-sweep probe shows lower local overlap than a dense geometric tokenizer, but stronger length control and bounded edit trajectories under 100 ms shifts. PairAlign is a sequence-symbolic predictive learner: like JEPA-style objectives, it predicts an abstract target from another view as a learned variable-length symbolic sequence, not a continuous latent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PairAlign, a self-alignment framework for learning compact discrete token sequences from audio. An encoder produces a continuous conditioning signal from speech, and an autoregressive decoder generates variable-length token sequences (including EOS) from paired content-preserving views. Training maximizes cross-view sequence likelihood with unrelated negatives for contrast, starting from VQ initialization and adding EMA-teacher targets, prefix corruption, and length control. On 3-second speech it reports broad vocabulary usage and cross-view consistency; on TIMIT it claims to preserve edit-distance retrieval while cutting archive token count by 55%, and a continuous-sweep probe shows improved length control and bounded edit trajectories under small shifts compared with dense geometric tokenizers.
Significance. If the central claims hold, the work would offer a scalable sequence-level predictive objective (analogous to JEPA but producing symbolic sequences) that directly targets compactness, termination, and edit-distance structure without explicit supervision on insertions/deletions/substitutions. This could advance discrete representation learning for audio and other sensory sequences where downstream tasks rely on symbolic comparison and retrieval.
major comments (3)
- [Abstract, §4] Abstract and experimental section: the claim that edit-distance search is 'preserved' on TIMIT is stated without accompanying retrieval metrics (precision, recall, or rank statistics) or comparison to the baseline tokenizer; only the 55% token-count reduction is quantified, leaving the fidelity claim unverifiable from the reported results.
- [§3.1–3.2] §3.1–3.2: the cross-view autoregressive likelihood plus contrastive negatives is presented as a surrogate for edit-distance preservation, yet no analysis, ablation, or theoretical argument demonstrates that small temporal shifts in the input produce correspondingly small Levenshtein distances in the output token sequences; the EMA-teacher, prefix corruption, and length-control terms are fitted and could dominate the metric structure.
- [§4] Experimental section: no ablations, error bars, or full hyper-parameter tables are provided for the TIMIT retrieval and continuous-sweep probes, so the reported gains cannot be assessed for robustness or sensitivity to the free parameters (vocabulary size, length-control coefficients, EMA decay).
minor comments (2)
- [§3] Notation for the encoder output and decoder conditioning is introduced without an explicit equation; a single diagram or equation block would clarify the information flow.
- [Abstract] The abstract states 'broad vocabulary usage' but no entropy or usage histogram is referenced; adding a brief statistic or figure would strengthen the non-degeneracy claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that will strengthen the verifiability and robustness of the presented results.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and experimental section: the claim that edit-distance search is 'preserved' on TIMIT is stated without accompanying retrieval metrics (precision, recall, or rank statistics) or comparison to the baseline tokenizer; only the 55% token-count reduction is quantified, leaving the fidelity claim unverifiable from the reported results.
Authors: We appreciate the referee highlighting this issue. The manuscript reports the 55% token-count reduction on TIMIT while stating that edit-distance retrieval is preserved, but we agree that explicit metrics (precision, recall, rank statistics) and a direct baseline comparison would make the preservation claim verifiable. In the revised manuscript we will add these retrieval metrics and the baseline comparison to the experimental section. revision: yes
-
Referee: [§3.1–3.2] §3.1–3.2: the cross-view autoregressive likelihood plus contrastive negatives is presented as a surrogate for edit-distance preservation, yet no analysis, ablation, or theoretical argument demonstrates that small temporal shifts in the input produce correspondingly small Levenshtein distances in the output token sequences; the EMA-teacher, prefix corruption, and length-control terms are fitted and could dominate the metric structure.
Authors: We thank the referee for this observation. The cross-view likelihood is intended to act as a scalable surrogate for edit-distance preservation by requiring sequences from content-preserving views to be mutually likely, while contrastive negatives discourage collapse. We acknowledge, however, that the manuscript does not contain explicit analysis, ablations, or theoretical arguments isolating the effect of small temporal shifts on Levenshtein distance, nor does it quantify the contribution of the auxiliary terms. In the revision we will add a dedicated analysis subsection with shift experiments and component ablations to address this point. revision: yes
-
Referee: [§4] Experimental section: no ablations, error bars, or full hyper-parameter tables are provided for the TIMIT retrieval and continuous-sweep probes, so the reported gains cannot be assessed for robustness or sensitivity to the free parameters (vocabulary size, length-control coefficients, EMA decay).
Authors: We agree that the experimental reporting can be strengthened. In the revised version we will include ablations on the main training components, error bars from repeated runs for the TIMIT and continuous-sweep results, and a complete hyper-parameter table specifying vocabulary size, length-control coefficients, EMA decay, and other relevant settings. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The PairAlign framework defines a self-alignment training objective based on cross-view conditional sequence likelihood plus contrastive negatives drawn from the dataset. This objective is presented explicitly as a surrogate for edit-distance preservation rather than being mathematically equivalent to it. Reported outcomes such as 55% token reduction on TIMIT retrieval while preserving edit-distance search are empirical results obtained after training and separate evaluation; they do not reduce by construction to the training inputs. Design elements including EMA-teacher targets, prefix corruption, and length control are explicit modeling choices whose effects are measured externally rather than assumed. No load-bearing self-citations, uniqueness theorems, or fitted parameters renamed as predictions appear in the provided text. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (3)
- vocabulary size
- length control parameters
- EMA decay rate
axioms (2)
- domain assumption Autoregressive token generation is a valid model for sequence tokenization
- domain assumption Content-preserving views exist and can be sampled for the same audio clip
Reference graph
Works this paper leans on
-
[1]
MusicLM: Generating Music From Text
Andrea Agostinelli, Timo I Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, et al. Musiclm: Generating music from text. arXiv preprint arXiv:2301.11325,
work page internal anchor Pith review arXiv
-
[2]
vq-wav2vec: Self-supervised learning of discrete speech representations
Alexei Baevski, Steffen Schneider, and Michael Auli. vq-wav2vec: Self-supervised learning of discrete speech representations.arXiv preprint arXiv:1910.05453,
-
[3]
Neural Machine Translation by Jointly Learning to Align and Translate
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate.arXiv preprint arXiv:1409.0473,
work page internal anchor Pith review arXiv
-
[4]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022a. Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jo...
work page internal anchor Pith review arXiv
-
[5]
Enc-dec rnn acoustic word embeddings learned via pairwise prediction
Adhiraj Banerjee and Vipul Arora. Enc-dec rnn acoustic word embeddings learned via pairwise prediction. InProc. Interspeech 2023, pp. 1478–1482,
2023
-
[6]
Adrien Bardes, Jean Ponce, and Yann LeCun. Vicreg: Variance-invariance-covariance regularization for self-supervised learning.arXiv preprint arXiv:2105.04906,
-
[7]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representations from video.arXiv preprint arXiv:2404.08471,
work page internal anchor Pith review arXiv
-
[8]
Listen, attend and spell.arXiv preprint arXiv:1508.01211,
William Chan, Navdeep Jaitly, Quoc V Le, and Oriol Vinyals. Listen, attend and spell.arXiv preprint arXiv:1508.01211,
-
[9]
Monotonic chunkwise attention.arXiv preprint arXiv:1712.05382, 2017a
Chung-Cheng Chiu and Colin Raffel. Monotonic chunkwise attention.arXiv preprint arXiv:1712.05382, 2017a. Chung-Cheng Chiu and Colin Raffel. Monotonic chunkwise attention.arXiv preprint arXiv:1712.05382, 2017b. Jishnu Ray Chowdhury and Cornelia Caragea. Monotonic location attention for length generalization. In International Conference on Machine Learning,...
-
[10]
Yu-An Chung, Wei-Ning Hsu, Hao Tang, and James Glass. An unsupervised autoregressive model for speech representation learning.arXiv preprint arXiv:1904.03240,
-
[11]
Vector-quantizedautoregressivepredictivecoding.arXiv preprint arXiv:2005.08392,
Yu-AnChung, HaoTang, andJamesGlass. Vector-quantizedautoregressivepredictivecoding.arXiv preprint arXiv:2005.08392,
-
[12]
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through struc- tured state space duality.arXiv preprint arXiv:2405.21060,
work page internal anchor Pith review arXiv
-
[13]
High Fidelity Neural Audio Compression
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression. arXiv preprint arXiv:2210.13438,
work page internal anchor Pith review arXiv
-
[14]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real-time dialogue.arXiv preprint arXiv:2410.00037,
work page internal anchor Pith review arXiv
-
[15]
Bert: Pre-trainingofdeepbidirectional transformers for language understanding
JacobDevlin, Ming-WeiChang, KentonLee, andKristinaToutanova. Bert: Pre-trainingofdeepbidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
2019
-
[16]
Lauragpt: Listen, attend, understand, and regenerate audio with gpt.arXiv preprint arXiv:2310.04673,
Zhihao Du, Jiaming Wang, Qian Chen, Yunfei Chu, Zhifu Gao, Zerui Li, Kai Hu, Xiaohuan Zhou, Jin Xu, Ziyang Ma, et al. Lauragpt: Listen, attend, understand, and regenerate audio with gpt.arXiv preprint arXiv:2310.04673,
-
[17]
Funcodec: A fundamental, reproducible and integrable open-source toolkit for neural speech codec
Zhihao Du, Shiliang Zhang, Kai Hu, and Siqi Zheng. Funcodec: A fundamental, reproducible and integrable open-source toolkit for neural speech codec. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 591–595. IEEE,
2024
-
[18]
KTO: Model Alignment as Prospect Theoretic Optimization
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Kto: Model alignment as prospect theoretic optimization.arXiv preprint arXiv:2402.01306,
work page internal anchor Pith review arXiv
-
[19]
Available: http://arxiv.org/abs/2002.07017
Marco Federici, Anjan Dutta, Patrick Forré, Nate Kushman, and Zeynep Akata. Learning robust represen- tations via multi-view information bottleneck.arXiv preprint arXiv:2002.07017,
-
[20]
A-jepa: Joint-embedding predictive architecture can listen.arXiv preprint arXiv:2311.15830,
Zhengcong Fei, Mingyuan Fan, and Junshi Huang. A-jepa: Joint-embedding predictive architecture can listen.arXiv preprint arXiv:2311.15830,
-
[21]
Sequence transduction with recurrent neural networks.arXiv preprint arXiv:1211.3711,
Alex Graves. Sequence transduction with recurrent neural networks.arXiv preprint arXiv:1211.3711,
-
[22]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396,
work page internal anchor Pith review arXiv
-
[23]
Multi-view recurrent neural acoustic word embeddings.arXiv preprint arXiv:1611.04496,
Wanjia He, Weiran Wang, and Karen Livescu. Multi-view recurrent neural acoustic word embeddings.arXiv preprint arXiv:1611.04496,
-
[24]
The Curious Case of Neural Text Degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degener- ation.arXiv preprint arXiv:1904.09751,
work page internal anchor Pith review arXiv 1904
-
[25]
Orpo: Monolithic preference optimization without reference model
Jiwoo Hong, Noah Lee, and James Thorne. Orpo: Monolithic preference optimization without reference model. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 11170–11189,
2024
-
[26]
Gaussian prediction based attention for online end-to-end speech recognition
Junfeng Hou, Shiliang Zhang, and Li-Rong Dai. Gaussian prediction based attention for online end-to-end speech recognition. InProc. Interspeech 2017, pp. 3692–3696,
2017
-
[27]
Mulan: A joint embedding of music audio and natural language.arXiv preprint arXiv:2208.12415,
Qingqing Huang, Aren Jansen, Joonseok Lee, Ravi Ganti, Judith Yue Li, and Daniel PW Ellis. Mulan: A joint embedding of music audio and natural language.arXiv preprint arXiv:2208.12415,
-
[28]
Jong Wook Kim, Justin Salamon, Peter Li, and Juan Pablo Bello
Shengpeng Ji, Ziyue Jiang, Wen Wang, Yifu Chen, Minghui Fang, Jialong Zuo, Qian Yang, Xize Cheng, Zehan Wang, Ruiqi Li, et al. Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling.arXiv preprint arXiv:2408.16532,
-
[29]
arXiv preprint arXiv:2403.03100 , year=
Zeqian Ju, Yuancheng Wang, Kai Shen, Xu Tan, Detai Xin, Dongchao Yang, Yanqing Liu, Yichong Leng, Kaitao Song, Siliang Tang, et al. Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models.arXiv preprint arXiv:2403.03100,
-
[30]
Audiogen: Textually guided audio gen- eration.arXiv preprint arXiv:2209.15352, 2022
Felix Kreuk, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre Défossez, Jade Copet, Devi Parikh, Yaniv Taigman, and Yossi Adi. Audiogen: Textually guided audio generation.arXiv preprint arXiv:2209.15352,
-
[31]
A path towards autonomous machine intelligence version 0.9
Yann LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27.Open Review, 62(1):1–62,
2022
-
[32]
rlhf: Scaling reinforcement learning from human feedback with ai feedback , author=
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, et al. Rlaif vs. rlhf: Scaling reinforcement learning from human feedback with ai feedback.arXiv preprint arXiv:2309.00267,
-
[33]
Mockingjay: Unsupervised speech representation learning with deep bidirectional transformer encoders
Andy T Liu, Shu-wen Yang, Po-Han Chi, Po-chun Hsu, and Hung-yi Lee. Mockingjay: Unsupervised speech representation learning with deep bidirectional transformer encoders. InICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6419–6423. IEEE,
2020
-
[34]
Understanding R1-Zero-Like Training: A Critical Perspective
Tianqi Liu, Zhen Qin, Junru Wu, Jiaming Shen, Misha Khalman, Rishabh Joshi, Yao Zhao, Mohammad Saleh, Simon Baumgartner, Jialu Liu, et al. Lipo: Listwise preference optimization through learning-to- rank. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologie...
work page internal anchor Pith review arXiv 2025
-
[35]
Monotonic multihead attention.arXiv preprint arXiv:1909.12406,
Xutai Ma, Juan Pino, James Cross, Liezl Puzon, and Jiatao Gu. Monotonic multihead attention.arXiv preprint arXiv:1909.12406,
-
[36]
Finite scalar quantization: Vq-vae made simple.arXiv preprint arXiv:2309.15505, 2023
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: Vq-vae made simple.arXiv preprint arXiv:2309.15505,
-
[37]
Discrete audio tokens: More than a survey!arXiv preprint arXiv:2506.10274, 2025
99 Pooneh Mousavi, Gallil Maimon, Adel Moumen, Darius Petermann, Jiatong Shi, Haibin Wu, Haici Yang, Anastasia Kuznetsova, Artem Ploujnikov, Ricard Marxer, et al. Discrete audio tokens: More than a survey!arXiv preprint arXiv:2506.10274,
-
[38]
Paarth Neekhara, Shehzeen Hussain, Subhankar Ghosh, Jason Li, Rafael Valle, Rohan Badlani, and Boris Ginsburg. Improving robustness of llm-based speech synthesis by learning monotonic alignment.arXiv preprint arXiv:2406.17957,
-
[39]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748,
work page internal anchor Pith review arXiv
-
[40]
AudioPaLM: A large language model that can speak and listen,
Paul K Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, et al. Audiopalm: A large language model that can speak and listen.arXiv preprint arXiv:2306.12925,
-
[41]
Lattice-based search for spoken utterance retrieval
Murat Saraclar and Richard Sproat. Lattice-based search for spoken utterance retrieval. InProceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics: HLT-NAACL 2004, pp. 129–136,
2004
-
[42]
Proximal Policy Optimization Algorithms
100 John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimiza- tion algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review arXiv
-
[43]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review arXiv
-
[44]
Attention-based audio embeddings for query-by-example
Anup Singh, Kris Demuynck, and Vipul Arora. Attention-based audio embeddings for query-by-example. arXiv preprint arXiv:2210.08624,
-
[45]
Simultaneously learning robust audio embeddings and balanced hash codes for query-by-example
Anup Singh, Kris Demuynck, and Vipul Arora. Simultaneously learning robust audio embeddings and balanced hash codes for query-by-example. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2023
-
[46]
Best-std: Bidirectional mamba-enhanced speech tokenization for spoken term detection
Anup Singh, Kris Demuynck, and Vipul Arora. Best-std: Bidirectional mamba-enhanced speech tokenization for spoken term detection. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE, 2025a. Anup Singh, Kris Demuynck, and Vipul Arora. Best-std2. 0: Balanced and efficient speech tokenizer for s...
-
[47]
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. Mass: Masked sequence to sequence pre- training for language generation.arXiv preprint arXiv:1905.02450,
-
[48]
Audio-language models for audio-centric tasks: A survey.arXiv preprint arXiv:2501.15177,
Yi Su, Jisheng Bai, Qisheng Xu, Kele Xu, and Yong Dou. Audio-language models for audio-centric tasks: A survey.arXiv preprint arXiv:2501.15177,
-
[49]
Segmental dtw: A parallelizable alternative to dynamic time warping
TJ Tsai. Segmental dtw: A parallelizable alternative to dynamic time warping. InICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 106–110. IEEE,
2021
-
[50]
Self-supervised Learning from a Multi-view Perspective , publisher =
Yao-HungHubertTsai, YueWu, RuslanSalakhutdinov, andLouis-PhilippeMorency. Self-supervisedlearning from a multi-view perspective.arXiv preprint arXiv:2006.05576,
-
[51]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111, 2023a. Dong Wang, Joe Frankel, Javier Tejedor, and Simon King. A comparison of phone and grapheme-based spoken termdetection...
work page internal anchor Pith review arXiv
-
[52]
Tianrui Wang, Long Zhou, Ziqiang Zhang, Yu Wu, Shujie Liu, Yashesh Gaur, Zhuo Chen, Jinyu Li, and Furu Wei. Viola: Unified codec language models for speech recognition, synthesis, and translation.arXiv preprint arXiv:2305.16107, 2023b. Xiaofei Wang, Manthan Thakker, Zhuo Chen, Naoyuki Kanda, Sefik Emre Eskimez, Sanyuan Chen, Min Tang, Shujie Liu, Jinyu Li...
-
[53]
Towards audio language modeling–an overview,
Haibin Wu, Xuanjun Chen, Yi-Cheng Lin, Kai-wei Chang, Ho-Lam Chung, Alexander H Liu, and Hung-yi Lee. Towards audio language modeling–an overview.arXiv preprint arXiv:2402.13236,
-
[54]
Audiodec: An open-source streaming high-fidelity neural audio codec
Yi-Chiao Wu, Israel D Gebru, Dejan Marković, and Alexander Richard. Audiodec: An open-source streaming high-fidelity neural audio codec. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2023
-
[55]
BigCodec: Pushing the limits of low-bitrate neural speech codec.arXiv preprint arXiv:2409.05377,
Detai Xin, Xu Tan, Shinnosuke Takamichi, and Hiroshi Saruwatari. Bigcodec: Pushing the limits of low- bitrate neural speech codec.arXiv preprint arXiv:2409.05377,
-
[56]
arXiv preprint arXiv:2305.02765 , year=
Dongchao Yang, Songxiang Liu, Rongjie Huang, Jinchuan Tian, Chao Weng, and Yuexian Zou. Hifi-codec: Group-residual vector quantization for high fidelity audio codec.arXiv preprint arXiv:2305.02765,
-
[57]
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Lijun Yu, José Lezama, Nitesh B Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Vighnesh Birodkar, Agrim Gupta, Xiuye Gu, et al. Language model beats diffusion–tokenizer is key to visual generation.arXiv preprint arXiv:2310.05737,
work page internal anchor Pith review arXiv
-
[58]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review arXiv
-
[59]
arXiv preprint arXiv:2304.05302 , year=
102 Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. Rrhf: Rank responses to align language models with human feedback without tears.arXiv preprint arXiv:2304.05302,
-
[60]
Barlow twins: Self-supervised learning viaredundancyreduction
Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, and Stéphane Deny. Barlow twins: Self-supervised learning viaredundancyreduction. InInternational conference on machine learning, pp.12310–12320.PMLR,2021. Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. Soundstream: An end-to-end neural audio codec.IEEE/ACM Transactions o...
2021
-
[61]
XinZhang, DongZhang, ShiminLi, YaqianZhou, andXipengQiu. Speechtokenizer: Unifiedspeechtokenizer for speech large language models.arXiv preprint arXiv:2308.16692, 2023a. Ziqiang Zhang, Long Zhou, Chengyi Wang, Sanyuan Chen, Yu Wu, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. Speak foreign languages with your own voice: Cross-lingual ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.