Recognition: no theorem link
Stochastic Policy Gradient Methods in the Uncertain Volatility Model
Pith reviewed 2026-05-13 22:19 UTC · model grok-4.3
The pith
A backward actor-critic policy gradient scheme with C-vine correlation parameterization solves high-dimensional robust option pricing in the uncertain volatility model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a backward actor-critic stochastic policy gradient scheme, obtained by merging a discrete dynamic programming principle with Proximal Policy Optimization and shallow neural-network approximations of both the value function and the control policy, yields accurate robust prices for multidimensional derivatives under joint volatility and correlation uncertainty when continuous controls are parameterized as squashed Gaussians on C-vine correlation matrices.
What carries the argument
The squashed Gaussian policy built on a C-vine representation of correlation matrices, which enforces positive semidefiniteness by construction while allowing gradient-based optimization of continuous controls inside the stochastic control problem.
If this is right
- The method produces accurate robust prices for a range of multidimensional derivatives.
- Computation remains efficient even when the state space is high-dimensional.
- The approach compares favorably with existing Monte Carlo and machine-learning benchmarks for robust pricing.
- The C-vine parameterization captures the full admissible set of correlation matrices without bias.
Where Pith is reading between the lines
- The same actor-critic structure with vine-parameterized policies could be applied to other robust stochastic control problems that involve matrix-valued controls.
- Replacing shallow networks with deeper architectures or adding variance-reduction techniques might extend the method to even higher-dimensional or path-dependent payoffs.
- Because the policy is learned backward in time, the framework naturally lends itself to pricing problems with early-exercise features under uncertainty.
Load-bearing premise
The shallow neural-network approximations of the value function and continuous control policy remain sufficiently accurate across the tested high-dimensional cases, and the C-vine parameterization fully captures the admissible set of correlation matrices without introducing material bias.
What would settle it
If the computed prices on a benchmark multidimensional derivative with independently verifiable robust value deviate materially from existing Monte Carlo or machine-learning benchmarks, the accuracy claim would be falsified.
Figures




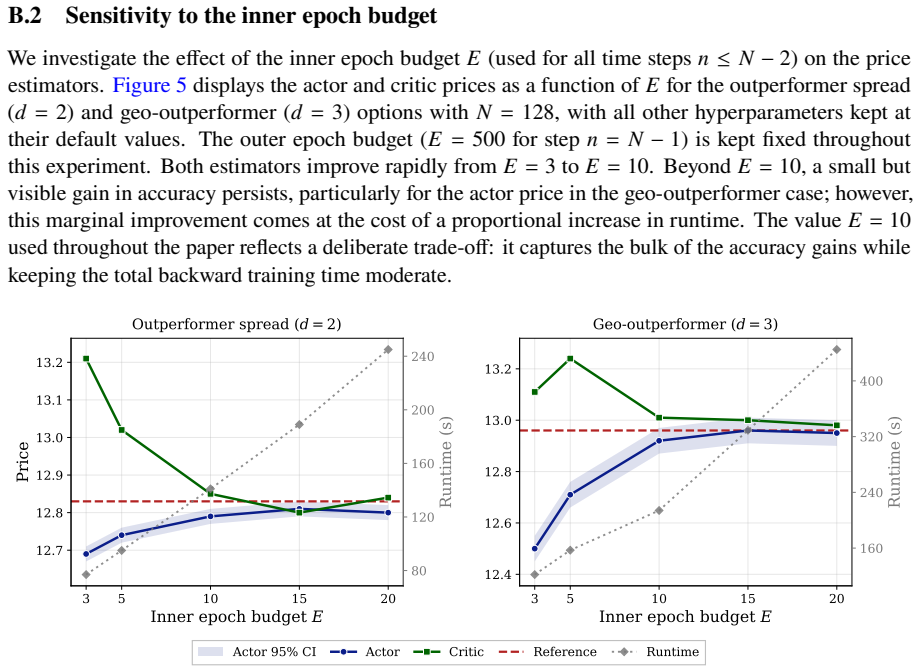
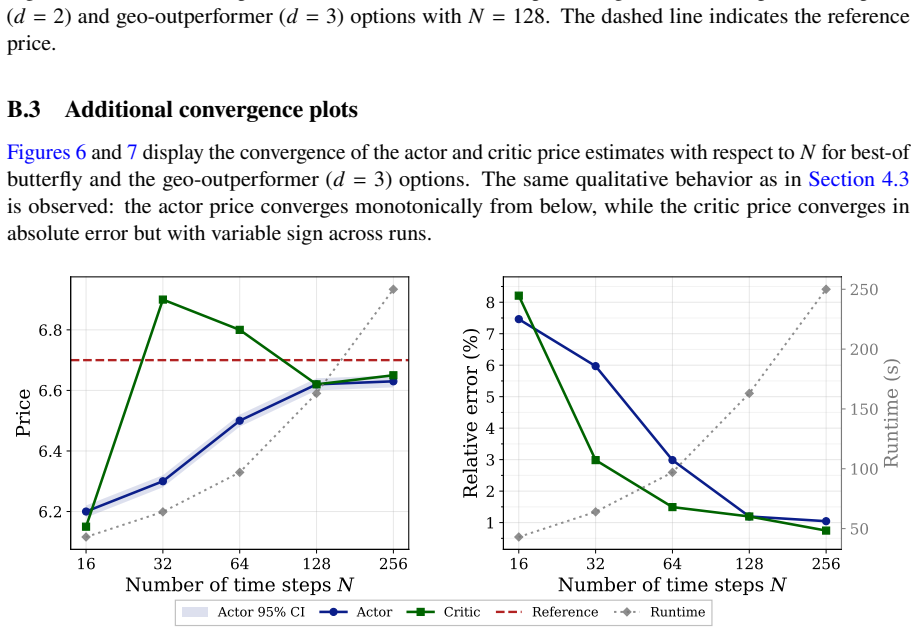

read the original abstract
The multidimensional Uncertain Volatility Model leads to robust option pricing problems under joint volatility and correlation uncertainty. Their numerical resolution quickly becomes challenging because the associated stochastic control problem is high-dimensional. We propose a backward actor-critic stochastic policy gradient scheme tailored to this setting. The method combines a discrete dynamic programming principle with Proximal Policy Optimization and shallow neural-network approximations of both the value function and the control policy. A key ingredient is the policy parameterization: continuous controls are represented through a squashed Gaussian policy built on a C-vine representation of correlation matrices, which enforces positive semidefiniteness by construction. Numerical experiments on a range of multidimensional derivatives show that the method yields accurate prices, remains computationally efficient, and compares favorably with existing Monte Carlo and machine-learning-based benchmarks for robust pricing in the Uncertain Volatility Model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a backward actor-critic stochastic policy gradient scheme for high-dimensional robust option pricing in the multidimensional Uncertain Volatility Model. It combines a discrete dynamic programming principle with Proximal Policy Optimization, using shallow neural-network approximations of the value function and continuous control policy. A key element is the squashed-Gaussian policy built on a C-vine representation of correlation matrices to enforce positive semidefiniteness by construction. Numerical experiments on multidimensional derivatives are reported to show accurate prices, computational efficiency, and favorable comparisons to Monte Carlo and machine-learning benchmarks.
Significance. If the shallow-network approximations remain accurate, the method would supply a practical numerical route to robust pricing under joint volatility and correlation uncertainty in dimensions where grid-based or standard Monte Carlo approaches become intractable, extending policy-gradient techniques to a class of nonlinear stochastic control problems that arise in quantitative finance.
major comments (2)
- [Numerical Experiments] Numerical Experiments section: the reported accuracy and efficiency comparisons are presented without error bars, convergence diagnostics, or full experimental protocols (including network depth, training epochs, and sample sizes), so the central claim that the method 'yields accurate prices' in high-dimensional cases rests on limited verifiable evidence.
- [Method Description] Policy parameterization and approximation sections: the claim that the shallow NN value-function and squashed-Gaussian policy approximations remain sufficiently accurate across tested high-dimensional UVM instances lacks supporting error bounds, convergence rates, or depth-ablation studies; the nonlinear dependence of the value function on the full correlation matrix and volatility bounds makes this a load-bearing assumption for the reported pricing tolerances.
minor comments (2)
- [Abstract] The abstract and introduction should explicitly state the network architectures (number of layers, neurons, activation functions) used for the value and policy networks to aid reproducibility.
- [Method Description] Notation for the C-vine parameterization and the squashed-Gaussian policy should be introduced with a short self-contained definition before the algorithm description.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the numerical experiments and approximation claims. We address each point below and outline revisions to enhance reproducibility and empirical support.
read point-by-point responses
-
Referee: [Numerical Experiments] Numerical Experiments section: the reported accuracy and efficiency comparisons are presented without error bars, convergence diagnostics, or full experimental protocols (including network depth, training epochs, and sample sizes), so the central claim that the method 'yields accurate prices' in high-dimensional cases rests on limited verifiable evidence.
Authors: We agree that the original presentation lacked sufficient detail for full reproducibility. In the revised manuscript, the Numerical Experiments section will be expanded to include error bars from multiple independent training runs, convergence diagnostics (e.g., value-function loss and policy gradient norms over epochs), and complete protocols specifying network depths, training epochs, batch sizes, sample sizes per iteration, and random seeds. These additions will strengthen the verifiable evidence supporting the accuracy claims in high dimensions. revision: yes
-
Referee: [Method Description] Policy parameterization and approximation sections: the claim that the shallow NN value-function and squashed-Gaussian policy approximations remain sufficiently accurate across tested high-dimensional UVM instances lacks supporting error bounds, convergence rates, or depth-ablation studies; the nonlinear dependence of the value function on the full correlation matrix and volatility bounds makes this a load-bearing assumption for the reported pricing tolerances.
Authors: We acknowledge that the manuscript provides no theoretical error bounds or convergence rates, which would require new analysis of the nonlinear dependence on the correlation matrix and volatility bounds—an undertaking outside the paper's applied scope. To address the concern empirically, the revised version will incorporate depth-ablation studies comparing shallow versus deeper networks on the tested instances, along with additional discussion of the C-vine squashed-Gaussian parameterization's role in enforcing positive semidefiniteness and observed numerical stability. This provides practical support for the reported tolerances while clarifying the assumption's empirical basis. revision: partial
- Deriving rigorous error bounds and convergence rates for the shallow neural-network approximations under the nonlinear dependence on the full correlation matrix and volatility bounds in high-dimensional UVM.
Circularity Check
No circularity: numerical scheme derives outputs from optimization, not algebraic reduction to inputs
full rationale
The paper describes a backward actor-critic scheme combining discrete dynamic programming with Proximal Policy Optimization and shallow NN approximations of value and policy. The C-vine parameterization enforces PSD by construction as a standard representation choice, not a self-referential fit. No step reduces a claimed prediction to a pre-fitted constant or to a self-citation chain whose validity depends on the present result. Numerical experiments serve as external validation rather than tautological confirmation. The derivation chain remains self-contained against the stated assumptions.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights and biases
axioms (1)
- domain assumption The dynamic programming principle applies to the robust pricing stochastic control problem
Reference graph
Works this paper leans on
-
[1]
Pricing and hedging derivative securities in markets with uncertain volatilities
Marco Avellaneda, Arnon Levy, and Antonio Paras. Pricing and hedging derivative securities in markets with uncertain volatilities. Applied Mathematical Finance , 2(2):73--88, 1995
work page 1995
-
[2]
Christian Beck, Weinan E, and Arnulf Jentzen. Machine learning approximation algorithms for high-dimensional fully nonlinear partial differential equations and second-order backward stochastic differential equations. Journal of Nonlinear Science , 29(4):1563--1619, 2019
work page 2019
-
[3]
Achref Bachouch, Côme Huré, Nicolas Langrené, and Huyên Pham. Deep neural networks algorithms for stochastic control problems on finite horizon: Numerical applications. Methodology and Computing in Applied Probability , 24(1):143--178, 2022
work page 2022
-
[4]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization. arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Mete Soner, Nizar Touzi, and Victoir Nicolas
Patrick Cheridito, H. Mete Soner, Nizar Touzi, and Victoir Nicolas. Second-order backward stochastic differential equations and fully nonlinear parabolic pdes. Communications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences , 60:1081--1110, 2007
work page 2007
-
[6]
A theoretical framework for the pricing of contigent claims in the presence of model uncertainty
Laurent Denis and Claude Martini. A theoretical framework for the pricing of contigent claims in the presence of model uncertainty. The Annals of Applied Probability , 16(2):827--852, 2006
work page 2006
-
[7]
Weinan E, Jiequn Han, and Arnulf Jentzen. Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations. Communications in Mathematics and Statistics , 5(4):349--380, 2017
work page 2017
-
[8]
Wendell H. Fleming and Raymond Rishel. Deterministic and Stochastic Optimal Control . Springer-Verlag, New York, 1975
work page 1975
-
[9]
Wendell H. Fleming and H. Mete Soner. Controlled Markov processes and viscosity solutions . Springer-Verlag, New York, 1993
work page 1993
-
[10]
A probabilistic numerical method for fully nonlinear parabolic pdes
Arash Fahim, Nizar Touzi, and Xavier Warin. A probabilistic numerical method for fully nonlinear parabolic pdes. The Annals of Applied Probability , 21(4):1322--1364, 2011
work page 2011
-
[11]
Evan Greensmith, Peter L. Bartlett, and Jonathan Baxter. Variance reduction techniques for gradient estimates in reinforcement learning. Journal of Machine Learning Research , 5(Nov):1471--1530, 2004
work page 2004
-
[12]
Uncertain volatility model: A monte-carlo approach
Julien Guyon and Pierre Henry-Labordère. Uncertain volatility model: A monte-carlo approach. Journal of Computational Finance , 14(3), 2011
work page 2011
-
[13]
A regression-based monte carlo method to solve backward stochastic differential equations
Emmanuel Gobet, Jean-Phillipe Lemor, and Xavier Warin. A regression-based monte carlo method to solve backward stochastic differential equations. The Annals of Applied Probability , 15(3):2172--2202, 2005
work page 2005
-
[14]
Ludovic Goudenege, Andrea Molent, and Antonino Zanette. Leveraging machine learning for high-dimensional option pricing within the uncertain volatility model. arXiv:2407.13213, 2024
-
[15]
Superreplication of european multiasset derivatives with bounded stochastic volatility
Fausto Gozzi and Tiziano Vargiolu. Superreplication of european multiasset derivatives with bounded stochastic volatility. Mathematical Methods of Operations Research , 55(1):69--91, 2002
work page 2002
-
[16]
A monotone scheme for high-dimensional fully nonlinear pdes
By Wenjie Guo, Jianfeng Zhang, and Jia Zhuo. A monotone scheme for high-dimensional fully nonlinear pdes. The Annals of Applied Probability , 25(3):1540--1580, 2015
work page 2015
-
[17]
Deep learning approximation for stochastic control problems
Jiequn Han and Weinan E. Deep learning approximation for stochastic control problems. Advances in Neural Information Processing Systems, Deep Reinforcement Learning Workshop , 2016
work page 2016
-
[18]
Mohamed Hamdouche, Pierre Henry-Labordère, and Huyên Pham. Policy gradient learning methods for stochastic control with exit time and applications to share repurchase pricing. Applied Mathematical Finance , 29(6):439--456, 2023
work page 2023
-
[19]
Solving high-dimensional partial differential equations using deep learning
Jiequn Han, Arnulf Jentzen, and Weinan E. Solving high-dimensional partial differential equations using deep learning. Proceedings of the National Academy of Sciences , 115(34):8505--8510, 2018
work page 2018
- [20]
-
[21]
Côme Huré, Huyên Pham, Achref Bachouch, and Nicolas Langrené. Deep neural networks algorithms for stochastic control problems on finite horizon: Convergence analysis. SIAM Journal on Numerical Analysis , 59(1):525--557, 2021
work page 2021
-
[22]
Peter J. Huber. Robust estimation of a location parameter. The Annals of Mathematical Statistics , 1964
work page 1964
-
[23]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. International Conference on Machine Learning , pages 1861--1870, 2018
work page 2018
-
[24]
Generating random correlation matrices based on vines and extended onion method
Harry Joe, Dorota Kurowicka, and Daniel Lewandowski. Generating random correlation matrices based on vines and extended onion method. Journal of Multivariate Analysis , 100(9):1989--2001, 2009
work page 1989
-
[25]
Generating random correlation matrices based on partial correlations
Harry Joe. Generating random correlation matrices based on partial correlations. Journal of Multivariate Analysis , 2006
work page 2006
-
[26]
Yanwei Jia and Xun Yu Zhou. Policy evaluation and temporal-difference learning in continuous time and space: A martingale approach. Journal of Machine Learning Research , 23(154):1--55, 2022
work page 2022
-
[27]
Policy gradient and actor-critic learning in continuous time and space: Theory and algorithms
Yanwei Jia and Xun Yu Zhou. Policy gradient and actor-critic learning in continuous time and space: Theory and algorithms. Journal of Machine Learning Research , 23(275):1--50, 2022
work page 2022
-
[28]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Lei Ba. Adam: A method for stochastic optimization. arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[29]
Differential learning methods for solving fully nonlinear pdes
William Lefebvre, Grégoire Loeper, and Huyên Pham. Differential learning methods for solving fully nonlinear pdes. Digital Finance , 5(1):183--229, 2023
work page 2023
-
[30]
Kai Ma and Peter A. Forsyth. An unconditionally monotone numerical scheme for the two-factor uncertain volatility model. IMA Journal of Numerical Analysis , 37(2):905--944, 2017
work page 2017
-
[31]
Jorge Nocedal and Stephen J. Wright. Numerical Optimization . Springer Series in Operations Research and Financial Engineering. Springer New York, 2006
work page 2006
-
[32]
Actor-critic learning algorithms for mean-field control with moment neural networks
Huyên Pham and Xavier Warin. Actor-critic learning algorithms for mean-field control with moment neural networks. Methodology and Computing in Applied Probability , 27(1):13, 2025
work page 2025
-
[33]
Neural networks-based backward scheme for fully nonlinear pdes
Huyên Pham, Xavier Warin, and Maximilien Germain. Neural networks-based backward scheme for fully nonlinear pdes. SN Partial Differential Equations and Applications , 2(1):16, 2021
work page 2021
-
[34]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational physics , 378:686--707, 2019
work page 2019
-
[35]
Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction . MIT press, 1998
work page 1998
-
[36]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. International conference on machine learning , pages 1889--1897, 2015
work page 2015
-
[37]
Dgm: A deep learning algorithm for solving partial differential equations
Justin Sirignano and Konstantinos Spiliopoulos. Dgm: A deep learning algorithm for solving partial differential equations. Journal of computational physics , 375:1339--1364, 2018
work page 2018
-
[38]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv:1707.06347v2, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [39]
-
[40]
Ronald J. Williams and Jing Peng. Function optimization using connectionist reinforcement learning algorithms. Connection Science , 3(3):241--268, 1991
work page 1991
-
[41]
Reinforcement learning in continuous time and space: A stochastic control approach
Haoran Wang, Thaleia Zariphopoulou, and Xun Yu Zhou. Reinforcement learning in continuous time and space: A stochastic control approach. Journal of Machine Learning Research , 21(198):1--34, 2020
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.