Recognition: 2 theorem links
· Lean TheoremOne Operator for Many Densities: Amortized Approximation of Conditioning by Neural Operators
Pith reviewed 2026-05-13 01:17 UTC · model grok-4.3
The pith
Neural operators can approximate the conditioning operator to arbitrary accuracy because it is continuous on suitable density classes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
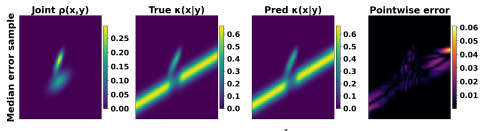
The conditioning operator maps any joint density to its conditional density and is continuous on suitable classes of densities. Neural operators can therefore approximate this operator to arbitrary accuracy. The paper illustrates the approach by learning the conditioning map for a class of Gaussian mixtures and argues that the result supplies the foundations for amortized probabilistic conditioning.
What carries the argument
The conditioning operator: the functional map from joint density p(x,y) to conditional density p(x|y), whose continuity on restricted density classes enables arbitrary approximation by neural operators.
If this is right
- A single trained neural operator can perform conditioning for many different joint distributions without retraining.
- Amortized conditioning becomes feasible for tasks that previously required a new model per joint.
- The framework supplies theoretical backing for general-purpose models that generalize Bayesian inference to new densities.
Where Pith is reading between the lines
- The same continuity argument might apply to other probabilistic operators such as marginalization.
- In practice the approach could reduce the cost of repeated uncertainty quantification in scientific workflows.
- Reusable conditioning models might serve as modular components inside larger inference pipelines.
Load-bearing premise
The joint densities are taken from classes on which the conditioning operator is continuous.
What would settle it
A concrete class of joint densities for which the map to conditionals is discontinuous, or an empirical demonstration that the approximation error of a neural operator remains bounded away from zero as capacity and training data increase.
Figures

read the original abstract
Probabilistic conditioning is concerned with the identification of a distribution of a random variable $X$ given a random variable $Y$. It is a cornerstone of scientific and engineering applications where modeling uncertainty is key. This problem has traditionally been addressed in machine learning by directly learning the conditional distribution of a fixed joint distribution. This paper introduces a novel perspective: we propose to solve the conditioning problem by identifying a single operator that maps any joint density to its conditional, thus amortizing over joint-conditional pairs. We establish that the conditioning operator can be approximated to arbitrary accuracy by neural operators. Our proof relies on new results establishing continuity of the conditioning operator over suitable classes of densities. Finally, we learn the conditioning map for a class of Gaussian mixtures using neural operators, illustrating the promise of our framework. This work provides the theoretical underpinnings for general-purpose, amortized methods for probabilistic conditioning, such as foundation models for Bayesian inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes amortizing the probabilistic conditioning problem by learning a single neural operator that maps joint densities p_{X,Y} to the corresponding conditional densities p_{X|Y}. It claims to prove that the conditioning operator is continuous on suitable classes of densities, which in turn enables arbitrary-accuracy approximation by neural operators. The approach is illustrated numerically on a class of Gaussian mixture models.
Significance. If the continuity results hold on classes that include practically relevant joint distributions (including those with marginals that can approach zero), the work would provide a rigorous foundation for general-purpose amortized conditioning models, with direct relevance to Bayesian inference and uncertainty quantification. The shift from per-joint learning to operator learning is conceptually attractive and could support foundation-model-style approaches in probabilistic modeling.
major comments (2)
- [Abstract / Theoretical results] Abstract and theoretical results section: the central claim that the conditioning operator can be approximated to arbitrary accuracy rests on new continuity results over 'suitable classes' of densities. The manuscript must explicitly define these function spaces (e.g., via specific norms or topologies) and state any lower bounds on marginal densities p_Y. Without such bounds, small L1 perturbations of the joint can induce arbitrarily large changes in the conditional when p_Y approaches zero on sets of positive measure, undermining the universal-approximation guarantee for many practical joints.
- [Theoretical results] Section presenting the continuity theorem (likely §3): the proof sketch must be expanded to show that the chosen topology on the space of joints makes the conditioning map continuous, and that the image of the operator lies in a space where neural operators are dense. If the classes exclude near-degenerate marginals, the result applies only to a restricted subclass and the claim of 'general-purpose' amortized conditioning requires qualification.
minor comments (2)
- [Experiments] The numerical illustration on Gaussian mixtures is useful but should include quantitative error metrics (e.g., Wasserstein or KL distances) across a range of conditioning values y, not only qualitative plots.
- [Introduction] Notation for the conditioning operator C should be introduced once and used consistently; currently the abstract and body alternate between descriptive phrases and operator symbols.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and describe the revisions we will make to clarify the theoretical foundations.
read point-by-point responses
-
Referee: [Abstract / Theoretical results] Abstract and theoretical results section: the central claim that the conditioning operator can be approximated to arbitrary accuracy rests on new continuity results over 'suitable classes' of densities. The manuscript must explicitly define these function spaces (e.g., via specific norms or topologies) and state any lower bounds on marginal densities p_Y. Without such bounds, small L1 perturbations of the joint can induce arbitrarily large changes in the conditional when p_Y approaches zero on sets of positive measure, undermining the universal-approximation guarantee for many practical joints.
Authors: We agree that the function spaces and assumptions on marginal densities require more explicit definition. In the revised manuscript we will add a dedicated subsection that defines the precise norms and topologies on the space of joint densities and states the lower bound p_Y >= epsilon > 0 almost everywhere that is used to guarantee continuity of the conditioning map. This will also include a brief discussion of the instability that arises without such a bound and will qualify the universal-approximation statement to the classes satisfying the bound. revision: yes
-
Referee: [Theoretical results] Section presenting the continuity theorem (likely §3): the proof sketch must be expanded to show that the chosen topology on the space of joints makes the conditioning map continuous, and that the image of the operator lies in a space where neural operators are dense. If the classes exclude near-degenerate marginals, the result applies only to a restricted subclass and the claim of 'general-purpose' amortized conditioning requires qualification.
Authors: We will expand the proof sketch in Section 3 to give a complete argument establishing continuity of the conditioning operator under the chosen topology and to verify that the image lies in a space on which neural operators are dense (citing the relevant approximation theorems). We will also add an explicit qualification that the result applies to classes excluding near-degenerate marginals and will discuss the practical scope and possible extensions. revision: yes
Circularity Check
No circularity: continuity and approximation results are independent of inputs
full rationale
The paper's central claim is that the conditioning operator is continuous on suitable classes of densities (new result) and can thus be approximated arbitrarily well by neural operators (via their universal approximation property). No equations or steps reduce a prediction or theorem to a fitted parameter or self-citation by construction. The Gaussian mixture illustration is presented separately as an empirical demonstration, not as the basis for the general theorem. The derivation chain is self-contained against external benchmarks (continuity proofs and neural operator theory).
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The conditioning operator is continuous over suitable classes of densities
invented entities (1)
-
Conditioning operator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe establish that the conditioning operator can be approximated to arbitrary accuracy by neural operators. Our proof relies on new results establishing continuity of the conditioning operator over suitable classes of densities.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearX_δ := {ρ ∈ C_ac(D×E) | inf_y m_ρ(y) ≥ δ}
Reference graph
Works this paper leans on
-
[1]
R. A. Adams and J. J. Fournier.Sobolev spaces, volume 140. Elsevier, 2 edition, 2003.(Cited on page 17)
work page 2003
-
[2]
M. Al-Jarrah, B. Hosseini, and A. Taghvaei. Fast filtering of non-Gaussian models using amortized optimal transport maps.IEEE Control Systems Letters, 2025.(Cited on page 3)
work page 2025
-
[3]
E. Bach, R. Baptista, E. Calvello, B. Chen, and A. Stuart. Learning enhanced ensemble filters. Journal of Computational Physics, art. 114550, 2025.(Cited on page 3)
work page 2025
-
[4]
K. Bhattacharya, B. Hosseini, N. B. Kovachki, and A. M. Stuart. Model reduction and neural networks for parametric PDEs.The SMAI Journal of Computational Mathematics, 7:121–157, 2021.(Cited on page 2)
work page 2021
-
[5]
K. Bhattacharya, L. Cao, G. Stepaniants, A. M. Stuart, and M. Trautner. Learning memory and material dependent constitutive laws.preprint arXiv:2502.05463, 2025.(Cited on page 5)
- [6]
- [7]
-
[8]
Fourcastnet 3: A geometric approach to probabilistic machine-learning weather forecasting at scale,
B. Bonev, T. Kurth, A. Mahesh, M. Bisson, J. Kossaifi, K. Kashinath, A. Anandkumar, W. D. Collins, M. S. Pritchard, and A. Keller. FourCastNet 3: A geometric approach to probabilistic machine-learning weather forecasting at scale.preprint arXiv:2507.12144, 2025.(Cited on page 2)
-
[9]
N. Boullé and A. Townsend. A mathematical guide to operator learning. In S. Mishra and A. Townsend, editors,Handbook of Numerical Analysis, volume 25, pages 83–125. Elsevier, 2024.(Cited on page 2)
work page 2024
-
[10]
Brezis.Functional analysis, Sobolev spaces and partial differential equations, volume 1
H. Brezis.Functional analysis, Sobolev spaces and partial differential equations, volume 1. Springer New York, NY , 2011.(Cited on pages 7, 18, and 19)
work page 2011
-
[11]
R. Brown. Function spaces and product topologies.The Quarterly Journal of Mathematics, 15 (1):238–250, 1964.(Cited on page 26)
work page 1964
-
[12]
S. Brugiapaglia, N. R. Franco, and N. H. Nelsen. A short tour of operator learning theory: Convergence rates, statistical limits, and open questions.preprint arXiv:2603.00819, 2026. (Cited on page 2)
-
[13]
E. Calvello, N. B. Kovachki, M. E. Levine, and A. M. Stuart. Continuum attention for neural operators.Journal of Machine Learning Research, 26(300):1–52, 2025.(Cited on pages 2, 9, and 27)
work page 2025
-
[14]
E. Calvello, S. Reich, and A. M. Stuart. Ensemble Kalman methods: A mean-field perspective. Acta Numerica, 34:123–291, 2025.(Cited on page 2)
work page 2025
-
[15]
E. Calvello, E. Carlson, N. Kovachki, M. N. Manta, and A. M. Stuart. Operator learning for smoothing and forecasting.preprint arXiv:2603.20359, 2026.(Cited on page 3)
- [16]
-
[17]
T. Chen and H. Chen. Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems.IEEE Transactions on Neural Networks, 6(4):911–917, 1995.(Cited on page 2)
work page 1995
- [18]
-
[19]
T. Cui, X. Feng, C. Pei, X. Wan, and T. Zhou. Amortized filtering and smoothing with conditional normalizing flows.preprint arXiv:2604.07169, 2026.(Cited on page 3)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [20]
-
[21]
L. Dinh, J. Sohl-Dickstein, and S. Bengio. Density estimation using real NVP. InInternational Conference on Learning Representations, 2017.(Cited on page 2)
work page 2017
- [22]
-
[23]
D. Fraiman. On the expressive power of contextual relations in transformers.preprint arXiv:2603.25860, 2026.(Cited on page 3)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [24]
- [25]
-
[26]
B. Geshkovski, C. Letrouit, Y . Polyanskiy, and P. Rigollet. A mathematical perspective on transformers.Bulletin of the American Mathematical Society, 62(3):427–479, 2025.(Cited on page 3)
work page 2025
-
[27]
D. Gilbarg and N. S. Trudinger.Elliptic Partial Differential Equations of Second Order. Classics in Mathematics. Springer, 2001.(Cited on page 6)
work page 2001
-
[28]
M. Gloeckler, M. Deistler, C. D. Weilbach, F. Wood, and J. H. Macke. All-in-one simulation- based inference. InInternational Conference on Machine Learning, pages 15735–15766. PMLR, 2024.(Cited on page 3)
work page 2024
-
[29]
Grafakos.Classical Fourier analysis, volume 2
L. Grafakos.Classical Fourier analysis, volume 2. Springer, 2008.(Cited on page 24)
work page 2008
-
[30]
X. Huan, J. Jagalur, and Y . Marzouk. Optimal experimental design: Formulations and computa- tions.Acta Numerica, 33:715–840, 2024.(Cited on page 2) 11
work page 2024
-
[31]
D. Z. Huang, N. H. Nelsen, and M. Trautner. An operator learning perspective on parameter-to- observable maps.Foundations of Data Science, 7(1):163–225, 2025.(Cited on page 5)
work page 2025
-
[32]
V . Ilin and P. Sushko. DiScoFormer: Plug-in density and score estimation with transformers. In International Conference on Machine Learning, 2026.(Cited on page 3)
work page 2026
-
[33]
R. Kawata and T. Suzuki. Transformers as measure-theoretic associative memory: A statistical perspective and minimax optimality.preprint arXiv:2602.01863, 2026.(Cited on page 3)
-
[34]
J. Kossaifi, N. Kovachki, Z. Li, D. Pitt, M. Liu-Schiaffini, R. J. George, B. Bonev, K. Azizzade- nesheli, J. Berner, V . Duruisseaux, and A. Anandkumar. A library for learning neural operators. preprint arXiv:2412.10354, 2025.(Cited on page 27)
-
[35]
N. B. Kovachki, Z. Li, B. Liu, K. Azizzadenesheli, K. Bhattacharya, A. M. Stuart, and A. Anand- kumar. Neural operator: Learning maps between function spaces with applications to PDEs. Journal of Machine Learning Research, 24(89):1–97, 2023.(Cited on page 2)
work page 2023
-
[36]
N. B. Kovachki, S. Lanthaler, and A. M. Stuart. Operator learning: Algorithms and analysis. In S. Mishra and A. Townsend, editors,Handbook of Numerical Analysis, volume 25, pages 419–467. Elsevier, 2024.(Cited on page 2)
work page 2024
-
[37]
T. Kurth, S. Subramanian, P. Harrington, J. Pathak, M. Mardani, D. Hall, A. Miele, K. Kashinath, and A. Anandkumar. FourCastNet: Accelerating global high-resolution weather forecasting using adaptive Fourier neural operators. InProceedings of the Platform for Advanced Scientific Computing Conference, pages 1–11, 2023.(Cited on page 2)
work page 2023
-
[38]
S. Lanthaler, S. Mishra, and G. E. Karniadakis. Error estimates for DeepONets: A deep learning framework in infinite dimensions.Transactions of Mathematics and its Applications, 6(1): tnac001, 2022.(Cited on page 2)
work page 2022
-
[39]
S. Lanthaler, Z. Li, and A. M. Stuart. Nonlocality and nonlinearity implies universality in operator learning.Constructive Approximation, 62(2):261–303, 2025.(Cited on pages 2, 4, 5, 6, 15, 16, and 18)
work page 2025
-
[40]
Le Gall.Brownian motion, martingales, and stochastic calculus, volume 274
J.-F. Le Gall.Brownian motion, martingales, and stochastic calculus, volume 274. Springer, 2016.(Cited on page 6)
work page 2016
-
[41]
Z. Li, N. B. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. M. Stuart, and A. Anand- kumar. Fourier neural operator for parametric partial differential equations. InInternational Conference on Learning Representations, 2021.(Cited on pages 2, 5, and 9)
work page 2021
-
[42]
Z. Li, D. Meunier, M. Mollenhauer, and A. Gretton. Optimal rates for regularized conditional mean embedding learning. InAdvances in Neural Information Processing Systems, volume 35, pages 4433–4445, 2022.(Cited on page 3)
work page 2022
-
[43]
Z. Li, N. Kovachki, C. Choy, B. Li, J. Kossaifi, S. Otta, M. A. Nabian, M. Stadler, C. Hundt, K. Azizzadenesheli, and A. Anandkumar. Geometry-informed neural operator for large-scale 3D PDEs. InAdvances in Neural Information Processing Systems, volume 36, pages 35836–35854, 2023.(Cited on page 2)
work page 2023
- [44]
-
[45]
L. Lu, P. Jin, G. Pang, Z. Zhang, and G. Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators.Nature Machine Intelligence, 3: 218–229, 2021.(Cited on pages 2 and 5)
work page 2021
-
[46]
L. Lyu, X. Yu, and H. Schaeffer. MVNN: A measure-valued neural network for learning McKean-Vlasov dynamics from particle data.preprint arXiv:2604.00333, 2026.(Cited on page 3)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
Y . Marzouk, T. Moselhy, M. Parno, and A. Spantini. Sampling via measure transport: An introduction.Springer Books, pages 785–825, 2017.(Cited on page 2)
work page 2017
-
[48]
Conditional Generative Adversarial Nets
M. Mirza and S. Osindero. Conditional generative adversarial nets.preprint arXiv:1411.1784, 2014.(Cited on page 2)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[49]
C. Moosmüller and A. Cloninger. Linear optimal transport embedding: Provable Wasserstein classification for certain rigid transformations and perturbations.Information and Inference: A Journal of the IMA, 12(1):363–389, 2023.(Cited on page 3) 12
work page 2023
-
[50]
N. H. Nelsen and Y . Yang. Operator learning meets inverse problems: A probabilistic perspective. In A. Hauptmann, B. Jin, and C.-B. Schönlieb, editors,Handbook of Numerical Analysis, volume 27. Elsevier, 2026.(Cited on page 2)
work page 2026
-
[51]
V . M. Panaretos and Y . Zemel.An invitation to statistics in Wasserstein space. Springer Nature, 2020.(Cited on page 3)
work page 2020
-
[52]
E. Pierret, V . Tosel, J. Delon, and A. Newson. Flow matching for applied mathematicians, 2026. (Cited on page 2)
work page 2026
- [53]
-
[54]
D. Sanz-Alonso, A. Stuart, and A. Taeb.Inverse problems and data assimilation, volume 107. Cambridge University Press, 2023.(Cited on page 2)
work page 2023
-
[55]
I. Schuster, M. Mollenhauer, S. Klus, and K. Muandet. Kernel conditional density operators. InInternational Conference on Artificial Intelligence and Statistics, pages 993–1004. PMLR, 2020.(Cited on page 3)
work page 2020
-
[56]
K. Sohn, X. Yan, and H. Lee. Learning structured output representation using deep conditional generative models. InAdvances in Neural Information Processing Systems, volume 28, 2015. (Cited on page 2)
work page 2015
-
[57]
L. Song, J. Huang, A. Smola, and K. Fukumizu. Hilbert space embeddings of conditional distributions. InInternational Conference on Machine Learning, 2009.(Cited on page 3)
work page 2009
-
[58]
A. M. Stuart. Inverse problems: A Bayesian perspective.Acta Numerica, 19:451–559, 2010. (Cited on page 2)
work page 2010
- [59]
-
[60]
X. T. Tong, Y . Wang, and L. Yan. Latent autoencoder ensemble Kalman filter for data assimila- tion.preprint arXiv:2603.06752, 2026.(Cited on page 3)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[61]
G. Whittle, J. Ziomek, J. Rawling, and M. A. Osborne. Distribution transformers: Fast approximate Bayesian inference with on-the-fly prior adaptation. InInternational Conference on Machine Learning, 2026.(Cited on page 3)
work page 2026
-
[62]
K. Wu, P. Chen, and O. Ghattas. A fast and scalable computational framework for large-scale high-dimensional Bayesian optimal experimental design.SIAM/ASA Journal on Uncertainty Quantification, 11(1):235–261, 2023.(Cited on page 2)
work page 2023
-
[63]
C. Zeng, Y . Zhang, J. Zhou, Y . Wang, Z. Wang, Y . Liu, L. Wu, and D. Z. Huang. Point cloud neural operator for parametric PDEs on complex and variable geometries.Computer Methods in Applied Mechanics and Engineering, 443:118022, 2025.(Cited on page 2) 13 Technical Appendices and Supplementary Material for: One Operator for Many Densities: Amortized Appr...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.