Recognition: no theorem link
Learning Visual Feature-Based World Models via Residual Latent Action
Pith reviewed 2026-05-11 01:31 UTC · model grok-4.3
The pith
Residual latent actions from visual feature differences let world models predict future states accurately and quickly via flow matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Residual latent actions derived from DINO feature residuals are predictive, generalizable across tasks, and encode temporal progression; modeling them with flow matching produces an accurate and efficient visual-feature world model that outperforms existing feature-based and video-diffusion alternatives while enabling entirely offline visual reinforcement learning.
What carries the argument
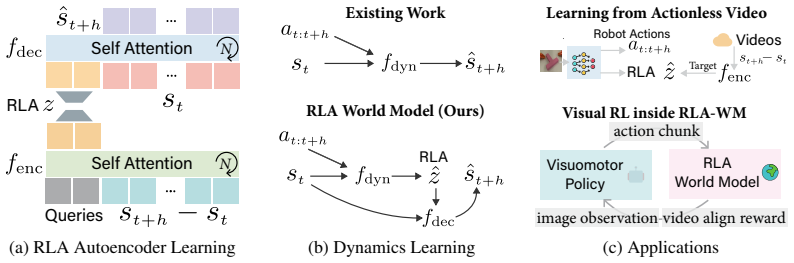
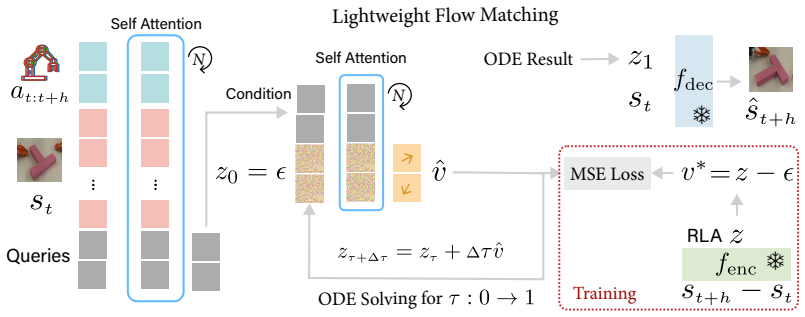
Residual Latent Action (RLA): a latent vector obtained from the residual between successive DINO visual features that is then predicted by flow matching to synthesize the next feature vector.
If this is right
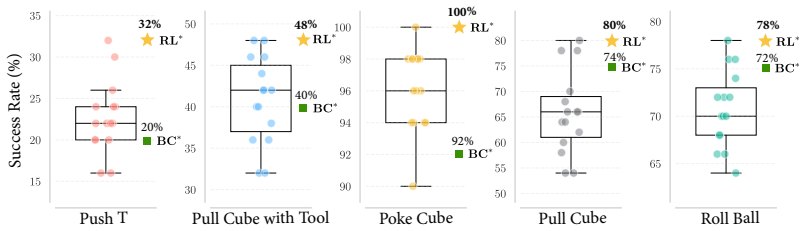
- The world model runs orders of magnitude faster than video-diffusion baselines while matching or exceeding their accuracy on both simulation and real-robot data.
- A minimalist world-action model trained with RLA can extract implicit actions from unlabeled demonstration videos.
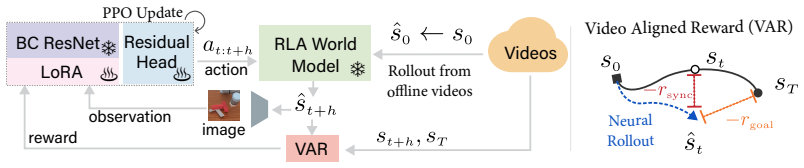
- Visual reinforcement-learning policies can be trained entirely inside the learned world model using only offline videos and a video-aligned reward, without any online interaction or handcrafted reward functions.
- Feature-space prediction avoids the hallucination problems typical of pixel-level generation while remaining more efficient than direct regression.
Where Pith is reading between the lines
- The approach may scale to large unlabeled video corpora, allowing world models to be pre-trained on internet-scale data before fine-tuning on robot tasks.
- Because RLA is compact and predictive, it could support real-time model-based planning loops inside physical robots.
- The success of residual features suggests that many existing self-supervised vision backbones already embed implicit action signals that could be reused for dynamics modeling.
Load-bearing premise
That the residuals between consecutive visual features already contain enough information about actions and dynamics to support accurate future prediction without extra supervision or task-specific tuning.
What would settle it
Run the trained RLA world model on a held-out real-robot dataset with new objects or camera angles and measure whether its predicted next-step features match the actual extracted features at least as closely as the best baseline method; a clear gap would falsify the claim.
Figures


read the original abstract
World models predict future transitions from observations and actions. Existing works predominantly focus on image generation only. Visual feature-based world models, on the other hand, predict future visual features instead of raw video pixels, offering a promising alternative that is more efficient and less prone to hallucination. However, current feature-based approaches rely on direct regression, which leads to blurry or collapsed predictions in complex interactions, while generative modeling in high-dimensional feature spaces still remains challenging. In this work, we discover that a new type of latent action representation, which we refer to as *Residual Latent Action* (RLA), can be easily learned from DINO residuals. We also show that RLA is predictive, generalizable, and encodes temporal progression. Building on RLA, we propose *RLA World Model* (RLA-WM), which predicts RLA values via flow matching. RLA-WM outperforms both state-of-the-art feature-based and video-diffusion world models on simulation and real-world datasets, while being orders of magnitude faster than video diffusion. Furthermore, we develop two robot learning techniques that use RLA-WM to improve policy learning. The first one is a minimalist world action model with RLA that learns from actionless demonstration videos. The second one is the first visual RL framework trained entirely inside a world model learned from offline videos only, using a video-aligned reward and no online interactions or handcrafted rewards. Project page: https://mlzxy.github.io/rla-wm
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Residual Latent Action (RLA), a latent representation derived from residuals between consecutive DINO visual features, and builds the RLA World Model (RLA-WM) that predicts future RLA via flow matching in feature space. It claims RLA is predictive, generalizable across tasks/environments, and encodes temporal progression, enabling RLA-WM to outperform state-of-the-art feature-based and video-diffusion world models on simulation and real-world datasets while being orders of magnitude faster. The paper further presents two robot learning applications: a minimalist world action model trained on actionless demonstration videos and the first visual RL framework trained entirely inside an offline-video-learned world model using video-aligned rewards without online interactions or handcrafted rewards.
Significance. If the empirical results and generalization claims hold, the work would offer a computationally efficient alternative to pixel-level world models for robotics, reducing hallucination risks through feature-space prediction and flow matching. The offline robot learning techniques, especially the fully model-based visual RL without online data or engineered rewards, could enable more scalable policy learning from passive video demonstrations.
major comments (3)
- Abstract: The central claims that RLA is 'predictive, generalizable, and encodes temporal progression' and that RLA-WM 'outperforms' SOTA methods are asserted without any quantitative results, baselines, ablation studies, error analysis, or dataset details in the provided text. These assertions are load-bearing for the introduction of RLA and the downstream robot learning techniques.
- Abstract: The assumption that residuals of DINO features yield meaningful latent actions (rather than photometric/viewpoint noise) is not justified or validated; DINO embeddings are optimized for static semantic discrimination, so it is unclear why their consecutive differences would reliably support causal, controllable future predictions under flow matching without additional supervision.
- Abstract: No derivation, training objective, or architectural details are supplied for how RLA is extracted or why flow matching on RLA succeeds where direct regression on features fails, leaving the claimed advantages over existing feature-based world models unsubstantiated.
minor comments (1)
- The abstract references a project page but provides no information on code, model weights, or reproducibility of the claimed results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with references to the full manuscript and indicate revisions where we strengthen the presentation.
read point-by-point responses
-
Referee: Abstract: The central claims that RLA is 'predictive, generalizable, and encodes temporal progression' and that RLA-WM 'outperforms' SOTA methods are asserted without any quantitative results, baselines, ablation studies, error analysis, or dataset details in the provided text. These assertions are load-bearing for the introduction of RLA and the downstream robot learning techniques.
Authors: The full manuscript presents these results in Sections 4 and 5, with quantitative comparisons to feature-based and diffusion baselines across simulation and real-world datasets, including ablations, error metrics, and dataset specifications. The abstract summarizes the key findings from these sections. We have revised the abstract to include a concise reference to the empirical evaluations and main datasets. revision: partial
-
Referee: Abstract: The assumption that residuals of DINO features yield meaningful latent actions (rather than photometric/viewpoint noise) is not justified or validated; DINO embeddings are optimized for static semantic discrimination, so it is unclear why their consecutive differences would reliably support causal, controllable future predictions under flow matching without additional supervision.
Authors: Section 3.1 derives RLA explicitly as the residual between consecutive DINO features and validates its properties through visualizations and experiments demonstrating that it captures temporal dynamics rather than noise. We show its predictive and generalizable nature via downstream tasks in Sections 4 and 5, where it enables effective flow-matching predictions without extra supervision. This is further supported by the success of the robot learning applications. revision: no
-
Referee: Abstract: No derivation, training objective, or architectural details are supplied for how RLA is extracted or why flow matching on RLA succeeds where direct regression on features fails, leaving the claimed advantages over existing feature-based world models unsubstantiated.
Authors: Section 3.1 details the RLA extraction as the per-frame DINO residual. Section 3.3 presents the flow-matching training objective and architecture, while Section 4.3 provides ablations showing that flow matching avoids the blurry predictions of direct regression in complex interactions. We have updated the abstract to briefly note the flow-matching formulation and its advantages. revision: partial
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper defines RLA explicitly as residuals between consecutive DINO features (an external pretrained model), then trains a separate flow-matching network to predict those RLA values for future states. This separation means the predictiveness claim is an empirical outcome of the trained model rather than a definitional tautology or a fitted parameter renamed as a prediction. No self-citation is invoked as a uniqueness theorem or load-bearing premise; DINO and flow matching are cited as independent prior work. The central claims rest on experimental validation across datasets rather than reducing to the inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Residual Latent Action (RLA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Learning to model the world: A survey of world models in artificial intelligence
Jiahua Dong, Qi Lyu, Baichen Liu, Xudong Wang, Wenqi Liang, Duzhen Zhang, Jiahang Tu, Hongliu Li, Hanbin Zhao, Henghui Ding, et al. Learning to model the world: A survey of world models in artificial intelligence. 2026
work page 2026
-
[2]
Learning interactive real-world simulators
Mengjiao Y ang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators. In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[3]
Rlvr-world: Training world models with reinforcement learning.arXiv preprint arXiv:2505.13934,
Jialong Wu, Shaofeng Yin, Ningya Feng, and Mingsheng Long. Rlvr-world: Training world models with reinforcement learning. arXiv preprint arXiv:2505.13934, 2025
-
[4]
Geometry Forcing: Marrying Video Diffusion and 3D Representation for Consistent World Modeling
Haoyu Wu, Diankun Wu, Tianyu He, Junliang Guo, Y ang Y e, Y ueqi Duan, and Jiang Bian. Ge- ometry forcing: Marrying video diffusion and 3d representation for consistent world modeling. arXiv preprint arXiv:2507.07982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Precise action-to-video generation through visual action prompts
Y uang Wang, Chao Wen, Haoyu Guo, Sida Peng, Minghan Qin, Hujun Bao, Xiaowei Zhou, and Ruizhen Hu. Precise action-to-video generation through visual action prompts. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 12713–12724, 2025
work page 2025
- [6]
-
[7]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Y u, Hangjie Y uan, Y uming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model. arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review arXiv 2025
-
[8]
Video-bench: Human-aligned video generation benchmark
Hui Han, Siyuan Li, Jiaqi Chen, Yiwen Y uan, Y uling Wu, Y ufan Deng, Chak Tou Leong, Hanwen Du, Junchen Fu, Y ouhua Li, et al. Video-bench: Human-aligned video generation benchmark. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 18858–18868, 2025
work page 2025
-
[9]
Open-sora 2.0: Training a commercial-level video generation model in $200k,
Zangwei Zheng, Xiangyu Peng, Y uxuan Lou, Chenhui Shen, Tom Y oung, Xinying Guo, Binluo Wang, Hang Xu, Hongxin Liu, Mingyan Jiang, et al. Open-sora 2.0: Training a commercial- level video generation model in $200 k. arXiv preprint arXiv:2503.09642, 2025
-
[10]
Interactive world simulator for robot policy training and evaluation, 2026
Yixuan Wang, Rhythm Syed, Fangyu Wu, Mengchao Zhang, Aykut Onol, Jose Barreiros, Hooshang Nayyeri, Tony Dear, Huan Zhang, and Y unzhu Li. Interactive world simulator for robot policy training and evaluation. arXiv preprint arXiv:2603.08546, 2026
-
[11]
GigaBrain Team, Angen Y e, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Haoyun Li, Jie Li, Jiagang Zhu, Lv Feng, et al. Gigabrain-0: A world model-powered vision- language-action model. arXiv preprint arXiv:2510.19430, 2025
-
[12]
Structured world models from human videos
Russell Mendonca, Shikhar Bahl, and Deepak Pathak. Structured world models from human videos. In Robotics: Science and Systems (RSS) , 2023
work page 2023
-
[13]
Gwm: Towards scalable gaussian world models for robotic manipulation
Guanxing Lu, Baoxiong Jia, Puhao Li, Yixin Chen, Ziwei Wang, Y ansong Tang, and Siyuan Huang. Gwm: Towards scalable gaussian world models for robotic manipulation. In Pro- ceedings of the IEEE/CVF International Conference on Computer Vision , pages 9263–9274, 2025
work page 2025
-
[14]
Yilun Du, Mengjiao Y ang, Pete Florence, Fei Xia, Ayzaan Wahid, Brian Ichter, Pierre Ser- manet, Tianhe Y u, Pieter Abbeel, Joshua B Tenenbaum, et al. Video language planning. In International Conference on Learning Representations (ICLR) , 2024
work page 2024
-
[15]
Planning with reasoning using vision language world model.arXiv preprint arXiv:2509.02722, 2025
Delong Chen, Theo Moutakanni, Willy Chung, Y ejin Bang, Ziwei Ji, Allen Bolourchi, and Pascale Fung. Planning with reasoning using vision language world model. arXiv preprint arXiv:2509.02722, 2025
-
[16]
Dino-wm: World models on pre- trained visual features enable zero-shot planning
Gaoyue Zhou, Hengkai Pan, Y ann LeCun, and Lerrel Pinto. Dino-wm: World models on pre- trained visual features enable zero-shot planning. In International Conference on Machine Learning (ICML), 2025. 10
work page 2025
-
[17]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V -jepa 2: Self-supervised video models enable understanding, prediction and planning. arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Using goal-driven deep learning models to understand sensory cortex
Daniel LK Y amins and James J DiCarlo. Using goal-driven deep learning models to understand sensory cortex. Nature neuroscience, 19(3):356–365, 2016
work page 2016
-
[19]
Simulation as an en- gine of physical scene understanding
Peter W Battaglia, Jessica B Hamrick, and Joshua B Tenenbaum. Simulation as an en- gine of physical scene understanding. Proceedings of the national academy of sciences , 110(45):18327–18332, 2013
work page 2013
-
[20]
Sparse imagination for efficient visual world model planning
Junha Chun, Y oungjoon Jeong, and Taesup Kim. Sparse imagination for efficient visual world model planning. arXiv preprint arXiv:2506.01392, 2025
-
[21]
Back to the features: Dino as a foundation for video world models.arXiv preprint arXiv:2507.19468,
Federico Baldassarre, Marc Szafraniec, Basile Terver, V asil Khalidov, Francisco Massa, Y ann LeCun, Patrick Labatut, Maximilian Seitzer, and Piotr Bojanowski. Back to the features: Dino as a foundation for video world models. arXiv preprint arXiv:2507.19468, 2025
-
[22]
Rethinking diffusion model in high dimension
Zhenxin Zheng and Zhenjie Zheng. Rethinking diffusion model in high dimension. arXiv preprint arXiv:2503.08643, 2025
-
[23]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representation autoencoders. arXiv preprint arXiv:2510.11690, 2025
work page internal anchor Pith review arXiv 2025
-
[24]
Adaworld: Learning adaptable world models with latent actions
Shenyuan Gao, Siyuan Zhou, Yilun Du, Jun Zhang, and Chuang Gan. Adaworld: Learning adaptable world models with latent actions. In International Conference on Machine Learning (ICML), 2025
work page 2025
-
[25]
Motus: A Unified Latent Action World Model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Y ao Feng, Chendong Xiang, Yinze Rong, et al. Motus: A unified latent action world model. arXiv preprint arXiv:2512.13030, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
3d-vla: A 3d vision-language-action generative world model
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Y ang, Xin Y an, Yilun Du, Yining Hong, and Chuang Gan. 3d-vla: A 3d vision-language-action generative world model. In Interna- tional Conference on Machine Learning (ICML) , 2024
work page 2024
-
[27]
Manigaussian++: General robotic bi- manual manipulation with hierarchical gaussian world model
Tengbo Y u, Guanxing Lu, Zaijia Y ang, Haoyuan Deng, Season Si Chen, Jiwen Lu, Wenbo Ding, Guoqiang Hu, Y ansong Tang, and Ziwei Wang. Manigaussian++: General robotic bi- manual manipulation with hierarchical gaussian world model. In 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages 12232–12239. IEEE, 2025
work page 2025
-
[28]
Wenlong Huang, Y u-Wei Chao, Arsalan Mousavian, Ming-Y u Liu, Dieter Fox, Kaichun Mo, and Li Fei-Fei. Pointworld: Scaling 3d world models for in-the-wild robotic manipulation. arXiv preprint arXiv:2601.03782, 2026
- [29]
-
[30]
Ying Chai, Litao Deng, Ruizhi Shao, Jiajun Zhang, Kangchen Lv, Liangjun Xing, Xiang Li, Hongwen Zhang, and Y ebin Liu. Gaf: Gaussian action field as a 4d representation for dynamic world modeling in robotic manipulation. arXiv preprint arXiv:2506.14135, 2025
-
[31]
Chenhao Li, Andreas Krause, and Marco Hutter. Robotic world model: A neural network simulator for robust policy optimization in robotics. arXiv preprint arXiv:2501.10100, 2025
-
[32]
Seo, Y ., Sferrazza, C., Chen, J., Shi, G., Duan, R., and Abbeel, P
SV Jyothir, Siddhartha Jalagam, Y ann LeCun, and Vlad Sobal. Gradient-based planning with world models. arXiv preprint arXiv:2312.17227, pages 703–708, 2023
-
[33]
Td-mpc2: Scalable, robust world models for continuous control
Nicklas Hansen, Hao Su, and Xiaolong Wang. Td-mpc2: Scalable, robust world models for continuous control. In International Conference on Learning Representations (ICLR) , 2024
work page 2024
-
[34]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse do- mains through world models. arXiv preprint arXiv:2301.04104, 2023. 11
work page internal anchor Pith review arXiv 2023
-
[35]
Training agents inside of scalable world models,
Danijar Hafner, Wilson Y an, and Timothy Lillicrap. Training agents inside of scalable world models. arXiv preprint arXiv:2509.24527, 2025
-
[36]
Pwm: Policy learn- ing with multi-task world models
Ignat Georgiev, V arun Giridhar, Nicklas Hansen, and Animesh Garg. Pwm: Policy learn- ing with multi-task world models. In International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[37]
arXiv preprint arXiv:2603.14482 (2026)
Lorenzo Mur-Labadia, Matthew Muckley, Amir Bar, Mido Assran, Koustuv Sinha, Mike Rab- bat, Y ann LeCun, Nicolas Ballas, and Adrien Bardes. V -jepa 2.1: Unlocking dense features in video self-supervised learning. arXiv preprint arXiv:2603.14482, 2026
-
[38]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, V asil Khali- dov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, V asil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
What do latent action models actually learn?arXiv preprint arXiv:2506.15691, 2025
Chuheng Zhang, Tim Pearce, Pushi Zhang, Kaixin Wang, Xiaoyu Chen, Wei Shen, Li Zhao, and Jiang Bian. What do latent action models actually learn? arXiv preprint arXiv:2506.15691, 2025
-
[41]
Flare: Robot learning with implicit world modeling, 2025
Ruijie Zheng, Jing Wang, Scott Reed, Johan Bjorck, Y u Fang, Fengyuan Hu, Joel Jang, Kaushil Kundalia, Zongyu Lin, Loic Magne, et al. Flare: Robot learning with implicit world modeling. arXiv preprint arXiv:2505.15659, 2025
-
[42]
Latent action pretraining from videos
Seonghyeon Y e, Joel Jang, Byeongguk Jeon, Sejune Joo, Jianwei Y ang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Y u-Wei Chao, Bill Y uchen Lin, et al. Latent action pretraining from videos. In International Conference on Learning Representations (ICLR) , 2025
work page 2025
-
[43]
Latent action pretraining through world modeling.arXiv preprint arXiv:2509.18428, 2025
Bahey Tharwat, Y ara Nasser, Ali Abouzeid, and Ian Reid. Latent action pretraining through world modeling. arXiv preprint arXiv:2509.18428, 2025
-
[44]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Y anting Y ang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Y ao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions. arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review arXiv 2025
-
[45]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Y am Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. In F orty-first international conference on machine learning, 2024
work page 2024
-
[46]
Diffusion schrödinger bridge matching
Y uyang Shi, V alentin De Bortoli, Andrew Campbell, and Arnaud Doucet. Diffusion schrödinger bridge matching. Advances in neural information processing systems , 36:62183– 62223, 2023
work page 2023
-
[47]
Schrodinger bridge flow for unpaired data translation
V alentin De Bortoli, Iryna Korshunova, Andriy Mnih, and Arnaud Doucet. Schrodinger bridge flow for unpaired data translation. Advances in Neural Information Processing Systems, 37:103384–103441, 2024
work page 2024
-
[48]
Crom: Continuous reduced-order modeling of pdes using implicit neural representations,
Peter Yichen Chen, Jinxu Xiang, Dong Heon Cho, Y ue Chang, GA Pershing, Henrique Teles Maia, Maurizio M Chiaramonte, Kevin Carlberg, and Eitan Grinspun. Crom: Continu- ous reduced-order modeling of pdes using implicit neural representations. arXiv preprint arXiv:2206.02607, 2022
-
[49]
Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations
Tongzhou Mu, Zhan Ling, Fanbo Xiang, Derek Cathera Y ang, Xuanlin Li, Stone Tao, Zhiao Huang, Zhiwei Jia, and Hao Su. Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations. In Thirty-fifth Conference on Neural Information Processing Sys- tems Datasets and Benchmarks Track (Round 2)
-
[50]
Flow matching for generative modeling
Y aron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. In The Eleventh International Conference on Learning Representations. 12
-
[51]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 586–595, 2018
work page 2018
-
[52]
Image quality assessment: from error visibility to structural similarity
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4):600– 612, 2004
work page 2004
-
[53]
Dynamicrafter: Animating open-domain images with video diffusion priors
Jinbo Xing, Menghan Xia, Y ong Zhang, Haoxin Chen, Wangbo Y u, Hanyuan Liu, Gongye Liu, Xintao Wang, Ying Shan, and Tien-Tsin Wong. Dynamicrafter: Animating open-domain images with video diffusion priors. In European Conference on Computer Vision , pages 399–
-
[54]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
work page 2015
-
[55]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
Tianyuan Y uan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination? arXiv preprint arXiv:2603.16666, 2026
work page internal anchor Pith review arXiv 2026
-
[56]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 770–778, 2016
work page 2016
-
[57]
Neural discrete representation learning
Aaron V an Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. Advances in neural information processing systems , 30, 2017
work page 2017
-
[58]
David Ha and Jürgen Schmidhuber. World models. arXiv preprint arXiv:1803.10122, 2(3):440, 2018
work page internal anchor Pith review arXiv 2018
-
[59]
Jacob Berg, Chuning Zhu, Y anda Bao, Ishan Durugkar, and Abhishek Gupta. Semantic world models. arXiv preprint arXiv:2510.19818, 2025
-
[60]
Temporal difference learning for model predictive control.arXiv preprint arXiv:2203.04955,
Nicklas Hansen, Xiaolong Wang, and Hao Su. Temporal difference learning for model predic- tive control. arXiv preprint arXiv:2203.04955, 2022
-
[61]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning, pages 1861–1870. PMLR, 2018
work page 2018
-
[62]
Reinforcement learning with action chunking
Qiyang Li, Zhiyuan Zhou, and Sergey Levine. Reinforcement learning with action chunking. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[63]
Top- erl: Transformer-based off-policy episodic reinforcement learning
Ge Li, Dong Tian, Hongyi Zhou, Xinkai Jiang, Rudolf Lioutikov, and Gerhard Neumann. Top- erl: Transformer-based off-policy episodic reinforcement learning
-
[64]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[65]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv:2005.01643, 2020
work page internal anchor Pith review arXiv 2005
-
[66]
Is behavior cloning all you need? under- standing horizon in imitation learning
Dylan J Foster, Adam Block, and Dipendra Misra. Is behavior cloning all you need? under- standing horizon in imitation learning. Advances in Neural Information Processing Systems , 37:120602–120666, 2024
work page 2024
-
[67]
Deep reinforcement learning that matters
Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, and David Meger. Deep reinforcement learning that matters. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[68]
Simple random search provides a competitive approach to reinforcement learning
Horia Mania, Aurelia Guy, and Benjamin Recht. Simple random search provides a competitive approach to reinforcement learning. arXiv preprint arXiv:1803.07055, 2018
-
[69]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations. 13
-
[70]
Structured 3d latents for scalable and versatile 3d generation
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Y u Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Y ang. Structured 3d latents for scalable and versatile 3d generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 21469–21480, 2025
work page 2025
-
[71]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research , 44(10-11):1684–1704, 2025
work page 2025
-
[72]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation. arXiv preprint arXiv:1506.02438, 2015. 14 A Appendix A.1 Code The source code of our work is included in the supplementary folder Code. Please see Code/README.md for instructions on installation, dat...
work page internal anchor Pith review arXiv 2015
-
[73]
Our RLA is learned from residuals between pairs of DINO tokens (st, st+h)
Background and random motion. Our RLA is learned from residuals between pairs of DINO tokens (st, st+h). However, task-irrelevant background motion or workspace randomness (e.g., in humanoid robot or eye-in-hand camera) can also cause visual changes between st and st+h. Learning to encode those randomness-driven motions could waste representation capacity...
-
[74]
Memory and partial observability. Our RLA-WM predicts st+h from st and at:t+h, yet changes may depend on s<t due to occlusion (e.g., an object disappears and reappears). Because RLA z is learned from a single frame pair, it must memorize the object in the latent space rather than encoding true movement and occlusion events. Extending RLA to condition on m...
-
[75]
Our RLA-WM predicts only visual state evolution via RLA, but not future proprioceptive states
Proprioceptive world model. Our RLA-WM predicts only visual state evolution via RLA, but not future proprioceptive states. Proprioception input has been shown to be useful for policy learning. Extending the world model to predict both would broaden applicability
-
[76]
Scaling to larger datasets. We deliberately evaluated on small-scale ManiSkill and IWS datasets to isolate method-driven gains from mere data scaling — many prior works scale first and leave it unclear whether improvements come from data volume or the method itself. Our clear, reproducible results on small data demonstrate the core properties of RLA and RL...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.