Recognition: 2 theorem links
· Lean TheoremCASCADE: Context-Aware Relaxation for Speculative Image Decoding
Pith reviewed 2026-05-11 02:05 UTC · model grok-4.3
The pith
By identifying semantic redundancies in hidden states, CASCADE relaxes token acceptance in tree-based speculative decoding to deliver up to 3.6x faster image generation without quality loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CASCADE formalizes semantic interchangeability and convergence as properties that emerge from redundancies in the target model's hidden states during tree-based speculative decoding. These properties permit context-aware acceptance relaxation that increases accepted tokens without degrading image quality or text-prompt fidelity. The same redundancy signals are injected into drafter training with only minimal changes, producing a combined system that achieves up to 3.6x acceleration across multiple text-to-image models and drafter architectures.
What carries the argument
Context-aware acceptance relaxation that detects semantic interchangeability and convergence opportunities in the hidden-state redundancies of the target model across the speculative token tree.
If this is right
- Drafter models achieve higher acceptance rates after receiving injected redundancy signals from the target model.
- Speedups reach up to 3.6x while image quality and prompt fidelity remain unchanged.
- No additional training of the target model is required to obtain the relaxation benefits.
- The approach works across multiple text-to-image architectures and drafter designs.
Where Pith is reading between the lines
- The same redundancy patterns could appear in video or 3D generation, allowing similar relaxation techniques in those domains.
- Combining CASCADE with quantization or caching could produce further latency reductions in deployed systems.
- The method's reliance on tree depth and breadth suggests it may scale differently on very large models where hidden-state correlations change.
- Real-time interactive image tools might become feasible once generation latency drops by the reported factors.
Load-bearing premise
The assumption that semantic interchangeability and convergence properties emerge reliably in tree-based speculative decoding for images and permit acceptance relaxation without degrading output quality or fidelity across models.
What would settle it
Applying the relaxation rules to a new text-to-image model and drafter pair and measuring either a drop in standard image-quality metrics such as FID or CLIP similarity to the prompt, or failure to exceed the speedup of standard speculative decoding.
Figures













read the original abstract
Autoregressive generation is a powerful approach for high-fidelity image synthesis, but it remains computationally demanding and slow even on the most advanced accelerators. While speculative decoding has been explored to mitigate this bottleneck, existing approaches fail to achieve efficiency gains comparable to those observed in text generation. A key limitation is the target model's high uncertainty during image generation, which leads to high draft token rejection rates. In this work, we identify previously overlooked patterns in the target model's behavior that emerge naturally in tree-based speculative decoding. Specifically, we formalize two properties, semantic interchangeability and convergence, arising from the redundancies in the target model's hidden state representations. By capturing these redundancies across the depth and breadth of the predicted token tree, our method identifies principled opportunities for acceptance relaxation without requiring additional training. Additionally, we enhance standalone drafter performance by injecting the redundancy signals from the target model into drafter training with minimal modification. We evaluate our approach across multiple text-to-image models and drafter architectures. Results show that CASCADE achieves state-of-the-art speedups for drafter-based speculative decoding, with up to 3.6x acceleration, while maintaining image quality and text-prompt fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CASCADE, a method for speculative decoding in autoregressive image synthesis. It formalizes two properties—semantic interchangeability and convergence—arising from redundancies in the target model's hidden states during tree-based decoding. These enable relaxed acceptance criteria without retraining. The drafter is further improved by injecting target-model redundancy signals during training. Evaluations across text-to-image models and drafter architectures claim state-of-the-art speedups of up to 3.6x while preserving image quality and text-prompt fidelity.
Significance. If the empirical claims and underlying properties hold under broader conditions, the work addresses a genuine efficiency bottleneck in high-fidelity image generation and could make autoregressive models more practical for deployment. The approach is notable for deriving relaxation opportunities from observed model behavior rather than introducing fitted parameters or extra training, which strengthens its potential generality if the properties prove robust.
major comments (2)
- [Method and Experiments] The central speedup and quality-maintenance claims rest on the reliable emergence of semantic interchangeability and convergence for safe acceptance relaxation. However, the manuscript provides no explicit bounds, failure-mode analysis, or conditions under which these properties hold, particularly for spatially varying uncertainty and long-range dependencies in image token sequences. This is load-bearing for the SOTA claim and requires additional validation in the method and experiments sections.
- [Abstract and Experiments] The abstract and results report up to 3.6x acceleration with maintained quality but supply no quantitative details on exact baselines, acceptance rates, variance across runs, statistical tests, or precise acceptance criteria. Without these, it is not possible to verify that the observed speedups are robust or that relaxation decisions do not introduce artifacts or prompt drift.
minor comments (1)
- [Abstract] The abstract could be expanded with at least one concrete metric (e.g., average acceptance rate or FID delta) to better support the empirical claims before the full results section.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will incorporate revisions to strengthen the empirical grounding and reporting of our results.
read point-by-point responses
-
Referee: [Method and Experiments] The central speedup and quality-maintenance claims rest on the reliable emergence of semantic interchangeability and convergence for safe acceptance relaxation. However, the manuscript provides no explicit bounds, failure-mode analysis, or conditions under which these properties hold, particularly for spatially varying uncertainty and long-range dependencies in image token sequences. This is load-bearing for the SOTA claim and requires additional validation in the method and experiments sections.
Authors: We agree that the manuscript would benefit from a more explicit discussion of the conditions under which semantic interchangeability and convergence reliably appear. Our formalization derives these properties directly from observed redundancies in the target model's hidden-state representations during tree-based speculative decoding, but we do not provide theoretical bounds that hold for arbitrary sequences. In the revised version we will add a dedicated subsection in the Method section that articulates the empirically observed conditions (including the role of spatial uncertainty and token-sequence length) and will include new experiments in the Experiments section that systematically examine long-range dependencies and potential failure cases where relaxation could introduce risk. These additions will directly support the robustness of the reported speedups. revision: yes
-
Referee: [Abstract and Experiments] The abstract and results report up to 3.6x acceleration with maintained quality but supply no quantitative details on exact baselines, acceptance rates, variance across runs, statistical tests, or precise acceptance criteria. Without these, it is not possible to verify that the observed speedups are robust or that relaxation decisions do not introduce artifacts or prompt drift.
Authors: We acknowledge that the current reporting lacks sufficient granularity for full verification. While the manuscript already compares against standard speculative-decoding baselines and states the overall speedup, we agree that exact baseline configurations, per-model acceptance rates, run-to-run variance, statistical tests, and a precise statement of the acceptance criteria are necessary. In the revision we will expand the abstract to reference the specific baselines used and will augment the Experiments section with tables reporting average acceptance rates, standard deviations across repeated runs, statistical significance results where appropriate, and a clear description of the context-aware relaxation thresholds. We will also add quantitative metrics for image quality, prompt fidelity, and any measurable artifacts or drift to confirm that relaxation decisions preserve output integrity. revision: yes
Circularity Check
No circularity; derivation rests on empirical observation and formalization of emergent patterns without reduction to fitted inputs or self-citations.
full rationale
The paper observes behavioral patterns (redundancies in hidden states) during tree-based speculative decoding for images, formalizes them as semantic interchangeability and convergence, then applies the formalization to relax acceptance criteria and inject signals into drafter training. These steps are presented as arising naturally from the target model's behavior rather than being defined in terms of the target speedup metric or quality scores. The reported 3.6x acceleration is an empirical outcome from evaluation across models, not a quantity forced by construction from the authors' own parameters or prior self-citations. No load-bearing equation or premise reduces to a self-definition, renamed known result, or fitted-input prediction. The central claims remain independent of the inputs they are derived from.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
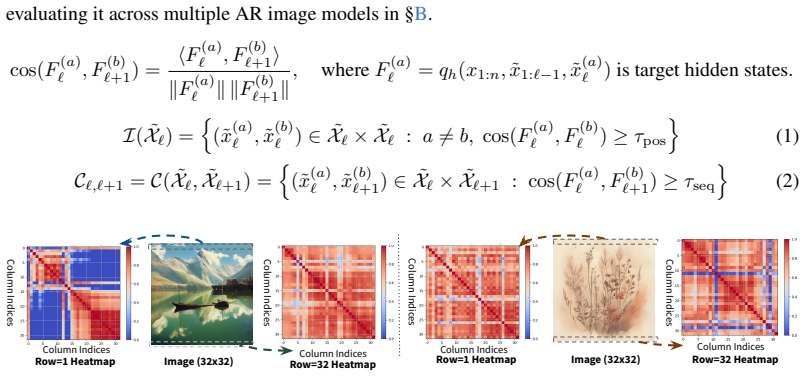
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearwe formalize two properties, semantic interchangeability and convergence, arising from the redundancies in the target model’s hidden state representations... cos(F(a)ℓ,F(b)ℓ)≥τpos
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearrelaxed distribution qR... TVD(qR,q)≤δ=0.5
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster, 2023. URLhttps://arxiv.org/abs/2210.09461. 2
work page internal anchor Pith review arXiv 2023
-
[4]
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads.arXiv preprint arXiv:2401.10774, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[5]
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T. Freeman. Maskgit: Masked generative image transformer.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11305–11315, 2022. URLhttps://api.semanticscholar.org/CorpusID:246680316. 3
work page 2022
-
[6]
Accelerating Large Language Model Decoding with Speculative Sampling
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318,
work page internal anchor Pith review arXiv
-
[7]
Generative pretraining from pixels
Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. Generative pretraining from pixels. InInternational conference on machine learning, pages 1691–1703. PMLR, 2020. 3
work page 2020
-
[8]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling, 2025. URLhttps://arxiv.org/abs/2501.17811. 1, 3
work page internal anchor Pith review arXiv 2025
-
[9]
Collaborative decoding makes visual auto- regressive modeling efficient
Zigeng Chen, Xinyin Ma, Gongfan Fang, and Xinchao Wang. Collaborative decoding makes visual auto- regressive modeling efficient. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23334–23344, 2025. 3
work page 2025
-
[10]
Anole: An open, autoregressive, native large multimodal models for interleaved image-text generation
Ethan Chern, Jiadi Su, Yan Ma, and Pengfei Liu. Anole: An open, autoregressive, native large multimodal models for interleaved image-text generation, 2024. URL https://arxiv.org/abs/2407.06135. 3, 13
-
[11]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, et al. Cosyvoice 2: Scalable streaming speech synthesis with large language models.arXiv preprint arXiv:2412.10117, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[12]
Generative Adversarial Networks
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks, 2014. URL https://arxiv.org/abs/ 1406.2661. 3
work page internal anchor Pith review arXiv 2014
-
[13]
Mars: Mixture of auto-regressive models for fine-grained text-to-image synthesis
Wanggui He, Siming Fu, Mushui Liu, Xierui Wang, Wenyi Xiao, Fangxun Shu, Yi Wang, Lei Zhang, Zhelun Yu, Haoyuan Li, et al. Mars: Mixture of auto-regressive models for fine-grained text-to-image synthesis. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 17123–17131,
-
[14]
Yefei He, Feng Chen, Yuanyu He, Shaoxuan He, Hong Zhou, Kaipeng Zhang, and Bohan Zhuang. Zipar: Parallel auto-regressive image generation through spatial locality, 2025. URLhttps://arxiv.org/abs/ 2412.04062. 3
-
[15]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning, 2022. URLhttps://arxiv.org/abs/2104.08718. 7
work page internal anchor Pith review arXiv 2022
-
[16]
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium, 2018. URL https://arxiv. org/abs/1706.08500. 7 10
work page Pith review arXiv 2018
-
[17]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 3
work page 2020
-
[18]
Improving autoregressive visual generation with cluster-oriented token prediction, 2025
Teng Hu, Jiangning Zhang, Ran Yi, Jieyu Weng, Yabiao Wang, Xianfang Zeng, Zhucun Xue, and Lizhuang Ma. Improving autoregressive visual generation with cluster-oriented token prediction, 2025. URL https://arxiv.org/abs/2501.00880. 3
-
[19]
Doohyuk Jang, Sihwan Park, June Yong Yang, Yeonsung Jung, Jihun Yun, Souvik Kundu, Sung-Yub Kim, and Eunho Yang. Lantern: Accelerating visual autoregressive models with relaxed speculative decoding. arXiv preprint arXiv:2410.03355, 2024. 2, 3, 7, 15
-
[20]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR, 2023. 3
work page 2023
-
[22]
Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. Autoregressive image generation without vector quantization.Advances in Neural Information Processing Systems, 37:56424–56445, 2024. 3
work page 2024
-
[23]
Autoregressive Image Generation Without Vector Quantization
Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. Autoregressive image generation without vector quantization, 2024. URLhttps://arxiv.org/abs/2406.11838. 3
-
[24]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty.arXiv preprint arXiv:2401.15077, 2024. 3, 7, 13
-
[25]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-2: Faster inference of language models with dynamic draft trees.arXiv preprint arXiv:2406.16858, 2024. 3
-
[26]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-3: Scaling up inference acceleration of large language models via training-time test.arXiv preprint arXiv:2503.01840, 2025. 3, 9, 13
-
[27]
Microsoft COCO: Common Objects in Context
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context, 2015. URLhttps://arxiv.org/abs/1405.0312. 7
work page internal anchor Pith review arXiv 2015
-
[28]
Dongyang Liu, Shitian Zhao, Le Zhuo, Weifeng Lin, Yi Xin, Xinyue Li, Qi Qin, Yu Qiao, Hongsheng Li, and Peng Gao. Lumina-mgpt: Illuminate flexible photorealistic text-to-image generation with multimodal generative pretraining.arXiv preprint arXiv:2408.02657, 2024. 1, 3
-
[29]
Unified-io 2: Scaling autoregressive multimodal models with vision language audio and action
Jiasen Lu, Christopher Clark, Sangho Lee, Zichen Zhang, Savya Khosla, Ryan Marten, Derek Hoiem, and Aniruddha Kembhavi. Unified-io 2: Scaling autoregressive multimodal models with vision language audio and action. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26439–26455, 2024. 3
work page 2024
-
[30]
Towards better & faster autoregressive image generation: From the perspective of entropy,
Xiaoxiao Ma, Feng Zhao, Pengyang Ling, Haibo Qiu, Zhixiang Wei, Hu Yu, Jie Huang, Zhixiong Zeng, and Lin Ma. Towards better & faster autoregressive image generation: From the perspective of entropy,
- [31]
-
[32]
Token-shuffle: Towards high-resolution image generation with autoregressive models
Xu Ma, Peize Sun, Haoyu Ma, Hao Tang, Chih-Yao Ma, Jialiang Wang, Kunpeng Li, Xiaoliang Dai, Yujun Shi, Xuan Ju, Yushi Hu, Artsiom Sanakoyeu, Felix Juefei-Xu, Ji Hou, Junjiao Tian, Tao Xu, Tingbo Hou, Yen-Cheng Liu, Zecheng He, Zijian He, Matt Feiszli, Peizhao Zhang, Peter Vajda, Sam Tsai, and Yun Fu. Token-shuffle: Towards high-resolution image generatio...
-
[33]
Sihwan Park, Doohyuk Jang, Sungyub Kim, Souvik Kundu, and Eunho Yang. Lantern++: Enhancing relaxed speculative decoding with static tree drafting for visual auto-regressive models.arXiv preprint arXiv:2502.06352, 2025. 2, 3, 7, 15
-
[34]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. URL https://arxiv.org/abs/ 2103.00020. 15
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InInternational conference on machine learning, pages 8821–8831. Pmlr, 2021. 3 11
work page 2021
-
[36]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 3
work page 2022
-
[37]
Tokenlearner: Adaptive space-time tokenization for videos
Michael Ryoo, AJ Piergiovanni, Anurag Arnab, Mostafa Dehghani, and Anelia Angelova. Tokenlearner: Adaptive space-time tokenization for videos. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 12786–12797. Curran Associates, Inc., 2021. URL https://pr...
work page 2021
-
[38]
Grouped speculative decoding for autoregressive image generation, 2025
Junhyuk So, Juncheol Shin, Hyunho Kook, and Eunhyeok Park. Grouped speculative decoding for autoregressive image generation, 2025. URLhttps://arxiv.org/abs/2508.07747. 2, 3, 7, 15
-
[39]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autore- gressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525,
work page internal anchor Pith review arXiv
-
[40]
Rethinking the inception architecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision, 2015. URL https://arxiv.org/abs/1512.00567. 15
-
[41]
Yao Teng, Han Shi, Xian Liu, Xuefei Ning, Guohao Dai, Yu Wang, Zhenguo Li, and Xihui Liu. Accelerating auto-regressive text-to-image generation with training-free speculative jacobi decoding, 2025. URL https://arxiv.org/abs/2410.01699. 3
-
[42]
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024. 3
work page 2024
-
[43]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Neural discrete representation learning,
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning,
-
[45]
URLhttps://arxiv.org/abs/1711.00937. 2
-
[46]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023. URL https://arxiv.org/abs/1706. 03762. 1
work page 2023
-
[47]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[48]
Parallelized autoregressive visual generation, 2025
Yuqing Wang, Shuhuai Ren, Zhijie Lin, Yujin Han, Haoyuan Guo, Zhenheng Yang, Difan Zou, Jiashi Feng, and Xihui Liu. Parallelized autoregressive visual generation, 2025. URL https://arxiv.org/abs/ 2412.15119. 3
-
[49]
Zili Wang, Robert Zhang, Kun Ding, Qi Yang, Fei Li, and Shiming Xiang. Continuous speculative decoding for autoregressive image generation.arXiv preprint arXiv:2411.11925, 2024. 3
-
[50]
VideoGPT: Video Generation using VQ-VAE and Transformers
Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. Videogpt: Video generation using vq-vae and transformers.arXiv preprint arXiv:2104.10157, 2021. 3
work page internal anchor Pith review arXiv 2021
-
[51]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, Ben Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge, and Yonghui Wu. Scaling autoregressive models for content-rich text-to-image generation, 2022. URLhttps://arxiv.org/abs/2206.10789. 7
work page internal anchor Pith review arXiv 2022
-
[52]
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Lijun Yu, José Lezama, Nitesh B. Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Vighnesh Birodkar, Agrim Gupta, Xiuye Gu, Alexander G. Hauptmann, Boqing Gong, Ming-Hsuan Yang, Irfan Essa, David A. Ross, and Lu Jiang. Language model beats diffusion – tokenizer is key to visual generation, 2024. URLhttps://arxiv.org/abs/2310.05737. 2
work page internal anchor Pith review arXiv 2024
-
[53]
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 3 12 A Limitations and Future Work A key limitation of our approach is that it does no...
work page 2023
-
[54]
We build on the standard verification algorithm 1 commonly used in drafter architectures [ 24– 26]. Essentially, the dynamic cosine-similarity measurements of semantic interchangeability and convergence appear in Line 9 and 14, respectively. The relaxation constraints τpos and τseq are percentage-based cosine-similarity thresholds within the interval [0,1...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.