Recognition: no theorem link
Experience Sharing in Mutual Reinforcement Learning for Heterogeneous Language Models
Pith reviewed 2026-05-11 01:55 UTC · model grok-4.3
The pith
Outcome-level experience sharing occupies the favorable point on the stability-support trade-off when heterogeneous language models exchange typed experiences during mutual reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that, across the three sharing mechanisms they instantiate, outcome-level success transfer supplies a rescue-set score direction toward verified peer successes and thereby occupies the favorable point on the stability-support trade-off, while data-level sharing incurs density-ratio variance plus residual retokenization costs and value-level sharing alters scalar baselines while preserving on-policy actor support.
What carries the argument
The stability-support trade-off in experience sharing, instantiated by the three probes (Peer Rollout Pooling, Cross-Policy GRPO Advantage Sharing, and Success-Gated Transfer) and enabled by the Tokenizer Heterogeneity Layer that retokenizes text and aligns traces across vocabularies.
Load-bearing premise
The Tokenizer Heterogeneity Layer can retokenize text and align token-level traces across incompatible vocabularies with acceptable residual costs.
What would settle it
Running the same three probes on a new pair of models with incompatible vocabularies and finding that data-level or value-level sharing produces both higher stability and higher support than outcome-level sharing would falsify the claim that outcome-level sharing is favorable in the evaluated regime.
Figures




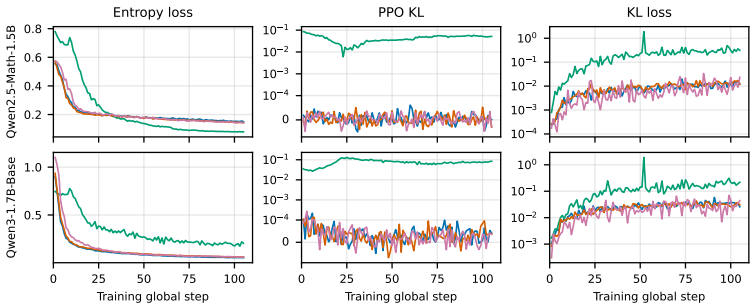

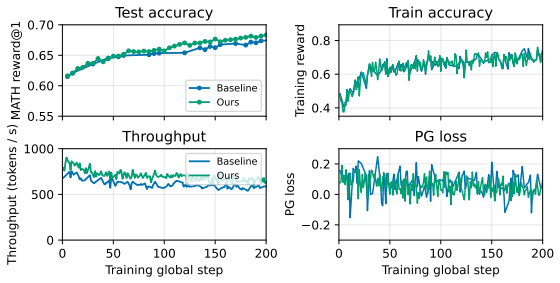

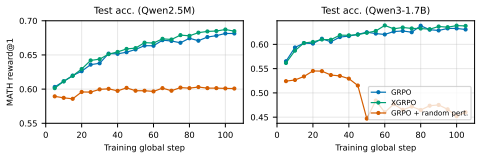



read the original abstract
We introduce Mutual Reinforcement Learning, a framework for concurrent RL post-training in which heterogeneous LLM policies exchange typed experience while keeping separate parameters, objectives, and tokenizers. The framework combines a Shared Experience Exchange (SEE), Multi-Worker Resource Allocation (MWRA), and a Tokenizer Heterogeneity Layer (THL) that retokenizes text and aligns token-level traces across incompatible vocabularies. This substrate makes the experience-sharing design question operational across model families. We instantiate three controlled probes on top of GRPO: data-level rollout sharing via Peer Rollout Pooling (PRP), value-level advantage sharing via Cross-Policy GRPO Advantage Sharing (XGRPO), and outcome-level success transfer via Success-Gated Transfer (SGT). A contextual-bandit analysis characterizes their structural positions on a stability-support trade-off: PRP pays density-ratio variance and THL residual costs, XGRPO preserves on-policy actor support while changing scalar baselines, and SGT supplies a rescue-set score direction toward verified peer successes. In the evaluated regime, outcome-level sharing occupies the favorable point of this trade-off.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Mutual Reinforcement Learning, a framework for concurrent RL post-training of heterogeneous LLM policies that exchange typed experience while retaining separate parameters, objectives, and tokenizers. It combines Shared Experience Exchange (SEE), Multi-Worker Resource Allocation (MWRA), and a Tokenizer Heterogeneity Layer (THL) for retokenizing text and aligning token-level traces. Three GRPO-based probes are defined: data-level Peer Rollout Pooling (PRP), value-level Cross-Policy GRPO Advantage Sharing (XGRPO), and outcome-level Success-Gated Transfer (SGT). A contextual-bandit analysis positions the mechanisms on a stability-support trade-off, claiming that SGT occupies the favorable point in the evaluated regime.
Significance. If the empirical results and analysis hold, the work could meaningfully advance collaborative post-training across incompatible LLM families by making experience sharing operational despite tokenizer and policy differences. The contextual-bandit characterization of the stability-support trade-off supplies a structured, falsifiable lens for comparing sharing designs and is a clear strength of the submission.
major comments (2)
- [Abstract] Abstract: the central claim that SGT occupies the favorable point of the stability-support trade-off depends on THL incurring only the budgeted residual costs already stated for PRP. The manuscript does not address whether SGT's success-gated transfers incur equivalent or larger alignment overhead or variance when vocabularies differ, which directly affects whether SGT remains at the claimed position on the trade-off.
- [Contextual-bandit analysis] Contextual-bandit analysis: no equations, derivations, or quantitative bounds are supplied to support the stated structural positions (PRP paying density-ratio variance plus THL costs, XGRPO preserving on-policy support while altering baselines, SGT supplying a rescue-set direction). Without these, it is impossible to verify that the analysis is independent of the empirical results or that it correctly predicts the reported regime.
minor comments (2)
- [Abstract] The abstract introduces many acronyms (SEE, MWRA, THL, PRP, XGRPO, SGT, GRPO) without first-use expansion; a short glossary or expanded first sentence would improve accessibility.
- [Experiments] The manuscript should report concrete experimental details (number of models, vocabulary mismatch sizes, exact THL overhead measurements, error bars) rather than referring only to an 'evaluated regime'.
Simulated Author's Rebuttal
Thank you for the detailed review and valuable feedback on our submission. We address the major comments point by point below, and we plan to incorporate revisions to clarify the analysis and strengthen the supporting arguments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that SGT occupies the favorable point of the stability-support trade-off depends on THL incurring only the budgeted residual costs already stated for PRP. The manuscript does not address whether SGT's success-gated transfers incur equivalent or larger alignment overhead or variance when vocabularies differ, which directly affects whether SGT remains at the claimed position on the trade-off.
Authors: We agree that the positioning of SGT on the trade-off relies on the THL costs being comparable. The THL is designed as a general layer for retokenizing text and aligning token-level traces, applied uniformly across all sharing mechanisms. For SGT, the success-gated transfers involve retokenizing only verified successful outcomes from peers, which uses the same THL process as in PRP without additional data-level or value-level alignments. This suggests the overhead remains residual and bounded similarly. To make this explicit and address potential variance differences, we will expand the discussion in the revised manuscript with a breakdown of THL operations per mechanism and include measurements of alignment overhead in the experimental section. revision: yes
-
Referee: [Contextual-bandit analysis] Contextual-bandit analysis: no equations, derivations, or quantitative bounds are supplied to support the stated structural positions (PRP paying density-ratio variance plus THL costs, XGRPO preserving on-policy support while altering baselines, SGT supplying a rescue-set direction). Without these, it is impossible to verify that the analysis is independent of the empirical results or that it correctly predicts the reported regime.
Authors: The contextual-bandit analysis provides a structural lens to position the mechanisms based on the type of information exchanged and the resulting variance or support implications. Specifically, PRP involves sharing full rollouts, incurring importance sampling variance from policy density ratios between heterogeneous models in addition to THL costs; XGRPO shares advantage estimates while keeping the actor's policy updates on-policy; and SGT transfers only successful outcome scores, directing the learning toward verified successes without modifying the on-policy support. While the main text presents this qualitatively to focus on the framework, we acknowledge the need for formal support. In the revision, we will add a dedicated subsection with the underlying contextual bandit formulation, including key equations for the value functions and variance terms, along with qualitative bounds on the stability-support trade-off. This will demonstrate the analysis's independence from the specific empirical outcomes. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces a new framework (Mutual RL with SEE, MWRA, THL) and three probes (PRP, XGRPO, SGT) on top of GRPO. The central characterization is a contextual-bandit analysis that positions the mechanisms on a stability-support trade-off by examining their structural properties (density-ratio variance for PRP, on-policy support for XGRPO, rescue-set direction for SGT). This analysis is presented as an independent structural mapping rather than a fit to the paper's own data or a self-referential definition. No equations reduce a claimed prediction to a fitted input by construction, no load-bearing self-citations are invoked for uniqueness theorems, and the THL is introduced as an enabling component rather than smuggled via prior ansatz. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Tokenizer Heterogeneity Layer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Abdelrahman Abouelenin, Atabak Ashfaq, Adam Atkinson, Hany Awadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, Vishrav Chaudhary, Congcong Chen, Dong Chen, Dongdong Chen, Junkun Chen, Weizhu Chen, Yen-Chun Chen, Yi ling Chen, Qi Dai, Xiyang Dai, Ruchao Fan, Mei Gao, Min Gao, Amit Garg, Abhishek Goswami, Junheng Hao, Amr Hendy, Yuxuan Hu, Xin Jin...
work page internal anchor Pith review doi:10.48550/arxiv.2503.01743 2025
-
[2]
Shivam Agarwal, Zimin Zhang, Lifan Yuan, Jiawei Han, and Hao Peng. The unreasonable effectiveness of entropy minimization in llm reasoning. arXiv preprint arXiv:2505.15134, 2025
-
[3]
arXiv preprint arXiv:2012.09816 , year=
Zeyuan Allen-Zhu and Yuanzhi Li. Towards understanding ensemble, knowledge distillation and self-distillation in deep learning, 2020. URL https://arxiv.org/abs/2012.09816
-
[4]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learning to retrieve, generate, and critique through self-reflection. arXiv preprint arXiv:2310.11511, 2023. URL https://arxiv.org/abs/2310.11511
work page internal anchor Pith review arXiv 2023
-
[5]
An actor-critic algorithm for sequence prediction
Dzmitry Bahdanau, Philemon Brakel, Kelvin Xu, Anirudh Goyal, Ryan Lowe, Joelle Pineau, Aaron Courville, and Yoshua Bengio. An actor-critic algorithm for sequence prediction. In International Conference on Learning Representations (ICLR), 2017
work page 2017
-
[6]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, K...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Piqa: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language. In AAAI, 2020
work page 2020
-
[8]
Combining labeled and unlabeled data with co-training
Avrim Blum and Tom Mitchell. Combining labeled and unlabeled data with co-training. In Conference on Computational Learning Theory (COLT), 1998
work page 1998
-
[9]
Deep reinforcement learning from human preferences
Paul F Christiano, Jan Leike, Tom B Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[10]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. In NAACL, 2019
work page 2019
-
[11]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Thomas Degris, Martha White, and Richard S. Sutton. Linear off-policy actor-critic. In Proceedings of the 29th International Conference on Machine Learning, 2012
work page 2012
-
[14]
Treegrpo: Tree-advantage grpo for online rl post-training of diffusion models
Zheng Ding and Weirui Ye. Treegrpo: Tree-advantage grpo for online rl post-training of diffusion models. In International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[15]
FOCUS : Effective embedding initialization for monolingual specialization of multilingual models
Konstantin Dobler and Gerard de Melo. FOCUS : Effective embedding initialization for monolingual specialization of multilingual models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13440--13454, 2023
work page 2023
-
[16]
RAFT : Reward ranked finetuning for generative foundation model alignment
Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, KaShun SHUM, and Tong Zhang. RAFT : Reward ranked finetuning for generative foundation model alignment. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=m7p5O7zblY
work page 2023
-
[17]
IMPALA : Scalable distributed deep- RL with importance weighted actor-learner architectures
Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Vlad Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, Shane Legg, and Koray Kavukcuoglu. IMPALA : Scalable distributed deep- RL with importance weighted actor-learner architectures. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Ma...
work page 2018
-
[18]
Counterfactual multi-agent policy gradients
Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. In AAAI Conference on Artificial Intelligence (AAAI), 2018
work page 2018
-
[19]
Deep ensembles: A loss landscape perspective, 2019
Stanislav Fort, Huiyi Hu, and Balaji Lakshminarayanan. Deep ensembles: A loss landscape perspective, 2019. URL https://arxiv.org/abs/1912.02757
-
[20]
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Wei Guo, Jun Mei, Jiashu Wang, Tongkai Yang, Binhang Yuan, and Yi Wu. Areal: A large-scale asynchronous reinforcement learning system for language reasoning. arXiv preprint arXiv:2505.24298, 2025. URL https://arxiv.org/abs/2505.24298
-
[21]
Lipton, Michael Tschannen, Laurent Itti, and Anima Anandkumar
Tommaso Furlanello, Zachary C. Lipton, Michael Tschannen, Laurent Itti, and Anima Anandkumar. Born again neural networks. In International Conference on Machine Learning (ICML), 2018
work page 2018
-
[22]
Pal: Program-aided language models
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. Pal: Program-aided language models. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 10764--10799. PMLR, 2023
work page 2023
-
[23]
One- shot entropy minimization,
Zitian Gao, Lynx Chen, Haoming Luo, Joey Zhou, and Bryan Dai. One-shot entropy minimization. arXiv preprint arXiv:2505.20282, 2025
-
[24]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, et al. The Llama 3 Herd of Models . arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor, 2018. URL https://arxiv.org/abs/1801.01290
work page internal anchor Pith review arXiv 2018
-
[27]
Bo Han, Quanming Yao, Xingrui Yu, Gang Niu, Miao Xu, Weihua Hu, Ivor W. Tsang, and Masashi Sugiyama. Co-teaching: Robust training of deep neural networks with extremely noisy labels. In Advances in Neural Information Processing Systems (NeurIPS), 2018
work page 2018
-
[28]
Jingkai He, Tianjian Li, Erhu Feng, Dong Du, Qian Liu, Tao Liu, Yubin Xia, and Haibo Chen. History rhymes: Accelerating llm reinforcement learning with rhymerl. arXiv preprint arXiv:2508.18588, 2025
-
[29]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, 2021
work page 2021
-
[30]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[31]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR) -- Poster, 2022. URL https://iclr.cc/virtual/2022/poster/6319. Also available as arXiv:2106.09685 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Jian Hu. Reinforce++: A simple and efficient approach for aligning large language models. arXiv preprint arXiv:2501.03262, 2025
work page internal anchor Pith review arXiv 2025
-
[33]
Editing Models with Task Arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic. arXiv preprint arXiv:2212.04089, 2022. doi:10.48550/arXiv.2212.04089. Also presented as a poster at ICLR 2023
work page internal anchor Pith review doi:10.48550/arxiv.2212.04089 2022
-
[34]
Actor-attention-critic for multi-agent reinforcement learning
Shariq Iqbal and Fei Sha. Actor-attention-critic for multi-agent reinforcement learning. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 2961--2970, Long Beach, California, USA, 09--15 Jun 2019. PMLR. URL https://proc...
work page 2019
-
[35]
Geoffrey Irving, Paul Christiano, and Dario Amodei. Ai safety via debate. arXiv preprint arXiv:1805.00899, 2018
work page internal anchor Pith review arXiv 2018
-
[36]
Leveraging passage retrieval with generative models for open domain question answering
Gautier Izacard and Edouard Grave. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 874--880, Online, Apr 2021. Association for Computational Linguistics. doi:10.18653/v1/2021.eacl-main.7...
-
[37]
Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels
Lu Jiang, Zhengyuan Zhou, Thomas Leung, Li-Jia Li, and Li Fei-Fei. Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels. In International Conference on Machine Learning (ICML), 2018
work page 2018
-
[38]
Tinybert: Distilling bert for natural language understanding
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. Tinybert: Distilling bert for natural language understanding. In Findings of the Association for Computational Linguistics: EMNLP 2020, 2020
work page 2020
-
[39]
arXiv preprint arXiv:2410.01679 , year=
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron Courville, and Nicolas Le Roux. Vineppo: Unlocking rl potential for llm reasoning through refined credit assignment. arXiv preprint arXiv:2410.01679, 2024
-
[40]
Yoon Kim and Alexander M. Rush. Sequence-level knowledge distillation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2016
work page 2016
-
[41]
Offline reinforcement learning with implicit q-learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=68n2s9ZJWF8
work page 2022
-
[42]
Conservative Q -learning for offline reinforcement learning
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative Q -learning for offline reinforcement learning. In Advances in Neural Information Processing Systems, 2020
work page 2020
-
[43]
Temporal ensembling for semi-supervised learning
Samuli Laine and Timo Aila. Temporal ensembling for semi-supervised learning. In International Conference on Learning Representations (ICLR), 2017
work page 2017
-
[44]
The Power of Scale for Parameter-Efficient Prompt Tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, 2021
work page internal anchor Pith review arXiv 2021
-
[45]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Sergey Levine. Reinforcement learning and control as probabilistic inference: Tutorial and review. arXiv preprint arXiv:1805.00909, 2018. URL https://arxiv.org/abs/1805.00909
work page internal anchor Pith review arXiv 2018
-
[46]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K\"uttler, Mike Lewis, Wen tau Yih, Tim Rockt\"aschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Advances in Neural Information Processing Systems 33 (NeurIPS 2020), 2020. URL https://arxiv.o...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[47]
Solving Quantitative Reasoning Problems with Language Models
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models. In Advances in Neural Information Processing Systems, 2022. doi:10.48550/arXiv.2...
work page internal anchor Pith review doi:10.48550/arxiv.2206.14858 2022
-
[48]
To think or not to think: A study of thinking in rule-based visual reinforcement fine-tuning
Ming Li, Jike Zhong, Shitian Zhao, Yuxiang Lai, Haoquan Zhang, Wang Bill Zhu, and Kaipeng Zhang. To think or not to think: A study of thinking in rule-based visual reinforcement fine-tuning. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026 a . URL https://openreview.net/forum?id=YexxvBGwQM
work page 2026
-
[49]
Pengyi Li, Matvey Skripkin, Alexander Zubrey, Andrey Kuznetsov, and Ivan Oseledets. Confidence is all you need: Few-shot rl fine-tuning of language models. arXiv preprint arXiv:2506.06395, 2025
-
[50]
Prefix-tuning: Optimizing continuous prompts for generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582--4597. Association for Computational Linguistics, 2021
work page 2021
-
[51]
Branchgrpo: Stable and efficient grpo with structured branching in diffusion models
Yuming Li, Yikai Wang, Yuying Zhu, Zhongyu Zhao, Ming Lu, Qi She, and Shanghang Zhang. Branchgrpo: Stable and efficient grpo with structured branching in diffusion models. In International Conference on Learning Representations (ICLR), 2026 b
work page 2026
-
[52]
Interactive Learning for LLM Reasoning
Hehai Lin, Shilei Cao, Sudong Wang, Haotian Wu, Minzhi Li, Linyi Yang, Juepeng Zheng, and Chengwei Qin. Interactive learning for llm reasoning. arXiv preprint arXiv:2509.26306, 2025. URL https://arxiv.org/abs/2509.26306
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Gdpo: Group reward-decoupled normalization policy optimization for multi-reward rl optimization,
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, Yejin Choi, Jan Kautz, and Pavlo Molchanov. Gdpo: Group reward-decoupled normalization policy optimization for multi-reward rl optimization, 2026. URL https://arxiv.org/abs/2601.05242
-
[54]
Off-policy policy gradient with stationary distribution correction
Yao Liu, Adith Swaminathan, Alekh Agarwal, and Emma Brunskill. Off-policy policy gradient with stationary distribution correction. In Ryan P. Adams and Vibhav Gogate, editors, Proceedings of The 35th Uncertainty in Artificial Intelligence Conference, volume 115 of Proceedings of Machine Learning Research, pages 1180--1190. PMLR, 22--25 Jul 2020. URL https...
work page 2020
-
[55]
Lennart Ljung. System identification. In Signal Analysis and Prediction, pages 163--173. Birkh \"a user, Boston, MA, 1998
work page 1998
-
[56]
Multi-agent actor-critic for mixed cooperative-competitive environments
Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. In Advances in Neural Information Processing Systems (NIPS), 2017
work page 2017
-
[57]
The climb carves wisdom deeper than the summit: On the noisy rewards in learning to reason
Ang Lv, Ruobing Xie, Xingwu Sun, Zhanhui Kang, and Rui Yan. The climb carves wisdom deeper than the summit: On the noisy rewards in learning to reason. arXiv preprint arXiv:2505.22653, 2025
-
[58]
Merging models with fisher-weighted averaging
Michael Matena and Colin Raffel. Merging models with fisher-weighted averaging. arXiv preprint arXiv:2111.09832, 2021. URL https://arxiv.org/abs/2111.09832. Also presented as a NeurIPS 2022 poster
-
[59]
Pointer sentinel mixture models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. In International Conference on Learning Representations (ICLR), 2017
work page 2017
-
[60]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. In EMNLP, 2018
work page 2018
-
[61]
Mistral AI team . Un ministral, des ministraux. https://mistral.ai/news/ministraux/, Oct 2024. Research / release announcement (Oct 16, 2024)
work page 2024
-
[62]
Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu
Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy P. Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In Maria Florina Balcan and Kilian Q. Weinberger, editors, Proceedings of the 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine...
work page 1928
-
[63]
Reward augmented maximum likelihood for neural structured prediction
Mohammad Norouzi, Samy Bengio, Zhifeng Chen, Navdeep Jaitly, Mike Schuster, Yonghui Wu, and Dale Schuurmans. Reward augmented maximum likelihood for neural structured prediction. In Advances in Neural Information Processing Systems 29 (NIPS 2016), pages 1723--1731, 2016
work page 2016
-
[64]
Asynchronous rlhf: Faster and more efficient off-policy rl for language models
Michael Noukhovitch, Shengyi Huang, Sophie Xhonneux, Arian Hosseini, Rishabh Agarwal, and Aaron Courville. Asynchronous rlhf: Faster and more efficient off-policy rl for language models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=FhTAG591Ve
work page 2025
-
[65]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.02155 2022
-
[66]
and Zhang, Kaiqing and Kim, Joo-Kyung
Chanwoo Park, Seungju Han, Xingzhi Guo, Asuman E. Ozdaglar, Kaiqing Zhang, and Joo-Kyung Kim. MAP o RL : Multi-agent post-co-training for collaborative large language models with reinforcement learning. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 30215--30248, Vienna, Austria, 2...
-
[67]
A deep reinforced model for abstractive summarization
Romain Paulus, Caiming Xiong, and Richard Socher. A deep reinforced model for abstractive summarization. In International Conference on Learning Representations (ICLR), 2018
work page 2018
-
[68]
Adapterfusion: Non-destructive task composition for transfer learning
Jonas Pfeiffer, Aishwarya Kamath, Andreas R "u ckl \'e , Kyunghyun Cho, and Iryna Gurevych. Adapterfusion: Non-destructive task composition for transfer learning. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 487--503, Online, April 2021. Association for Computational Lin...
-
[69]
Mihir Prabhudesai, Lili Chen, Alex Ippoliti, Katerina Fragkiadaki, Hao Liu, and Deepak Pathak. Maximizing confidence alone improves reasoning. arXiv preprint arXiv:2505.22660, 2025
-
[70]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[71]
Sequence level training with recurrent neural networks
MarcAurelio Ranzato, Sumit Chopra, Michael Auli, and Wojciech Zaremba. Sequence level training with recurrent neural networks. In International Conference on Learning Representations (ICLR), 2016
work page 2016
-
[72]
Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder de Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning. In International Conference on Machine Learning (ICML), 2018
work page 2018
-
[73]
Self-critical sequence training for image captioning
Steven J Rennie, Etienne Marcheret, Youssef Mroueh, Jerret Ross, and Vaibhava Goel. Self-critical sequence training for image captioning. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
work page 2017
-
[74]
Fitnets: Hints for thin deep nets
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets. In International Conference on Learning Representations (ICLR), 2015
work page 2015
-
[75]
How good is your tokenizer? on the monolingual performance of multilingual language models
Phillip Rust, Jonas Pfeiffer, Ivan Vuli \'c , Sebastian Ruder, and Iryna Gurevych. How good is your tokenizer? on the monolingual performance of multilingual language models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics, pages 3118--3135, 2021
work page 2021
-
[76]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: Smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108, 2019
work page internal anchor Pith review arXiv 1910
-
[77]
Social iqa: Commonsense reasoning about social interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. Social iqa: Commonsense reasoning about social interactions. In EMNLP, 2019
work page 2019
-
[78]
John Schulman, Sergey Levine, Pieter Abbeel, Michael I. Jordan, and Philipp Moritz. Trust region policy optimization. In International Conference on Machine Learning (ICML), 2015
work page 2015
-
[79]
John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation. In International Conference on Learning Representations (ICLR), 2016
work page 2016
-
[80]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.