Recognition: no theorem link
TREA: Low-precision Time-Multiplexed, Resource-Efficient Edge Accelerator for Object Detection and Classification
Pith reviewed 2026-05-11 00:56 UTC · model grok-4.3
The pith
TREA uses dual-precision time-multiplexed MACs and structured pruning to cut kernel latency by up to 9 times for edge object detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TREA combines a DQ-MAC unit using most-significant-digit-first shift-and-add for dual-precision operations with SHARP pruning for near 50 percent structured sparsity and an RQ-NAF CORDIC core, allowing a 3x3 convolution in 1 cycle at 4-bit precision versus 9 cycles at 8-bit in a reconfigurable 1D array architecture.
What carries the argument
The DQ-MAC SIMD unit with MSDF computation and run-time bit truncation that performs 4x 4-bit or 1x 8-bit operations per cycle while reducing multiplier and accumulator overhead.
If this is right
- A 3x3 convolution kernel completes in 1 cycle in 4-bit mode instead of 9 cycles in 8-bit mode.
- A 5x5 kernel takes 3 cycles versus 25, for up to 9x kernel-level latency reduction.
- The design shows better latency, hardware utilization, and energy efficiency than fixed-precision non-reconfigurable accelerators.
- Layer-wise hardware reuse in a 1D array of 100 units reduces overall area and control complexity.
Where Pith is reading between the lines
- The approach may generalize to other neural network layers or vision models if the pruning strategy adapts well.
- Time-multiplexing could allow smaller chip areas for the same performance in multi-task edge devices.
- Combining low precision with CORDIC activations might reduce power further in always-on vision sensors.
Load-bearing premise
The structured hardware-aware reductive pruning maintains acceptable accuracy at near 50 percent sparsity while preserving full MAC utilization in all layers.
What would settle it
Measuring the accuracy of object detection on standard benchmarks like COCO when using the SHARP-pruned 4-bit model on the TREA accelerator versus the unpruned 8-bit baseline.
Figures






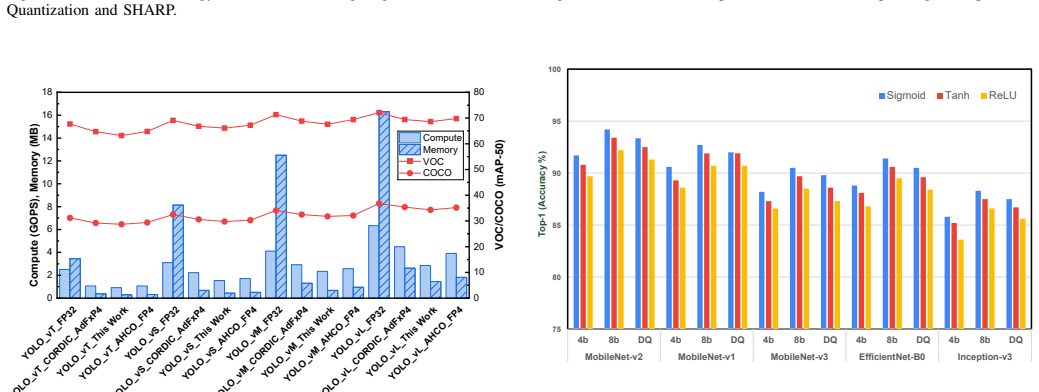

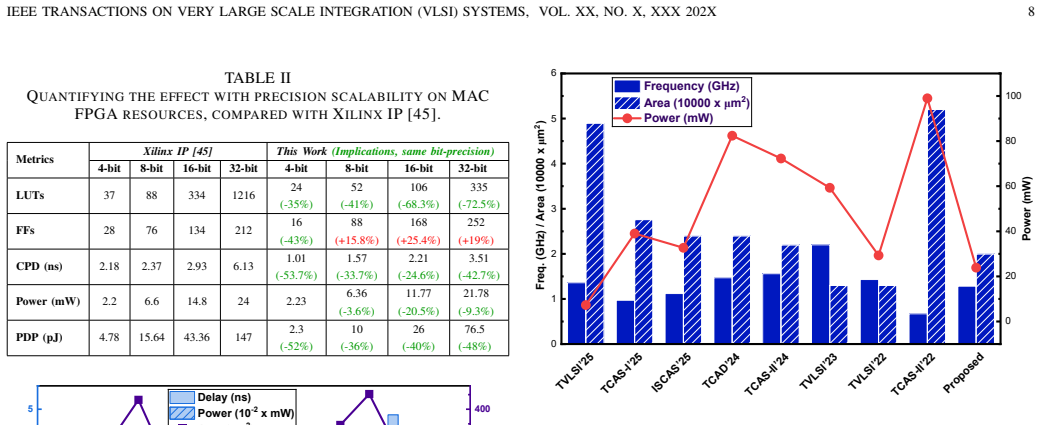
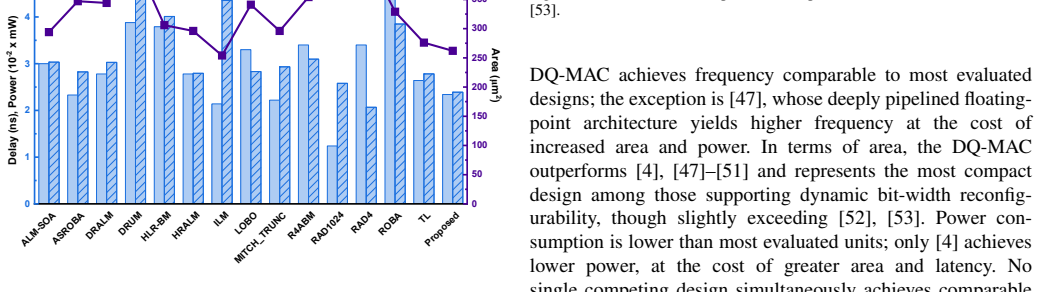

read the original abstract
This work presents TREA, a low-precision time-multiplexed and resource-efficient edge-AI accelerator for object detection and classification, targeting stringent area-power-latency constraints of edge vision platforms. The proposed architecture integrates a dual-precision (4/8-bit) SIMD multiply-accumulate (DQ-MAC) unit based on most-significant-digit-first (MSDF) shift-and-add computation with run-time bit truncation, eliminating conventional multiplier overhead and reducing accumulator bit-width. The DQ-MAC supports 4x FxP4 or 1x FxP8 operations per cycle, achieving up to 4x throughput improvement without hardware duplication. A structured hardware-aware reductive pruning (SHARP) strategy is co-designed with the SIMD datapath, enabling near 50% structured sparsity while maintaining full MAC utilization. This allows a 3x3 convolution kernel to be computed in 1 cycle in FxP4 mode compared to 9 cycles in FxP8, and a 5x5 kernel in 3 cycles versus 25 cycles, yielding up to 9x latency reduction at the kernel level. The accelerator further incorporates a reconfigurable CORDIC-based nonlinear activation function (RQ-NAF) core with a 9-stage pipeline, supporting Sigmoid, Tanh, and ReLU at one output per cycle after pipeline fill, while enabling (N-1) hardware reuse through time-multiplexing. The complete TREA architecture employs a 1D array of 100 SIMD DQ-MAC units with layer-wise hardware reuse, significantly reducing area and control complexity. Experimental results demonstrate substantial improvements in latency, hardware utilization, and energy efficiency compared to conventional fixed-precision and non-reconfigurable accelerators, validating TREA as an effective solution for real-time edge vision workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TREA, a low-precision time-multiplexed edge-AI accelerator for object detection and classification. It integrates a dual-precision (4/8-bit) SIMD MAC unit (DQ-MAC) based on MSDF shift-and-add with run-time truncation, a structured hardware-aware reductive pruning (SHARP) strategy enabling ~50% structured sparsity while preserving full MAC utilization in the SIMD array, and a reconfigurable CORDIC-based nonlinear activation (RQ-NAF) core. The architecture uses a 1D array of 100 DQ-MAC units with layer-wise reuse and claims up to 9x kernel-level latency reduction (e.g., 3x3 conv in 1 cycle at FxP4 vs. 9 at FxP8) plus substantial gains in latency, utilization, and energy efficiency over fixed-precision and non-reconfigurable baselines, validated by experimental results.
Significance. If the co-design of SHARP with the DQ-MAC datapath successfully maintains detection accuracy at the reported sparsity levels while delivering the hardware gains, the work would offer a concrete example of hardware-aware structured pruning enabling efficient low-precision SIMD operation for edge vision. The explicit mapping of pruning to preserve full MAC utilization across kernel sizes and the time-multiplexed RQ-NAF reuse are strengths that could inform similar co-design efforts.
major comments (2)
- [Abstract and Experimental Results] The central claim that TREA is 'an effective solution for real-time edge vision workloads' rests on experimental results showing latency/utilization/energy gains while remaining effective for detection. However, no quantitative accuracy metrics (mAP, top-1 accuracy, or deltas vs. dense/unstructured baselines) are reported for SHARP at near-50% structured sparsity on any detection dataset. This is load-bearing because the performance claims are explicitly tied to SHARP enabling full MAC utilization without unacceptable accuracy loss (Abstract; Experimental Results section).
- [Abstract and Experimental Results] The reported kernel-level latency reductions (3x3 in 1 cycle at FxP4, 5x5 in 3 cycles) and overall 'substantial improvements' lack any baseline accelerator details, dataset sizes, error bars, or layer-wise utilization numbers. Without these, the magnitude and reproducibility of the gains cannot be assessed (Abstract; Experimental Results section).
minor comments (1)
- [Abstract] The abstract introduces multiple acronyms (DQ-MAC, SHARP, RQ-NAF) in a single paragraph; a brief parenthetical expansion or table of acronyms would improve readability for readers unfamiliar with the co-design terms.
Simulated Author's Rebuttal
We thank the referee for the insightful comments and the recommendation for major revision. We address each major comment below, agreeing that additional details are needed to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experimental Results] The central claim that TREA is 'an effective solution for real-time edge vision workloads' rests on experimental results showing latency/utilization/energy gains while remaining effective for detection. However, no quantitative accuracy metrics (mAP, top-1 accuracy, or deltas vs. dense/unstructured baselines) are reported for SHARP at near-50% structured sparsity on any detection dataset. This is load-bearing because the performance claims are explicitly tied to SHARP enabling full MAC utilization without unacceptable accuracy loss (Abstract; Experimental Results section).
Authors: We agree with the referee that the absence of quantitative accuracy metrics for SHARP pruning is a significant omission, as the claims rely on maintaining detection accuracy at high structured sparsity levels. The manuscript currently emphasizes hardware efficiency gains but does not report specific mAP values or comparisons to dense and unstructured pruning baselines on detection datasets. To address this, we will revise the Experimental Results section to include accuracy results on a detection dataset (e.g., PASCAL VOC or COCO), showing mAP for the baseline model, after SHARP pruning at approximately 50% sparsity, and any deltas. This will validate that the structured pruning preserves accuracy sufficiently for the hardware benefits to be meaningful. We will also discuss the hardware-aware nature of SHARP that enables this balance. revision: yes
-
Referee: [Abstract and Experimental Results] The reported kernel-level latency reductions (3x3 in 1 cycle at FxP4, 5x5 in 3 cycles) and overall 'substantial improvements' lack any baseline accelerator details, dataset sizes, error bars, or layer-wise utilization numbers. Without these, the magnitude and reproducibility of the gains cannot be assessed (Abstract; Experimental Results section).
Authors: We acknowledge that providing more context on the baselines and evaluation setup is necessary for assessing the reported gains. The kernel-level latency reductions are calculated based on the time-multiplexed operation of the DQ-MAC array with SHARP pruning allowing full utilization (e.g., mapping 9 MACs of a 3x3 kernel to 1 cycle in 4-bit mode via 4x parallelism and pruning). However, the manuscript does not detail the exact baseline accelerators, the datasets used for timing/energy measurements, error bars, or per-layer utilization statistics. In the revised version, we will add these details: descriptions of comparison baselines (such as fixed 8-bit SIMD without reconfiguration), the input sizes and datasets (e.g., ImageNet for classification, COCO for detection), any statistical measures, and layer-wise utilization figures for the 100-unit array. This will improve the reproducibility and clarity of the experimental claims. revision: yes
Circularity Check
No circularity in TREA architecture proposal
full rationale
The paper is an engineering hardware design contribution describing DQ-MAC units, SHARP co-designed pruning, RQ-NAF activation, and a 1D SIMD array, with all performance claims (latency, utilization, energy) resting on explicit hardware operation counts and experimental measurements rather than any derivation, equation, or prediction that reduces to fitted parameters or self-referential definitions. No self-citations, ansatzes, or uniqueness theorems are invoked in the provided text to support load-bearing steps; the central validation is external to the design description itself.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions of synchronous digital design, including no timing violations in the 9-stage RQ-NAF pipeline and full MAC utilization under structured sparsity.
invented entities (3)
-
DQ-MAC unit
no independent evidence
-
SHARP pruning strategy
no independent evidence
-
RQ-NAF core
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Scaling vision transformers,
X. Zhai, A. Kolesnikov, N. Houlsby, and L. Beyer, “Scaling vision transformers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 12104–12113, 2022
2022
-
[2]
Learning both weights and con- nections for efficient neural network,
S. Han, J. Pool, J. Tran, and W. Dally, “Learning both weights and con- nections for efficient neural network,”Advances in neural information processing systems, vol. 28, 2015
2015
-
[3]
Towards Energy-Efficiency by Navigating the Trilemma of Energy, Latency, and Accuracy,
B. Tian, Y . Pang, M. Huzaifa, S. Wang, and S. V . Adve, “Towards Energy-Efficiency by Navigating the Trilemma of Energy, Latency, and Accuracy,”IEEE International Symposium on Mixed and Augmented Reality (ISMAR), pp. 913–922, 2024
2024
-
[4]
Flex-PE: Flexible and SIMD Multiprecision Processing Element for AI Workloads,
M. Lokhande, G. Raut, and S. K. Vishvakarma, “Flex-PE: Flexible and SIMD Multiprecision Processing Element for AI Workloads,”IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 33, no. 6, pp. 1610– 1623, 2025
2025
-
[5]
Falcon: A Fused- Layer Accelerator With Layer-Wise Hybrid Inference Flow for Compu- tational Imaging CNNs,
Y .-T. Chen, Y .-T. Chiu, H.-J. Tu, and C.-T. Huang, “Falcon: A Fused- Layer Accelerator With Layer-Wise Hybrid Inference Flow for Compu- tational Imaging CNNs,”IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 33, no. 3, pp. 720–732, 2025
2025
-
[6]
XR-NPE: High-Throughput Mixed-precision SIMD Neural Processing Engine for Extended Reality Perception Workloads,
T. Chaudhari, T. Dewangan, M. Lokhande, S. K. Vishvakarma,et al., “XR-NPE: High-Throughput Mixed-precision SIMD Neural Processing Engine for Extended Reality Perception Workloads,”39 th International Conference On VLSI Design and 25 th International Conference On Embedded Systems, 2026
2026
-
[7]
An Efficient Hardware Accelerator for Structured Sparse Convolutional Neural Networks on FPGAs,
C. Zhu, K. Huang, S. Yang, Z. Zhu, H. Zhang, and H. Shen, “An Efficient Hardware Accelerator for Structured Sparse Convolutional Neural Networks on FPGAs,”IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 28, pp. 1953–1965, Sept. 2020
1953
-
[8]
Haq: Hardware-aware automated quantization with mixed precision,
K. Wang, Z. Liu, Y . Lin, J. Lin, and S. Han, “Haq: Hardware-aware automated quantization with mixed precision,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 8612–8620, 2019
2019
-
[9]
Qserve: W4a8kv4 quantization and system co-design for efficient llm serving,
Y . Lin, H. Tang, S. Yang, Z. Zhang, G. Xiao, C. Gan, and S. Han, “Qserve: W4a8kv4 quantization and system co-design for efficient llm serving,”Proceedings of Machine Learning and Systems, vol. 7, 2025
2025
-
[10]
Power-of-Two Quantization for Low Bitwidth and Hardware Compliant Neural Networks,
D. Przewlocka-Rus, S. S. Sarwar, H. E. Sumbul, Y . Li, and B. De Salvo, “Power-of-Two Quantization for Low Bitwidth and Hardware Compliant Neural Networks,”tinyML Research Symposium, Mar. 2022
2022
-
[11]
Smoothquant: Accurate and efficient post-training quantization for large language models,
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “Smoothquant: Accurate and efficient post-training quantization for large language models,” inInternational conference on machine learning, pp. 38087–38099, PMLR, 2023
2023
-
[12]
SVDQuant: Absorbing Outliers by Low-Rank Component for 4-Bit Diffusion Models,
M. Li, Y . Lin, Z. Zhang, T. Cai, X. Li, J. Guo, E. Xie, C. Meng, J.- Y . Zhu, and S. Han, “SVDQuant: Absorbing Outliers by Low-Rank Component for 4-Bit Diffusion Models,” inThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[13]
An Efficient Unstructured Sparse Convolutional Neural Network Accelerator for Wearable ECG Classification Device,
J. Lu, D. Liu, X. Cheng, L. Wei, A. Hu, and X. Zou, “An Efficient Unstructured Sparse Convolutional Neural Network Accelerator for Wearable ECG Classification Device,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 69, pp. 4572–4582, Nov. 2022
2022
-
[14]
Precision-aware On- device Learning and Adaptive Runtime-cONfigurable AI acceleration,
M. Lokhande, A. Jain, and S. K. Vishvakarma, “Precision-aware On- device Learning and Adaptive Runtime-cONfigurable AI acceleration,” IEEE International Symposium on VLSI Design and Test, Aug. 2025
2025
-
[15]
An efficient un- structured sparse convolutional neural network accelerator for wearable ECG classification device,
J. Lu, D. Liu, X. Cheng, L. Wei, A. Hu, and X. Zou, “An efficient un- structured sparse convolutional neural network accelerator for wearable ECG classification device,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 69, no. 11, pp. 4572–4582, 2022
2022
-
[16]
An Efficient Hardware Accelerator for Block Sparse Convolutional Neural Networks on FPGA,
X. Yin, Z. Wu, D. Li, C. Shen, and Y . Liu, “An Efficient Hardware Accelerator for Block Sparse Convolutional Neural Networks on FPGA,” IEEE Embedded Systems Letters, vol. 16, no. 2, pp. 158–161, 2024
2024
-
[17]
Systolic Tensor Array: An Efficient Structured-Sparse GEMM Accelerator for Mobile CNN Inference,
Z.-G. Liu, P. N. Whatmough, and M. Mattina, “Systolic Tensor Array: An Efficient Structured-Sparse GEMM Accelerator for Mobile CNN Inference,”IEEE Computer Architecture Letters, vol. 19, no. 1, pp. 34– 37, 2020
2020
-
[18]
A 3-D Multi-Precision Scalable Systolic FMA Architecture,
H. Liu, X. Lu, X. Yu, K. Li, K. Yang,et al., “A 3-D Multi-Precision Scalable Systolic FMA Architecture,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 72, no. 1, pp. 265–276, 2025
2025
-
[19]
QuantMAC: Enhancing Hardware Performance in DNNs With Quantize Enabled Multiply-Accumulate Unit,
N. Ashar, G. Raut, V . Trivedi, S. K. Vishvakarma, and A. Ku- mar, “QuantMAC: Enhancing Hardware Performance in DNNs With Quantize Enabled Multiply-Accumulate Unit,”IEEE Access, vol. 12, pp. 43600–43614, 2024
2024
-
[20]
ART-MAC: Approximate Rounding and Truncation based MAC Unit for Fault-Tolerant Applications,
V . Mishra, D. Pandey, S. Singh, S. Satapathy, K. Goswami, B. Jajodia, and D. S. Banerjee, “ART-MAC: Approximate Rounding and Truncation based MAC Unit for Fault-Tolerant Applications,” inIEEE International Symposium on Circuits and Systems (ISCAS), pp. 1640–1644, 2022
2022
-
[21]
QForce- RL: Quantized FPGA-Optimized RL Compute Engine,
A. Jha, T. Dewangan, M. Lokhande, and S. K. Vishvakarma, “QForce- RL: Quantized FPGA-Optimized RL Compute Engine,”IEEE Interna- tional Symposium on VLSI Design and Test (VDAT), Aug. 2025
2025
-
[22]
An Improved Logarithmic Multiplier for Energy-Efficient Neural Computing,
M. S. Ansari, B. F. Cockburn, and J. Han, “An Improved Logarithmic Multiplier for Energy-Efficient Neural Computing,”IEEE Transactions on Computers, vol. 70, no. 4, pp. 614–625, 2021
2021
-
[23]
Approximate Hybrid High Radix Encoding for Energy-Efficient Inexact Multipliers,
V . Leon, G. Zervakis, D. Soudris, and K. Pekmestzi, “Approximate Hybrid High Radix Encoding for Energy-Efficient Inexact Multipliers,” IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 26, no. 3, pp. 421–430, 2018
2018
-
[24]
Design of a Hardware-Efficient Approximate 4-2 Compressor for Multiplications in Image Processing,
S. Hwang, K.-W. Kwon, and Y . Kim, “Design of a Hardware-Efficient Approximate 4-2 Compressor for Multiplications in Image Processing,” IEEE Embedded Systems Letters, vol. 17, no. 4, pp. 226–229, 2025
2025
-
[25]
Concept, Design, and Implementation of Reconfigurable CORDIC,
S. Aggarwal, P. K. Meher, and K. Khare, “Concept, Design, and Implementation of Reconfigurable CORDIC,”IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 24, no. 4, pp. 1588–1592, 2016
2016
-
[26]
RECON: Resource- Efficient CORDIC-Based Neuron Architecture,
G. Raut, S. Rai, S. K. Vishvakarma, and A. Kumar, “RECON: Resource- Efficient CORDIC-Based Neuron Architecture,”IEEE Open Journal of Circuits and Systems, vol. 2, pp. 170–181, 2021
2021
-
[27]
Tpu v4: An optically reconfigurable supercomputer for machine learning with hardware support for embeddings,
N. Jouppi, G. Kurian, S. Li, P. Ma, R. Nagarajan, L. Nai,et al., “Tpu v4: An optically reconfigurable supercomputer for machine learning with hardware support for embeddings,” inProceedings of the 50th Annual International Symposium on Computer Architecture, ISCA ’23, Association for Computing Machinery, 2023
2023
-
[28]
ReAFM: A Reconfigurable Nonlinear Activation Function Module for Neural Networks,
X. Wu, S. Liang, M. Wang, and Z. Wang, “ReAFM: A Reconfigurable Nonlinear Activation Function Module for Neural Networks,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 70, pp. 2660–2664, July 2023
2023
-
[29]
Design Space Exploration of Neural Network Activation Function IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. XX, NO. X, XXX 202X 11 Circuits,
T. Yang, Y . Wei, Z. Tu, H. Zeng, M. A. Kinsy, N. Zheng, and P. Ren, “Design Space Exploration of Neural Network Activation Function IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. XX, NO. X, XXX 202X 11 Circuits,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 38, pp. 1974–1978, Oct. 2019
1974
-
[30]
Efficient CORDIC-Based Acti- vation Functions for RNN Acceleration on FPGAs,
W. Shen, J. Jiang, M. Li, and S. Liu, “Efficient CORDIC-Based Acti- vation Functions for RNN Acceleration on FPGAs,”IEEE Transactions on Artificial Intelligence, pp. 1–11, 2024
2024
-
[31]
A Unified Parallel CORDIC- Based Hardware Architecture for LSTM Network Acceleration,
N. A. Mohamed and J. R. Cavallaro, “A Unified Parallel CORDIC- Based Hardware Architecture for LSTM Network Acceleration,”IEEE Transactions on Computers, vol. 72, pp. 2752–2766, Oct. 2023
2023
-
[32]
Exploring Hardware Ac- tivation Function Design: CORDIC Architecture in Diverse Floating Formats,
M. Basavaraju, V . Rayapati, and M. Rao, “Exploring Hardware Ac- tivation Function Design: CORDIC Architecture in Diverse Floating Formats,” in25th International Symposium on Quality Electronic Design (ISQED), pp. 1–8, 2024
2024
-
[33]
A novel reconfigurable hardware architecture of neural network,
K. Khalil, O. Eldash, B. Dey, A. Kumar, and M. Bayoumi, “A novel reconfigurable hardware architecture of neural network,” inIEEE In- ternational Midwest Symposium on Circuits and Systems (MWSCAS), no. 62, pp. 618–621, IEEE, 2023
2023
-
[34]
Accurate Modulation Classification with Reusable-Feature Convolutional Neural Network,
T. Huynh-The, C.-H. Hua, V .-S. Doan, and D.-S. Kim, “Accurate Modulation Classification with Reusable-Feature Convolutional Neural Network,” in2020 IEEE Eighth International Conference on Commu- nications and Electronics (ICCE), pp. 12–17, 2021
2021
-
[35]
Data multiplexed and hardware reused architecture for deep neural network accelerator,
G. Raut, A. Biasizzo, N. Dhakad, N. Gupta,et al., “Data multiplexed and hardware reused architecture for deep neural network accelerator,” Neurocomputing, vol. 486, pp. 147–159, 2022
2022
-
[36]
HYDRA: Hybrid Data Multiplexing and Run-time Layer Configurable DNN Accelerator,
S. Kumar, K. Gupta, I. S. Dasanayake, M. Lokhande, and S. K. Vishvakarma, “HYDRA: Hybrid Data Multiplexing and Run-time Layer Configurable DNN Accelerator,”Proc. 19th Int. Conf. on Industrial and Information Systems (ICIIS), Sri Lanka, Jan. 2026
2026
-
[37]
LPRE: Logarithmic Posit-enabled Reconfigurable edge-AI Engine,
O. Kokane, M. Lokhande, G. Raut, A. Teman, and S. K. Vishvakarma, “LPRE: Logarithmic Posit-enabled Reconfigurable edge-AI Engine,” pp. 1–5, Dec. 2024
2024
-
[38]
AHCO-YOLO: An Algo- rithm–Hardware Co-Optimization Framework for Energy-Efficient and Real-Time Object Detection on Edge Devices,
J. Kim, J.-K. Kang, and Y . Kim, “AHCO-YOLO: An Algo- rithm–Hardware Co-Optimization Framework for Energy-Efficient and Real-Time Object Detection on Edge Devices,”IEEE Trans. Very Large Scale Integr. (VLSI) Syst., pp. 1–14, 2025
2025
-
[39]
The pascal visual object classes (voc) challenge,
M. Everingham, L. Gool, C. K. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes (voc) challenge,”International Journal of Computer Vision, vol. 88, pp. 303–338, 2009
2009
-
[40]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inComputer Vision - ECCV 2014, (Cham), pp. 740–755, Springer International Publishing, 2014
2014
-
[41]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang,et al., “Mobilenets: Efficient convolutional neural networks for mobile vision applications,”CoRR, vol. abs/1704.04861, 2017
work page internal anchor Pith review arXiv 2017
-
[42]
Efficientnet: Rethinking model scaling for con- volutional neural networks,
M. Tan and Q. Le, “Efficientnet: Rethinking model scaling for con- volutional neural networks,” inInternational conference on machine learning, pp. 6105–6114, PMLR, 2019
2019
-
[43]
Going deeper with convolutions,
C. Szegedy, W. Liu, Y . Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V . Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 1–9, 2015
2015
-
[44]
ImageNet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” in2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255, 2009
2009
-
[45]
Xilinx LogiCORE IP MAC v12.0,
A. M. D. Inc., “Xilinx LogiCORE IP MAC v12.0,” Feb. 2024
2024
-
[46]
A Two-Stage Operand Trimming Approximate Logarithmic Multiplier,
R. Pilipovi ´c, P. Buli´c, and U. Lotri ˇc, “A Two-Stage Operand Trimming Approximate Logarithmic Multiplier,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 68, no. 6, pp. 2535–2545, 2021
2021
-
[47]
Unified Posit/IEEE-754 Vector MAC Unit for Transprecision Computing,
L. Crespo, P. Tom ´as, and N. Roma, “Unified Posit/IEEE-754 Vector MAC Unit for Transprecision Computing,”IEEE Trans. on Circuits and Syst. II, vol. 69, pp. 2478–2482, May 2022
2022
-
[48]
Maestro: A 302 GFLOPS/W and 19.8 GFLOPS RISC-V Vector-Tensor Architecture for Wearable Ultrasound Edge Computing,
M. Sinigagliaet al., “Maestro: A 302 GFLOPS/W and 19.8 GFLOPS RISC-V Vector-Tensor Architecture for Wearable Ultrasound Edge Computing,”IEEE Trans. on Circuits and Syst.- I, pp. 1–15, 2025
2025
-
[49]
LPRE: Logarithmic Posit-enabled Reconfigurable edge-AI Engine,
O. Kokane, M. Lokhande, G. Raut, A. Teman, and S. K. Vishvakarma, “LPRE: Logarithmic Posit-enabled Reconfigurable edge-AI Engine,” in 2025 IEEE International Symposium on Circuits and Systems (ISCAS), pp. 1–5, May 2025
2025
-
[50]
A Low-Cost FP Dot-Product-Dual-Accumulate Architecture for HPC-Enabled AI,
H. Tan, L. Huang,et al., “A Low-Cost FP Dot-Product-Dual-Accumulate Architecture for HPC-Enabled AI,”IEEE Trans. Comp.-Aided Des. Integ. Cir. Syst., vol. 43, pp. 681–693, Feb. 2024
2024
-
[51]
A Reconfig- urable Processing Element for Multiple-Precision Floating/Fixed-Point HPC,
B. Li, K. Li, J. Zhou, Y . Ren, W. Mao, H. Yu, and N. Wong, “A Reconfig- urable Processing Element for Multiple-Precision Floating/Fixed-Point HPC,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 71, no. 3, pp. 1401–1405, 2024
2024
-
[52]
Multiple-Mode- Supporting Floating-Point FMA Unit for Deep Learning Processors,
H. Tan, G. Tong, L. Huang, L. Xiao, and N. Xiao, “Multiple-Mode- Supporting Floating-Point FMA Unit for Deep Learning Processors,” IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 31, no. 2, pp. 253–266, 2023
2023
-
[53]
A Configurable Floating-Point Multiple-Precision Processing Element for HPC and AI Converged Computing,
W. Mao, K. Li, Q. Cheng, L. Dai, B. Li, X. Xie, H. Li, L. Lin, and H. Yu, “A Configurable Floating-Point Multiple-Precision Processing Element for HPC and AI Converged Computing,”IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 30, no. 2, pp. 213–226, 2022
2022
-
[54]
High-Performance Accurate and Approximate Multipliers for FPGA-Based Hardware Ac- celerators,
S. Ullah, S. Rehman, M. Shafique, and A. Kumar, “High-Performance Accurate and Approximate Multipliers for FPGA-Based Hardware Ac- celerators,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 41, no. 2, pp. 211–224, 2022
2022
-
[55]
A Precision-Aware Neuron Engine for DNN Accelerators,
S. Vishwakarma, G. Raut, S. Jaiswal, S. K. Vishvakarma, and D. Ghai, “A Precision-Aware Neuron Engine for DNN Accelerators,”SN Com- puter Science, vol. 5, no. 5, p. 494, 2024
2024
-
[56]
Energy-Efficient Low- Latency Signed Multiplier for FPGA-Based Hardware Accelerators,
S. Ullah, T. D. A. Nguyen, and A. Kumar, “Energy-Efficient Low- Latency Signed Multiplier for FPGA-Based Hardware Accelerators,” IEEE Embedded Systems Letters, vol. 13, no. 2, pp. 41–44, 2021
2021
-
[57]
RAMAN: A Reconfigurable and Sparse tinyML Accelerator for Inference on Edge,
A. Krishna, S. Rohit Nudurupati, D. G. Chandana, P. Dwivedi, A. van Schaik, M. Mehendale, and C. S. Thakur, “RAMAN: A Reconfigurable and Sparse tinyML Accelerator for Inference on Edge,”IEEE Internet of Things Journal, vol. 11, pp. 24831–24845, July 2024
2024
-
[58]
Edge-Side Fine-Grained Sparse CNN Accelerator With Efficient Dynamic Pruning Scheme,
B. Wu, T. Yu, K. Chen, and W. Liu, “Edge-Side Fine-Grained Sparse CNN Accelerator With Efficient Dynamic Pruning Scheme,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 71, pp. 1285–1298, Mar. 2024
2024
-
[59]
A High-Throughput Full-Dataflow MobileNetv2 Accelerator on Edge FPGA,
W. Jiang, H. Yu, and Y . Ha, “A High-Throughput Full-Dataflow MobileNetv2 Accelerator on Edge FPGA,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 42, no. 5, pp. 1532–1545, 2023
2023
-
[60]
ShortcutFusion: From Tensorflow to FPGA-Based Accelerator With a Reuse-Aware Memory Allocation for Shortcut Data,
D. T. Nguyen, H. Je, T. N. Nguyen, S. Ryu, K. Lee, and H.-J. Lee, “ShortcutFusion: From Tensorflow to FPGA-Based Accelerator With a Reuse-Aware Memory Allocation for Shortcut Data,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 69, no. 6, pp. 2477– 2489, 2022
2022
-
[61]
A Real-Time Object Detection Processor With xnor-Based Variable-Precision Computing Unit,
W. Lee, K. Kim, W. Ahn, J. Kim, and D. Jeon, “A Real-Time Object Detection Processor With xnor-Based Variable-Precision Computing Unit,”IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 31, no. 6, pp. 749–761, 2023
2023
-
[62]
Dedicated FPGA Implementation of the Gaussian TinyYOLOv3 Accelerator,
S. Ki, J. Park, and H. Kim, “Dedicated FPGA Implementation of the Gaussian TinyYOLOv3 Accelerator,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 70, no. 10, pp. 3882–3886, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.