Recognition: no theorem link
Your Language Model is Its Own Critic: Reinforcement Learning with Value Estimation from Actor's Internal States
Pith reviewed 2026-05-12 03:56 UTC · model grok-4.3
The pith
A policy model's hidden states can estimate value baselines for reinforcement learning without extra models or multiple samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
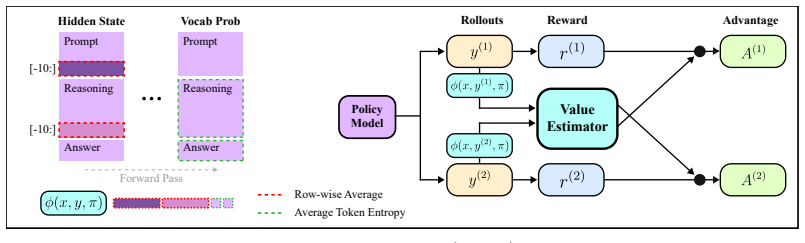
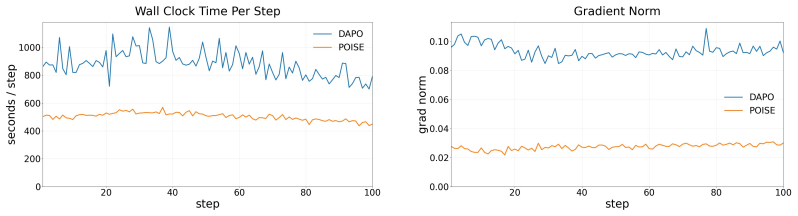
POISE obtains a baseline by predicting expected verifiable reward from the hidden states of the prompt and generated trajectory along with token-entropy statistics using a lightweight probe trained online alongside the policy. To keep gradients unbiased, each rollout's value is predicted from an independent rollout's internal states. This matches the performance of DAPO on math reasoning benchmarks for models like Qwen3-4B while using less compute, and the estimator performs comparably to a full-scale value model.
What carries the argument
The lightweight probe that predicts value from hidden states and entropy, together with the cross-rollout construction for unbiased estimation.
If this is right
- Training can use higher prompt diversity at fixed compute.
- Gradient variance is reduced leading to more stable learning.
- No extra sampling needed to detect zero-advantage prompts.
- The value estimator generalizes across verifiable tasks.
Where Pith is reading between the lines
- This approach might extend to non-verifiable reward settings if internal states encode useful signals.
- It could reduce the overall parameter count needed for RL training by eliminating separate critics.
- Future work might explore what specific aspects of hidden states carry the most value information.
Load-bearing premise
That training a small probe on the actor's hidden states and entropy produces value estimates accurate enough to reduce variance without biasing the policy updates.
What would settle it
Observing that the POISE-trained policy achieves lower accuracy or higher variance than DAPO on the same math benchmarks when both use equivalent total compute and rollouts.
Figures




read the original abstract
Reinforcement learning with verifiable rewards (RLVR) for Large Reasoning Models hinges on baseline estimation for variance reduction, but existing approaches pay a heavy price: PPO requires a policy-model scale critic, while GRPO needs multiple rollouts per prompt to keep its empirical group mean stable. We introduce Policy Optimization with Internal State Value Estimation), which obtains a baseline at negligible cost by using the policy model's internal signals already computed during the policy forward pass. A lightweight probe predicts the expected verifiable reward from the hidden states of the prompt and generated trajectory, as well as token-entropy statistics, and is trained online alongside the policy. To preserve gradient unbiasedness despite using trajectory-conditioned features, we introduce a cross-rollout construction that predicts each rollout's value from an independent rollout's internal states. Because POISE estimates prompt value using only a single rollout, it enables higher prompt diversity for a fixed compute budget during training. This reduces gradient variance for more stable learning and also eliminates the compute overhead of sampling costs for detecting zero-advantage prompts. On Qwen3-4B and DeepSeek-R1-Distill-Qwen-1.5B across math reasoning benchmarks, POISE matches DAPO while requiring less compute. Moreover, its value estimator shows similar performance to a separate LLM-scale value model and generalizes to various verifiable tasks. By leveraging the model's own internal representations, POISE enables more stable and efficient policy optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces POISE (Policy Optimization with Internal State Value Estimation) for RLVR in large reasoning models. It trains a lightweight probe online on the policy model's hidden states (from prompt and trajectory) plus token-entropy statistics to produce value baselines for advantage estimation. A cross-rollout construction is used to predict each rollout's value from an independent rollout's internal states, intended to preserve unbiased policy gradients despite trajectory-conditioned features. The method claims to match DAPO performance on math reasoning benchmarks with Qwen3-4B and DeepSeek-R1-Distill-Qwen-1.5B while using less compute, enabling higher prompt diversity, and that the probe performs comparably to a separate LLM-scale value model while generalizing across verifiable tasks.
Significance. If the unbiasedness of the cross-rollout gradients and the accuracy of the lightweight internal-state probe both hold, POISE would offer a low-overhead alternative to PPO-style critics or multi-rollout group baselines, reducing compute per prompt and supporting more diverse training batches in RLVR. This could meaningfully improve efficiency for reasoning model post-training without sacrificing stability.
major comments (2)
- [cross-rollout construction] Cross-rollout construction (method description): the claim that predicting value for rollout i from rollout j's (j≠i) hidden states and entropy fully breaks trajectory-specific dependence is not obviously true. All rollouts for a given prompt share identical prompt tokens and therefore identical early-layer hidden states; any prompt-level signal captured by the probe can still correlate the baseline with the policy's own trajectory, violating the zero-covariance requirement for unbiased policy gradients. A formal argument or covariance measurement under this construction is required.
- [value estimator training] Value estimator training (online probe section): the probe is trained jointly with the policy on the same rollouts. Even with cross-rollout prediction, the online fitting on trajectory-conditioned features risks the probe learning spurious correlations rather than true expected reward, especially since no ablation isolating the probe's contribution or measuring value prediction error against ground-truth returns is referenced in the provided claims.
minor comments (2)
- The abstract and summary claims reference specific performance parity and generalization results, but the manuscript should include explicit experimental details, ablation tables, and statistical significance tests for the compute savings and value-estimator comparisons to allow verification.
- Notation for the probe inputs (hidden states + entropy) and the exact loss used for online training should be formalized with equations to clarify how the cross-rollout prediction is implemented during the forward pass.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The comments raise important points about the theoretical grounding of the cross-rollout construction and the empirical validation of the value probe. We address each major comment below with clarifications drawn from the manuscript and commit to revisions that strengthen the presentation without altering the core claims or results.
read point-by-point responses
-
Referee: [cross-rollout construction] Cross-rollout construction (method description): the claim that predicting value for rollout i from rollout j's (j≠i) hidden states and entropy fully breaks trajectory-specific dependence is not obviously true. All rollouts for a given prompt share identical prompt tokens and therefore identical early-layer hidden states; any prompt-level signal captured by the probe can still correlate the baseline with the policy's own trajectory, violating the zero-covariance requirement for unbiased policy gradients. A formal argument or covariance measurement under this construction is required.
Authors: We appreciate the referee's careful scrutiny of the independence argument. Although prompt tokens (and thus early-layer hidden states) are identical across rollouts for a given prompt, the cross-rollout construction feeds the probe exclusively with the full set of hidden states and entropy statistics from an independent rollout j when computing the baseline for rollout i. Because j is sampled independently of i, the baseline random variable for i is statistically independent of the actions, log-probabilities, and reward of rollout i. This independence directly implies that the covariance between the baseline and the policy gradient term for i is zero, satisfying the condition for unbiased policy gradients. Prompt-level signals captured by the probe are fixed for the prompt and do not introduce dependence on i's specific trajectory. To make this argument fully rigorous, we will add a short formal proof of unbiasedness (showing E[baseline_i * ∇log π_i] = 0) together with empirical covariance measurements between the cross-rollout baselines and the corresponding advantages in the revised manuscript. revision: yes
-
Referee: [value estimator training] Value estimator training (online probe section): the probe is trained jointly with the policy on the same rollouts. Even with cross-rollout prediction, the online fitting on trajectory-conditioned features risks the probe learning spurious correlations rather than true expected reward, especially since no ablation isolating the probe's contribution or measuring value prediction error against ground-truth returns is referenced in the provided claims.
Authors: We agree that joint online training on trajectory-conditioned features warrants explicit safeguards and validation. The cross-rollout prediction already prevents the baseline used for a rollout from depending on that rollout's own features, reducing the risk of direct spurious correlation with the advantage. Nevertheless, the manuscript currently demonstrates the probe's utility through end-to-end performance matching DAPO and comparability to a separate LLM-scale value model, without dedicated ablations that isolate the probe or report its prediction error (e.g., MSE) against ground-truth returns. We will incorporate these analyses in the revision, including (i) value-prediction error curves against actual verifiable rewards, (ii) an ablation that replaces the probe with a constant or random baseline, and (iii) a comparison of probe accuracy when trained with versus without cross-rollout, to confirm that the estimator learns meaningful expected-reward signals rather than artifacts. revision: yes
Circularity Check
No significant circularity detected in POISE derivation
full rationale
The paper's claimed derivation chain centers on introducing a lightweight probe trained online on hidden states and entropy, combined with an explicit cross-rollout construction to estimate values while aiming to preserve unbiased policy gradients. This construction is presented as a methodological safeguard (predicting rollout i's value from rollout j's independent internal states) rather than a quantity that reduces to its inputs by definition or a fitted parameter renamed as a prediction. No equations or steps in the provided text show the advantage estimate or gradient unbiasedness being equivalent to the probe's training data by construction. No self-citation chains, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation are invoked to force the central result. The performance claims (matching DAPO with less compute) are framed as empirical outcomes on benchmarks, not tautological derivations. The method is self-contained against external benchmarks like DAPO and separate value models, with the cross-rollout serving as an independent design choice to address bias rather than a circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- lightweight probe weights
axioms (1)
- domain assumption Cross-rollout construction preserves unbiased policy gradients when using trajectory-conditioned internal states
invented entities (1)
-
lightweight probe
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The internal state of an LLM knows when it's lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it’s lying. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Com- putational Linguistics: EMNLP 2023, pages 967–976, Singapore, December 2023. Associ- ation for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.68. URL https://aclanthol...
-
[2]
BrUMO 2025: Brown University Mathematics Olympiad
Brown University Math Olympiad Team. BrUMO 2025: Brown University Mathematics Olympiad. https://www.brumo.org , 2025. Inaugural competition, held April 4–5, 2025, Brown University, Providence, RI
work page 2025
-
[3]
Discovering latent knowledge in language models without supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=ETKGuby0hcs
work page 2023
-
[4]
No answer needed: Predicting LLM answer accuracy from question-only linear probes, 2026
Iván Vicente Moreno Cencerrado, Arnau Padrés Masdemont, Anton Gonzalvez Hawthorne, David Demitri Africa, and Lorenzo Pacchiardi. No answer needed: Predicting LLM answer accuracy from question-only linear probes, 2026. URL https://openreview.net/forum?i d=OhN25uxVab
work page 2026
-
[5]
Trace length is a simple uncertainty signal in reasoning models
Siddartha Devic, Charlotte Peale, Arwen Bradley, Sinead Williamson, Preetum Nakkiran, and Aravind Gollakota. Trace length is a simple uncertainty signal in reasoning models.arXiv preprint arXiv:2510.10409, 2025
-
[6]
A mathematical framework for transformer circuits.Transformer Circuits Thread,
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
-
[7]
https://transformer-circuits.pub/2021/framework/index.html
work page 2021
-
[8]
Prompt curriculum learning for efficient llm post-training, 2025
Zhaolin Gao, Joongwon Kim, Wen Sun, Thorsten Joachims, Sid Wang, Richard Yuanzhe Pang, and Liang Tan. Prompt curriculum learning for efficient llm post-training, 2025. URL https://arxiv.org/abs/2510.01135
-
[9]
Evan Greensmith, Peter L. Bartlett, and Jonathan Baxter. Variance reduction techniques for gradient estimates in reinforcement learning.Journal of Machine Learning Research, 5:1471– 1530, 2004
work page 2004
-
[10]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[11]
HMMT February 2025: Harvard–MIT Mathematics Tournament
HMMT Organization. HMMT February 2025: Harvard–MIT Mathematics Tournament. https: //www.hmmt.org/www/archive/282, 2025. Individual round problems, February 2025, MIT, Cambridge, MA
work page 2025
-
[12]
PROS: Towards compute-efficient RLVR via rollout prefix reuse
Baizhou Huang and Xiaojun Wan. PROS: Towards compute-efficient RLVR via rollout prefix reuse. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=lz1SRTcnUb
work page 2026
-
[13]
Aaron Jaech et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[15]
Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V . Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Chris Wilhelm, Luca Soldaini, Noah A. Smith, Yizhong Wang, Pradeep Dasigi, and Hannaneh Hajishirz...
work page 2025
-
[16]
Inference- time intervention: Eliciting truthful answers from a language model
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 41451–41530. Curran Associates, Inc., 2023. URL...
work page 2023
-
[17]
Zicheng Lin, Tian Liang, Jiahao Xu, Qiuzhi Lin, Xing Wang, Ruilin Luo, Chufan Shi, Siheng Li, Yujiu Yang, and Zhaopeng Tu. Critical tokens matter: Token-level contrastive estimation enhances llm’s reasoning capability, 2025. URLhttps://arxiv.org/abs/2411.19943
-
[18]
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y . Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Li Erran Li, Raluca Ada Popa, and Ion Stoica. Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl. https://pretty-radio-b75.not ion.site/DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling -RL-19681902c1468005...
work page 2025
-
[19]
MAA American Mathematics Competitions (AMC)
Mathematical Association of America. MAA American Mathematics Competitions (AMC). https://maa.org/student-programs/amc/, 2023–2026
work page 2023
-
[20]
Mathematical Association of America. American Invitational Mathematics Examination (AIME).https://maa.org/maa-invitational-competitions/, 2024–2026
work page 2024
-
[21]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback....
work page 2022
-
[22]
The linear representation hypothesis and the geometry of large language models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. InForty-first International Conference on Machine Learning, 2024. URLhttps://openreview.net/forum?id=UGpGkLzwpP
work page 2024
-
[23]
Generalizing verifiable instruction following
Valentina Pyatkin, Saumya Malik, Victoria Graf, Hamish Ivison, Shengyi Huang, Pradeep Dasigi, Nathan Lambert, and Hannaneh Hajishirzi. Generalizing verifiable instruction following. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2026. URLhttps://openreview.net/forum?id=yfYgwjj5F8
work page 2026
-
[24]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model,
-
[25]
URLhttps://arxiv.org/abs/2305.18290
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Jeonghoon Shim, Gyuhyeon Seo, Cheongsu Lim, and Yohan Jo. Tooldial: Multi-turn dialogue generation method for tool-augmented language models.arXiv preprint arXiv:2503.00564, 2025
-
[29]
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Na Zou, Hanjie Chen, and Xia Hu. Stop overthinking: A survey on efficient reasoning for large language models.Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https://openreview.net/forum?id=HvoG8Sxg gZ
work page 2025
-
[30]
Sutton, David McAllester, Satinder Singh, and Yishay Mansour
Richard S. Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. InAdvances in Neural Information Processing Systems (NIPS) 12, pages 1057–1063. MIT Press, 2000. URLhttps: //papers.nips.cc/paper/1713-policy-gradient-methods-for-reinforcement-l earning-with-function-app...
work page 2000
-
[31]
Turner, Zoubin Ghahramani, and Sergey Levine
George Tucker, Surya Bhupatiraju, Shixiang Gu, Richard E. Turner, Zoubin Ghahramani, and Sergey Levine. The mirage of action-dependent baselines in reinforcement learning, 2018. URL https://arxiv.org/abs/1802.10031
-
[32]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xiong- Hui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for LLM reasoning. InThe Thirty- ninth Annual Con...
work page 2026
-
[33]
SPPO: Sequence-Level PPO for Long-Horizon Reasoning Tasks
Tianyi Wang, Yixia Li, Long Li, Yibiao Chen, Shaohan Huang, Yun Chen, Peng Li, Yang Liu, and Guanhua Chen. Sppo: Sequence-level ppo for long-horizon reasoning tasks, 2026. URL https://arxiv.org/abs/2604.08865
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
The optimal reward baseline for gradient-based reinforcement learning
Lex Weaver and Nigel Tao. The optimal reward baseline for gradient-based reinforcement learning. InProceedings of the 17th Conference on Uncertainty in Artificial Intelligence (UAI), pages 538–545, 2001
work page 2001
-
[35]
Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine Learning, 8(3–4):229–256, 1992. doi: 10.1007/BF00992696
-
[36]
Single-stream policy optimization.arXiv preprint arXiv:2509.13232,
Zhongwen Xu and Zihan Ding. Single-stream policy optimization, 2025. URL https: //arxiv.org/abs/2509.13232. 13
-
[37]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Demystifying long chain-of-thought reasoning in llms
Edward Yeo, Yuxuan Tong, Morry Niu, Graham Neubig, and Xiang Yue. Demystifying long chain-of-thought reasoning in llms, 2025. URLhttps://arxiv.org/abs/2502.03373
-
[39]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
ACECODER: Acing coder RL via automated test-case synthesis
Huaye Zeng, Dongfu Jiang, Haozhe Wang, Ping Nie, Xiaotong Chen, and Wenhu Chen. ACECODER: Acing coder RL via automated test-case synthesis. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12023–1204...
-
[41]
Rea- soning models know when they’re right: Probing hidden states for self-verification
Anqi Zhang, Yulin Chen, Jane Pan, Chen Zhao, Aurojit Panda, Jinyang Li, and He He. Rea- soning models know when they’re right: Probing hidden states for self-verification. InSecond Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=O6 I0Av7683
work page 2025
-
[42]
v0.5: Generalist value model as a prior for sparse rl rollouts, 2026
Yi-Kai Zhang, Yueqing Sun, Hongyan Hao, Qi Gu, Xunliang Cai, De-Chuan Zhan, and Han- Jia Ye. v0.5: Generalist value model as a prior for sparse rl rollouts, 2026. URL https: //arxiv.org/abs/2603.10848
-
[43]
Bartoldson, Bhavya Kailkhura, Fan Lai, Jiawei Zhao, and Beidi Chen
Haizhong Zheng, Yang Zhou, Brian R. Bartoldson, Bhavya Kailkhura, Fan Lai, Jiawei Zhao, and Beidi Chen. Act only when it pays: Efficient reinforcement learning for llm reasoning via selective rollouts, 2025. URLhttps://arxiv.org/abs/2506.02177
-
[44]
The LLM already knows: Estimating LLM-perceived question difficulty via hidden representations
Yubo Zhu, Dongrui Liu, Zecheng Lin, Wei Tong, Sheng Zhong, and Jing Shao. The LLM already knows: Estimating LLM-perceived question difficulty via hidden representations. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 1...
-
[45]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023. 14 A Theoretical Proofs A.1 Proof of Proposition 1 Proof.Define: µ(x) =E[Z(x, y)|x],Σ w =E x[Cov(Z(x, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.