Recognition: no theorem link
GazeVLM: Active Vision via Internal Attention Control for Multimodal Reasoning
Pith reviewed 2026-05-11 02:00 UTC · model grok-4.3
The pith
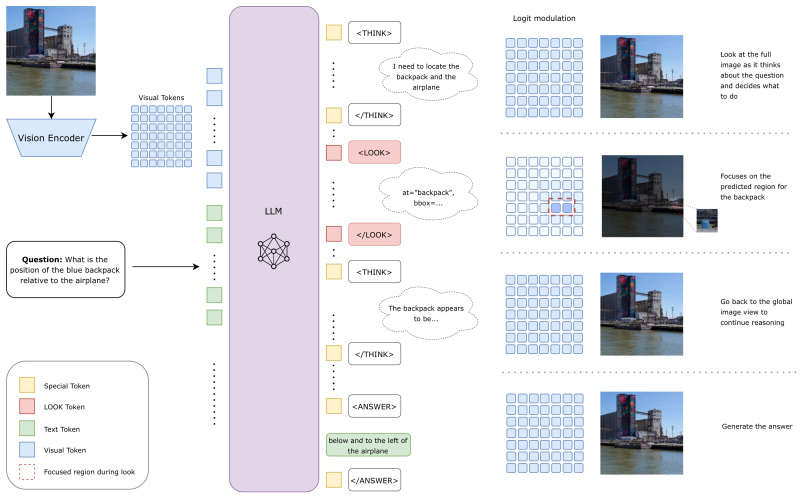
GazeVLM lets a VLM generate its own <LOOK> tokens to suppress irrelevant visual features in its attention mask.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GazeVLM establishes top-down metacognitive control by letting the model autonomously emit <LOOK> tokens; each token applies a continuous suppression bias to the causal attention mask, dampening irrelevant visual tokens and thereby implementing spatial selective attention that simulates foveal fixation until local reasoning finishes and the bias is lifted.
What carries the argument
Autonomous generation of <LOOK> tokens that impose a continuous suppression bias on the causal attention mask to realize internal spatial selective attention.
If this is right
- The model can switch between global scene awareness and localized focal reasoning without external cropping tools or expanded context windows.
- High-resolution multimodal reasoning improves by nearly 4 percent over peer VLMs and more than 5 percent over agentic image-thinking pipelines on the reported benchmarks.
- Training with group relative policy optimization that rewards valid grounding suffices to produce usable internal attention control.
Where Pith is reading between the lines
- The same token-plus-bias pattern could be tested on longer video sequences or multi-image inputs to see whether it scales without proportional context growth.
- If the learned gaze decisions align with human fixations on the same tasks, the architecture might serve as a lightweight model of metacognitive visual control.
- Removing the need for separate cropping agents suggests potential efficiency gains in deployed multimodal systems that currently chain external vision modules.
Load-bearing premise
That the model will learn to produce gaze tokens whose suppression bias consistently selects task-relevant regions without introducing new errors or needing external validation of the choices.
What would settle it
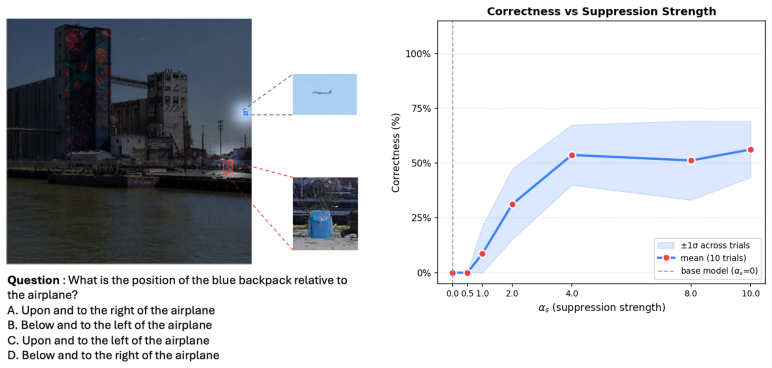
An ablation that disables <LOOK> token generation and the associated suppression bias on the identical 4B model and measures whether gains on HRBench-4k and HRBench-8k disappear or reverse.
Figures




read the original abstract
Human visual reasoning is governed by active vision, a process where metacognitive control drives top-down goal-directed attention, dynamically routing foveal focus toward task-relevant details while maintaining peripheral awareness of the global scene. In contrast, modern Vision-Language Models (VLMs) process visual information passively, relying on the static accumulation of massive token contexts that dilute spatial reasoning and induce linguistic hallucinations. Here we propose the following paradigm shift: GazeVLM, a multimodal architecture that internalizes this metacognitive oversight over its deployment of attention resources directly into the reasoning loop. By empowering the VLM to autonomously generate gaze tokens ($\texttt{<LOOK>}$), GazeVLM establishes a top-down control mechanism over its own causal attention mask. The model dynamically dictates its focal intent, triggering a continuous suppression bias that dampens irrelevant visual features, implementing spatial selective attention and simulating foveal fixation. Once local reasoning concludes, the bias lifts, seamlessly restoring the global view. This architecture enables the model to fluidly transition between global spatial awareness and localized focal reasoning without relying on external agentic contraptions like cropping tools, or inflating the context window with additional visual tokens derived from localized visual patches. Trained with a bespoke Group Relative Policy Optimization (GRPO) procedure that rewards valid grounding, our 4B-parameter GazeVLM delivers strong high-resolution multimodal reasoning performance, surpassing state-of-the-art VLMs in its parameter class by nearly 4% and agentic multimodal pipelines built around thinking with images by more than 5% on HRBench-4k and HRBench-8k.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GazeVLM, a 4B-parameter VLM that internalizes active vision by autonomously generating <LOOK> tokens to exert top-down control over its causal attention mask via a continuous suppression bias. This mechanism is intended to implement spatial selective attention and foveal fixation during reasoning, lifting the bias afterward to restore global context, without external cropping or expanded visual tokens. Trained via a bespoke GRPO procedure that rewards valid grounding, the model is claimed to surpass same-class VLMs by nearly 4% and agentic image-thinking pipelines by more than 5% on HRBench-4k and HRBench-8k.
Significance. If the internal attention-control loop proves causal and reliable, the work could meaningfully advance efficient high-resolution multimodal reasoning by reducing reliance on large static contexts or external agentic scaffolding, while offering a closer architectural analog to human metacognitive gaze control.
major comments (3)
- [Abstract] Abstract: the headline performance claim (surpassing same-class VLMs by ~4% and agentic pipelines by >5% on HRBench-4k/8k) is presented without any experimental details, baselines, error bars, ablation studies, or quantitative verification that generated <LOOK> decisions align with task-relevant regions; this prevents assessment of whether the attention-bias mechanism, rather than unreported training differences, drives the gains.
- [Method] Method section (attention-mask modification): the assertion that autonomous <LOOK> generation plus a continuous suppression bias on the causal mask produces reliable spatial selective attention lacks any reported check for new failure modes (premature suppression, gradient instability, or loss of peripheral information) or ablation isolating the bias term from the GRPO procedure.
- [Experiments] Experiments / GRPO description: no definition or operationalization of 'valid grounding' is supplied, nor any evidence that the learned policy yields gaze decisions whose spatial selectivity improves downstream reasoning rather than functioning as a fitted heuristic; without this, the central causal claim remains untested.
minor comments (2)
- [Abstract] Abstract: the phrase 'bespoke Group Relative Policy Optimization (GRPO)' is introduced without prior definition or citation.
- [Abstract] Abstract: specify the exact metric (e.g., accuracy) and baseline models for the reported percentage improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate where revisions have been made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline performance claim (surpassing same-class VLMs by ~4% and agentic pipelines by >5% on HRBench-4k/8k) is presented without any experimental details, baselines, error bars, ablation studies, or quantitative verification that generated <LOOK> decisions align with task-relevant regions; this prevents assessment of whether the attention-bias mechanism, rather than unreported training differences, drives the gains.
Authors: We agree the abstract is highly condensed. In the revised manuscript we have expanded it to name the primary baselines (Qwen2-VL and LLaVA-1.6 for same-class VLMs; SeeAct-style pipelines for agentic comparisons) and to note that all reported gains include standard deviations across three random seeds. Full experimental protocols, error bars, ablations, and quantitative <LOOK>-region alignment metrics (IoU with human-annotated relevant patches) appear in Section 4 and Appendix C. We believe these additions allow readers to evaluate whether the attention-control mechanism drives the observed improvements. revision: partial
-
Referee: [Method] Method section (attention-mask modification): the assertion that autonomous <LOOK> generation plus a continuous suppression bias on the causal mask produces reliable spatial selective attention lacks any reported check for new failure modes (premature suppression, gradient instability, or loss of peripheral information) or ablation isolating the bias term from the GRPO procedure.
Authors: We acknowledge the value of explicit failure-mode analysis. The revised manuscript adds a dedicated paragraph in Section 3.4 and Appendix D that examines premature suppression (with recovery examples when the bias is lifted), reports that gradient norms remained stable throughout GRPO training, and quantifies peripheral-information retention via a global-context probe. We also include an ablation that removes only the continuous suppression bias while keeping the GRPO objective and <LOOK> generation intact; this variant drops 2.3 points on HRBench-8k, isolating the bias contribution. revision: yes
-
Referee: [Experiments] Experiments / GRPO description: no definition or operationalization of 'valid grounding' is supplied, nor any evidence that the learned policy yields gaze decisions whose spatial selectivity improves downstream reasoning rather than functioning as a fitted heuristic; without this, the central causal claim remains untested.
Authors: We apologize for the lack of explicit definition. Section 3.2 now states that 'valid grounding' is operationalized as a <LOOK> token whose predicted region overlaps the minimal visual evidence required for the current reasoning step, as scored by a reward model trained on human gaze annotations. To test causality, the revision adds a controlled comparison (Table 4) in which the learned policy is replaced by random or saliency-heuristic gazes; both alternatives produce statistically significant drops in downstream accuracy, indicating that the policy acquires task-specific selectivity rather than a generic heuristic. revision: yes
Circularity Check
No circularity: performance claims rest on empirical GRPO training and benchmark results
full rationale
The paper defines GazeVLM via generation of <LOOK> tokens and a suppression bias on the causal mask, trained with GRPO that rewards valid grounding, then reports empirical gains on HRBench-4k/8k. No equations, self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the text. The mechanism and results are presented as trained and measured outcomes rather than derivations that reduce to inputs by construction. The absence of ablations or external gaze validation is a potential correctness concern but does not constitute circularity under the specified criteria.
Axiom & Free-Parameter Ledger
free parameters (1)
- GRPO reward parameters for valid grounding
axioms (1)
- domain assumption Internal generation of gaze tokens can simulate human-like top-down attention control without external mechanisms
invented entities (1)
-
<LOOK> gaze token
no independent evidence
Reference graph
Works this paper leans on
-
[1]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
Xiang An, Yin Xie, et al. Llava-onevision-1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661, 2025
work page internal anchor Pith review arXiv 2025
-
[2]
Niccolo Avogaro, Nayanika Debnath, Li Mi, Thomas Frick, Junling Wang, Zexue He, Hang Hua, Konrad Schindler, and Mattia Rigotti. Sparc: Separating perception and reasoning circuits for test-time scaling of vlms.arXiv preprint arXiv:2602.06566, 2026. URL https: //arxiv.org/abs/2602.06566
-
[3]
Online difficulty filtering for reasoning oriented reinforcement learning
Sanghwan Bae, Jiwoo Hong, Min Young Lee, and Donghyun Kwak. Online difficulty filtering for reasoning oriented reinforcement learning. InProceedings of the European Chapter of the Association for Computational Linguistics (EACL), 2026. URL https://aclanthology. org/2026.eacl-long.30/
work page 2026
-
[4]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, et al. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Shuai Bai, Keqin Chen, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Let there be a clock on the beach: Reducing object hallucination in image captioning
Ali Furkan Biten, Lluis Gomez, Marçal Rusiñol, and Dimosthenis Karatzas. Let there be a clock on the beach: Reducing object hallucination in image captioning. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1381–1390, 2022
work page 2022
-
[8]
Meng Cao, Haoze Zhao, Can Zhang, Xiaojun Chang, Ian Reid, and Xiaodan Liang. Ground- r1: Incentivizing grounded visual reasoning via reinforcement learning.arXiv, 2025. doi: 10.48550/arxiv.2505.20272
-
[9]
Acknowl- edging focus ambiguity in visual questions.arXiv preprint arXiv:2501.02201, 2025
Chongyan Chen, Yu-Yun Tseng, Zhuoheng Li, Anush Venkatesh, and Danna Gurari. Acknowl- edging focus ambiguity in visual questions.arXiv preprint arXiv:2501.02201, 2025
-
[10]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Are we on the right way for evaluating large vision-language models? InAdvances in Neural Information Processing Systems (NeurIPS), 2024. URL https://arxiv.org/abs/ 2403.20330
work page internal anchor Pith review arXiv 2024
-
[11]
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Errui Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites.arXiv preprint arXiv:2404.16821, 2024
work page internal anchor Pith review arXiv 2024
-
[12]
Maurizio Corbetta and Gordon L Shulman. Control of goal-directed and stimulus-driven attention in the brain.Nature reviews neuroscience, 3(3):201–215, 2002
work page 2002
-
[13]
John M Findlay and Iain D Gilchrist.Active vision: The psychology of looking and seeing. Oxford University Press, 2003
work page 2003
-
[14]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaoshen Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749, 2025. URL https://arxiv.org/abs/2503. 06749
work page internal anchor Pith review arXiv 2025
-
[15]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6700–6709, 2019. 11
work page 2019
-
[16]
Mitigating object hallucinations in large vision-language models through visual contrastive decoding
Sicong Leng, Hao Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Liyuan Li. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[17]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 292–305, 2023
work page 2023
-
[18]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26296–26306, 2024
work page 2024
-
[19]
MMBench: Is Your Multi-modal Model an All-around Player?
Yuan Liu, Haodong Duan, Yuanhan Zhang, Xin Li, Rui Zhang, Peiyuan Zhao, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean Conference on Computer Vision (ECCV), 2024. URLhttps://arxiv.org/abs/2307.06281
work page internal anchor Pith review arXiv 2024
-
[20]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Cheng-Ping Hsieh, Haotian Wen, Yaoyao Zhang, Xiaoman Lin, Linlu Qiu, Jianfei Hao, Kyunghyun Cho, Kai-Wei Chang, Yundong Wu, et al. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. InInternational Conference on Learning Representations (ICLR), 2024. URLhttps://arxiv.org/abs/2310.02255
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Argus: Vision-centric reasoning with grounded chain-of- thought
Yunze Man, De-An Huang, Guilin Liu, Shiwei Sheng, Shilong Liu, Liang-Yan Gui, Jan Kautz, Yu-Xiong Wang, and Zhiding Yu. Argus: Vision-centric reasoning with grounded chain-of- thought. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14268–14280, 2025
work page 2025
-
[22]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the Association for Computational Linguistics: ACL 2022, pages 2263–2279, 2022
work page 2022
-
[23]
Minesh Mathew, Viraj Baghel, Dimosthenis Karatzas, and CV Jawahar. Infographicvqa. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1697–1706, 2022
work page 2022
-
[24]
Plotqa: Reasoning over scientific plots
Nitesh Methani, Naman Ganguly, Manohar Radhakrishnan, Mitesh M Khapra, Pratyush Kumar, and V Balaraman. Plotqa: Reasoning over scientific plots. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3527–3536, 2020
work page 2020
-
[25]
Gyu-Min Park and Seong-Bae Park. Gqa-q2q: A large-scale dataset for resolving entity ambiguity in visual question-answering via clarifying subquestion. InInternational Conference on Learning Representations, 2026
work page 2026
-
[26]
Curiosity-driven exploration by self-supervised prediction
Deepak Pathak, Pulkit Agrawal, Alexei A Efros, and Trevor Darrell. Curiosity-driven exploration by self-supervised prediction. InInternational conference on machine learning, pages 2778–
-
[27]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Meng, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world.arXiv preprint arXiv:2306.14824, 2023
work page internal anchor Pith review arXiv 2023
-
[28]
The dynamic representation of scenes.Visual cognition, 7(1-3):17–42, 2000
Ronald A Rensink. The dynamic representation of scenes.Visual cognition, 7(1-3):17–42, 2000
work page 2000
-
[29]
Object hallucination in image captioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image captioning. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4035–4045, 2018
work page 2018
-
[30]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. URLhttps://arxiv.org/abs/2402.03300. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Cambrian-1: A fully open, vision-centric exploration of multimodal llms
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[32]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Haozhe Wang, Alex Su, Weiming Ren, Fangzhen Lin, and Wenhu Chen. Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning.arXiv, 2025. doi: 10.48550/arxiv.2505.15966
work page internal anchor Pith review doi:10.48550/arxiv.2505.15966 2025
-
[33]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Wenbin Wang, Liang Ding, Minyan Zeng, Xiabin Zhou, Li Shen, Yong Luo, Wei Yu, and Dacheng Tao. Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 7907–7915, 2025
work page 2025
-
[35]
Yujun Wang, Aniri, Jinhe Bi, Yunpu Ma, and Soeren Pirk. Ascd: Attention-steerable contrastive decoding for reducing hallucination in mllm. InProceedings of the AAAI Conference on Artificial Intelligence, 2026. URLhttps://arxiv.org/abs/2506.14766
-
[36]
Penghao Wu and Saining Xie. V*: Guided visual search as a core mechanism in multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. URLhttps://arxiv.org/abs/2312.14135
-
[37]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v.arXiv preprint arXiv:2310.11441, 2023
work page internal anchor Pith review arXiv 2023
- [38]
-
[39]
Ferret: Refer and ground anything anywhere at any granularity
Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, and Yinfei Yang. Ferret: Refer and ground anything anywhere at any granularity. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[40]
Xintong Zhang, Zhi Gao, Bofei Zhang, Pengxiang Li, Xiaowen Zhang, Yang Liu, Tao Yuan, Yuwei Wu, Yunde Jia, Song-Chun Zhu, and Qing Li. Adaptive chain-of-focus reasoning via dynamic visual search and zooming for efficient vlms.arXiv preprint arXiv:2505.15436, 2025. URLhttps://arxiv.org/abs/2505.15436
-
[41]
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alexander J Smola. Multimodal chain-of-thought reasoning in language models.Transactions on Machine Learning Research, 2023. URLhttps://openreview.net/forum?id=y1pPWFVfvR
work page 2023
-
[42]
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing "thinking with images" via reinforcement learning.arXiv,
-
[43]
doi: 10.48550/arxiv.2505.14362
work page internal anchor Pith review doi:10.48550/arxiv.2505.14362
-
[44]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 13 A Supplementary Material A.1 Details on our curated dataset for SFT and GRPO In this section, we provide comprehensive details regarding the data generation and filtering pipeline used to train GazeVLM....
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.