Recognition: no theorem link
Text-Guided Multi-Scale Frequency Representation Adaptation
Pith reviewed 2026-05-12 01:21 UTC · model grok-4.3
The pith
Text-guided multi-scale frequency adaptation reduces redundancy in fine-tuning pre-trained models and achieves one-epoch convergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FreqAdapter integrates textual information and performs multi-scale fine-tuning of signals in the frequency domain, along with a multi-scale adaptation strategy to optimize receptive fields across different frequency ranges, thereby improving representational capacity and yielding better performance and efficiency than prior methods that stay in the signal space with fixed prompts.
What carries the argument
FreqAdapter, which shifts adaptation to the frequency domain, incorporates text guidance, and applies multi-scale receptive fields to reduce redundancy while handling multi-scale signal properties.
If this is right
- It reduces the information redundancy that arises when adaptation stays in the signal space domain.
- It captures multi-scale characteristics of signals that fixed prompts ignore.
- It delivers performance improvements on multimodal models such as CLIP and LLaVA at minimal added parameter cost.
- It reaches effective adaptation with convergence inside a single epoch.
Where Pith is reading between the lines
- The frequency-domain approach may transfer to other modalities such as audio or time-series data where spectral representations are already natural.
- If frequency adaptation systematically lowers redundancy, future work could combine it with other parameter-efficient techniques to shrink adapter sizes further.
- Testing whether dynamically chosen scales per input outperform the fixed multi-scale design would clarify the necessity of the current strategy.
Load-bearing premise
That performing adaptation in the frequency domain with text guidance and multi-scale receptive fields will reduce information redundancy and overcome fixed-prompt limitations without introducing new representational or optimization problems.
What would settle it
If direct comparisons on CLIP and LLaVA benchmarks show no accuracy gains over baselines, require more than one epoch to converge, or produce frequency representations with equal or higher redundancy than spatial ones, the central claims would be falsified.
Figures

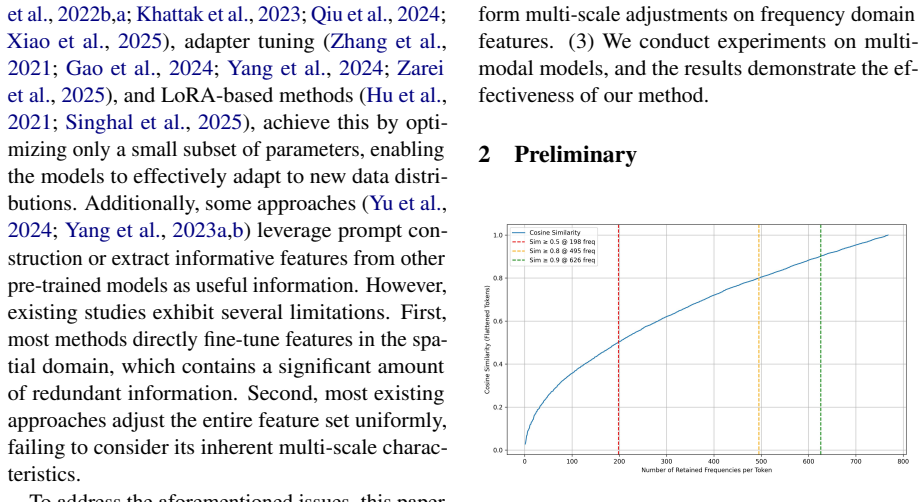
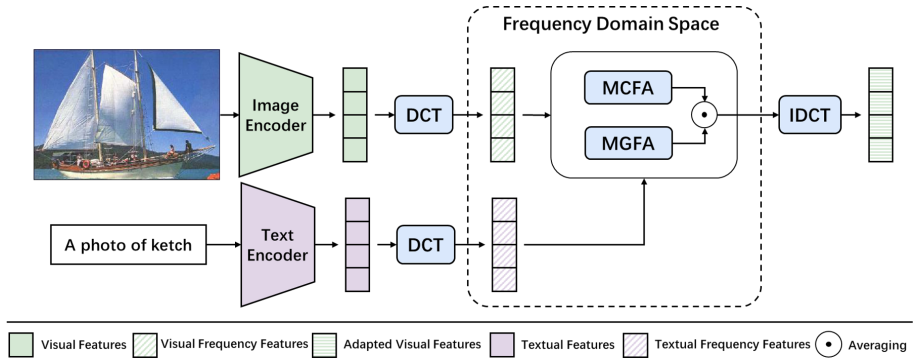



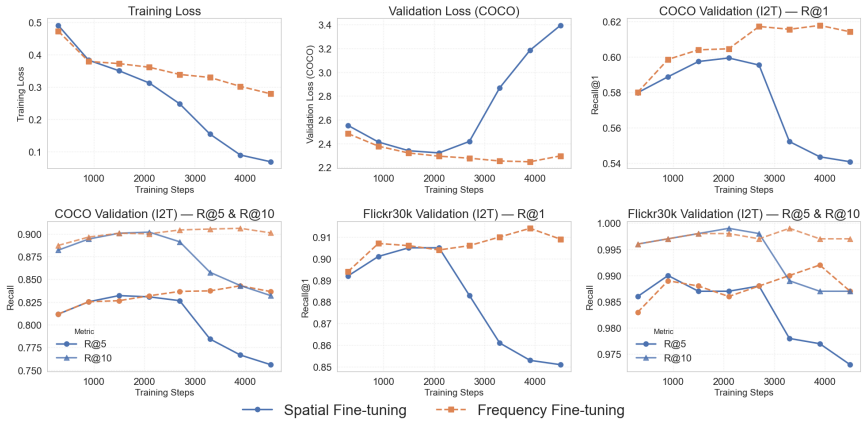







read the original abstract
Parameter-efficient fine-tuning methods introduce a small number of training parameters, enabling pre-trained models to adapt rapidly to new data distributions. While these methods have shown promising results, they exhibit notable limitations. First, most existing methods operate in the signal space domain, which results in substantial information redundancy. Second, most existing methods utilize fixed prompts or adaptation layers, failing to fully account for the multi-scale characteristics of signals. To address these challenges, we propose the Multi-Scale Frequency Adapter (FreqAdapter), which integrates textual information and performs multi-scale fine-tuning of signals in the frequency domain. Additionally, we introduce a multi-scale adaptation strategy to optimize receptive fields across different frequency ranges, further enhancing the model's representational capacity. Extensive experiments on multimodal models, including CLIP and LLaVA, demonstrate that FreqAdapter significantly improves both performance and efficiency. FreqAdapter improves performance with minimal cost and fast convergence within one epoch. Code is available at https://github.com/Kelvin-ywc/FreqAdapter.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Multi-Scale Frequency Adapter (FreqAdapter) for parameter-efficient fine-tuning of multimodal models including CLIP and LLaVA. It shifts adaptation to the frequency domain, incorporates text guidance, and employs a multi-scale strategy to address information redundancy in signal-space methods and the limitations of fixed prompts or adaptation layers. The authors report that FreqAdapter yields performance gains with near-zero added parameters relative to the backbone and converges within a single epoch, supported by experiments and ablations on scale and text components.
Significance. If the empirical results hold, this offers a practical frequency-domain approach to adaptation that reduces redundancy while adding text guidance and multi-scale receptive fields, with clear efficiency benefits for vision-language models. The low parameter overhead, one-epoch convergence, and ablations on the multi-scale and text elements are notable strengths; code availability further supports reproducibility.
minor comments (3)
- [Abstract] Abstract: the statement that FreqAdapter 'significantly improves both performance and efficiency' would be strengthened by including at least one concrete metric (e.g., accuracy delta or FLOPs reduction) rather than remaining purely qualitative.
- [Method] Method section: the integration of text guidance into the frequency-domain adapter is described at a high level; a short pseudocode block or explicit equation for the text-conditioned frequency modulation would improve reproducibility.
- [Experiments] Experiments: while ablations on scale and text components are mentioned, ensure that all compared baselines report their exact parameter counts and training epochs in a single table for direct efficiency comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive and positive review of our work on FreqAdapter. We appreciate the recognition of the method's efficiency advantages, one-epoch convergence, ablations, and code release. The recommendation for minor revision is noted with gratitude.
Circularity Check
No significant circularity; empirical method with external validation
full rationale
The paper proposes FreqAdapter as an empirical adaptation technique operating in the frequency domain with text guidance and multi-scale receptive fields. Claims of performance and efficiency gains are supported by experiments on CLIP and LLaVA, ablations on scale/text components, and reported parameter counts with one-epoch convergence. No derivation chain, equations, or first-principles results are presented that reduce to inputs by construction. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Multi-Scale Frequency Adapter (FreqAdapter)
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Publications Manual , year = "1983", publisher =
work page 1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
- [4]
-
[5]
Dan Gusfield , title =. 1997
work page 1997
-
[6]
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
work page 2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae , month=. LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
-
[9]
Improved Baselines with Visual Instruction Tuning , author=
-
[10]
Visual Instruction Tuning , author=
-
[11]
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
work page 2023
-
[12]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Conditional Prompt Learning for Vision-Language Models , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[13]
International Journal of Computer Vision (IJCV) , year=
Learning to Prompt for Vision-Language Models , author=. International Journal of Computer Vision (IJCV) , year=
-
[14]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
MMA: Multi-Modal Adapter for Vision-Language Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[15]
LoRA: Low-Rank Adaptation of Large Language Models
Lora: Low-rank adaptation of large language models , author=. arXiv preprint arXiv:2106.09685 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
International Journal of Computer Vision , volume=
Clip-adapter: Better vision-language models with feature adapters , author=. International Journal of Computer Vision , volume=. 2024 , publisher=
work page 2024
-
[17]
Advances in Neural Information Processing Systems , year=
Attention is all you need , author=. Advances in Neural Information Processing Systems , year=
-
[18]
arXiv preprint arXiv:2304.06446 , year=
SpectFormer: Frequency and Attention is what you need in a Vision Transformer , author=. arXiv preprint arXiv:2304.06446 , year=
-
[19]
International conference on machine learning , pages=
Scaling up visual and vision-language representation learning with noisy text supervision , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
- [20]
-
[21]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[22]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Maple: Multi-modal prompt learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[23]
The Twelfth International Conference on Learning Representations , year=
Federated Text-driven Prompt Generation for Vision-Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[24]
arXiv preprint arXiv:2111.03930 , year=
Tip-adapter: Training-free clip-adapter for better vision-language modeling , author=. arXiv preprint arXiv:2111.03930 , year=
-
[25]
Git: A generative image-to-text transformer for vision and language.ArXiv, abs/2205.14100, 2022
Git: A generative image-to-text transformer for vision and language , author=. arXiv preprint arXiv:2205.14100 , year=
-
[26]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
work page 2023
-
[27]
Microsoft coco: Common objects in context , author=. Computer vision--ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part v 13 , pages=. 2014 , organization=
work page 2014
-
[28]
Proceedings of the IEEE international conference on computer vision , pages=
Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[29]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Mm-vet: Evaluating large multimodal models for integrated capabilities , author=. arXiv preprint arXiv:2308.02490 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[31]
European Conference on Computer Vision , pages=
Attention prompting on image for large vision-language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[32]
Advances in Neural Information Processing Systems , volume=
Fine-grained visual prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v , author=. arXiv preprint arXiv:2310.11441 , year=
work page internal anchor Pith review arXiv
-
[34]
2018 IEEE winter conference on applications of computer vision (WACV) , pages=
Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks , author=. 2018 IEEE winter conference on applications of computer vision (WACV) , pages=. 2018 , organization=
work page 2018
-
[35]
Advances in Neural Information Processing Systems , volume=
Visual fourier prompt tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Advances in neural information processing systems , volume=
Qlora: Efficient finetuning of quantized llms , author=. Advances in neural information processing systems , volume=
-
[37]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Adalora: Adaptive budget allocation for parameter-efficient fine-tuning , author=. arXiv preprint arXiv:2303.10512 , year=
work page internal anchor Pith review arXiv
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Xu, Kai and Qin, Minghai and Sun, Fei and Wang, Yuhao and Chen, Yen-Kuang and Ren, Fengbo , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[39]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Unleashing channel potential: Space-frequency selection convolution for SAR object detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[40]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Boosting diffusion models with moving average sampling in frequency domain , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[41]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Revisiting Spatial-Frequency Information Integration from a Hierarchical Perspective for Panchromatic and Multi-Spectral Image Fusion , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[42]
Can Jin and Ying Li and Mingyu Zhao and Shiyu Zhao and Zhenting Wang and Xiaoxiao He and Ligong Han and Tong Che and Dimitris N. Metaxas , booktitle=. LoR-. 2025 , url=
work page 2025
-
[43]
Learning Transferable Visual Models From Natural Language Supervision , author=. ICML , year=
-
[44]
Ilharco, Gabriel and Wortsman, Mitchell and Wightman, Ross and Gordon, Cade and Carlini, Nicholas and Taori, Rohan and Dave, Achal and Shankar, Vaishaal and Namkoong, Hongseok and Miller, John and Hajishirzi, Hannaneh and Farhadi, Ali and Schmidt, Ludwig , title =. doi:10.5281/zenodo.5143773 , url =
-
[45]
FedEx-LoRA: Exact aggregation for federated and efficient fine-tuning of large language models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[46]
International Journal of Computational Intelligence Systems , volume=
Dual Adapter Tuning of Vision--Language Models Using Large Language Models , author=. International Journal of Computational Intelligence Systems , volume=. 2025 , publisher=
work page 2025
-
[47]
arXiv preprint arXiv:2507.07796 , year=
Visual instance-aware prompt tuning , author=. arXiv preprint arXiv:2507.07796 , year=
-
[48]
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
LLaVA-OneVision: Easy Visual Task Transfer
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Seed1. 5-vl technical report , author=. arXiv preprint arXiv:2505.07062 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
IEEE Transactions on Image Processing , volume=
Spatial-Frequency Enhanced Mamba for Multi-Modal Image Fusion , author=. IEEE Transactions on Image Processing , volume=. 2025 , publisher=
work page 2025
-
[52]
arXiv preprint arXiv:2409.19658 , year=
Dual-Attention Frequency Fusion at Multi-Scale for Joint Segmentation and Deformable Medical Image Registration , author=. arXiv preprint arXiv:2409.19658 , year=
-
[53]
Towards text-refereed multi-modal image fusion by cross-modality interaction , author=. Signal Processing , volume=. 2025 , publisher=
work page 2025
-
[54]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Chat-driven text generation and interaction for person retrieval , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[55]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Boosting speech recognition robustness to modality-distortion with contrast-augmented prompts , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[56]
Xize Cheng and Dongjie Fu and Chenyuhao Wen and Shannon Yu and Zehan Wang and Shengpeng Ji and Siddhant Arora and Tao Jin and Shinji Watanabe and Zhou Zhao , booktitle=. 2025 , url=
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.