Recognition: 2 theorem links
· Lean TheoremHTPO: Towards Exploration-Exploitation Balanced Policy Optimization via Hierarchical Token-level Objective Control
Pith reviewed 2026-05-12 00:47 UTC · model grok-4.3
The pith
HTPO partitions LLM response tokens by prompt difficulty, answer correctness, and entropy to assign specialized objectives that balance exploration and exploitation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HTPO takes a divide-and-conquer approach to hierarchically partition response tokens into functional groups from prompt difficulty, answer correctness, and token entropy; within each group it designs specialized optimization objectives according to the tokens' contributions to exploration or exploitation, thereby achieving a more balanced trade-off than uniform token treatment in standard RLVR.
What carries the argument
Hierarchical Token-level Objective Control, which partitions tokens into groups from three aspects and applies contribution-based specialized objectives inside each group.
If this is right
- Models trained with HTPO reach higher accuracy on challenging reasoning benchmarks such as AIME'24 and AIME'25.
- The performance advantage over DAPO grows as the number of test-time samples increases.
- The method supports effective exploration while preserving strong exploitation on correct reasoning paths.
- Token-level grouping supplies a concrete way to give different parts of a chain-of-thought distinct optimization targets.
Where Pith is reading between the lines
- The same three-way partitioning could be tried inside other policy-gradient or preference-tuning algorithms to add granularity without changing the overall RL framework.
- If the entropy and correctness signals remain informative outside math, the approach might transfer to coding or scientific reasoning tasks where token roles also vary.
- Adding a fourth grouping axis such as token position within the chain-of-thought could be tested as a direct extension to further refine control.
Load-bearing premise
Partitioning response tokens into groups based on prompt difficulty, answer correctness, and token entropy, then applying specialized objectives within each group, supplies an effective dynamic mechanism to balance exploration and exploitation.
What would settle it
Training an LLM with HTPO and then measuring accuracy on AIME'24 or AIME'25; if the scores are no higher than those from the DAPO baseline under identical training and sampling budgets, or if the gap does not widen with increased test-time samples, the central claim would not hold.
Figures










read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a pivotal technique for enhancing the reasoning capabilities of Large Language Models (LLMs). However, the de facto practice of mainstream RL algorithms is to treat all tokens of one response equally and assign the same optimization objective to each token, failing to provide granular guidance for the reasoning process. While in Chain-of-Thought (CoT) reasoning, different tokens usually play distinct roles. Therefore, the current RL algorithms lack an effective mechanism to dynamically balance the exploration-exploitation trade-off during learning. To this end, we propose Hierarchical Token-level Objective Control Policy Optimization (HTPO), a novel RL algorithm that takes the divide-and-conquer idea to hierarchically partition the response tokens into specific functional groups from three aspects (i.e., prompt difficulty, answer correctness, and token entropy). Within each group, according to the contributions to exploration or exploitation, we design specialized optimization objectives to facilitate the effective execution of each token's expected functionality. In this way, HTPO can achieve a more balanced exploration-exploitation trade-off. Extensive experiments on challenging reasoning benchmarks validate the superiority of our HTPO algorithm, which significantly outperforms the strong DAPO baseline (e.g., +8.6% and +6.7% on AIME'24 and AIME'25, respectively). When scaling test-time compute, the HTPO-trained model maintains a consistent performance advantage over the DAPO baseline, and the gap widens as the sampling budget increases, validating that our adaptive token-level control method fosters effective exploration without sacrificing exploitation performance. Code will be at https://github.com/xcyao00/HTPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Hierarchical Token-level Objective Control Policy Optimization (HTPO), an RLVR algorithm for LLMs that hierarchically partitions response tokens into functional groups according to prompt difficulty, answer correctness, and token entropy. Within each group, specialized optimization objectives are assigned based on their contributions to exploration or exploitation. The central claim is that this divide-and-conquer approach supplies a dynamic mechanism for balancing the exploration-exploitation trade-off that is absent when all tokens receive the same objective (as in standard RLVR and the DAPO baseline). Experiments report that HTPO significantly outperforms DAPO (+8.6% on AIME'24, +6.7% on AIME'25) and maintains a widening advantage as test-time sampling budget increases.
Significance. If the reported gains are causally attributable to the hierarchical token partitioning and group-specific objectives rather than other training differences, the method could advance token-level control in reasoning RL. The planned public code release is a positive for reproducibility. However, the significance is currently limited by the absence of implementation details, ablations, and statistical validation needed to confirm the mechanism.
major comments (3)
- [§3] §3 (Method): The exact definitions and computation procedures for the three partitioning criteria (prompt difficulty quantification, answer correctness labeling, and token entropy, including whether entropy is computed on-policy) are not provided, nor are the specialized per-group objective formulations. Without these, it is impossible to verify that the claimed dynamic balance is implemented as described or to reproduce the +8.6% / +6.7% gains.
- [§4] §4 (Experiments): No ablation studies isolate the contribution of each grouping dimension or the group-specific objectives versus a uniform-objective baseline with otherwise identical hyperparameters. Consequently the performance lifts and the widening test-time scaling gap cannot be confidently attributed to the hierarchical control rather than reward scaling, implementation details, or hyperparameter differences from DAPO.
- [§4.2] §4.2 (Scaling results): The claim that the performance gap widens with increased sampling budget lacks reported variance, number of runs, or statistical tests. This weakens the assertion that HTPO fosters effective exploration without sacrificing exploitation.
minor comments (1)
- Ensure the promised GitHub repository (https://github.com/xcyao00/HTPO) is populated with the exact grouping thresholds, objective equations, and training scripts upon publication to support the reproducibility claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that additional details, ablations, and statistical reporting are needed to strengthen the claims and will revise the manuscript accordingly. Below we respond to each major comment.
read point-by-point responses
-
Referee: [§3] §3 (Method): The exact definitions and computation procedures for the three partitioning criteria (prompt difficulty quantification, answer correctness labeling, and token entropy, including whether entropy is computed on-policy) are not provided, nor are the specialized per-group objective formulations. Without these, it is impossible to verify that the claimed dynamic balance is implemented as described or to reproduce the +8.6% / +6.7% gains.
Authors: We agree that the original manuscript did not include sufficient mathematical detail on the partitioning criteria and per-group objectives. In the revised version we will expand §3 with exact definitions and computation procedures: prompt difficulty will be quantified via a normalized difficulty score derived from model performance on similar prompts; answer correctness will be labeled using the verifiable reward signal; token entropy will be specified as on-policy entropy computed from the current policy during training. We will also provide the closed-form expressions for the specialized objectives assigned to each functional group (exploration-oriented vs. exploitation-oriented) together with pseudocode for the hierarchical grouping step. These additions will make the dynamic balance mechanism fully verifiable and reproducible. revision: yes
-
Referee: [§4] §4 (Experiments): No ablation studies isolate the contribution of each grouping dimension or the group-specific objectives versus a uniform-objective baseline with otherwise identical hyperparameters. Consequently the performance lifts and the widening test-time scaling gap cannot be confidently attributed to the hierarchical control rather than reward scaling, implementation details, or hyperparameter differences from DAPO.
Authors: We acknowledge that the current experiments lack the requested ablations. We will add a dedicated ablation subsection that (i) removes each grouping dimension in turn while keeping the remaining two, (ii) replaces the group-specific objectives with a single uniform objective under identical hyperparameters and training budget, and (iii) reports the resulting performance on AIME'24/25. These controlled comparisons will allow readers to attribute gains specifically to the hierarchical token-level control rather than other factors. revision: yes
-
Referee: [§4.2] §4.2 (Scaling results): The claim that the performance gap widens with increased sampling budget lacks reported variance, number of runs, or statistical tests. This weakens the assertion that HTPO fosters effective exploration without sacrificing exploitation.
Authors: We agree that the scaling analysis requires statistical support. In the revised §4.2 we will report results averaged over multiple independent runs (with different random seeds), include error bars or standard deviations, and apply paired statistical tests (e.g., t-tests) between HTPO and DAPO at each sampling budget. This will provide rigorous evidence that the widening gap reflects improved exploration-exploitation balance rather than noise. revision: yes
Circularity Check
No circularity: algorithmic proposal with external empirical validation
full rationale
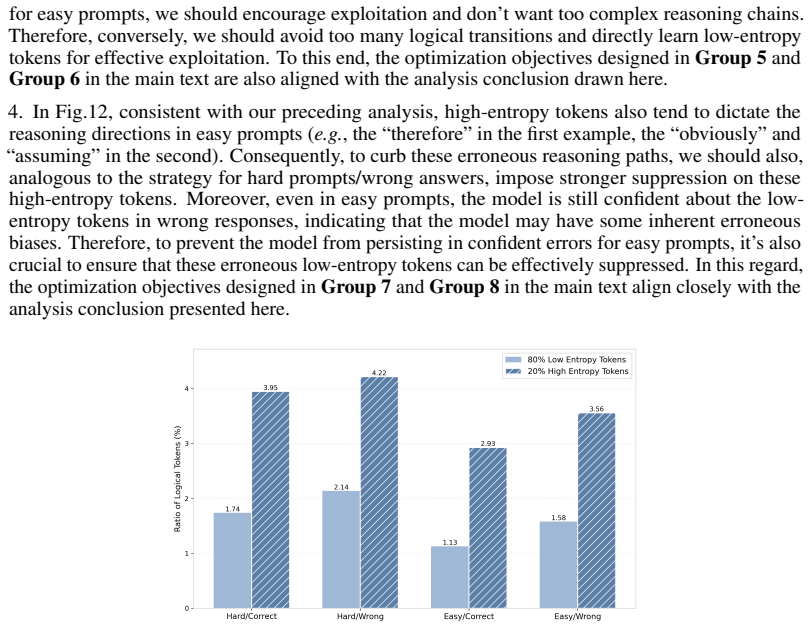
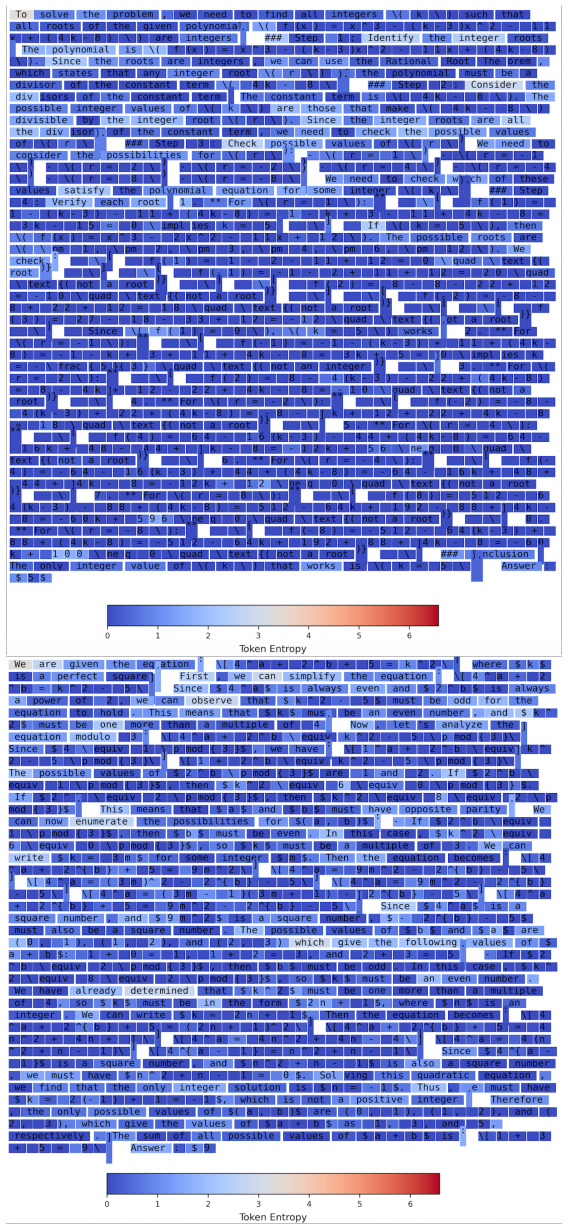
The paper introduces HTPO as a new RLVR algorithm that hierarchically partitions response tokens by prompt difficulty, answer correctness, and token entropy, then applies group-specific optimization objectives. No equations, derivations, or first-principles results are claimed that reduce by construction to fitted parameters or self-defined quantities. The central claims rest on empirical outperformance versus the DAPO baseline on AIME benchmarks and test-time scaling experiments, which are independent external evaluations rather than self-referential predictions. Any self-citations (if present for DAPO or related methods) are not load-bearing for the uniqueness or correctness of the partitioning scheme, satisfying the criteria for a self-contained proposal.
Axiom & Free-Parameter Ledger
free parameters (1)
- grouping thresholds for difficulty, correctness, and entropy
axioms (1)
- domain assumption Different tokens in Chain-of-Thought responses play distinct roles that can be captured by prompt difficulty, answer correctness, and token entropy.
invented entities (1)
-
Hierarchical functional groups of tokens
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/reality_from_one_distinctionreality_from_one_distinction echoeshierarchically partition the response tokens into eight functional groups from three aspects (i.e., prompt difficulty, answer correctness, and token entropy)
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclearGroup 1 ... Group 8 ... Jt(θ) = ... specialized optimization objectives
Reference graph
Works this paper leans on
-
[1]
Claude 3.7 sonnet.https://www.anthropic.com/claude/sonnet, 2025
Anthropic. Claude 3.7 sonnet.https://www.anthropic.com/claude/sonnet, 2025
work page 2025
-
[2]
Introducing claude opus 4.6.https://www.anthropic.com/news/claude-opus-4-6, 2025
Anthropic. Introducing claude opus 4.6.https://www.anthropic.com/news/claude-opus-4-6, 2025
work page 2025
-
[3]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv: 2505.22617, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv: 2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Kto: Model alignment as prospect theoretic optimization.In ICML, 2024
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Kto: Model alignment as prospect theoretic optimization.In ICML, 2024
work page 2024
-
[6]
arXiv preprint arXiv:2511.20347 , year=
Chang Gao, Chujie Zheng, Xiong-Hui Chen, Kai Dang, Shixuan Liu, Bowen Yu, An Yang, Shuai Bai, Jingren Zhou, and Junyang Lin. Soft adaptive policy optimization.arXiv preprint arXiv: 2511.20347, 2025
-
[7]
Shangmin Guo, Biao Zhang, Tianlin Liu, Tianqi Liu, Misha Khalman, Felipe Llinares, Alexan- dre Rame, Thomas Mesnard, Yao Zhao, Bilal Piot, Johan Ferret, and Mathieu Blondel. Direct language model alignment from online ai feedback.arXiv preprint arXiv: 2402.04792, 2024
-
[8]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems.In Proceedings of the 62nd Annual Meeting of the Association for Computa...
work page 2024
-
[9]
Jiwoo Hong, Noah Lee, and James Thornen. Orpo: Monolithic preference optimization without reference model.arXiv preprint arXiv: 2403.07691, 2024
-
[10]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model.arXiv preprint arXiv: 2503.24290, 2025
work page internal anchor Pith review arXiv 2025
-
[11]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv: 2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Binary classifier optimization for large language model alignment.In ACL, 2025
Seungjae Jung, Gunsoo Han, Daniel Wontae Nam, and Kyoung-Woon On. Binary classifier optimization for large language model alignment.In ACL, 2025
work page 2025
-
[13]
Ang Li, Zhihang Yuan, Yang Zhang, Shouda Liu, and Yisen Wang. Know when to explore: Difficulty-aware certainty as a guide for llm reinforcement learning.arXiv preprint arXiv: 2509.00125, 2025
-
[14]
Zicheng Lin, Tian Liang, Jiahao Xu, Xing Wang, Ruilin Luo, Chufan Shi, Siheng Li, Yujiu Yang, and Zhaopeng Tu. Critical tokens matter: Token-level contrastive estimation enhence llm’s reasoning capability.arXiv preprint arXiv: 2411.19943, 2024
-
[15]
Simpo: Simple preference optimization with a reference-free reward.In NeurIPS, 2024
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward.In NeurIPS, 2024
work page 2024
- [16]
-
[17]
American invitational mathematics examination 2024
Mathematical Association of America. American invitational mathematics examination 2024. https://artofproblemsolving.com/wiki/index.php/AIME_Problems_and_Solutions, 2024
work page 2024
-
[18]
American invitational mathematics examination 2025
Mathematical Association of America. American invitational mathematics examination 2025. https://artofproblemsolving.com/wiki/index.php/AIME_Problems_and_Solutions, 2025
work page 2025
-
[19]
Learning to reason with llms.https://openai.com/index/ learning-to-reason-with-llms/, 2024
OpenAI. Learning to reason with llms.https://openai.com/index/ learning-to-reason-with-llms/, 2024
work page 2024
-
[20]
Introducing gpt-5.2.https://openai.com/index/introducing-gpt-5-2/, 2025
OpenAI. Introducing gpt-5.2.https://openai.com/index/introducing-gpt-5-2/, 2025
work page 2025
-
[21]
Training language models to follow instructions with human feedback.In NeurIPS, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and et al. Training language models to follow instructions with human feedback.In NeurIPS, 2022
work page 2022
-
[22]
Team Qwen. Qwen3 technical report.arXiv preprint arXiv: 2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In NeurIPS, 2023
work page 2023
-
[24]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv: 1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
ByteDance Seed. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv: 2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language modelss.arXiv preprint arXiv: 2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Cote, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.In Proceedings of the International Conference on Learning Representations, 2021
work page 2021
-
[29]
Gemini Team. Gemini 3 flash: frontier intelligence built for speed.https://blog.google/products- and-platforms/products/gemini/gemini-3-flash//, 2025
work page 2025
-
[30]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
GLM-4.5 Team. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv: 2508.06471, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi Team. Kimi k1.5: Scaling reinforcement learning with llms.arXiv preprint arXiv: 2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Kimi K2: Open Agentic Intelligence
Kimi Team. Kimi k2: Open agentic intelligence.arXiv preprint arXiv: 2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Tongyi deepresearch technical report.arXiv preprint arXiv:2510.24701, 2025
Tongyi DeepResearch Team. Tongyi deepresearch technical report.arXiv preprint arXiv: 2510.24701, 2025
-
[34]
Jean Vassoyan, Nathanaël Beau, and Roman Plaud. Ignore the kl penalty! boosting exploration on critical tokens to enhance rl fine-tuning.arXiv preprint arXiv: 2502.06533, 2025
-
[35]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.arXiv preprint arXiv: 2506.01939, 2025
work page internal anchor Pith review arXiv 2025
- [36]
-
[37]
arXiv preprint arXiv:2510.18927 , year=
Zhiheng Xi, Xin Guo, Yang Nan, Enyu Zhou, Junrui Shen, Wenxiang Chen, Jiaqi Liu, Jixuan Huang, Zhihao Zhang, Honglin Guo, Xun Deng, Zhikai Lei, Miao Zheng, Guoteng Wang, Shuo Zhang, Peng Sun, Rui Zheng, Hang Yan, Tao Gui, Qi Zhang, and Xuanjing Huang. Bapo: Stabilizing off-policy reinforcement learning for llms via balanced policy optimization with adapti...
-
[38]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable realworld web interaction with grounded language agents.In Proceedings of the Advances in Neural Information Processing Systems, 2022
work page 2022
-
[39]
Chen Wang, Lai Wei, Yanzhi Zhang, Chenyang Shao, Zedong Dan, Weiran Huang, Yuzhi Zhang, and Yue Wang
YipingWang, Qing Yang, Zhiyuan Zeng, Liliang Ren, Lucas Liu, Baolin Peng, Hao Cheng, Xuehai He, Kuan Wang, Jianfeng Gao, Weizhu Chen, Shuohang Wang, Simon Shaolei Du, and Yelong Shen. Reinforcement learning for reasoning in large language models with one training example.arXiv preprint arXiv: 2504.20571, 2025
-
[40]
Why is rlhf alignment shallow? a gradient analysis.arXiv preprint arXiv: 2603.04851, 2026
Robin Young. Why is rlhf alignment shallow? a gradient analysis.arXiv preprint arXiv: 2603.04851, 2026
-
[41]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv preprint arXiv: 2504.13837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Yu Yue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, TianTian Fan, Zhengyin Du, Xiangpeng Wei, Xiangyu Yu, Gaohong Liu, Juncai Liu, Lingjun Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Ru Zhang, Xin Liu, Mingxuan Wang, YonghuiWu, and Lin Yan. Vapo: Efficient and reliable rein...
work page internal anchor Pith review arXiv 2025
-
[43]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv: 2503.18892, 2025
work page internal anchor Pith review arXiv 2025
-
[44]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization.arXiv preprint arXiv: 2507.18071, 2025. 13 Appendix A Limitations and Social Impacts A.1 Limitations Previous RL improvement methods have primarily focused on dense credit ass...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
The score function ∇θ logπ θ(ot|st) is L-Lipschitz continuous in θ, where we define st := (q, o<t)for brevity. 2.∥∇ θ logπ θ(ot|st)∥ ≤G max for allo t, st, θ. Assumption 2(Advantage-Weighted Gradient Direction Stability).There exists a unit reference directiond ∗ such that for all tokenso t in the training batch: ⟨ ˆAt · ∇θ logπ θ(ot|st),d ∗⟩ | ˆAt| · ∥∇θ...
work page 2048
-
[46]
Tokens with the highest entropy are typically the logical connection or transition words, such as “however” and “unless” (indicating logical contrasts or shifts), “hence” and “therefore” (presenting progressive reasoning), or “since” and “because” (expressing causality). Similarly, tokens like “suppose”, “given” and “let” frequently appear in mathematical...
-
[47]
By contrast, tokens with the lowest entropy tend to words that just complete the current sentence or sub-words that finish constructing a word, all of which don’t directly affect the reasoning logic and exhibit high certainty. Our analysis results are also consistent with the conclusion drawn in the previous work [ 35]. In Chain-of-Thought (CoT) reasoning...
-
[48]
Regardless of hard/easy prompts or correct/wrong responses, logical tokens mainly exist in high- entropy tokens, whereas low-entropy tokens usually consist of words that have minimal impact on the reasoning process (this does not imply that there are no logical words, such as “therefore”, “since” and “but”, in low-entropy tokens, but the quantity is relat...
-
[49]
Compared to correct responses, the model exhibits higher uncertainty in incorrect responses. The entropy of high-entropy tokens in wrong responses is overall higher than that of high-entropy tokens in correct ones. The two token patterns observed above also validate the motivation rationale behind our algorithmic design. Specifically, in correct responses...
-
[50]
As illustrated in Fig.9, for correct responses to hard prompts, high-entropy tokens predominantly correspond to logical connectors, such as “since”, “consider”, “if”, “which”, and “thus”, etc. In con- trast, low-entropy tokens primarily consist of mathematical expressions that should be deterministic knowledge of the model. Given the complexity of hard pr...
-
[51]
In Fig.10, compared to Fig.9, the model exhibits higher uncertainty in wrong responses (i.e., the entropy of high-entropy tokens in wrong responses is overall higher than that in correct ones). These high-entropy tokens also contain many logical connection words, such as “leading”, “ultimately”, “clearly”, “therefore” and “thus”, etc, which often tend to ...
-
[52]
In Fig.11, mirroring the patterns observed in hard prompts, in easy prompts, the logical words exhibit a similar preference for appearing as high-entropy tokens. However, unlike hard prompts, 24 for easy prompts, we should encourage exploitation and don’t want too complex reasoning chains. Therefore, conversely, we should avoid too many logical transition...
-
[53]
In Fig.12, consistent with our preceding analysis, high-entropy tokens also tend to dictate the reasoning directions in easy prompts (e.g., the “therefore” in the first example, the “obviously” and “assuming” in the second). Consequently, to curb these erroneous reasoning paths, we should also, analogous to the strategy for hard prompts/wrong answers, imp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.