Recognition: 2 theorem links
· Lean TheoremLLMSYS-HPOBench: Hyperparameter Optimization Benchmark Suite for Real-World LLM Systems
Pith reviewed 2026-05-12 01:18 UTC · model grok-4.3
The pith
A benchmark suite supplies real run data from large language model systems to support hyperparameter optimization research.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
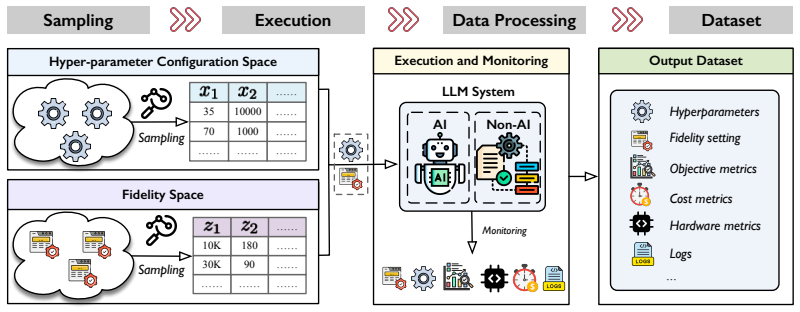
No existing benchmark captures the full mix of AI and non-AI hyperparameters, fidelity implications, and cost diversity that appear when optimizing real LLM systems; LLMSYS-HPOBench addresses this by releasing datasets of inference objective values obtained from actual system runs, currently containing 364450 configurations with 12-23 dimensions, 3-5 fidelity dimensions that produce 932 settings, 3-9 objective metrics, 2-10 cost metrics, and the generated measurement logs.
What carries the argument
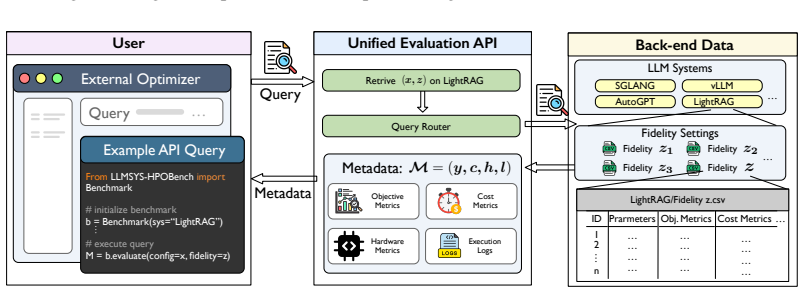
LLMSYS-HPOBench, the suite that aggregates profiled inference objective values and cost data from hyperparameter configurations executed on live LLM systems.
If this is right
- Existing HPO algorithms can now be revalidated directly against data from frontier LLM systems rather than synthetic or simplified proxies.
- AutoML methods can be developed that explicitly handle mixed AI and system hyperparameters together with fidelity and cost trade-offs.
- The live nature of the suite permits ongoing addition of new LLM systems and workloads as the field evolves.
- Improved HPO on these benchmarks could translate into lower inference latency or resource use in deployed LLM applications.
Where Pith is reading between the lines
- The benchmark may reveal that standard HPO techniques require substantial adaptation to manage the high-dimensional mixed spaces and variable costs typical of LLM serving.
- Researchers could use the provided logs to derive new cost models that predict measurement expense before running full configurations.
- Integration with automated deployment tools might allow closed-loop optimization where HPO results feed back into live system tuning.
Load-bearing premise
The specific LLM systems and profiled runs used to build the datasets represent the compound spaces, nonlinear fidelities, and cost patterns found across wider real-world LLM deployments.
What would settle it
Demonstrating that hyperparameter optimization algorithms tuned on this benchmark produce no measurable gains when applied to independent, production-scale LLM deployments would undermine the claim of representativeness.
Figures



read the original abstract
Large Language Model (LLM) systems have been the frontier of AI in many application domains, leading to new challenges and opportunities for hyperparameter optimization (HPO) for the AutoML community. However, this type of system exhibits an unprecedented compound space of hyperparameter configuration from both the AI and non-AI components; rich and nonlinear implications from the fidelity factors; and diverse costs of measuring hyperparameter configurations, none of which have been fully captured in existing benchmarks. This paper presents the first (live) benchmark suite and datasets for HPO of real-world LLM systems, dubbed LLMSYS-HPOBench, covering data related to the inference objective values of hyperparameter configurations profiled from running the LLM systems. Currently, LLMSYS-HPOBench contains 364,450 hyperparameter configurations with a dimensionality of 12-23, 3-5 dimensions of fidelity factor leading to 932 settings, 3-9 inference objective metrics, and 2-10 cost metrics, together with generated logs from measuring the LLM systems. What we seek to advocate is not only a revalidation of the existing HPO algorithms over the frontier LLM systems, but also to provide an evolving platform for the AutoML community to explore new directions of research in this regard. The benchmark suite has been made available at: https://github.com/ideas-labo/llmsys-hpobench
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LLMSYS-HPOBench, presented as the first live benchmark suite and associated datasets for hyperparameter optimization (HPO) of real-world LLM systems. It profiles 364,450 hyperparameter configurations (dimensionality 12-23) across LLM systems, incorporating 3-5 fidelity factors (yielding 932 settings), 3-9 inference objective metrics, and 2-10 cost metrics, together with generated measurement logs. The work supplies the raw data via GitHub and advocates for revalidating existing HPO algorithms on these frontier systems while enabling new AutoML research directions on compound spaces, nonlinear fidelities, and diverse costs not captured in prior benchmarks.
Significance. If the profiled systems and measurements prove representative, the benchmark would fill a clear gap by supplying realistic, high-dimensional, multi-fidelity, multi-objective HPO instances with explicit costs for the AutoML community. The public release of raw datasets and logs is a concrete strength that supports reproducibility and secondary analyses, distinguishing this from purely synthetic or low-fidelity benchmarks.
major comments (2)
- [Abstract] Abstract and the benchmark description: the central claim that the suite captures 'the compound space of hyperparameter configuration from both the AI and non-AI components; rich and nonlinear implications from the fidelity factors; and diverse costs of measuring hyperparameter configurations' for real-world LLM systems rests on the unvalidated assumption that the specific profiled systems, hardware, and protocols generalize; no diversity analysis, cross-system comparison, coverage metrics, or sensitivity study is supplied to support extrapolation beyond the chosen instances.
- [Abstract] Data collection and validation section (inferred from the abstract's description of profiling): the manuscript provides no details on data collection methodology, measurement validation protocols, or noise handling, which directly affects the soundness of the 364,450 configurations and the 3-9 objectives as reliable ground truth for HPO algorithm testing.
minor comments (2)
- [Abstract] The abstract lists aggregate statistics (364,450 configurations, 12-23 dims, etc.) but does not state how many distinct LLM systems or hardware platforms were used; adding this count would help readers gauge coverage.
- [Abstract] The GitHub link is given but the manuscript does not describe the exact file formats, schema, or example usage scripts for the released logs and datasets, which would improve immediate usability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of generalizability and methodological transparency that we will address in the revision to strengthen the presentation of LLMSYS-HPOBench as a practical benchmark for the AutoML community.
read point-by-point responses
-
Referee: [Abstract] Abstract and the benchmark description: the central claim that the suite captures 'the compound space of hyperparameter configuration from both the AI and non-AI components; rich and nonlinear implications from the fidelity factors; and diverse costs of measuring hyperparameter configurations' for real-world LLM systems rests on the unvalidated assumption that the specific profiled systems, hardware, and protocols generalize; no diversity analysis, cross-system comparison, coverage metrics, or sensitivity study is supplied to support extrapolation beyond the chosen instances.
Authors: We agree that the manuscript would benefit from greater clarity on the scope and representativeness of the profiled systems. LLMSYS-HPOBench is explicitly positioned as a collection of real-world instances drawn from prevalent open-source LLM inference setups (e.g., Llama and Mistral variants on standard GPU hardware), rather than a universal claim about all possible LLM deployments. In the revised version we will add a dedicated subsection that (i) states the selection criteria for the systems and hardware, (ii) discusses limitations on generalization, and (iii) explains why these concrete, high-dimensional, multi-fidelity instances still fill a documented gap in existing HPO benchmarks. We will not add new empirical diversity or sensitivity analyses, as the core contribution is the release of the raw profiling data and logs themselves; however, the added discussion will make the extrapolation assumptions explicit and invite community extensions. revision: partial
-
Referee: [Abstract] Data collection and validation section (inferred from the abstract's description of profiling): the manuscript provides no details on data collection methodology, measurement validation protocols, or noise handling, which directly affects the soundness of the 364,450 configurations and the 3-9 objectives as reliable ground truth for HPO algorithm testing.
Authors: We acknowledge that the current manuscript does not devote sufficient space to these procedural details. Although the GitHub repository contains the raw measurement logs, the paper text itself should make the collection process transparent. In the revision we will expand (or add, if the existing section is too brief) a 'Data Collection and Validation' subsection that describes: the inference frameworks and hardware used, the exact protocol for recording each objective and cost metric, the number of repeated runs per configuration, the averaging procedure employed to reduce measurement noise, and any outlier filtering steps. This addition will directly support the claim that the released data constitute reliable ground truth for HPO algorithm evaluation. revision: yes
Circularity Check
No circularity: empirical benchmark release with no derivations or self-referential claims
full rationale
The manuscript presents LLMSYS-HPOBench as a new collection of 364450 profiled configurations and logs from specific LLM systems. No equations, predictions, fitted parameters, or first-principles derivations appear in the provided text. The central claim is simply the existence and release of the dataset itself; this is self-contained empirical material and does not reduce to any input by construction, self-citation, or renaming. Representativeness concerns are validity issues, not circularity.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LLMSYS-HPOBench contains 364,450 hyperparameter configurations with a dimensionality of 12-23, 3-5 dimensions of fidelity factor leading to 932 settings, 3-9 inference objective metrics, and 2-10 cost metrics
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The benchmark suite has been made available at: https://github.com/ideas-labo/llmsys-hpobench
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
https://huggingface.co/datasets/anon8231489123/ ShareGPT_Vicuna_unfiltered, 2025
Sharegpt conversation dataset. https://huggingface.co/datasets/anon8231489123/ ShareGPT_Vicuna_unfiltered, 2025. Accessed: 2026-05-05
work page 2025
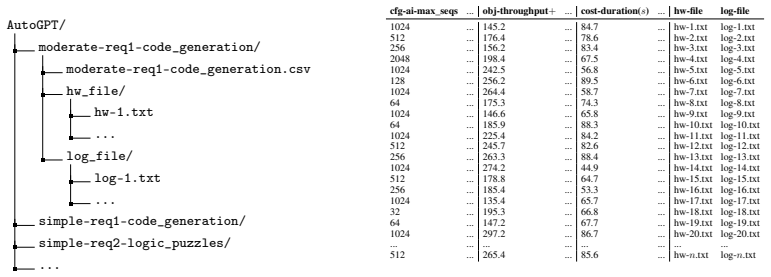
-
[2]
Gulavani, Ramachandran Ramjee, and Alexey Tumanov
Amey Agrawal, Nitin Kedia, Jayashree Mohan, Ashish Panwar, Nipun Kwatra, Bhargav S. Gulavani, Ramachandran Ramjee, and Alexey Tumanov. VIDUR: A large-scale simulation framework for LLM inference. In Phillip B. Gibbons, Gennady Pekhimenko, and Christopher De Sa, editors,Proceedings of the Seventh Annual Conference on Machine Learning and Systems, MLSys 202...
work page 2024
-
[3]
AutoGPT Contributors. AutoGPT. https://github.com/Significant-Gravitas/ AutoGPT, 2023. GitHub repository. Accessed: 2024
work page 2023
-
[4]
Awad, Neeratyoy Mallik, and Frank Hutter
Noor H. Awad, Neeratyoy Mallik, and Frank Hutter. DEHB: evolutionary hyberband for scalable, robust and efficient hyperparameter optimization. In Zhi-Hua Zhou, editor,Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI 2021, Virtual Event / Montreal, Canada, 19-27 August 2021, pages 2147–2153. ijcai.org, 2021
work page 2021
-
[5]
Mist: A co-design framework for heterogeneous, multi-stage llm inference, 2026
Abhimanyu Rajeshkumar Bambhaniya, Hanjiang Wu, Suvinay Subramanian, Sudarshan Srini- vasan, Souvik Kundu, Amir Yazdanbakhsh, Midhilesh Elavazhagan, Madhu Kumar, Minlan Yu, Arijit Raychowdhury, and Tushar Krishna. Mist: A co-design framework for heterogeneous, multi-stage llm inference, 2026
work page 2026
-
[6]
Jahs-bench-201: A foundation for research on joint architecture and hyperparameter search
Archit Bansal, Danny Stoll, Maciej Janowski, Arber Zela, and Frank Hutter. Jahs-bench-201: A foundation for research on joint architecture and hyperparameter search. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing...
work page 2022
-
[7]
Faster, cheaper, better: Multi-objective hyperparameter optimization for LLM and RAG systems
Matthew Barker, Andrew Bell, Evan Thomas, James Carr, Thomas Andrews, and Umang Bhatt. Faster, cheaper, better: Multi-objective hyperparameter optimization for LLM and RAG systems. CoRR, abs/2502.18635, 2025
-
[8]
Paul Brookes, Vardan K. V oskanyan, Rafail Giavrimis, Matthew Truscott, Mina Ilieva, Chrys- talla Pavlou, Andrei Staicu, Manal T. Adham, Will Evers-Hood, Jingzhi Gong, Kejia Zhang, Matvey Fedoseev, Vishal Sharma, Roman Bauer, Zheng Wang, Hema Nair, Wei Jie, Tianhua Xu, Aurora Constantin, Leslie Kanthan, and Michail Basios. Evolving excellence: Automated o...
-
[9]
Wu, Panpan Zhangsun, Yufei Li, and Zhe Zhang
Rong Cao, Liang Bao, Chase Q. Wu, Panpan Zhangsun, Yufei Li, and Zhe Zhang. CM-CASL: comparison-based performance modeling of software systems via collaborative active and semisupervised learning.J. Syst. Softw., 201:111686, 2023
work page 2023
-
[10]
Cds4rag: Cyclic dual-sequential hyperparameter optimization for rag
Pengzhou Chen and Tao Chen. Cds4rag: Cyclic dual-sequential hyperparameter optimization for rag. InProceedings of the 35th International Joint Conference on Artificial Intelligence, IJCAI 2026, Bremen, Germany, 15-21 August 2026. ijcai.org, 2026
work page 2026
-
[11]
Promisetune: Unveiling causally promising and explainable configuration tuning
Pengzhou Chen and Tao Chen. Promisetune: Unveiling causally promising and explainable configuration tuning. In48th International Conference on Software Engineering. IEEE, 2026
work page 2026
-
[12]
MMO: meta multi-objectivization for software configuration tuning.IEEE Trans
Pengzhou Chen, Tao Chen, and Miqing Li. MMO: meta multi-objectivization for software configuration tuning.IEEE Trans. Software Eng., 50(6):1478–1504, 2024
work page 2024
-
[13]
Accuracy can lie: On the impact of surrogate model in configuration tuning.IEEE Trans
Pengzhou Chen, Jingzhi Gong, and Tao Chen. Accuracy can lie: On the impact of surrogate model in configuration tuning.IEEE Trans. Software Eng., 51(2):548–580, 2025
work page 2025
-
[14]
Tao Chen, Ke Li, Rami Bahsoon, and Xin Yao. FEMOSAA: feature-guided and knee-driven multi-objective optimization for self-adaptive software.ACM Trans. Softw. Eng. Methodol., 27(2):5:1–5:50, 2018
work page 2018
-
[15]
Multi-objectivizing software configuration tuning
Tao Chen and Miqing Li. Multi-objectivizing software configuration tuning. In Diomidis Spinellis, Georgios Gousios, Marsha Chechik, and Massimiliano Di Penta, editors,ESEC/FSE ’21: 29th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Athens, Greece, August 23-28, 2021, pages 453–465. ACM, 2021
work page 2021
-
[16]
Tao Chen and Miqing Li. Do performance aspirations matter for guiding software configuration tuning? an empirical investigation under dual performance objectives.ACM Trans. Softw. Eng. Methodol., 32(3):68:1–68:41, 2023
work page 2023
-
[17]
Adapting multi-objectivized software configuration tuning.Proc
Tao Chen and Miqing Li. Adapting multi-objectivized software configuration tuning.Proc. ACM Softw. Eng., 1(FSE):539–561, 2024
work page 2024
-
[18]
HtmlRAG Contributors. HtmlRAG. https://github.com/plageon/HtmlRAG, 2024. GitHub repository. Accessed: 2024
work page 2024
-
[19]
HEBO: Pushing the limits of sample-efficient hyperparameter optimisa- tion
Alexander Imani Cowen-Rivers, Wenlong Lyu, Rasul Tutunov, Zhi Wang, Antoine Gros- nit, Ryan-Rhys Griffiths, Alexandre Max Maraval, Jianye HAO, Jun Wang, Jan Peters, and Haitham Bou Ammar. HEBO: Pushing the limits of sample-efficient hyperparameter optimisa- tion. InFirst Conference on Automated Machine Learning (Journal Track), 2022
work page 2022
-
[20]
Kalyanmoy Deb and Himanshu Jain. An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part i: solving problems with box constraints.IEEE transactions on evolutionary computation, 18(4):577–601, 2013
work page 2013
-
[21]
Tobias Domhan, Jost Tobias Springenberg, and Frank Hutter. Speeding up automatic hyperpa- rameter optimization of deep neural networks by extrapolation of learning curves. In Qiang Yang and Michael J. Wooldridge, editors,Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, IJCAI 2015, Buenos Aires, Argentina, July 25...
work page 2015
-
[22]
Nas-bench-201: Extending the scope of reproducible neural architecture search
Xuanyi Dong and Yi Yang. Nas-bench-201: Extending the scope of reproducible neural architecture search. In8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020
work page 2020
-
[23]
Evaluating large language models in class-level code generation
Xueying Du, Mingwei Liu, Kaixin Wang, Hanlin Wang, Junwei Liu, Yixuan Chen, Jiayi Feng, Chaofeng Sha, Xin Peng, and Yiling Lou. Evaluating large language models in class-level code generation. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering, ICSE 2024, Lisbon, Portugal, April 14-20, 2024, pages 81:1–81:13. ACM, 2024. 11
work page 2024
-
[24]
Awad, Marius Lindauer, and Frank Hutter
Katharina Eggensperger, Philipp Müller, Neeratyoy Mallik, Matthias Feurer, René Sass, Aaron Klein, Noor H. Awad, Marius Lindauer, and Frank Hutter. Hpobench: A collection of repro- ducible multi-fidelity benchmark problems for HPO. In Joaquin Vanschoren and Sai-Kit Yeung, editors,Proceedings of the Neural Information Processing Systems Track on Datasets a...
work page 2021
-
[25]
BOHB: robust and efficient hyperparameter optimization at scale
Stefan Falkner, Aaron Klein, and Frank Hutter. BOHB: robust and efficient hyperparameter optimization at scale. In Jennifer G. Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, Proceedings of Machine Learning Research, pages 1436–1445. PMLR, 2018
work page 2018
-
[26]
Pieter Gijsbers, Marcos L. P. Bueno, Stefan Coors, Erin LeDell, Sébastien Poirier, Janek Thomas, Bernd Bischl, and Joaquin Vanschoren. AMLB: an automl benchmark.J. Mach. Learn. Res., 25:101:1–101:65, 2024
work page 2024
-
[27]
Predicting software performance with divide-and-learn
Jingzhi Gong and Tao Chen. Predicting software performance with divide-and-learn. In Satish Chandra, Kelly Blincoe, and Paolo Tonella, editors,Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2023, San Francisco, CA, USA, December 3-9, 2023, pages 858–870. ACM, 2023
work page 2023
-
[28]
Predicting configuration performance in multiple environments with sequential meta-learning.Proc
Jingzhi Gong and Tao Chen. Predicting configuration performance in multiple environments with sequential meta-learning.Proc. ACM Softw. Eng., 1(FSE):359–382, 2024
work page 2024
-
[29]
Dividable configuration performance learning
Jingzhi Gong, Tao Chen, and Rami Bahsoon. Dividable configuration performance learning. IEEE Trans. Software Eng., 51(1):106–134, 2025
work page 2025
-
[30]
LightRAG: Simple and fast retrieval-augmented generation
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. LightRAG: Simple and fast retrieval-augmented generation. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Lin- guistics: EMNLP 2025, pages 10746–10761, Suzhou, China, November 2025. Association for Computation...
work page 2025
-
[31]
Deepperf: performance prediction for configurable software with deep sparse neural network
Huong Ha and Hongyu Zhang. Deepperf: performance prediction for configurable software with deep sparse neural network. In Joanne M. Atlee, Tevfik Bultan, and Jon Whittle, edi- tors,Proceedings of the 41st International Conference on Software Engineering, ICSE 2019, Montreal, QC, Canada, May 25-31, 2019, pages 1095–1106. IEEE / ACM, 2019
work page 2019
- [32]
-
[33]
Multi-fidelity automatic hyper-parameter tuning via transfer series expansion
Yi-Qi Hu, Yang Yu, Wei-Wei Tu, Qiang Yang, Yuqiang Chen, and Wenyuan Dai. Multi-fidelity automatic hyper-parameter tuning via transfer series expansion. InThe Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational...
work page 2019
-
[34]
Frank Hutter, Holger H. Hoos, and Kevin Leyton-Brown. Sequential model-based optimization for general algorithm configuration. In Carlos A. Coello Coello, editor,Learning and Intelligent Optimization, pages 507–523, Berlin, Heidelberg, 2011. Springer Berlin Heidelberg
work page 2011
-
[35]
Evolutionary many-objective opti- mization: A short review
Hisao Ishibuchi, Noritaka Tsukamoto, and Yusuke Nojima. Evolutionary many-objective opti- mization: A short review. InProceedings of the IEEE Congress on Evolutionary Computation, CEC 2008, June 1-6, 2008, Hong Kong, China, pages 2419–2426. IEEE, 2008
work page 2008
-
[36]
Song Jin, Shuqi Li, Shukun Zhang, and Rui Yan. Finrpt: Dataset, evaluation system and llm-based multi-agent framework for equity research report generation. In Sven Koenig, Chad Jenkins, and Matthew E. Taylor, editors,Fortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative Applications of Artificial Intelligence, Sixtee...
work page 2026
-
[37]
Distance-based sampling of software configuration spaces
Christian Kaltenecker, Alexander Grebhahn, Norbert Siegmund, Jianmei Guo, and Sven Apel. Distance-based sampling of software configuration spaces. In2019 IEEE/ACM 41st Interna- tional Conference on Software Engineering (ICSE), pages 1084–1094. IEEE, 2019
work page 2019
-
[38]
Jiin Kim, Byeong-Gon Shin, Jin-Won Chung, and Minsoo Rhu. The cost of dynamic reasoning: Demystifying ai agents and test-time scaling from an ai infrastructure perspective.2026 IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 1–16, 2025
work page 2026
-
[39]
Llm-based skill diffusion for zero-shot policy adaptation
Woo Kyung Kim, Youngseok Lee, Jooyoung Kim, and Honguk Woo. Llm-based skill diffusion for zero-shot policy adaptation. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2...
work page 2024
-
[40]
Fast bayesian optimization of machine learning hyperparameters on large datasets
Aaron Klein, Stefan Falkner, Simon Bartels, Philipp Hennig, and Frank Hutter. Fast bayesian optimization of machine learning hyperparameters on large datasets. In Aarti Singh and Xiaojin (Jerry) Zhu, editors,Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, AISTATS 2017, 20-22 April 2017, Fort Lauderdale, FL, USA,...
work page 2017
-
[41]
Whence to learn? transferring knowledge in configurable systems using BEETLE.IEEE Trans
Rahul Krishna, Vivek Nair, Pooyan Jamshidi, and Tim Menzies. Whence to learn? transferring knowledge in configurable systems using BEETLE.IEEE Trans. Software Eng., 47(12):2956– 2972, 2021
work page 2021
-
[42]
Bioasq-qa: A manually curated corpus for biomedical question answering.Scientific Data, 10:170, 2023
Anastasia Krithara, Anastasios Nentidis, Konstantinos Bougiatiotis, and Georgios Paliouras. Bioasq-qa: A manually curated corpus for biomedical question answering.Scientific Data, 10:170, 2023
work page 2023
- [43]
-
[44]
Input sensitivity on the performance of configurable systems an empirical study.J
Luc Lesoil, Mathieu Acher, Arnaud Blouin, and Jean-Marc Jézéquel. Input sensitivity on the performance of configurable systems an empirical study.J. Syst. Softw., 201:111671, 2023
work page 2023
-
[45]
Ke Li, Zilin Xiang, Tao Chen, Shuo Wang, and Kay Chen Tan. Understanding the automated parameter optimization on transfer learning for cross-project defect prediction: an empirical study. In Gregg Rothermel and Doo-Hwan Bae, editors,ICSE ’20: 42nd International Confer- ence on Software Engineering, Seoul, South Korea, 27 June - 19 July, 2020, pages 566–57...
work page 2020
-
[46]
Hyper- band: A novel bandit-based approach to hyperparameter optimization.J
Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. Hyper- band: A novel bandit-based approach to hyperparameter optimization.J. Mach. Learn. Res., 18:185:1–185:52, 2017
work page 2017
-
[47]
Miqing Li, Tao Chen, and Xin Yao. How to evaluate solutions in pareto-based search-based software engineering: A critical review and methodological guidance.IEEE Trans. Software Eng., 48(5):1771–1799, 2022
work page 2022
-
[48]
Eoh-s: Evolution of heuristic set using llms for automated heuristic design
Fei Liu, Yilu Liu, Qingfu Zhang, Xialiang Tong, and Mingxuan Yuan. Eoh-s: Evolution of heuristic set using llms for automated heuristic design. In Sven Koenig, Chad Jenkins, and Matthew E. Taylor, editors,Fortieth AAAI Conference on Artificial Intelligence, Thirty- Eighth Conference on Innovative Applications of Artificial Intelligence, Sixteenth Symposiu...
work page 2026
-
[49]
Latin hypercube sampling as a tool in uncertainty analysis of computer models
Michael D McKay. Latin hypercube sampling as a tool in uncertainty analysis of computer models. InProceedings of the 24th conference on Winter simulation, pages 557–564, 1992
work page 1992
-
[50]
Nas-bench-suite: NAS evaluation is (now) surprisingly easy
Yash Mehta, Colin White, Arber Zela, Arjun Krishnakumar, Guri Zabergja, Shakiba Moradian, Mahmoud Safari, Kaicheng Yu, and Frank Hutter. Nas-bench-suite: NAS evaluation is (now) surprisingly easy. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. 13
work page 2022
-
[51]
MOOT: a repository of many multi-objective optimization tasks
Tim Menzies, Tao Chen, Yulong Ye, Kishan Kumar Ganguly, Amirali Rayegan, Srinath Srini- vasan, and Andre Lustosa. MOOT: a repository of many multi-objective optimization tasks. IEEE Mining Software Repositories (MSR) Conference, 2026
work page 2026
-
[52]
Analysing the impact of workloads on modeling the performance of configurable software systems
Stefan Mühlbauer, Florian Sattler, Christian Kaltenecker, Johannes Dorn, Sven Apel, and Norbert Siegmund. Analysing the impact of workloads on modeling the performance of configurable software systems. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 2085–2097. IEEE, 2023
work page 2085
-
[53]
Finding faster configura- tions using FLASH.IEEE Trans
Vivek Nair, Zhe Yu, Tim Menzies, Norbert Siegmund, and Sven Apel. Finding faster configura- tions using FLASH.IEEE Trans. Software Eng., 46(7):794–811, 2020
work page 2020
- [54]
- [55]
-
[56]
Y AHPO gym - an efficient multi-objective multi-fidelity benchmark for hyperparameter optimization
Florian Pfisterer, Lennart Schneider, Julia Moosbauer, Martin Binder, and Bernd Bischl. Y AHPO gym - an efficient multi-objective multi-fidelity benchmark for hyperparameter optimization. In Isabelle Guyon, Marius Lindauer, Mihaela van der Schaar, Frank Hutter, and Roman Garnett, editors,International Conference on Automated Machine Learning, AutoML 2022,...
work page 2022
-
[57]
Jomaa, Martin Wistuba, and Josif Grabocka
Sebastian Pineda-Arango, Hadi S. Jomaa, Martin Wistuba, and Josif Grabocka. HPO-B: A large- scale reproducible benchmark for black-box HPO based on openml. In Joaquin Vanschoren and Sai-Kit Yeung, editors,Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual, 2021
work page 2021
-
[58]
A comprehensive survey on fitness landscape analysis
Erik Pitzer and Michael Affenzeller. A comprehensive survey on fitness landscape analysis. Recent advances in intelligent engineering systems, pages 161–191, 2012
work page 2012
-
[59]
SGLang Contributors. SGLang. https://github.com/sgl-project/sglang, 2023. GitHub repository. Accessed: 2024
work page 2023
-
[60]
ProofWriter: Generating implications, proofs, and abductive statements over natural language
Oyvind Tafjord, Bhavana Dalvi, and Peter Clark. ProofWriter: Generating implications, proofs, and abductive statements over natural language. InFindings of the Association for Compu- tational Linguistics: ACL-IJCNLP 2021, pages 3621–3634. Association for Computational Linguistics, 2021
work page 2021
-
[61]
Htmlrag: HTML is better than plain text for modeling retrieved knowledge in RAG systems
Jiejun Tan, Zhicheng Dou, Wen Wang, Mang Wang, Weipeng Chen, and Ji-Rong Wen. Htmlrag: HTML is better than plain text for modeling retrieved knowledge in RAG systems. In Guodong Long, Michale Blumestein, Yi Chang, Liane Lewin-Eytan, Zi Helen Huang, and Elad Yom-Tov, editors,Proceedings of the ACM on Web Conference 2025, WWW 2025, Sydney, NSW, Australia, 2...
work page 2025
-
[62]
Catbench: A compiler autotuning benchmarking suite for black-box optimization
Jacob O Tørring, Carl Hvarfner, Luigi Nardi, and Magnus Själander. Catbench: A compiler autotuning benchmarking suite for black-box optimization. InInternational Conference on Automated Machine Learning, pages 24–1. PMLR, 2025
work page 2025
-
[63]
vLLM Contributors. vLLM. https://github.com/vllm-project/vllm, 2023. GitHub repository. Accessed: 2024
work page 2023
-
[64]
Large language models as urban residents: An LLM agent framework for personal mobility generation
Jiawei Wang, Renhe Jiang, Chuang Yang, Zengqing Wu, Makoto Onizuka, Ryosuke Shibasaki, Noboru Koshizuka, and Chuan Xiao. Large language models as urban residents: An LLM agent framework for personal mobility generation. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in N...
work page 2024
-
[65]
Shihai Wang and Tao Chen. Conjecture and inquiry: Quantifying software performance requirements via interactive retrieval-augmented preference elicitation. InFindings: Annual Meeting of the Association for Computational Linguistics (ACL). ACL, 2026. 14
work page 2026
-
[66]
Light over heavy: Automated performance requirements quantifi- cation with linguistic inducement
Shihai Wang and Tao Chen. Light over heavy: Automated performance requirements quantifi- cation with linguistic inducement. In48th IEEE/ACM International Conference on Software Engineering (ICSE). ACM, 2026
work page 2026
-
[67]
Twins or false friends? A study on energy consumption and performance of configurable software
Max Weber, Christian Kaltenecker, Florian Sattler, Sven Apel, and Norbert Siegmund. Twins or false friends? A study on energy consumption and performance of configurable software. In 45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, May 14-20, 2023, pages 2098–2110. IEEE, 2023
work page 2023
-
[68]
Dually hierarchical drift adaptation for online configuration performance learning
Zezhen Xiang, Jingzhi Gong, and Tao Chen. Dually hierarchical drift adaptation for online configuration performance learning. In48th IEEE/ACM International Conference on Software Engineering (ICSE). ACM, 2026
work page 2026
-
[69]
Cotune: Co-evolutionary configuration tuning
Gangda Xiong and Tao Chen. Cotune: Co-evolutionary configuration tuning. In40th IEEE/ACM International Conference on Automated Software Engineering, ASE 2025, Seoul, Korea, Repub- lic of, November 16-20, 2025, pages 1490–1502. IEEE, 2025
work page 2025
-
[70]
Cohen, Ruslan Salakhut- dinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhut- dinov, and Christopher D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors,Proceedings of the 2018 Conference on Empirical Methods in Natural Language Pro-...
work page 2018
-
[71]
Distilled lifelong self-adaptation for configurable systems
Yulong Ye, Tao Chen, and Miqing Li. Distilled lifelong self-adaptation for configurable systems. In47th IEEE/ACM International Conference on Software Engineering, ICSE 2025, Ottawa, ON, Canada, April 26 - May 6, 2025, pages 1333–1345. IEEE, 2025
work page 2025
-
[72]
Yulong Ye, Hongyuan Liang, Chao Jiang, Miqing Li, and Tao Chen. Revealing domain-spatiality patterns for configuration tuning: Domain knowledge meets fitness landscapes.ACM Trans. Softw. Eng. Methodol., March 2026. Just Accepted
work page 2026
-
[73]
Nas-bench-101: Towards reproducible neural architecture search
Chris Ying, Aaron Klein, Eric Christiansen, Esteban Real, Kevin Murphy, and Frank Hutter. Nas-bench-101: Towards reproducible neural architecture search. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, Proceedings of Machin...
work page 2019
-
[74]
Surrogate NAS benchmarks: Going beyond the limited search spaces of tabular NAS benchmarks
Arber Zela, Julien Niklas Siems, Lucas Zimmer, Jovita Lukasik, Margret Keuper, and Frank Hutter. Surrogate NAS benchmarks: Going beyond the limited search spaces of tabular NAS benchmarks. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022
work page 2022
-
[75]
On speeding up language model evaluation
Jin Zhou, Christian Belardi, Ruihan Wu, Travis Zhang, Carla Gomes, Wen Sun, and Kilian Weinberger. On speeding up language model evaluation. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Representations, volume 2025, pages 65092–65111, 2025
work page 2025
-
[76]
Bestconfig: tapping the performance potential of systems via automatic configuration tuning
Yuqing Zhu, Jianxun Liu, Mengying Guo, Yungang Bao, Wenlong Ma, Zhuoyue Liu, Kunpeng Song, and Yingchun Yang. Bestconfig: tapping the performance potential of systems via automatic configuration tuning. InProceedings of the 2017 Symposium on Cloud Computing, SoCC ’17, page 338–350, New York, NY , USA, 2017. Association for Computing Machinery. 15 A Limita...
work page 2017
-
[77]
Open a tracking issue.The contributor first describes the target LLM system, its family (RAG pipeline, inference engine, or agentic system), the intended contribution type (new sys- tem, new fidelity settings, or additional measurements), and the expected hardware/software requirements. 18
-
[78]
Create the system manual.Add a manual under the corresponding documentation directory, i.e., RAG/manuals/, Engine/manuals/, or Agent/manuals/. The manual should define the AI and non-AI hyperparameters, their types and value ranges, implementation references, default settings, and any deployment assumptions. 3.Implement the benchmark interface.Add scripts...
-
[79]
Specify fidelities and sampling policy.Document all fidelity dimensions, their allowed val- ues, the Cartesian product or sampling strategy, and their expected impact on cost/resources. If the full Cartesian product is too expensive, the contributor should justify the reduced sampling plan and include a small pre-experiment showing that the selected fidel...
-
[80]
Generate and organize measurements.Store raw outputs, processed .csv summaries, cost logs, error logs, hardware traces, and visualizations in the standardized data layout. Every measured configuration should have a stable identifier so that objectives, costs, hardware metrics, and execution logs can be joined unambiguously
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.