Recognition: no theorem link
Improved monocular depth prediction using distance transform over pre-semantic contours with self-supervised neural networks
Pith reviewed 2026-05-12 00:47 UTC · model grok-4.3
The pith
Distance transform over pre-semantic contours augments variance and improves self-supervised monocular depth estimation in low-texture areas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
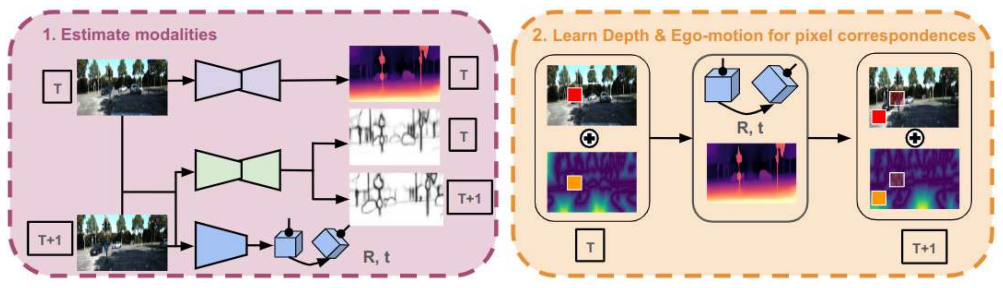
By jointly estimating pre-semantic contours, depth, and ego-motion, then feeding images whose variance has been augmented by the distance transform over those contours, the network obtains stronger training signals in low-texture regions. The distance transform is shown theoretically to be the optimal variance-augmenting operator in this setting. The resulting model surpasses competing self-supervised monocular depth estimation methods on KITTI, Cityscapes, Waymo, NYUv2, and ScanNet.
What carries the argument
The distance transform applied to jointly estimated pre-semantic contours, which produces new input images that increase local variance in uniform areas and thereby strengthen the photometric loss for depth and ego-motion learning.
If this is right
- Depth accuracy increases in low-texture regions on outdoor driving datasets such as KITTI, Cityscapes, and Waymo.
- The model reports lower error than other self-supervised monocular depth methods on standard benchmark metrics.
- Joint contour estimation supplies boundary cues that improve depth consistency without requiring separate semantic labels.
- Performance gains hold across both outdoor and indoor scenes on NYUv2 and ScanNet.
Where Pith is reading between the lines
- The same contour-plus-distance-transform idea could be tested in other self-supervised dense-prediction tasks such as optical flow or surface-normal estimation where textureless regions also cause ambiguity.
- Pre-semantic contours might serve as a lightweight substitute for full semantic segmentation when the goal is only to inject structural information into depth training.
- Evaluating the method on sequences that contain motion blur or strong illumination changes would show whether the learned contours remain stable enough to keep the variance augmentation beneficial.
Load-bearing premise
Pre-semantic contours can be estimated jointly with enough accuracy to supply reliable variance augmentation in low-texture regions without introducing new artifacts or boundary errors.
What would settle it
An ablation that removes the distance transform or replaces it with a different edge-based augmentation, then measures whether depth error increases specifically inside low-texture patches on held-out test sequences from KITTI or NYUv2.
Figures


read the original abstract
Monocular depth estimation (MDE) with self-supervised training approaches struggles in low-texture areas, where photometric losses may lead to ambiguous depth predictions. To address this, we propose a novel technique that enhances spatial information by applying a distance transform over pre-semantic contours, augmenting discriminative power in low texture regions. Our approach jointly estimates pre-semantic contours, depth and ego-motion. The pre-semantic contours are leveraged to produce new input images, with variance augmented by the distance transform in uniform areas. This approach results in more effective loss functions, enhancing the training process for depth and ego-motion. We demonstrate theoretically that the distance transform is the optimal variance-augmenting technique in this context. Through extensive experiments on KITTI, Cityscapes, Waymo, NYUv2 and ScanNet our model demonstrates robust performance, surpassing competing self-supervised methods in MDE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a self-supervised monocular depth estimation framework that jointly predicts pre-semantic contours, depth, and ego-motion. Pre-semantic contours are used to generate variance-augmented input images via the distance transform, with the goal of improving photometric loss effectiveness in low-texture regions. The authors claim a theoretical proof that the distance transform is the optimal variance-augmenting operator in this setting and report superior performance over competing self-supervised methods on KITTI, Cityscapes, Waymo, NYUv2, and ScanNet.
Significance. If the theoretical optimality holds and the joint contour estimation remains accurate enough in low-texture zones to avoid artifacts, the method could meaningfully advance self-supervised MDE by providing a principled way to strengthen supervision where photometric cues are weak. The multi-dataset evaluation and joint estimation of contours with depth/ego-motion are positive aspects that would strengthen the contribution if the core mechanism is validated.
major comments (3)
- [Theoretical analysis] Theoretical analysis (abstract and theory section): The asserted optimality of the distance transform as a variance-augmenting technique is load-bearing for the central claim, yet the provided description does not include the full derivation or explicit assumptions about contour reliability; without these, it is impossible to confirm whether the proof avoids circularity with respect to the joint self-supervised objective or presupposes perfect boundary detection in low-texture areas.
- [Method] Method and loss formulation: The joint estimation of pre-semantic contours is presented as enabling reliable distance-transform augmentation, but no explicit regularization term or auxiliary loss is described that would guarantee contour accuracy in the low-texture regions explicitly targeted by the approach; misalignment here would directly undermine the claimed improvement in discriminative power.
- [Experiments] Experiments section: Performance gains are reported across five datasets, but the manuscript lacks ablations or quantitative metrics (e.g., contour precision/recall in low-texture patches) that isolate the contribution of the distance-transform step from other architectural choices, making it difficult to attribute improvements to the proposed mechanism rather than general capacity increases.
minor comments (2)
- [Method] Notation for the distance transform and pre-semantic contour maps should be introduced with explicit definitions and symbols in the method section to improve readability.
- [Experiments] Figure captions for qualitative results should indicate which regions correspond to low-texture areas to allow direct visual assessment of the claimed benefit.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the presentation of our contributions. We address each major point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical analysis (abstract and theory section): The asserted optimality of the distance transform as a variance-augmenting technique is load-bearing for the central claim, yet the provided description does not include the full derivation or explicit assumptions about contour reliability; without these, it is impossible to confirm whether the proof avoids circularity with respect to the joint self-supervised objective or presupposes perfect boundary detection in low-texture areas.
Authors: We appreciate this observation. The theory section provides a sketch showing that, under the assumption of reliable pre-semantic contours, the distance transform is the operator that maximizes variance augmentation for the photometric loss in uniform regions. To fully address concerns about circularity and assumptions, we will expand the supplementary material with the complete derivation, explicitly listing assumptions (including that optimality is conditional on contour estimates rather than presupposing perfection) and discussing how the joint self-supervised objective (photometric consistency across frames) provides the necessary grounding without circularity. This revision will allow independent verification of the proof. revision: yes
-
Referee: [Method] Method and loss formulation: The joint estimation of pre-semantic contours is presented as enabling reliable distance-transform augmentation, but no explicit regularization term or auxiliary loss is described that would guarantee contour accuracy in the low-texture regions explicitly targeted by the approach; misalignment here would directly undermine the claimed improvement in discriminative power.
Authors: The contours are estimated jointly via a shared backbone and are supervised indirectly through the end-to-end photometric loss on the augmented images. While this coupling provides some implicit regularization, we agree that an explicit term would better guarantee accuracy in low-texture zones. In the revised manuscript we will introduce an auxiliary edge-consistency loss (enforcing temporal coherence of contours across adjacent frames) and an edge-aware smoothness regularizer on the contour predictions, with corresponding ablation results. revision: yes
-
Referee: [Experiments] Experiments section: Performance gains are reported across five datasets, but the manuscript lacks ablations or quantitative metrics (e.g., contour precision/recall in low-texture patches) that isolate the contribution of the distance-transform step from other architectural choices, making it difficult to attribute improvements to the proposed mechanism rather than general capacity increases.
Authors: We acknowledge the need for stronger isolation of the distance-transform contribution. The current experiments include overall comparisons and some architectural variants, but lack the requested targeted ablations. We will add: (i) an ablation replacing the distance transform with alternative variance-augmentation operators (e.g., Gaussian blur, random noise), (ii) quantitative contour precision/recall and F1 scores evaluated specifically on low-texture patches (identified via gradient magnitude thresholds) on KITTI, and (iii) a controlled experiment measuring depth error reduction attributable to the augmentation step alone. These will be included in the revised experiments section and supplementary material. revision: yes
Circularity Check
No significant circularity; theoretical optimality claim is independent of fitted inputs
full rationale
The paper's derivation applies the standard distance transform operation to jointly estimated pre-semantic contours as a variance-augmentation step within a self-supervised photometric loss. The abstract states a theoretical demonstration that this transform is optimal for the stated purpose, but provides no equations reducing that optimality to quantities defined by the model's own parameters or outputs. No self-citation load-bearing uniqueness theorems, ansatz smuggling, or renaming of known results are visible in the given text. The joint estimation of contours, depth, and ego-motion is presented as an architectural choice whose value is assessed via external benchmarks on KITTI, Cityscapes, Waymo, NYUv2, and ScanNet rather than by construction. The central improvement therefore does not collapse to a tautology or fitted-input prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Photometric consistency and rigid-scene assumptions hold sufficiently for training depth and ego-motion from image sequences
Reference graph
Works this paper leans on
-
[1]
Ali Akbari, Muhammad Awais, Manijeh Bashar, and Josef Kittler. How does loss function affect generalization per- formance of deep learning? application to human age esti- mation. InInternational Conference on Machine Learning, pages 141–151. PMLR, 2021. 4
work page 2021
-
[2]
Bi3d: Stereo depth estimation via binary classifications
Abhishek Badki, Alejandro Troccoli, Kihwan Kim, Jan Kautz, Pradeep Sen, and Orazio Gallo. Bi3d: Stereo depth estimation via binary classifications. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1600–1608, 2020. 1
work page 2020
-
[3]
Jiawang Bian, Zhichao Li, Naiyan Wang, Huangying Zhan, Chunhua Shen, Ming-Ming Cheng, and Ian Reid. Unsuper- vised scale-consistent depth and ego-motion learning from monocular video.Advances in neural information process- ing systems, 32, 2019. 6
work page 2019
-
[4]
Vincent Casser, Soeren Pirk, Reza Mahjourian, and Anelia Angelova. Depth prediction without the sensors: Leveraging structure for unsupervised learning from monocular videos. InProceedings of the AAAI conference on artificial intelli- gence, pages 8001–8008, 2019. 2, 7, 3, 4
work page 2019
-
[5]
Unsupervised monocular depth and ego-motion learning with structure and semantics
Vincent Casser, Soeren Pirk, Reza Mahjourian, and Anelia Angelova. Unsupervised monocular depth and ego-motion learning with structure and semantics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 0–0, 2019. 6
work page 2019
-
[6]
Improving monocu- lar depth estimation by leveraging structural awareness and complementary datasets
Tian Chen, Shijie An, Yuan Zhang, Chongyang Ma, Huayan Wang, Xiaoyan Guo, and Wen Zheng. Improving monocu- lar depth estimation by leveraging structural awareness and complementary datasets. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16, pages 90–108. Springer,
work page 2020
-
[7]
Yuhua Chen, Cordelia Schmid, and Cristian Sminchis- escu. Self-supervised learning with geometric constraints in monocular video: Connecting flow, depth, and camera. In Proceedings of the IEEE/CVF international conference on computer vision, pages 7063–7072, 2019. 1, 2, 7, 5
work page 2019
-
[8]
Estimating depth from rgb and sparse sensing
Zhao Chen, Vijay Badrinarayanan, Gilad Drozdov, and An- drew Rabinovich. Estimating depth from rgb and sparse sensing. InProceedings of the European Conference on Computer Vision (ECCV), pages 167–182, 2018. 3
work page 2018
-
[9]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016. 2, 6
work page 2016
-
[10]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017. 2, 6
work page 2017
-
[11]
Learning to predict crisp boundaries
Ruoxi Deng, Chunhua Shen, Shengjun Liu, Huibing Wang, and Xinru Liu. Learning to predict crisp boundaries. In Proceedings of the European conference on computer vision (ECCV), pages 562–578, 2018. 2
work page 2018
-
[12]
Tom van Dijk and Guido de Croon. How do neural networks see depth in single images? InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2183– 2191, 2019. 1
work page 2019
-
[13]
David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep net- work.Advances in neural information processing systems, 27, 2014. 1, 6
work page 2014
-
[14]
F El Jamiy and R Marsh. Survey on depth perception in head mounted displays: distance estimation in virtual reality, augmented reality, and mixed reality. iet image processing 13 (5), 707–712 (2019), 2018. 1
work page 2019
-
[15]
Lightweight monocular depth estimation model by joint end-to-end filter pruning
Sara Elkerdawy, Hong Zhang, and Nilanjan Ray. Lightweight monocular depth estimation model by joint end-to-end filter pruning. In2019 IEEE International Conference on Image Processing (ICIP), pages 4290–4294. IEEE, 2019. 1
work page 2019
-
[16]
Deeper into self-supervised monocular indoor depth estimation
Chao Fan, Zhenyu Yin, Yue Li, and Feiqing Zhang. Deeper into self-supervised monocular indoor depth estimation. arXiv preprint arXiv:2312.01283, 2023. 6, 7
-
[17]
Flownet: Learn- ing optical flow with convolutional networks.arXiv preprint arXiv:1504.06852, 2015
Philipp Fischer, Alexey Dosovitskiy, Eddy Ilg, Philip H¨ausser, Caner Hazırbas ¸, Vladimir Golkov, Patrick Van der Smagt, Daniel Cremers, and Thomas Brox. Flownet: Learn- ing optical flow with convolutional networks.arXiv preprint arXiv:1504.06852, 2015. 5
-
[18]
Deep ordinal regression net- work for monocular depth estimation
Huan Fu, Mingming Gong, Chaohui Wang, Kayhan Bat- manghelich, and Dacheng Tao. Deep ordinal regression net- work for monocular depth estimation. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 2002–2011, 2018. 1
work page 2002
-
[19]
Unsupervised cnn for single view depth estimation: Geom- etry to the rescue
Ravi Garg, Vijay Kumar Bg, Gustavo Carneiro, and Ian Reid. Unsupervised cnn for single view depth estimation: Geom- etry to the rescue. InComputer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, Octo- ber 11-14, 2016, Proceedings, Part VIII 14, pages 740–756. Springer, 2016. 1
work page 2016
-
[20]
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The Inter- national Journal of Robotics Research, 32(11):1231–1237,
-
[21]
Unsupervised monocular depth estimation with left- right consistency
Cl ´ement Godard, Oisin Mac Aodha, and Gabriel J Bros- tow. Unsupervised monocular depth estimation with left- right consistency. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 270–279,
-
[22]
Digging into self-supervised monocular depth estimation
Cl ´ement Godard, Oisin Mac Aodha, Michael Firman, and Gabriel J Brostow. Digging into self-supervised monocular depth estimation. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 3828–3838,
-
[23]
Depth from videos in the wild: Unsupervised monocular depth learning from unknown cameras
Ariel Gordon, Hanhan Li, Rico Jonschkowski, and Anelia Angelova. Depth from videos in the wild: Unsupervised monocular depth learning from unknown cameras. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 8977–8986, 2019. 1, 2
work page 2019
-
[24]
Vitor Guizilini, Rui Hou, Jie Li, Rares Ambrus, and Adrien Gaidon. Semantically-guided representation learn- ing for self-supervised monocular depth.arXiv preprint arXiv:2002.12319, 2020. 2, 7
-
[25]
High-quality depth from uncalibrated small motion clip
Hyowon Ha, Sunghoon Im, Jaesik Park, Hae-Gon Jeon, and In So Kweon. High-quality depth from uncalibrated small motion clip. InProceedings of the IEEE conference on computer vision and pattern Recognition, pages 5413–5421,
-
[26]
David Hafner, Oliver Demetz, and Joachim Weickert. Why is the census transform good for robust optic flow computa- tion? InScale Space and Variational Methods in Computer Vision: 4th International Conference, SSVM 2013, Schloss Seggau, Leibnitz, Austria, June 2-6, 2013. Proceedings 4, pages 210–221. Springer, 2013. 3
work page 2013
-
[27]
Train faster, generalize better: Stability of stochastic gradient descent
Moritz Hardt, Ben Recht, and Yoram Singer. Train faster, generalize better: Stability of stochastic gradient descent. In International conference on machine learning, pages 1225–
-
[28]
Marwane Hariat, Antoine Manzanera, and David Filliat. Re- balancing gradient to improve self-supervised co-training of depth, odometry and optical flow predictions. InProceed- ings of the IEEE/CVF winter conference on applications of computer vision, pages 1267–1276, 2023. 2, 6, 7, 8, 4, 5
work page 2023
-
[29]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 6
work page 2016
-
[30]
Ra-depth: Resolution adaptive self-supervised monocular depth estimation
Mu He, Le Hui, Yikai Bian, Jian Ren, Jin Xie, and Jian Yang. Ra-depth: Resolution adaptive self-supervised monocular depth estimation. InEuropean Conference on Computer Vi- sion, pages 565–581. Springer, 2022. 7
work page 2022
-
[31]
Improved edge awareness in discontinuity preserving smoothing.arXiv preprint arXiv:1103.5808, 2011
Stuart B Heinrich and Wesley E Snyder. Improved edge awareness in discontinuity preserving smoothing.arXiv preprint arXiv:1103.5808, 2011. 3
-
[32]
Visualiza- tion of convolutional neural networks for monocular depth estimation
Junjie Hu, Yan Zhang, and Takayuki Okatani. Visualiza- tion of convolutional neural networks for monocular depth estimation. InProceedings of the IEEE/CVF international conference on computer vision, pages 3869–3878, 2019. 1
work page 2019
-
[33]
Flownet 2.0: Evolu- tion of optical flow estimation with deep networks
Eddy Ilg, Nikolaus Mayer, Tonmoy Saikia, Margret Keuper, Alexey Dosovitskiy, and Thomas Brox. Flownet 2.0: Evolu- tion of optical flow estimation with deep networks. InPro- ceedings of the IEEE conference on computer vision and pat- tern recognition, pages 2462–2470, 2017. 5
work page 2017
-
[34]
Spatial transformer networks.Advances in neural informa- tion processing systems, 28, 2015
Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spatial transformer networks.Advances in neural informa- tion processing systems, 28, 2015. 2
work page 2015
-
[35]
Linearized multi-sampling for dif- ferentiable image transformation
Wei Jiang, Weiwei Sun, Andrea Tagliasacchi, Eduard Trulls, and Kwang Moo Yi. Linearized multi-sampling for dif- ferentiable image transformation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2988–2997, 2019. 2
work page 2019
-
[36]
A recipe for global con- vergence guarantee in deep neural networks
Kenji Kawaguchi and Qingyun Sun. A recipe for global con- vergence guarantee in deep neural networks. InProceed- ings of the AAAI conference on artificial intelligence, pages 8074–8082, 2021. 4
work page 2021
-
[37]
Re- visiting self-supervised monocular depth estimation
Ue-Hwan Kim, Gyeong-Min Lee, and Jong-Hwan Kim. Re- visiting self-supervised monocular depth estimation. InIn- ternational Conference on Robot Intelligence Technology and Applications, pages 336–350. Springer, 2021. 2
work page 2021
-
[38]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980, 2014. 6
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[39]
Comoda: Continuous monocular depth adaptation using past experiences
Yevhen Kuznietsov, Marc Proesmans, and Luc Van Gool. Comoda: Continuous monocular depth adaptation using past experiences. InProceedings of the IEEE/CVF Winter Con- ference on Applications of Computer Vision, pages 2907– 2917, 2021. 2
work page 2021
-
[40]
Learning residual flow as dynamic motion from stereo videos
Seokju Lee, Sunghoon Im, Stephen Lin, and In So Kweon. Learning residual flow as dynamic motion from stereo videos. In2019 IEEE/RSJ International Conference on Intel- ligent Robots and Systems (IROS), pages 1180–1186. IEEE,
-
[41]
Unsupervised monocular depth learning in dynamic scenes
Hanhan Li, Ariel Gordon, Hang Zhao, Vincent Casser, and Anelia Angelova. Unsupervised monocular depth learning in dynamic scenes. InConference on Robot Learning, pages 1908–1917. PMLR, 2021. 2, 6, 7
work page 1908
-
[42]
Rtm3d: Real-time monocular 3d detection from object key- points for autonomous driving
Peixuan Li, Huaici Zhao, Pengfei Liu, and Feidao Cao. Rtm3d: Real-time monocular 3d detection from object key- points for autonomous driving. InEuropean Conference on Computer Vision, pages 644–660. Springer, 2020. 1
work page 2020
-
[43]
Pengzhi Li, Yikang Ding, Haohan Wang, Chengshuai Tang, and Zhiheng Li. The devil is in the edges: Monocular depth estimation with edge-aware consistency fusion.arXiv preprint arXiv:2404.00373, 2024. 2
-
[44]
Runze Li, Pan Ji, Yi Xu, and Bir Bhanu. Monoindoor++: Towards better practice of self-supervised monocular depth estimation for indoor environments.IEEE Transactions on Circuits and Systems for Video Technology, 33(2):830–846,
-
[45]
Rui Li, Danna Xue, Shaolin Su, Xiantuo He, Qing Mao, Yu Zhu, Jinqiu Sun, and Yanning Zhang. Learning depth via leveraging semantics: Self-supervised monocular depth es- timation with both implicit and explicit semantic guidance. Pattern Recognition, 137:109297, 2023. 2, 3
work page 2023
-
[46]
Unsupervised learning of edges
Yin Li, Manohar Paluri, James M Rehg, and Piotr Doll ´ar. Unsupervised learning of edges. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 1619–1627, 2016. 3
work page 2016
-
[47]
Un- supervised learning of scene flow estimation fusing with lo- cal rigidity
Liang Liu, Guangyao Zhai, Wenlong Ye, and Yong Liu. Un- supervised learning of scene flow estimation fusing with lo- cal rigidity. InIJCAI, pages 876–882, 2019. 2
work page 2019
-
[48]
Hengjie Lu, Shugong Xu, and Shan Cao. Sgtbn: generat- ing dense depth maps from single-line lidar.IEEE Sensors Journal, 21(17):19091–19100, 2021. 1
work page 2021
-
[49]
Hr-depth: High resolution self-supervised monocular depth estimation
Xiaoyang Lyu, Liang Liu, Mengmeng Wang, Xin Kong, Lina Liu, Yong Liu, Xinxin Chen, and Yi Yuan. Hr-depth: High resolution self-supervised monocular depth estimation. InProceedings of the AAAI conference on artificial intelli- gence, pages 2294–2301, 2021. 7
work page 2021
-
[50]
Unflow: Un- supervised learning of optical flow with a bidirectional cen- sus loss
Simon Meister, Junhwa Hur, and Stefan Roth. Unflow: Un- supervised learning of optical flow with a bidirectional cen- sus loss. InProceedings of the AAAI conference on artificial intelligence, 2018. 3
work page 2018
-
[51]
Raul Mur-Artal, Jose Maria Martinez Montiel, and Juan D Tardos. Orb-slam: a versatile and accurate monocular slam system.IEEE transactions on robotics, 31(5):1147–1163,
-
[52]
Oskar Natan and Jun Miura. End-to-end autonomous driving with semantic depth cloud mapping and multi-agent.IEEE Transactions on Intelligent Vehicles, 8(1):557–571, 2022. 1
work page 2022
-
[53]
A simple proof of the rademacher theorem
Ale ˇs Nekvinda and Lud ˇek Zaj´ıˇcek. A simple proof of the rademacher theorem. ˇCasopis pro pˇestov´an´ı matematiky, 113 (4):337–341, 1988. 3
work page 1988
-
[54]
C Wayne Niblack, Phillip B Gibbons, and David W Capson. Generating skeletons and centerlines from the distance trans- form.CVGIP: Graphical Models and image processing, 54 (5):420–437, 1992. 2
work page 1992
-
[55]
Understanding ssim.arXiv preprint arXiv:2006.13846, 2020
Jim Nilsson and Tomas Akenine-M ¨oller. Understanding ssim.arXiv preprint arXiv:2006.13846, 2020. 1
-
[56]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Daniel Otero, Davide La Torre, O Michailovich, and Ed- ward R Vrscay. Optimization of structural similarity in math- ematical imaging.Optimization and Engineering, 22:2367– 2401, 2021. 4
work page 2021
-
[58]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An im- perative style, high-performance deep learning library.Ad- vances in neural information processing systems, 32, 2019. 6
work page 2019
-
[59]
Sharpnet: Fast and accurate recovery of occluding contours in monocular depth estimation
Michael Ramamonjisoa and Vincent Lepetit. Sharpnet: Fast and accurate recovery of occluding contours in monocular depth estimation. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision Workshops, pages 0–0, 2019. 2
work page 2019
-
[60]
Anurag Ranjan, Varun Jampani, Lukas Balles, Kihwan Kim, Deqing Sun, Jonas Wulff, and Michael J Black. Competitive collaboration: Joint unsupervised learning of depth, camera motion, optical flow and motion segmentation. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12240–12249, 2019. 2
work page 2019
-
[61]
Alex Rasla and Michael Beyeler. The relative importance of depth cues and semantic edges for indoor mobility using simulated prosthetic vision in immersive virtual reality. In Proceedings of the 28th ACM Symposium on Virtual Reality Software and Technology, pages 1–11, 2022. 1
work page 2022
-
[62]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InMedical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, pages 234–241. Springer, 2015. 6, 3
work page 2015
-
[63]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115:211–252, 2015. 6
work page 2015
-
[64]
Boosting monocular depth with panoptic segmentation maps
Faraz Saeedan and Stefan Roth. Boosting monocular depth with panoptic segmentation maps. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3853–3862, 2021. 2
work page 2021
-
[65]
Jrmot: A real-time 3d multi-object tracker and a new large-scale dataset
Abhijeet Shenoi, Mihir Patel, JunYoung Gwak, Patrick Goebel, Amir Sadeghian, Hamid Rezatofighi, Roberto Martin-Martin, and Silvio Savarese. Jrmot: A real-time 3d multi-object tracker and a new large-scale dataset. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10335–10342. IEEE, 2020. 1
work page 2020
-
[66]
Feature-metric loss for self-supervised learning of depth and egomotion
Chang Shu, Kun Yu, Zhixiang Duan, and Kuiyuan Yang. Feature-metric loss for self-supervised learning of depth and egomotion. InEuropean Conference on Computer Vision, pages 572–588. Springer, 2020. 3, 7, 8
work page 2020
-
[67]
Indoor segmentation and support inference from rgbd images
Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from rgbd images. InComputer Vision–ECCV 2012: 12th Eu- ropean Conference on Computer Vision, Florence, Italy, Oc- tober 7-13, 2012, Proceedings, Part V 12, pages 746–760. Springer, 2012. 2, 6
work page 2012
-
[68]
The distance transform and its computation
Tilo Strutz. The distance transform and its computation. arXiv preprint arXiv:2106.03503, 2021. 2
-
[69]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020. 2, 6
work page 2020
-
[70]
Zachary Teed and Jia Deng. Deepv2d: Video to depth with differentiable structure from motion.arXiv preprint arXiv:1812.04605, 2018. 1
-
[71]
Attention is all you need.Advances in Neural Information Processing Systems, 2017
A Vaswani. Attention is all you need.Advances in Neural Information Processing Systems, 2017. 3
work page 2017
-
[72]
MOTS: Multi-object tracking and seg- mentation
Paul V oigtlaender, Michael Krause, Aljo ˘sa O ˘sep, Jonathon Luiten, Berin Balachandar Gnana Sekar, Andreas Geiger, and Bastian Leibe. MOTS: Multi-object tracking and seg- mentation. InCVPR, 2019. 8, 6, 7, 11
work page 2019
-
[73]
Learning depth from monocular videos using direct methods
Chaoyang Wang, Jos ´e Miguel Buenaposada, Rui Zhu, and Simon Lucey. Learning depth from monocular videos using direct methods. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2022–2030,
work page 2022
-
[74]
Peng Wang, Xiaohui Shen, Bryan Russell, Scott Cohen, Brian Price, and Alan L Yuille. Surge: Surface regularized geometry estimation from a single image.Advances in Neu- ral Information Processing Systems, 29, 2016. 2
work page 2016
-
[75]
Occlusion aware unsupervised learning of optical flow
Yang Wang, Yi Yang, Zhenheng Yang, Liang Zhao, Peng Wang, and Wei Xu. Occlusion aware unsupervised learning of optical flow. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4884–4893,
-
[76]
Yan Wang, Wei-Lun Chao, Divyansh Garg, Bharath Hari- haran, Mark Campbell, and Kilian Q Weinberger. Pseudo- lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8445–8453, 2019. 1
work page 2019
-
[77]
The temporal opportunist: Self-supervised multi-frame monocular depth
Jamie Watson, Oisin Mac Aodha, Victor Prisacariu, Gabriel Brostow, and Michael Firman. The temporal opportunist: Self-supervised multi-frame monocular depth. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1164–1174, 2021. 2
work page 2021
-
[78]
Fastdepth: Fast monocular depth esti- mation on embedded systems
Diana Wofk, Fangchang Ma, Tien-Ju Yang, Sertac Karaman, and Vivienne Sze. Fastdepth: Fast monocular depth esti- mation on embedded systems. In2019 International Confer- ence on Robotics and Automation (ICRA), pages 6101–6108. IEEE, 2019. 1
work page 2019
-
[79]
Structure-guided ranking loss for single im- age depth prediction
Ke Xian, Jianming Zhang, Oliver Wang, Long Mai, Zhe Lin, and Zhiguo Cao. Structure-guided ranking loss for single im- age depth prediction. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 611–620, 2020. 2, 3
work page 2020
-
[80]
Holistically-nested edge de- tection
Saining Xie and Zhuowen Tu. Holistically-nested edge de- tection. InProceedings of the IEEE international conference on computer vision, pages 1395–1403, 2015. 2
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.