Recognition: no theorem link
SecureForge: Finding and Preventing Vulnerabilities in LLM-Generated Code via Prompt Optimization
Pith reviewed 2026-05-12 01:04 UTC · model grok-4.3
The pith
SecureForge optimizes system prompts to reduce vulnerabilities in LLM-generated code by up to 48% while preserving unit test success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
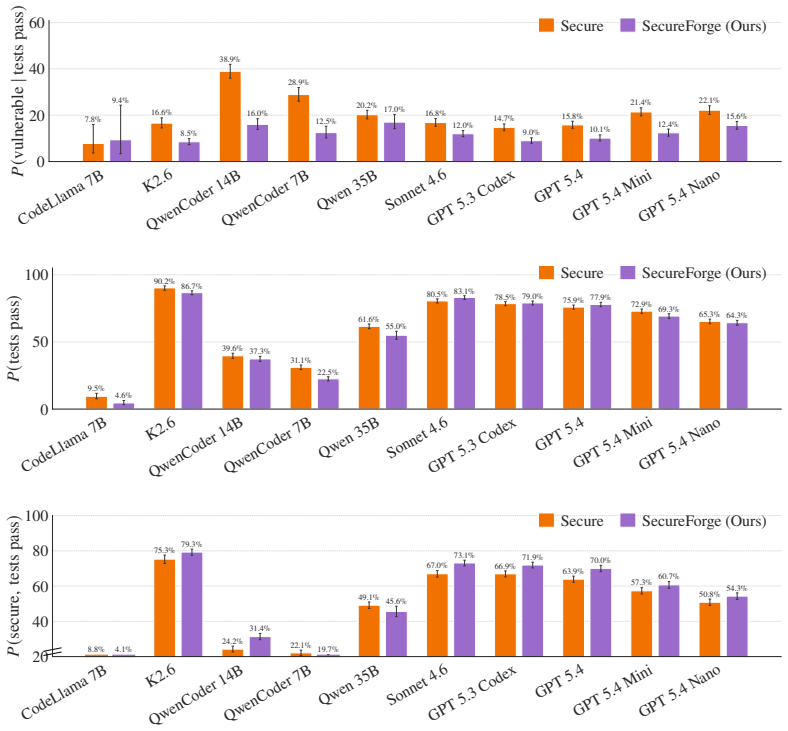
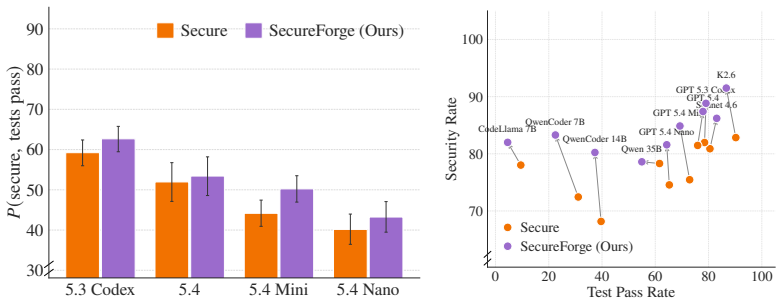
SecureForge first identifies benign prompts that produce statically detectable vulnerabilities, and then amplifies them into a large synthetic prompt corpus of diverse scenarios using a Markovian sampling technique to jointly maintain error rates and prompt diversity. This corpus is then used to iteratively optimize the system prompts to reduce output security vulnerabilities. On frontier models, SecureForge yields a statistically significant Pareto improvement in both unit test success and output security, with output vulnerabilities reduced by up to 48%. The resulting system prompts transfer zero-shot to in-the-wild coding agent prompts, without any exposure to real user prompt distri
What carries the argument
Markovian sampling technique that amplifies a seed set of vulnerability-triggering prompts into a large synthetic corpus while preserving both error rates and prompt diversity, followed by iterative system-prompt optimization on that corpus.
If this is right
- Output vulnerabilities drop by up to 48% on frontier models.
- Unit test success and security improve together rather than trading off.
- The refined prompts apply zero-shot to real coding-agent prompts never seen in training.
- No real user prompt data is required for the optimization step.
Where Pith is reading between the lines
- The same synthetic-corpus approach could be reused to tune prompts against other LLM failure modes such as logical errors or privacy leaks.
- Zero-shot transfer without real-user data exposure offers a route to safety tuning that avoids direct access to proprietary prompt logs.
- If the Markovian sampling step generalizes, similar pipelines could generate training material for security audits in domains beyond code generation.
Load-bearing premise
The synthetic corpus produced by Markovian sampling accurately reflects the vulnerability distribution and diversity found in actual user prompts.
What would settle it
Applying the optimized prompts to a large collection of real-world coding prompts drawn independently from any data used in the synthetic corpus and checking whether the vulnerability rate drops by a comparable amount.
Figures










read the original abstract
LLM coding agents now generate code at an unprecedented scale, yet LLM-generated code introduces cybersecurity vulnerabilities into codebases without human involvement. Even when frontier models are explicitly asked to write secure production code with relevant weaknesses to avoid in context, we find that they still produce verifiable vulnerabilities on average 23% of the time across a corpus of 250 benign coding prompts. We introduce SecureForge, an automated pipeline that both audits security risks of frontier models and produces auditing-informed secure system prompts that reduce output security vulnerabilities while maintaining unit test performance. SecureForge first identifies benign prompts that produce statically detectable vulnerabilities, and then amplifies them into a large synthetic prompt corpus of diverse scenarios using a Markovian sampling technique to jointly maintain error rates and prompt diversity. This corpus is then used to iteratively optimize the system prompts to reduce output security vulnerabilities. On frontier models, SecureForge yields a statistically significant Pareto improvement in both unit test success and output security, with output vulnerabilities reduced by up to 48%. The resulting system prompts transfer zero-shot to in-the-wild coding agent prompts, without any exposure to real user prompt distributions during optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SecureForge, a pipeline that audits LLM-generated code for security vulnerabilities by identifying benign prompts that trigger statically detectable issues, amplifies them into a large synthetic corpus via Markovian sampling while preserving error rates and diversity, and then iteratively optimizes system prompts on this corpus. It reports that frontier models produce verifiable vulnerabilities ~23% of the time even with secure-context prompts, and that the optimized prompts achieve a statistically significant Pareto improvement: up to 48% reduction in output vulnerabilities while maintaining unit-test success, with zero-shot transfer to in-the-wild coding-agent prompts.
Significance. If the central empirical claims hold, the work offers a practical, data-efficient method for hardening LLM coding agents against security issues without requiring exposure to real user prompt distributions. The combination of automated vulnerability discovery, synthetic corpus construction, and prompt optimization that generalizes zero-shot would be a notable contribution to the security of LLM-assisted software development.
major comments (3)
- [Abstract / Markovian sampling] Abstract and the description of the Markovian sampling technique: no quantitative validation (distributional distance, CWE-class histograms, embedding overlap, or diversity metrics) is provided to confirm that the synthetic corpus faithfully reproduces the vulnerability distribution and prompt diversity of real-world coding prompts. This assumption is load-bearing for the zero-shot transfer claim and the reported 48% reduction.
- [Abstract] Abstract: the 48% vulnerability reduction and statistical significance are stated without error bars, exact test details (e.g., paired t-test, Wilcoxon, or bootstrap), or per-model breakdowns beyond the initial 250-prompt corpus. This prevents assessment of effect-size stability and post-hoc selection risk.
- [Vulnerability identification] Vulnerability identification and verification step: insufficient detail on the static-analysis tools, false-positive handling, and manual verification protocol used to label the 23% baseline and post-optimization rates. Without this, the magnitude of the security improvement cannot be independently evaluated.
minor comments (2)
- [Abstract] The abstract refers to 'up to 48%' reduction; the main text should clarify whether this is the maximum across models or an average, and report the full range.
- Consider adding a limitations section that explicitly discusses potential mismatches between the synthetic corpus and real user prompts, even if the authors believe the Markovian method mitigates them.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review of our manuscript. We address each major comment point by point below, providing the strongest honest defense of the work while committing to revisions that improve clarity, rigor, and reproducibility without misrepresenting the original results.
read point-by-point responses
-
Referee: [Abstract / Markovian sampling] Abstract and the description of the Markovian sampling technique: no quantitative validation (distributional distance, CWE-class histograms, embedding overlap, or diversity metrics) is provided to confirm that the synthetic corpus faithfully reproduces the vulnerability distribution and prompt diversity of real-world coding prompts. This assumption is load-bearing for the zero-shot transfer claim and the reported 48% reduction.
Authors: We acknowledge that the manuscript as submitted does not report explicit quantitative validation metrics for the Markovian sampling procedure. The technique was constructed to preserve per-prompt error rates and lexical/semantic diversity by design, and the zero-shot transfer results provide indirect empirical support. However, we agree that direct distributional comparisons would make the claims more robust. In the revised manuscript we will add: (1) cosine similarity and Wasserstein distance on sentence embeddings between the synthetic corpus and a held-out set of real-world coding prompts, (2) side-by-side CWE-class histograms, (3) diversity statistics (unique n-gram coverage, prompt-length distribution, and semantic cluster entropy), and (4) a Kolmogorov-Smirnov test for distributional equality. These additions will be placed in a new subsection of the methods and will be linked to the zero-shot evaluation. revision: yes
-
Referee: [Abstract] Abstract: the 48% vulnerability reduction and statistical significance are stated without error bars, exact test details (e.g., paired t-test, Wilcoxon, or bootstrap), or per-model breakdowns beyond the initial 250-prompt corpus. This prevents assessment of effect-size stability and post-hoc selection risk.
Authors: We agree that the abstract and results section would benefit from fuller statistical disclosure. The reported 48% reduction is the largest observed improvement across the evaluated frontier models; statistical significance was assessed via paired t-tests on vulnerability rates (pre- vs. post-optimization) with p < 0.05 after Bonferroni correction for the number of models. In the revision we will: (a) add standard-error bars to all bar plots and tables, (b) explicitly state the test (paired t-test with effect-size Cohen’s d), (c) provide per-model tables showing baseline and optimized vulnerability rates plus unit-test success on the 250-prompt corpus, and (d) clarify that optimization was performed on the synthetic corpus while final numbers were obtained on held-out real prompts, thereby addressing post-hoc selection concerns. revision: yes
-
Referee: [Vulnerability identification] Vulnerability identification and verification step: insufficient detail on the static-analysis tools, false-positive handling, and manual verification protocol used to label the 23% baseline and post-optimization rates. Without this, the magnitude of the security improvement cannot be independently evaluated.
Authors: We accept that the current description of the vulnerability labeling pipeline is too terse. The pipeline combined Semgrep (with custom rules for the top-10 OWASP and CWE categories) and CodeQL data-flow queries. False positives were mitigated by a two-stage process: automatic filtering of low-confidence Semgrep matches followed by manual review of a stratified random sample of 150 flagged snippets (approximately 12% false-positive rate after review). Two independent annotators performed the review; disagreements were adjudicated by a third senior reviewer, with inter-annotator agreement measured by Cohen’s kappa = 0.87. In the revised manuscript we will expand the “Vulnerability Identification” subsection to include the exact tool versions, rule sets, sampling procedure for manual review, and the resulting false-positive statistics, enabling independent replication. revision: yes
Circularity Check
No circularity: empirical pipeline with no definitional or fitted reductions
full rationale
The paper describes an empirical pipeline—vulnerability detection on 250 prompts, Markovian amplification to synthetic corpus, iterative system-prompt optimization, and measurement of unit-test and security metrics—without any equations, derivations, or self-citations that reduce the reported 48% vulnerability reduction or zero-shot transfer to the inputs by construction. The optimization step is a standard search procedure whose outputs are externally evaluated; the synthetic corpus is generated from identified vulnerable prompts rather than being defined in terms of the final security gains. No load-bearing self-citation, ansatz smuggling, or renaming of known results appears in the provided text. The method is therefore self-contained as an experimental procedure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Beware of double agents: How AI can fortify — or fracture — your cybersecurity, 11 2025
Charlie Bell. Beware of double agents: How AI can fortify — or fracture — your cybersecurity, 11 2025. URL https://blogs.microsoft.com/blog/2025/11/05/ beware-of-double-agents-how-ai-can-fortify-or-fracture-your-cybersecurity/
work page 2025
-
[2]
Asleep at the keyboard? Assessing the security of github copilot’s code contributions.Commun
Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, and Ramesh Karri. Asleep at the keyboard? Assessing the security of github copilot’s code contributions.Commun. ACM, 68(2):96–105, January 2025. ISSN 0001-0782. doi: 10.1145/3610721. URL https: //doi.org/10.1145/3610721
-
[5]
URLhttps://arxiv.org/pdf/2604.20779
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Measuring ai agents’ progress on multi-step cyber attack scenarios,
Linus Folkerts, Will Payne, Simon Inman, Philippos Giavridis, Joe Skinner, Sam Deverett, James Aung, Ekin Zorer, Michael Schmatz, Mahmoud Ghanem, John Wilkinson, Alan Steer, Vy Hong, and Jessica Wang. Measuring AI agents’ progress on multi-step cyber attack scenarios.arXiv preprint arXiv:2603.11214, March 2026. URLhttps://arxiv.org/pdf/2603.11214
-
[7]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=VTF8yNQM66
work page 2024
-
[8]
Shengye Wan, Cyrus Nikolaidis, Daniel Song, David Molnar, James Crnkovich, Jayson Grace, Manish Bhatt, Sahana Chennabasappa, Spencer Whitman, Stephanie Ding, Vlad Ionescu, Yue Li, and Joshua Saxe. CYBERSECEV AL 3: Advancing the Evaluation of Cybersecurity Risks and Capabilities in Large Language Models, September 2024. URLhttp://arxiv.org/abs/ 2408.01605....
-
[9]
Purple Llama CyberSecEval: A Secure Coding Benchmark for Language Models, December
Manish Bhatt, Sahana Chennabasappa, Cyrus Nikolaidis, Shengye Wan, Ivan Evtimov, Dominik Gabi, Daniel Song, Faizan Ahmad, Cornelius Aschermann, Lorenzo Fontana, Sasha Frolov, Ravi Prakash Giri, Dhaval Kapil, Yiannis Kozyrakis, David LeBlanc, James Milazzo, Alek- sandar Straumann, Gabriel Synnaeve, Varun V ontimitta, Spencer Whitman, and Joshua Saxe. Purpl...
-
[10]
Purple llama CyberSecEval : A secure coding benchmark for language models
URLhttp://arxiv.org/abs/2312.04724. arXiv:2312.04724 [cs]
-
[11]
Maddison, and Tatsunori Hashimoto
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. Identifying the risks of LM agents with an LM-emulated sandbox. InThe Twelfth International Conference on Learning Representations,
-
[12]
URLhttps://openreview.net/forum?id=GEcwtMk1uA
-
[13]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Pro- cessing Systems, volume...
-
[14]
Agentpoison: red-teaming llm agents via poisoning memory or knowledge bases
Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li. Agentpoison: red-teaming llm agents via poisoning memory or knowledge bases. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2024. Curran Associates Inc. ISBN 9798331314385
work page 2024
-
[15]
Mark Vero, Niels Mündler, Victor Chibotaru, Veselin Raychev, Maximilian Baader, Nikola Jovanovi´c, Jingxuan He, and Martin Vechev. Baxbench: Can LLMs generate correct and secure backends? InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=il3KRr4H9u
work page 2025
-
[16]
Security weaknesses of copilot-generated code in github projects: An empirical study.ACM Trans
Yujia Fu, Peng Liang, Amjed Tahir, Zengyang Li, Mojtaba Shahin, Jiaxin Yu, and Jinfu Chen. Security weaknesses of copilot-generated code in github projects: An empirical study.ACM Trans. Softw. Eng. Methodol., 34(8), October 2025. ISSN 1049-331X. doi: 10.1145/3716848. URLhttps://doi.org/10.1145/3716848
-
[17]
Robert A. Martin and Sean Barnum. Common weakness enumeration (cwe) status update.Ada Lett., XXVIII(1):88–91, April 2008. ISSN 1094-3641. doi: 10.1145/1387830.1387835. URL https://doi.org/10.1145/1387830.1387835
-
[18]
Hossein Hajipour, Keno Hassler, Thorsten Holz, Lea Schönherr, and Mario Fritz. CodeLM- Sec Benchmark: Systematically Evaluating and Finding Security Vulnerabilities in Black- Box Code Language Models, October 2023. URL http://arxiv.org/abs/2302.04012. arXiv:2302.04012 [cs]
-
[19]
Black-Box Adversarial Attacks on LLM-Based Code Completion, June 2025
Slobodan Jenko, Niels Mündler, Jingxuan He, Mark Vero, and Martin Vechev. Black-Box Adversarial Attacks on LLM-Based Code Completion, June 2025. URL http://arxiv.org/ abs/2408.02509. arXiv:2408.02509 [cs]
-
[20]
RedCode: Risky Code Execution and Generation Benchmark for Code Agents
Chengquan Guo, Xun Liu, Chulin Xie, Andy Zhou, Yi Zeng, Zinan Lin, Dawn Song, and Bo Li. RedCode: Risky Code Execution and Generation Benchmark for Code Agents. 2024
work page 2024
-
[21]
Assessing the Security of GitHub Copilot’s Generated Code - A Targeted Replication Study
Vahid Majdinasab, Michael Joshua Bishop, Shawn Rasheed, Arghavan Moradidakhel, Amjed Tahir, and Foutse Khomh. Assessing the Security of GitHub Copilot’s Generated Code - A Targeted Replication Study . In2024 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), pages 435–444, Los Alamitos, CA, USA, March
-
[22]
doi: 10.1109/SANER60148.2024.00051
IEEE Computer Society. doi: 10.1109/SANER60148.2024.00051. URL https://doi. ieeecomputersociety.org/10.1109/SANER60148.2024.00051
-
[23]
Security Weaknesses of Copilot-Generated Code in GitHub Projects: An Empirical Study, February 2025
Yujia Fu, Peng Liang, Amjed Tahir, Zengyang Li, Mojtaba Shahin, Jiaxin Yu, and Jinfu Chen. Security Weaknesses of Copilot-Generated Code in GitHub Projects: An Empirical Study, February 2025. URLhttp://arxiv.org/abs/2310.02059. arXiv:2310.02059 [cs]
-
[24]
In Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security
Jingxuan He and Martin Vechev. Large language models for code: Security hardening and adversarial testing. InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, CCS ’23, page 1865–1879, New York, NY , USA, 2023. Association for Computing Machinery. ISBN 9798400700507. doi: 10.1145/3576915.3623175. URL https://doi.org/10....
-
[25]
Instruction tuning for secure code generation
Jingxuan He, Mark Vero, Gabriela Krasnopolska, and Martin Vechev. Instruction tuning for secure code generation. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024. URLhttps://arxiv.org/abs/2402.09497
-
[26]
PROSEC: fortifying code LLMs with proactive security alignment
Xiangzhe Xu, Zian Su, Jinyao Guo, Kaiyuan Zhang, Zhenting Wang, and Xiangyu Zhang. PROSEC: fortifying code LLMs with proactive security alignment. InProceedings of the 42nd International Conference on Machine Learning, ICML’25. JMLR.org, 2025. URL https: //arxiv.org/abs/2411.12882
-
[27]
Cybersecurity and Infrastructure Security Agency. Secure by design pledge. U.S. Cybersecurity and Infrastructure Security Agency, 2024. URLhttps://www.cisa.gov/securebydesign/ pledge. Accessed 2026-04-23
work page 2024
-
[28]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and Transferable Adversarial Attacks on Aligned Language Models, December 2023. URLhttp://arxiv.org/abs/2307.15043. arXiv:2307.15043 [cs]. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Gradient-based language model red teaming
Nevan Wichers, Carson Denison, and Ahmad Beirami. Gradient-based language model red teaming. In Yvette Graham and Matthew Purver, editors,Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2862–2881, St. Julian’s, Malta, March 2024. Association for Computational Lingui...
-
[30]
Red Teaming Language Models with Language Models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3419–3448, Abu Dhabi,...
-
[31]
Amelia Hardy, Houjun Liu, Allie Griffith, Bernard Lange, Duncan Eddy, and Mykel Kochen- derfer. ASTPrompter: Preference-aligned automated language model red-teaming to generate low-perplexity unsafe prompts. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Linguistics:...
-
[32]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, Eric Winsor, Jerome Wynne, Yarin Gal, and Xander Davies. AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents, April 2025. URLhttp://arxiv.org/abs/2410.09024. arXiv:2410.09024 [cs]
work page internal anchor Pith review arXiv 2025
- [33]
-
[34]
Nicholas Metropolis, Arianna W Rosenbluth, Marshall N Rosenbluth, Augusta H Teller, and Edward Teller. Equation of state calculations by fast computing machines.The journal of chemical physics, 21(6):1087–1092, 1953
work page 1953
-
[35]
Monte carlo sampling methods using markov chains and their applications
W Keith Hastings. Monte carlo sampling methods using markov chains and their applications. 1970
work page 1970
-
[36]
Ulf Grenander and Michael I Miller. Representations of knowledge in complex systems.Journal of the Royal Statistical Society: Series B (Methodological), 56(4):549–581, 1994
work page 1994
-
[37]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedbac...
work page 2022
-
[38]
Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan A, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. DSPy: Compiling declarative language model calls into state-of-the-art pipelines. InThe Twelfth International Conference on Learning Represent...
work page 2024
-
[39]
Semgrep: Lightweight static analysis for many languages
Semgrep, Inc. Semgrep: Lightweight static analysis for many languages. Open-source static analysis tool, 2025. URLhttps://semgrep.dev/. Accessed 2026-04-18. 12
work page 2025
-
[40]
GEPA: Reflective prompt evolution can outperform reinforcement learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl- Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alex Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. GEPA: Reflective prompt evolution can outperform reinforcement learning. InInternational Conference on...
work page 2026
-
[41]
Qwen2.5-Coder Technical Report
Binyuan Hui, Jian Yang, Zeyu Cui, An Yang, Dayiheng Liu, Lei Zhang, Tianyu Zhang, Kai Dang, Bowen Yu, Rui Men, Chengyuan Li, Junyang Lin, Jingren Zhou, Dahua Lin, Jingren Gu, et al. Qwen2.5-Coder technical report.arXiv preprint arXiv:2409.12186, 2024. URL https://arxiv.org/abs/2409.12186
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. URL https: //arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Code Llama: Open Foundation Models for Code
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950, 2023. URL https://arxiv.org/abs/2308.12950
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Kimi K2: Open Agentic Intelligence
Kimi Team. Kimi K2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025. URL https://arxiv.org/abs/2507.20534
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
GPT-5.3-Codex system card, February 2026
OpenAI. GPT-5.3-Codex system card, February 2026. URL https://openai.com/index/ gpt-5-3-codex-system-card/
work page 2026
-
[46]
Claude Sonnet 4.6 system card, February 2026
Anthropic. Claude Sonnet 4.6 system card, February 2026. URL https://www.anthropic. com/claude-sonnet-4-6-system-card
work page 2026
- [47]
-
[48]
Optimizing instructions and demonstrations for multi-stage language model programs
Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab. Optimizing instructions and demonstrations for multi-stage language model programs. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9...
-
[49]
") description: Description of the CWEs the task excercises - test_code: str (default
Zhang-Wei Hong, Idan Shenfeld, Tsun-Hsuan Wang, Yung-Sung Chuang, Aldo Pareja, James R. Glass, Akash Srivastava, and Pulkit Agrawal. Curiosity-driven red-teaming for large language models. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=4KqkizXgXU. A Mipro vs. GEPA We compare in fig. 6 here two...
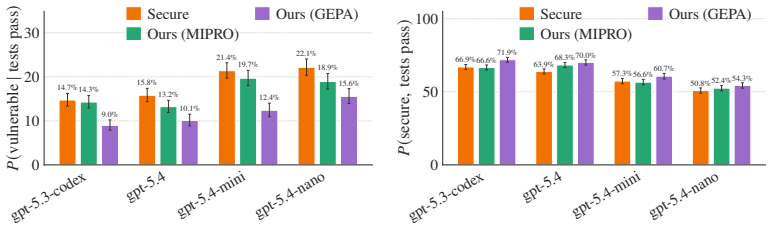
work page 2024
-
[50]
PRESERVE EVERY USER-STATED DETAIL. Every specific requirement, constraint, file path, function name, API shape, test case, edge case, stylistic preference, and data example the user mentioned must survive into the distilled task. When in doubt, include it. Verbatim quoting of user phrasing is allowed and encouraged where the phrasing is clear
-
[51]
RESOLVE SHORT REPLIES USING AGENT CONTEXT. When a user entry is a short reply like " yes please", "go ahead", "option 2", "no, the other one", use the [PRECEDING AGENT CONTEXT] to figure out WHAT the user is agreeing to or choosing, and write the resolved choice into the distilled task AS USER INTENT. Capture only the high-level " what" the user adopted -...
-
[52]
NO META-DIALOGUE. Do not reference "the previous agent", "the conversation", "earlier messages", "the assistant", or the multi-turn nature of the source. Write the task as a single fresh request
-
[53]
NEVER INVENT REQUIREMENTS. Do not add acceptance criteria, non-functional requirements, testing expectations, error-handling policies, or constraints the user did not state. No boilerplate like "ensure robustness" or "add proper error handling" unless the user said so
-
[54]
OUTPUT FORMAT. Return ONLY the distilled task as a single plain-text string. No preamble, no headers, no JSON, no markdown scaffolding unless the user's own prompts used markdown. No "Here is the task:" introduction. No trailing commentary. Just the task
-
[55]
Keep it as long as it needs to be to preserve every user detail, and no longer
LENGTH. Keep it as long as it needs to be to preserve every user detail, and no longer. Do not pad. 21
-
[56]
DO NOT COPY SOLUTION DETAILS FROM AGENT MESSAGES. Even though you can see agent context, you MUST NOT copy code snippets, file diffs, step-by-step implementation plans, function bodies, detailed variable names, specific imports, or line-by-line recipes from agent messages
-
[57]
WHEN THE USER GAVE NO REPLY TO AN AGENT PROPOSAL, IGNORE IT. If the agent proposed something but the user did not endorse it (no subsequent reply, or the user said something else), that proposal is not part of the task
-
[58]
COLLAPSE REVERSALS AND CORRECTIONS. If the user said "do X" and later "actually do Y instead", keep only Y. If the user said "you forgot Z", incorporate Z as a stated requirement without referencing the prior mistake. The distilled task represents the user's FINAL intent
-
[59]
PRIOR CONTEXT IS DONE. If prior context says "add function foo to bar.py" and the current block says "now add a test for foo", write "Add a test for the existing` foo`function in`bar.py`" -- treating foo as already present. JSecureForgetoolkit Automatic generation ofbenignprompts and language model rollouts that exercise specific software vulnerabilities ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.