Recognition: no theorem link
Mid-Training with Self-Generated Data Improves Reinforcement Learning in Language Models
Pith reviewed 2026-05-12 01:07 UTC · model grok-4.3
The pith
Mid-training on multiple self-generated correct variants of answers improves subsequent reinforcement learning performance in language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
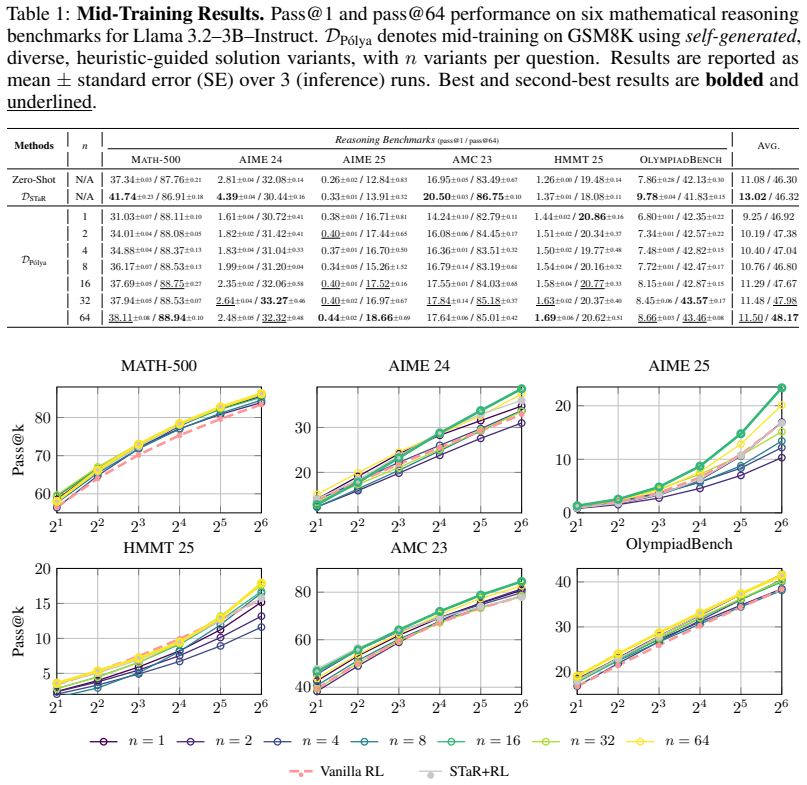
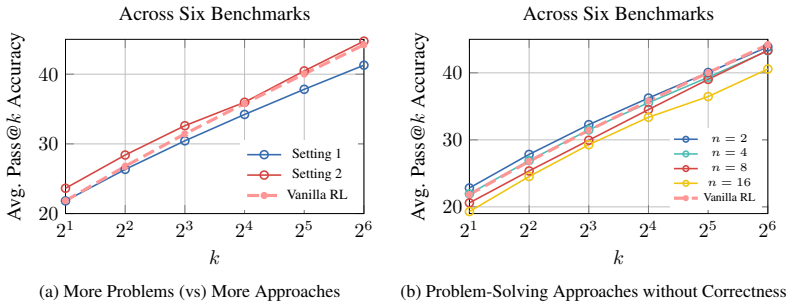
Mid-training language models on bootstrapped self-generated data that contains multiple correct variants of answers, produced according to Polya's problem-solving approaches, improves the effectiveness of subsequent RL training. A theoretical argument shows that policy-gradient updates can then incentivize the model to combine several approaches rather than converging on one. Empirically, RL models initialized from this mid-trained checkpoint obtain consistent gains on mathematical reasoning benchmarks and on out-of-distribution tasks including code generation and narrative reasoning.
What carries the argument
The bootstrapped data-generation framework that uses Polya's problem-solving approaches to create multiple correct answer variants per question for mid-training before RL.
If this is right
- RL models that begin from the mid-trained checkpoint achieve higher scores on mathematical reasoning benchmarks.
- The same initialization produces gains on out-of-distribution tasks such as code generation and narrative reasoning.
- Policy-gradient updates become able to combine multiple problem-solving approaches when the model has seen them during mid-training.
- Learning several correct strategies through self-generated data supplies a stronger starting policy for RL.
Where Pith is reading between the lines
- The method may lower the total amount of RL data or compute needed to reach a target performance level.
- It could be tested on domains beyond math where multiple valid strategies exist, such as planning or story generation.
- If the generation process systematically favors certain styles of solution, gains might be limited on problems that require very different approaches.
- Scaling the number of variants per question or applying the same mid-training step to other base models would be direct next experiments.
Load-bearing premise
The self-generated answer variants stay correct and diverse enough that they do not introduce systematic errors that would weaken the RL signal.
What would settle it
Running RL from the mid-trained checkpoint and finding no improvement over a standard initialization on the mathematical reasoning benchmarks, or discovering that a substantial fraction of the generated variants contain undetected errors that degrade policy quality.
Figures










read the original abstract
The effectiveness of Reinforcement Learning (RL) in Large Language Models (LLMs) depends on the nature and diversity of the data used before and during RL. In particular, reasoning problems can often be approached in multiple ways that rely on different forms of reasoning, and exposure to only a limited range of such approaches in the training data may limit the effectiveness of RL. Motivated by this, we investigate using diverse self-generated data during mid-training as an intermediate step before RL training. Specifically, we adopt a bootstrapped data-generation framework guided by George Polya's problem-solving approaches for generating multiple variants of correct answers for each question in the training data, and then perform fine-tuning. We first provide a theoretical perspective on how mid-training on such data improves RL and explain how policy-gradient updates can incentivize combining multiple approaches. We then empirically demonstrate that RL-trained models initialized with our mid-training data achieve consistent improvements across various mathematical reasoning benchmarks and other OOD tasks like code generation and narrative reasoning. Overall, our investigative study shows that a language model learning multiple problem-solving approaches, through self-generated data helps subsequent RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that mid-training LLMs on diverse self-generated variants of reasoning problems—produced via a bootstrapped framework guided by Polya's heuristics—serves as an effective intermediate step before RL training. It sketches a policy-gradient argument explaining how exposure to multiple correct approaches incentivizes better combination of strategies during RL, and reports consistent empirical gains on mathematical reasoning benchmarks plus OOD tasks including code generation and narrative reasoning.
Significance. If the self-generated data is verifiably correct and diverse, the approach could offer a practical method to strengthen RL by addressing limited reasoning diversity in pre-RL data. The theoretical link to policy-gradient incentives provides a plausible mechanism, and the multi-benchmark evaluation (including OOD) suggests potential generality. This would be a useful contribution to data curation for RL in LLMs, though its impact hinges on securing the data-quality precondition.
major comments (2)
- Abstract and data-generation framework: the claim that bootstrapped generation produces 'multiple variants of correct answers' for each question lacks any reported error-rate statistics, diversity metrics (e.g., semantic or reasoning-path distinctness), or verification details (model-based vs. external oracle). This is load-bearing for the central claim, because undetected systematic errors or superficial variants would reduce mid-training to noisy SFT and undermine the policy-gradient incentive argument that diversity enables combining approaches.
- Empirical evaluation section: the reported consistent improvements lack specification of baselines, statistical significance tests, exact number of variants per question, data filtering rules, and the precise generation procedure. Without these, the gains cannot be fully attributed to the proposed mid-training or assessed for robustness.
minor comments (2)
- The theoretical perspective would benefit from explicit equations or a formal derivation showing how mid-training diversity modifies the policy gradient, rather than a high-level sketch.
- Add a specific citation to Polya's original work on heuristics when describing the generation framework.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify key aspects of our work. We address each major comment below and will revise the manuscript to incorporate the requested details and clarifications.
read point-by-point responses
-
Referee: Abstract and data-generation framework: the claim that bootstrapped generation produces 'multiple variants of correct answers' for each question lacks any reported error-rate statistics, diversity metrics (e.g., semantic or reasoning-path distinctness), or verification details (model-based vs. external oracle). This is load-bearing for the central claim, because undetected systematic errors or superficial variants would reduce mid-training to noisy SFT and undermine the policy-gradient incentive argument that diversity enables combining approaches.
Authors: We agree that quantitative support for data correctness and diversity is essential to substantiate the central claims and the policy-gradient argument. In the revised manuscript, we will add error-rate statistics from manual verification on a random sample of 200 generated variants (reporting the fraction that are verifiably correct), diversity metrics including the average number of distinct reasoning paths per question (measured by step-level edit distance) and semantic similarity scores via embedding cosine distance, and full verification details (hybrid model-based filtering followed by oracle checks on a subset). These additions will confirm that the variants are both correct and meaningfully diverse, directly bolstering the incentive mechanism described in the theoretical section. revision: yes
-
Referee: Empirical evaluation section: the reported consistent improvements lack specification of baselines, statistical significance tests, exact number of variants per question, data filtering rules, and the precise generation procedure. Without these, the gains cannot be fully attributed to the proposed mid-training or assessed for robustness.
Authors: We acknowledge the need for greater specificity to enable attribution and reproducibility. The revised manuscript will include: explicit baselines (vanilla RL without mid-training, SFT on original data only, and random variant augmentation); statistical significance via paired t-tests and p-values across 5 independent runs with different seeds; the exact number of variants generated per question (4 on average, with a range of 3-5); data filtering rules (duplicate removal via embedding similarity threshold, discard of variants below a model confidence threshold of 0.7); and a precise, step-by-step description of the Polya-guided bootstrapped generation procedure including prompt templates and hyperparameters. These revisions will allow readers to fully assess the robustness and source of the reported gains. revision: yes
Circularity Check
No circularity; theory is explanatory and empirical results independent
full rationale
The paper's chain consists of (1) generating self-bootstrapped variants via Polya heuristics, (2) a theoretical explanation that policy gradients can incentivize combining multiple approaches when diversity is present, and (3) empirical RL improvements on benchmarks. No equation or claim reduces by construction to a fitted parameter, self-citation, or renamed input. The theoretical section offers a general incentive argument rather than a closed-form prediction that matches the mid-training data by definition. Empirical gains are presented as separate validation, not forced by the theory. This satisfies the self-contained criterion; the skeptic concern about data quality is a correctness issue, not a circularity reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of variants per question
axioms (1)
- domain assumption Self-generated answers produced via Polya's problem-solving steps are both correct and diverse enough to improve downstream RL.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2402.10571 , year=
Afra Amini, Tim Vieira, and Ryan Cotterell. Direct preference optimization with an off- set.ArXiv, abs/2402.10571, 2024. URL https://api.semanticscholar.org/CorpusID: 267740352
-
[2]
Matharena: Evaluating llms on uncontaminated math competitions, February 2025
Mislav Balunovi ´c, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi ´c, and Martin Vechev. Matharena: Evaluating llms on uncontaminated math competitions, February 2025. URL https://matharena.ai/
work page 2025
-
[3]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page 2021
-
[4]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Sitao Cheng, Xunjian Yin, Ruiwen Zhou, Yuxuan Li, Xinyi Wang, Liangming Pan, William Yang Wang, and Victor Zhong. From atomic to composite: Reinforcement learning enables general- ization in complementary reasoning.arXiv preprint arXiv:2512.01970, 2025
-
[6]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review arXiv 2025
-
[8]
Dan Friedman and Adji Bousso Dieng. The vendi score: A diversity evaluation metric for machine learning.arXiv preprint arXiv:2210.02410, 2022
-
[9]
Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars
Kanishk Gandhi, Ayush Chakravarthy, Anikait Singh, Nathan Lile, and Noah D Goodman. Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars.arXiv preprint arXiv:2503.01307, 2025
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Targen: Targeted data genera- tion with large language models.arXiv preprint arXiv:2310.17876, 2023
Himanshu Gupta, Kevin Scaria, Ujjwala Anantheswaran, Shreyas Verma, Mihir Parmar, Saurabh Arjun Sawant, Chitta Baral, and Swaroop Mishra. Targen: Targeted data genera- tion with large language models.arXiv preprint arXiv:2310.17876, 2023
-
[14]
Andre He, Daniel Fried, and Sean Welleck. Rewarding the unlikely: Lifting grpo beyond distribution sharpening.arXiv preprint arXiv:2506.02355, 2025. 10
-
[15]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems.arXiv preprint arXiv:2402.14008, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
arXiv preprint arXiv:2504.11456 , year =
Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, et al. Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning.arXiv preprint arXiv:2504.11456, 2025
-
[17]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
Unnatural instructions: Tuning language models with (almost) no human labor
Or Honovich, Thomas Scialom, Omer Levy, and Timo Schick. Unnatural instructions: Tuning language models with (almost) no human labor. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14409–14428, 2023
work page 2023
-
[19]
Math-verify: Robust mathematical expression evaluator
Hugging Face. Math-verify: Robust mathematical expression evaluator. https://github. com/huggingface/Math-Verify, 2025. GitHub repository; version <vX.Y .Z>; accessed 2025-09-09
work page 2025
-
[20]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
arXiv preprint arXiv:2510.13786 , year=
Devvrit Khatri, Lovish Madaan, Rishabh Tiwari, Rachit Bansal, Sai Surya Duvvuri, Manzil Zaheer, Inderjit S Dhillon, David Brandfonbrener, and Rishabh Agarwal. The art of scaling reinforcement learning compute for llms.arXiv preprint arXiv:2510.13786, 2025
-
[23]
Spoc: Search-based pseudocode to code.Advances in Neural Information Processing Systems, 32, 2019
Sumith Kulal, Panupong Pasupat, Kartik Chandra, Mina Lee, Oded Padon, Alex Aiken, and Percy S Liang. Spoc: Search-based pseudocode to code.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[24]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
-
[25]
Step-dpo: Step-wise preference optimization for long-chain reasoning of llms, 2024
Xin Lai, Zhuotao Tian, Yukang Chen, Senqiao Yang, Xiangru Peng, and Jiaya Jia. Step- dpo: Step-wise preference optimization for long-chain reasoning of llms.arXiv preprint arXiv:2406.18629, 2024
-
[26]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
The measurement of observer agreement for categorical data.biometrics, pages 159–174, 1977
J Richard Landis and Gary G Koch. The measurement of observer agreement for categorical data.biometrics, pages 159–174, 1977
work page 1977
-
[28]
Small models struggle to learn from strong reasoners
Yuetai Li, Xiang Yue, Zhangchen Xu, Fengqing Jiang, Luyao Niu, Bill Yuchen Lin, Bhaskar Ramasubramanian, and Radha Poovendran. Small models struggle to learn from strong reasoners. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 25366–25394, ...
-
[29]
arXiv preprint arXiv:2507.01352 , year=
Chris Yuhao Liu, Liang Zeng, Yuzhen Xiao, Jujie He, Jiacai Liu, Chaojie Wang, Rui Yan, Wei Shen, Fuxiang Zhang, Jiacheng Xu, Yang Liu, and Yahui Zhou. Skywork-reward-v2: Scaling preference data curation via human-ai synergy.arXiv preprint arXiv:2507.01352, 2025
-
[30]
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward.Advances in Neural Information Processing Systems, 37:124198–124235, 2024
work page 2024
-
[31]
Cross-task gener- alization via natural language crowdsourcing instructions
Swaroop Mishra, Daniel Khashabi, Chitta Baral, and Hannaneh Hajishirzi. Cross-task gener- alization via natural language crowdsourcing instructions. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3470–3487, 2022
work page 2022
-
[32]
Orca 2: Teaching small language models how to reason.arXiv preprint arXiv:2311.11045, 2023
Arindam Mitra, Luciano Del Corro, Shweti Mahajan, Andres Codas, Clarisse Simoes, Sahaj Agarwal, Xuxi Chen, Anastasia Razdaibiedina, Erik Jones, Kriti Aggarwal, et al. Orca 2: Teaching small language models how to reason.arXiv preprint arXiv:2311.11045, 2023
-
[33]
Mid-training of large language models: A survey.arXiv preprint arXiv:2510.06826, 2025
Kaixiang Mo, Yuxin Shi, Weiwei Weng, Zhiqiang Zhou, Shuman Liu, Haibo Zhang, and Anxi- ang Zeng. Mid-training of large language models: A survey.arXiv preprint arXiv:2510.06826, 2025
-
[34]
Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. Orca: Progressive learning from complex explanation traces of gpt-4.arXiv preprint arXiv:2306.02707, 2023
-
[35]
AMC 12A (2023): Problems and Solutions
Mathematical Association of America. AMC 12A (2023): Problems and Solutions. https: //artofproblemsolving.com/wiki/index.php/2023_AMC_12A_Problems, 2023. Com- petition held Nov 8, 2023. Problems © MAA AMC
work page 2023
-
[36]
Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, et al. Olmo 3.arXiv preprint arXiv:2512.13961, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
New embedding models and api updates
OpenAI. New embedding models and api updates. https://openai.com/index/ new-embedding-models-and-api-updates/, January 2024
work page 2024
-
[38]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[39]
Ravsehaj Singh Puri, Swaroop Mishra, Mihir Parmar, and Chitta Baral. How many data samples is an additional instruction worth? InFindings of the Association for Computational Linguistics: EACL 2023, pages 1042–1057, 2023
work page 2023
-
[40]
George Pólya and John Horton Conway.How to solve it. Princeton science library. Princeton University Press, Princeton [N.J.], expanded princeton science library ed. edition, 2004. ISBN 0-691-11966-X ; 978-0-691-11966-3. Includes bibliographical references
work page 2004
-
[41]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
work page 2023
-
[42]
Aswin RRV , Jacob Dineen, Divij Handa, Md Nayem Uddin, Mihir Parmar, Chitta Baral, and Ben Zhou. Thinktuning: Instilling cognitive reflections without distillation.arXiv preprint arXiv:2508.07616, 2025
-
[43]
Amir Saeidi, Shivanshu Verma, Aswin RRV , Kashif Rasul, and Chitta Baral. Triple preference optimization: Achieving better alignment using a single step optimization.arXiv preprint arXiv:2405.16681, 2024
-
[44]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. 12
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
Amrith Setlur, Saurabh Garg, Xinyang Geng, Naman Garg, Virginia Smith, and Aviral Kumar. Rl on incorrect synthetic data scales the efficiency of llm math reasoning by eight-fold.Advances in Neural Information Processing Systems, 37:43000–43031, 2024
work page 2024
-
[46]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Yankai Li, Yu Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Musr: Testing the limits of chain-of-thought with multistep soft reasoning.arXiv:2310.16049,
Zayne Sprague, Xi Ye, Kaj Bostrom, Swarat Chaudhuri, and Greg Durrett. Musr: Testing the limits of chain-of-thought with multistep soft reasoning.arXiv preprint arXiv:2310.16049, 2023
-
[49]
Qwq-32b: Embracing the power of reinforcement learning, March 2025
Qwen Team. Qwq-32b: Embracing the power of reinforcement learning, March 2025. URL https://qwenlm.github.io/blog/qwq-32b/
work page 2025
-
[50]
A survey on llm mid-training.arXiv preprint arXiv:2510.23081, 2025
Chengying Tu, Xuemiao Zhang, Rongxiang Weng, Rumei Li, Chen Zhang, Yang Bai, Hongfei Yan, Jingang Wang, and Xunliang Cai. A survey on llm mid-training.arXiv preprint arXiv:2510.23081, 2025
-
[51]
Trl: Transformer reinforce- ment learning.https://github.com/huggingface/trl, 2020
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. Trl: Transformer reinforce- ment learning.https://github.com/huggingface/trl, 2020
work page 2020
-
[52]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.01939, 2025
work page internal anchor Pith review arXiv 2025
-
[53]
Self-instruct: Aligning language models with self-generated instruc- tions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instruc- tions. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 13484–13508, 2023
work page 2023
-
[54]
Finetuned Language Models Are Zero-Shot Learners
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners.arXiv preprint arXiv:2109.01652, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[55]
Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist re- inforcement learning.Mach. Learn., 8(3–4):229–256, May 1992. ISSN 0885-6125. doi: 10.1007/BF00992696. URLhttps://doi.org/10.1007/BF00992696
-
[56]
Wizardlm: Empowering large pre-trained language models to follow complex instructions
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Qing- wei Lin, and Daxin Jiang. Wizardlm: Empowering large pre-trained language models to follow complex instructions. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[57]
Kodcode: A diverse, challenging, and verifiable synthetic dataset for coding
Zhangchen Xu, Yang Liu, Yueqin Yin, Mingyuan Zhou, and Radha Poovendran. Kodcode: A diverse, challenging, and verifiable synthetic dataset for coding. 2025. URL https://arxiv. org/abs/2503.02951
-
[58]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Weinan Dai, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
arXiv preprint arXiv:2509.25123 , year=
Lifan Yuan, Weize Chen, Yuchen Zhang, Ganqu Cui, Hanbin Wang, Ziming You, Ning Ding, Zhiyuan Liu, Maosong Sun, and Hao Peng. From f(x) and g(x) to f(g(x)) : Llms learn new skills in rl by composing old ones, 2025. URLhttps://arxiv.org/abs/2509.25123
-
[60]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv preprint arXiv:2504.13837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning.Advances in Neural Information Processing Systems, 35:15476–15488, 2022
work page 2022
-
[62]
Charlie Zhang, Graham Neubig, and Xiang Yue. On the interplay of pre-training, mid-training, and rl on reasoning language models, 2025. URLhttps://arxiv.org/abs/2512.07783
-
[63]
American invitational mathematics examination (aime) 2024, 2024
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2024, 2024
work page 2024
-
[64]
American invitational mathematics examination (aime) 2025, 2025
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2025, 2025
work page 2025
-
[65]
Each sentence in the generated text uses a second person
Yang Zhou, Sunzhu Li, Shunyu Liu, Wenkai Fang, Jiale Zhao, Jingwen Yang, Jianwei Lv, Kongcheng Zhang, Yihe Zhou, Hengtong Lu, et al. Breaking the exploration bottleneck: Rubric- scaffolded reinforcement learning for general llm reasoning.arXiv preprint arXiv:2508.16949, 2025. 14 Table of Contents A Appendix. . . . . . . . . . . . . . . . . . . . . . . . ....
-
[66]
Filter candidates by answer correctness via Math-Verify
-
[67]
Score remaining candidates with reward model
-
[68]
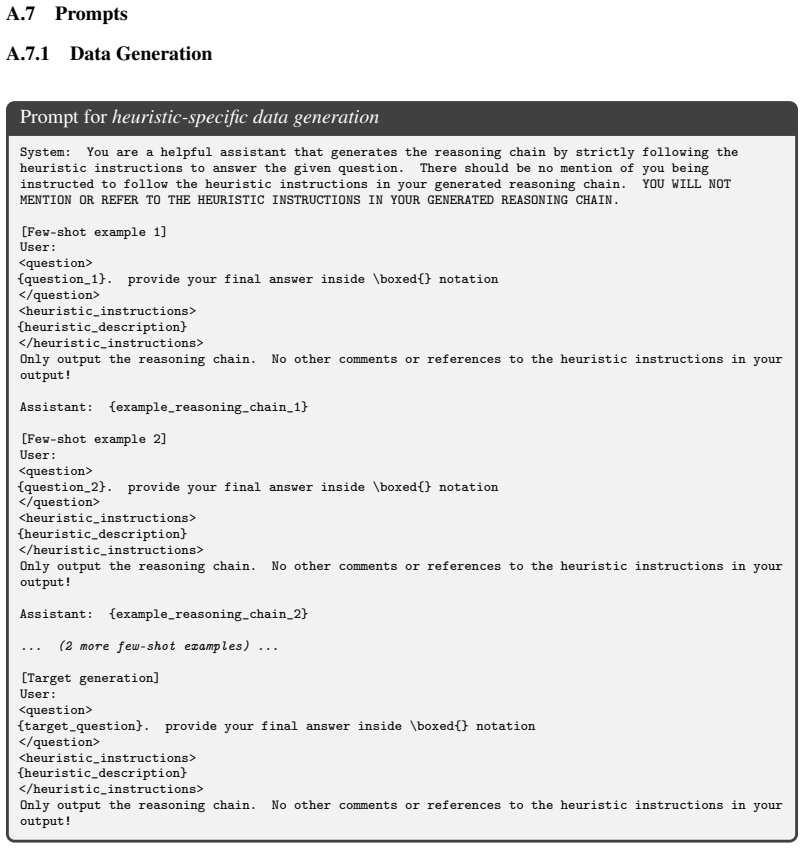
Select response with highest score as final heuristic-specific solution Figure 8: Reward model scoring pipeline. After filtering for correctness, Skywork-Reward-V2 ranks candidate responses by heuristic adherence. The highest-scoring response per (question, heuristic) pair is selected for mid-training. A.7.2 Reinforcement Learning RL Training Data Format ...
work page 2024
-
[69]
benchmark scale. These results further support the reliability of our automated classifier for large-scale heuristic annotation. Human Annotation Interface Instructions: For each sample, determine if the reasoning chain exhibits the described behavior. Click Yes or No.). Sample 1 / 40 Heuristic:Determination Hope Success Behavior Description: In your reas...
work page 2024
-
[70]
All the given conditions are satisfied, and the context makes sense
Let’s verify: If she sold 48 in April and 24 in May (which is indeed half of 48), their sum is 72. All the given conditions are satisfied, and the context makes sense. The answer is correct. Can You Derive Result Differently Try to reach the same answer using another method or ap- proach or viewpoint. Comparing two ways helps confirm the answer and gives ...
-
[71]
Pappus First construct or create something that helps you explore the problem
By clearly naming each quantity, the solution pathway is visible and straightforward. Pappus First construct or create something that helps you explore the problem. Draw a figure, build an example, or add a new element that reveals how the parts are related. Think of problem solving as a process of invention — by con- structing and observing, you can ofte...
-
[72]
33 Table 7 – continued Heuristic Description Example Problems To Find And Prove Approach the problem in two stages. First, find what seems to be the right answer or pattern by exploring ex- amples, calculating, or testing possibilities. Then, once you have a likely result, prove it by explaining why it must be true in all cases, using logical reasoning or...
-
[73]
So, this possibility is inconsistent with the problem statement
But the problem says May’s sales were half of April’s, not double. So, this possibility is inconsistent with the problem statement. Therefore, May’s number must truly be half of April’s: 48 / 2 = 24. Adding April and May gives 48 + 24 = 72 clips. Redundant When analyzing the problem, check whether any part of the information or condition repeats, adds not...
-
[74]
Now, adding both months together, 48 plus 24 gives 72
At this point, I’m reminded, ’Measure twice, cut once.’ Before I add, let me double-check that math: half of 48 is indeed 24. Now, adding both months together, 48 plus 24 gives 72. Careful checking helps avoid mistakes, just like the proverb says. 36 Table 7 – continued Heuristic Description Example Working Backwards You must start from the goal itself. A...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.