Recognition: no theorem link
Causal Stories from Sensor Traces: Auditing Epistemic Overreach in LLM-Generated Personal Sensing Explanations
Pith reviewed 2026-05-12 00:49 UTC · model grok-4.3
The pith
LLMs frequently generate causal explanations for personal sensing anomalies that go beyond what the sensor data can support.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
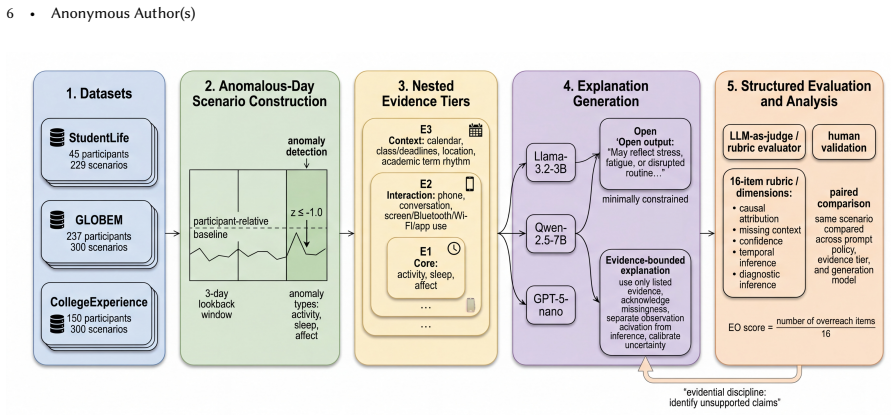
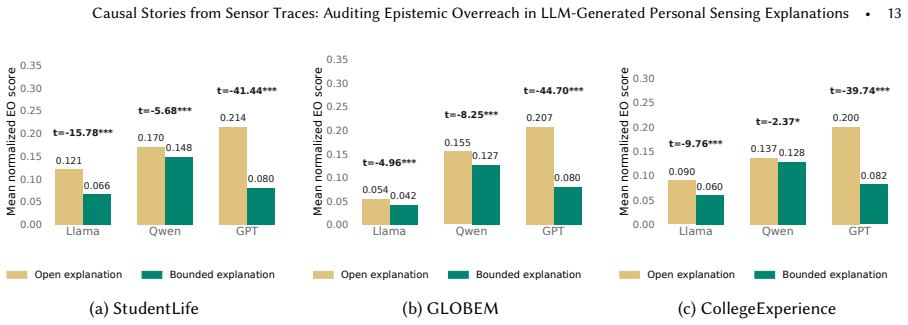
We introduce epistemic overreach (EO) as a measure for cases where a generated explanation implies more than the available sensing evidence can justify. To audit how often and in what forms EO occurs, we obtained anomalous-day scenarios from three longitudinal sensing datasets of college students. Across activity, sleep, and affect anomalies, we generated 14,922 explanations using three LLM families under two prompting conditions. We find that LLMs routinely attribute anomalous days to causes without sufficient support from the data, and that this pattern replicates across datasets, anomaly types, and model families. Further, providing richer context does not reliably reduce EO; bounded 0,0,
What carries the argument
Epistemic overreach, measured by a structured rubric that scores explanations on unsupported causal attribution, unacknowledged data gaps, overconfident language, temporal inconsistency, and diagnostic inference.
If this is right
- Evidential grounding should be a primary criterion for evaluating LLM-generated personal sensing explanations, alongside fluency and plausibility.
- Personal sensing explanation systems need to explicitly distinguish what is observed, what is inferred, and what remains unknown.
- The pattern of overreach holds across different anomaly types and data sources, suggesting it is a general property of current LLMs in this use case.
- Bounded prompting reduces but does not remove epistemic overreach, indicating a need for stronger controls or architectural changes.
Where Pith is reading between the lines
- Users of personal sensing apps that use LLMs for explanations may need warnings or alternative non-causal summaries to avoid overinterpreting their data.
- Similar audits could be applied to LLM use in other data-driven storytelling domains like financial reports or health diagnostics.
- Future models might incorporate explicit uncertainty tracking or retrieval from raw data to reduce overreach.
- Developers should test for EO before deploying LLM explainers in high-stakes personal data contexts.
Load-bearing premise
The structured rubric used to score epistemic overreach accurately reflects when explanations exceed the evidence, without major bias or inconsistency in how evaluators apply it.
What would settle it
A follow-up study that applies the same scenarios and models but uses a different set of human evaluators or an automated metric for overreach and finds substantially lower rates of unsupported attributions would challenge the finding that overreach is routine.
Figures


read the original abstract
LLMs are increasingly used to explain personal sensing data, translating traces of activity and mood into natural-language accounts of why an anomalous day may have occurred. However, such explanations can sound coherent and personally meaningful even when the underlying evidence is sparse or missing. We introduce epistemic overreach (EO) as a measure for cases where a generated explanation implies more than the available sensing evidence can justify. To audit how often and in what forms EO occurs, we obtained anomalous-day scenarios from three longitudinal sensing datasets of college students: StudentLife, GLOBEM, and CollegeExperience. Across activity, sleep, and affect anomalies, we generated 14,922 explanations using three LLM families -- Llama, Qwen, and GPT -- under two prompting conditions: one minimally constrained prompt and another prompt explicitly instructing models to bound claims to the data. For each scenario, we varied the amount of behavioral evidence available to the model to examine whether more evidence reduces EO. We evaluated each explanation using a structured rubric, decomposing EO into the dimensions of unsupported causal attribution, unacknowledged data gaps, overconfident language, temporal inconsistency, and diagnostic inference. We find that LLMs routinely attribute anomalous days to causes without sufficient support from the data, and that this pattern replicates across datasets, anomaly types, and model families. Further, providing richer context does not reliably reduce EO; bounded prompting helps but does not eliminate it. These findings suggest that evidential grounding should be a first-order evaluation criterion for LLM-generated personal sensing explanations, alongside fluency and plausibility. We argue that personal sensing explanations require evidential discipline: systems must distinguish what is observed, what is inferred, and what remains unknown.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces epistemic overreach (EO) as a measure of LLM-generated explanations for anomalous days in personal sensing data that imply more than the available sensor traces justify. Using three public longitudinal datasets (StudentLife, GLOBEM, CollegeExperience), it generates 14,922 explanations across activity, sleep, and affect anomalies with Llama, Qwen, and GPT models under minimal and bounded prompting conditions while varying available behavioral evidence. Each explanation is scored on a five-dimension rubric (unsupported causal attribution, unacknowledged data gaps, overconfident language, temporal inconsistency, diagnostic inference), yielding the finding that EO occurs routinely, replicates across datasets/models/anomaly types, richer context does not reliably reduce it, and bounded prompting helps but does not eliminate it.
Significance. If the results hold, the work is significant for establishing evidential grounding as a necessary evaluation criterion for LLM use in personal sensing applications. It earns credit for its large generation volume (14,922 explanations), use of three public longitudinal datasets, and decomposed rubric applied across multiple conditions and model families, which together provide solid empirical grounding for the replication claims.
major comments (2)
- [Evaluation section / Rubric description] Evaluation section / Rubric description: The paper applies a five-dimension rubric to score EO but reports no inter-rater reliability statistics, no validation against domain-expert gold labels, and no explicit operationalization of 'sufficient support from the data' for activity/sleep/affect anomalies. Because the central claims about routine EO and the effects of context/prompting rest entirely on these scores, the absence of reliability metrics is load-bearing.
- [Results on context variation] Results on context variation: The claim that 'providing richer context does not reliably reduce EO' depends on how the amount of behavioral evidence was varied in the prompts; without a precise description of the context levels (e.g., which sensor features were added or withheld) or controls for prompt length, it is difficult to isolate the effect of evidence volume from other prompt properties.
minor comments (2)
- [Abstract] Abstract: The statement that 'bounded prompting helps but does not eliminate it' would be clearer if it included the magnitude of the observed reduction (e.g., percentage-point change in EO rate) rather than a qualitative description.
- [Methods] Methods: The exact wording of the 'minimally constrained prompt' and the 'bounded prompt' should be provided verbatim in the main text or an appendix so readers can assess how the bounding instructions were phrased.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. The comments identify important areas for clarification and strengthening of the manuscript. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Evaluation section / Rubric description] The paper applies a five-dimension rubric to score EO but reports no inter-rater reliability statistics, no validation against domain-expert gold labels, and no explicit operationalization of 'sufficient support from the data' for activity/sleep/affect anomalies. Because the central claims about routine EO and the effects of context/prompting rest entirely on these scores, the absence of reliability metrics is load-bearing.
Authors: We agree that greater transparency around the rubric is warranted. The five dimensions were derived from the sensor traces available in the datasets, with 'sufficient support' operationalized as the presence of direct quantitative evidence (e.g., step-count deviation or location change for activity anomalies; sleep-duration or timing data for sleep anomalies; self-report affect scores for affect anomalies). Scoring was performed by the author team with consensus resolution of borderline cases. We did not collect external expert labels or compute inter-rater reliability statistics. In the revised manuscript we will (1) add an expanded Evaluation section that provides explicit operational definitions and one annotated scoring example per anomaly type, (2) include a table mapping each rubric dimension to the specific sensor features that constitute support, and (3) add a limitations paragraph noting the absence of external validation and IRR as a direction for subsequent work. These changes increase transparency without altering the core findings. revision: partial
-
Referee: [Results on context variation] The claim that 'providing richer context does not reliably reduce EO' depends on how the amount of behavioral evidence was varied in the prompts; without a precise description of the context levels (e.g., which sensor features were added or withheld) or controls for prompt length, it is difficult to isolate the effect of evidence volume from other prompt properties.
Authors: We appreciate the request for precision. Context was varied across three explicitly defined levels: minimal (anomaly flag and date only), aggregate (daily summary statistics such as total steps, sleep duration, and average affect), and full (time-series traces plus location and app-usage features). Structured prompt templates were used to keep token length comparable across conditions. In the revision we will insert a table that lists the exact sensor features supplied at each level, report mean and standard-deviation token counts per condition, and add a supplementary analysis confirming that prompt length does not explain the observed EO patterns. These additions will allow readers to isolate the contribution of evidence volume. revision: yes
Circularity Check
No circularity: purely empirical audit with no derivations or self-referential predictions
full rationale
The paper conducts an empirical audit of LLM-generated explanations for sensor data anomalies. It generates 14,922 explanations across datasets and models, then applies a human-defined rubric to score epistemic overreach dimensions. No equations, fitted parameters, uniqueness theorems, or predictive claims appear in the abstract or described methods. The central findings derive directly from the generated text evaluated against provided traces, with no step reducing by construction to prior inputs or self-citations. The rubric is an evaluation tool, not a derived result. This matches the default expectation of no significant circularity for non-mathematical empirical studies.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The structured rubric (unsupported causal attribution, unacknowledged data gaps, overconfident language, temporal inconsistency, diagnostic inference) reliably identifies explanations that exceed available sensing evidence.
invented entities (1)
-
epistemic overreach (EO)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ashraf Abdul, Jo Vermeulen, Danding Wang, Brian Y. Lim, and Mohan Kankanhalli. 2018. Trends and Trajectories for Explainable, Accountable and Intelligible Systems: An HCI Research Agenda. InProceedings of the 2018 CHI Conference on Human Factors in Computing Systems (CHI ’18). Association for Computing Machinery, New York, NY, USA, 1–18. https://doi.org/1...
-
[2]
Gregory D Abowd, Anind K Dey, Peter J Brown, Nigel Davies, Mark Smith, and Pete Steggles. 1999. Towards a better understanding of context and context-awareness. InInternational Symposium on Handheld and Ubiquitous Computing. Springer, 304–307
work page 1999
-
[3]
Daniel A. Adler, Vincent W.-S. Tseng, Gengmo Qi, Joseph Scarpa, Srijan Sen, and Tanzeem Choudhury. 2021. Identifying Mobile Sensing Indicators of Stress-Resilience.Proc. ACM Interact. Mob. Wearable Ubiquitous Technol.5, 2, Article 51 (2021). https://doi.org/10.1145/ 3463528
work page 2021
-
[4]
In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems
Saleema Amershi, Dan Weld, Mihaela Vorvoreanu, Adam Fourney, Besmira Nushi, Penny Collisson, Jina Suh, Shamsi Iqbal, Paul N. Bennett, Kori Inkpen, Jaime Teevan, Ruth Kikin-Gil, and Eric Horvitz. 2019. Guidelines for Human-AI Interaction. InProceedings of the 2019 CHI Conference on Human Factors in Computing Systems(Glasgow, Scotland, UK)(CHI ’19). Associa...
-
[5]
D’Mello, Munmun De Choudhury, Gregory D
Mehrab Bin Morshed, Koustuv Saha, Richard Li, Sidney K. D’Mello, Munmun De Choudhury, Gregory D. Abowd, and Thomas Plötz
-
[6]
Prediction of Mood Instability with Passive Sensing.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies3, 3 (2019)
work page 2019
-
[7]
Zana Buçinca, Maja Barbara Malaya, and Krzysztof Z Gajos. 2021. To trust or to think: Cognitive forcing functions can reduce overreliance on AI in AI-assisted decision-making.Proceedings of the ACM on Human-Computer Interaction5, CSCW1 (2021), 1–21
work page 2021
- [8]
-
[9]
Eun Kyoung Choe, Bongshin Lee, Haining Zhu, Nathalie Henry Riche, and Dominikus Baur. 2017. Understanding Self-Reflection: How People Reflect on Personal Data through Visual Data Exploration.Proceedings of the 11th EAI International Conference on Pervasive Computing Technologies for Healthcare(2017), 173–182. https://doi.org/10.1145/3154862.3154881
-
[10]
Shaan Chopra, Katherine Juarez, James Fogarty, and Sean A Munson. 2025. Engagements with Generative AI and Personal Health Informatics: Opportunities for Planning, Tracking, Reflecting, and Acting around Personal Health Data.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies9, 3 (2025), 1–33
work page 2025
-
[11]
Akshat Choube, Sohini Bhattacharya, Rahul Majethia, Jiachen Li, Vedant Das Swain, and Varun Mishra. 2025. Imputation Matters: A Deeper Look into an Overlooked Step in Longitudinal Health and Behavior Sensing Research.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies9, 4 (2025), 1–30
work page 2025
-
[12]
Akshat Choube, Ha Le, Jiachen Li, Kaixin Ji, Vedant Das Swain, and Varun Mishra. 2025. GLOSS: Group of LLMs for open-ended sensemaking of passive sensing data for health and wellbeing.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies9, 3 (2025), 1–32. Causal Stories from Sensor Traces: Auditing Epistemic Overreach in LLM-...
work page 2025
-
[13]
Zheng Chu, Jingchang Chen, Qianglon Chen, Weijiang Yu, Haotian Wang, Ming Liu, and Bing Qin. 2024. TimeBench: A Comprehensive Evaluation of Temporal Reasoning Abilities in Large Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 1197...
work page 2024
-
[14]
Justin Cosentino, Anastasiya Belyaeva, Xin Liu, Zhun Yang, Yun Liu, Shyam A Tailor, Tim Althoff, John B Hernandez, Yossi Matias, Greg Corrado, et al. 2024. Towards a Personal Health Large Language Model. InAdvancements In Medical Foundation Models: Explainability, Robustness, Security, and Beyond
work page 2024
-
[15]
Aykut Coşkun and Armağan Karahanoğlu. 2023. Data Sensemaking in Self-Tracking: Towards a New Generation of Self-Tracking Tools. International Journal of Human–Computer Interaction(2023). https://doi.org/10.1080/10447318.2022.2075637
-
[16]
In this online environment, we’re limited
Vedant Das Swain, Victor Chen, Shrija Mishra, Stephen M. Mattingly, Gregory D. Abowd, and Munmun De Choudhury. 2022. Semantic Gap in Predicting Mental Wellbeing through Passive Sensing. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems (CHI ’22). Association for Computing Machinery, New York, NY, USA, Article 374, 16 pages. ht...
-
[17]
Vedant Das Swain, Koustuv Saha, Hemang Rajvanshy, Anusha Sirigiri, Julie M. Gregg, Suwen Lin, Gonzalo J. Martinez, Stephen M. Mattingly, Shayan Mirjafari, Raghu Mulukutla, and et al. 2019. A Multisensor Person-Centered Approach to Understand the Role of Daily Activities in Job Performance with Organizational Personas.Proc. ACM IMWUT(2019)
work page 2019
-
[18]
Morris, Chun-Cheng Chang, Xuhai Xu, Xin Liu, Shwetak Patel, and Vikram Iyer
Zachary Englhardt, Chengqian Ma, Margaret E. Morris, Chun-Cheng Chang, Xuhai Xu, Xin Liu, Shwetak Patel, and Vikram Iyer. 2024. From Classification to Clinical Insights: Towards Analyzing and Reasoning About Mobile and Behavioral Health Data With Large Language Models.Proc. ACM Interact. Mob. Wearable Ubiquitous Technol.8, 2, Article 56 (2024). https://do...
-
[19]
Epstein, Monica Caraway, Chuck Johnston, An Ping, James Fogarty, and Sean A
Daniel A. Epstein, Monica Caraway, Chuck Johnston, An Ping, James Fogarty, and Sean A. Munson. 2016. Beyond Abandonment to Next Steps: Understanding and Designing for Life after Personal Informatics Tool Use. InProceedings of the 2016 CHI Conference on Human Factors in Computing Systems(San Jose, California, USA)(CHI ’16). Association for Computing Machin...
-
[20]
Daniel A. Epstein, An Ping, James Fogarty, and Sean A. Munson. 2015. A Lived Informatics Model of Personal Informatics. InProceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing(Osaka, Japan)(UbiComp ’15). Association for Computing Machinery, New York, NY, USA, 731–742. https://doi.org/10.1145/2750858.2804250
-
[21]
Alexander Richard Fabbri, Chien-Sheng Wu, Wenhao Liu, and Caiming Xiong. 2022. QAFactEval: Improved QA-based factual consistency evaluation for summarization. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2587–2601
work page 2022
-
[22]
Cathy Mengying Fang, Valdemar Danry, Nathan Whitmore, Andria Bao, Andrew Hutchison, Cayden Pierce, and Pattie Maes. 2024. PhysioLLM: Supporting Personalized Health Insights with Wearables and Large Language Models. In2024 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI). IEEE, 1–8. https://doi.org/10.1109/BHI62660.2024.10913781
-
[23]
Drishti Goel, Jeongah Lee, Qiuyue Joy Zhong, Violeta J Rodriguez, Daniel S Brown, Ravi Karkar, Dong Whi Yoo, and Koustuv Saha
- [24]
-
[25]
Miriam Greis, Jessica Hullman, Michael Correll, Matthew Kay, and Orit Shaer. 2017. Designing for Uncertainty in HCI: When Does Uncertainty Help?. InProceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems (CHI EA ’17). Association for Computing Machinery, New York, NY, USA, 593–600. https://doi.org/10.1145/3027063.3027091
-
[26]
Gabriella M. Harari, Sandrine S. Vaid, Sandrine R. Müller, Clemens Stachl, Zachary Marrero, Ramona Schoedel, Markus Bühner, and Samuel D. Gosling. 2020. Personality Sensing for Theory Development and Assessment in the Digital Age.European Journal of Personality34, 5, 649–669. https://doi.org/10.1002/per.2273
-
[27]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. 2025. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions.ACM Transactions on Information Systems43, 2, Article 43 (2025). https://doi.org/10.1145/3703155
-
[28]
Thomas R Insel. 2017. Digital phenotyping: technology for a new science of behavior.Jama318, 13 (2017), 1215–1216
work page 2017
- [29]
-
[30]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Wenliang Dai, Andrea Madotto, and Pascale Fung
-
[31]
Survey of Hallucination in Natural Language Generation.Comput. Surveys55, 12, Article 248 (2023). https://doi.org/10.1145/3571730
-
[32]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Harmanpreet Kaur, Daniel McDuff, Alex C Williams, Jaime Teevan, and Shamsi T Iqbal. 2022. “I Didn’t Know I Looked Angry”: Characterizing Observed Emotion and Reported Affect at Work. InCHI Conference on Human Factors in Computing Systems. 1–18. 22•Anonymous Author(s)
work page 2022
-
[34]
Harmanpreet Kaur, Harsha Nori, Samuel Jenkins, Rich Caruana, Hanna Wallach, and Jennifer Wortman Vaughan. 2020. Interpreting Interpretability: Understanding Data Scientists’ Use of Interpretability Tools for Machine Learning. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems (CHI ’20). Association for Computing Machinery, New ...
-
[35]
Mathew V Kiang, Jarvis T Chen, Nancy Krieger, Caroline O Buckee, Monica J Alexander, Justin T Baker, Randy L Buckner, Garth Coombs III, Janet W Rich-Edwards, Kenzie W Carlson, et al. 2021. Sociodemographic characteristics of missing data in digital phenotyping. Scientific Reports11, 1 (2021), 15408
work page 2021
- [36]
-
[37]
Yubin Kim, Xuhai Xu, Daniel McDuff, Cynthia Breazeal, and Hae Won Park. 2024. Health-LLM: Large Language Models for Health Prediction via Wearable Sensor Data. InProceedings of the 14th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics. Association for Computing Machinery. https://doi.org/10.1145/3698587.3701355
-
[38]
Klaus Krippendorff. 2019.Content Analysis. SAGE Publications, Inc. https://doi.org/10.4135/9781071878781
-
[39]
Ian Li, Anind Dey, and Jodi Forlizzi. 2010. A Stage-Based Model of Personal Informatics Systems. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems(Atlanta, Georgia, USA)(CHI ’10). Association for Computing Machinery, New York, NY, USA, 557–566. https://doi.org/10.1145/1753326.1753409
-
[40]
Ian Li, Anind K. Dey, and Jodi Forlizzi. 2011. Understanding My Data, Myself: Supporting Self-Reflection with Ubicomp Technologies. InProceedings of the 13th International Conference on Ubiquitous Computing(Beijing, China)(UbiComp ’11). Association for Computing Machinery, New York, NY, USA, 405–414. https://doi.org/10.1145/2030112.2030166
-
[41]
Junyi Li, Xiaoxue Cheng, Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. 2023. Halueval: A large-scale hallucination evaluation benchmark for large language models. InProceedings of the 2023 conference on empirical methods in natural language processing. 6449–6464
work page 2023
-
[42]
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al . 2022. Holistic Evaluation of Language Models.Transactions on Machine Learning Research. https: //arxiv.org/abs/2211.09110
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[43]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. TruthfulQA: Measuring How Models Mimic Human Falsehoods. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 3214–3252. https://doi.org/10.18653/v1/2022.acl-long.229
-
[44]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval: NLG Evaluation Using GPT-4 with Better Human Alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2511–2522. https://doi.org/10.18653/v1/2023.emnlp-main.153
-
[45]
Yuhan Luo, Xinning Gui, Xianghua Ding, Xi Zheng, Rie Helene Hernandez, Zhuoyang Li, and Qiurong Song. 2025. Reflecting Upon The Unintended Consequences of Personal Informatics Systems: A Systematic Review of Empirical Studies. InProceedings of the 2025 ACM Designing Interactive Systems Conference (DIS ’25). Association for Computing Machinery, New York, N...
-
[46]
Potsawee Manakul, Adian Liusie, and Mark Gales. 2023. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. InProceedings of the 2023 conference on empirical methods in natural language processing. 9004–9017
work page 2023
-
[47]
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. 2020. On Faithfulness and Factuality in Abstractive Summarization. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 1906–1919. https://doi.org/10.18653/v1/2020.acl-main.173
-
[48]
Lakmal Meegahapola, William Droz, Peter Kun, Amalia de Götzen, Chaitanya Nutakki, Shyam Diwakar, Salvador Ruiz Correa, Donglei Song, Hao Xu, Miriam Bidoglia, et al. 2023. Generalization and Personalization of Mobile Sensing-Based Mood Inference Models: An Analysis of College Students in Eight Countries.Proc. ACM Interact. Mob. Wearable Ubiquitous Technol....
-
[49]
Mike A. Merrill, Akshay Paruchuri, Naghmeh Rezaei, Geza Kovacs, Javier Perez, Jake Chan, Shyam Dash, Xin Liu, Daniel McDuff, and Tim Althoff. 2025. Transforming Wearable Data into Health Insights using Large Language Model Agents.Nature Communications16, Article 548 (2025). https://doi.org/10.1038/s41467-025-67922-y
-
[50]
Tim Miller. 2019. Explanation in artificial intelligence: Insights from the social sciences.Artificial intelligence267 (2019), 1–38
work page 2019
-
[51]
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long-Form Text Generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Ling...
-
[52]
Shayan Mirjafari, Kizito Masaba, Ted Grover, Weichen Wang, Pino Audia, Andrew T. Campbell, Nitesh V. Chawla, Vedant Das Swain, Munmun De Choudhury, Anind K. Dey, and et al. 2019. Differentiating Higher and Lower Job Performers in the Workplace Using Mobile Sensing.Proc. ACM IMWUT(2019). Causal Stories from Sensor Traces: Auditing Epistemic Overreach in LL...
work page 2019
-
[53]
David C. Mohr, Mi Zhang, and Stephen M. Schueller. 2017. Personal Sensing: Understanding Mental Health Using Ubiquitous Sensors and Machine Learning.Annual Review of Clinical Psychology13 (2017), 23–47. https://doi.org/10.1146/annurev-clinpsy-032816-044949
-
[54]
Huckins, Courtney Rogers, Meghan L
Subigya Nepal, Wenjun Liu, Arvind Pillai, Weichen Wang, Vlado Vojdanovski, Jeremy F. Huckins, Courtney Rogers, Meghan L. Meyer, and Andrew T. Campbell. 2024. Capturing the College Experience: A Four-Year Mobile Sensing Study of Mental Health, Resilience and Behavior of College Students during the Pandemic.Proceedings of the ACM on Interactive, Mobile, Wea...
-
[55]
Subigya Nepal, Arvind Pillai, William Campbell, Talie Massachi, Michael V Heinz, Ashmita Kunwar, Eunsol Soul Choi, Xuhai Xu, Joanna Kuc, Jeremy F Huckins, et al. 2024. MindScape study: integrating LLM and behavioral sensing for personalized AI-driven journaling experiences.Proceedings of the ACM on interactive, mobile, wearable and ubiquitous technologies...
work page 2024
-
[56]
Thomas Plötz. 2021. Applying Machine Learning for Sensor Data Analysis in Interactive Systems: Common Pitfalls of Pragmatic Use and Ways to Avoid Them.Comput. Surveys54, 6, Article 134 (2021), 25 pages. https://doi.org/10.1145/3459666
-
[57]
Mashfiqui Rabbi, Shahid Ali, Tanzeem Choudhury, and Ethan Berke. 2011. Passive and In-Situ Assessment of Mental and Physical Well-Being Using Mobile Sensors. InProceedings of the 13th International Conference on Ubiquitous Computing(Beijing, China)(UbiComp ’11). Association for Computing Machinery, New York, NY, USA, 385–394. https://doi.org/10.1145/20301...
-
[58]
John Rooksby, Mattias Rost, Alistair Morrison, and Matthew Chalmers. 2014. Personal Tracking As Lived Informatics. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems(Toronto, Ontario, Canada)(CHI ’14). ACM, New York, NY, USA, 1163–1172. https://doi.org/10.1145/2556288.2557039
-
[59]
Ognjen Rudovic, Jaeryoung Lee, Miles Dai, Björn Schuller, and Rosalind W Picard. 2018. Personalized machine learning for robot perception of affect and engagement in autism therapy.Science Robotics3, 19 (2018)
work page 2018
-
[60]
Daniel M Russell, Mark J Stefik, Peter Pirolli, and Stuart K Card. 1993. The cost structure of sensemaking. InProceedings of the INTERACT’93 and CHI’93 conference on Human factors in computing systems. 269–276
work page 1993
-
[61]
Koustuv Saha, Larry Chan, Kaya De Barbaro, Gregory D Abowd, and Munmun De Choudhury. 2017. Inferring mood instability on social media by leveraging ecological momentary assessments.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies1, 3 (2017), 95
work page 2017
-
[62]
Koustuv Saha and Munmun De Choudhury. 2017. Modeling stress with social media around incidents of gun violence on college campuses.PACM Human-Computer InteractionCSCW (2017)
work page 2017
-
[63]
Mattingly, Vedant Das swain, Pranshu Gupta, Gonzalo J
Koustuv Saha, Ted Grover, Stephen M. Mattingly, Vedant Das swain, Pranshu Gupta, Gonzalo J. Martinez, Pablo Robles-Granda, Gloria Mark, Aaron Striegel, and Munmun De Choudhury. 2021. Person-Centered Predictions of Psychological Constructs with Social Media Contextualized by Multimodal Sensing.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubi...
-
[64]
Reddy, Vedant das Swain, Julie M
Koustuv Saha, Manikanta D. Reddy, Vedant das Swain, Julie M. Gregg, Ted Grover, Suwen Lin, Gonzalo J. Martinez, Stephen M. Mattingly, Shayan Mirjafari, Raghu Mulukutla, Kari Nies, Pablo Robles-Granda, Anusha Sirigiri, Dong Whi Yoo, Pino Audia, Andrew T. Campbell, Nitesh V. Chawla, Sidney K. D’Mello, Anind K. Dey, Kaifeng Jiang, Qiang Liu, Gloria Mark, Edw...
-
[65]
2025.The Coding Manual for Qualitative Researchers
Johnny Saldaña. 2025.The Coding Manual for Qualitative Researchers. SAGE Publications Ltd. https://doi.org/10.4135/9781036235611
-
[66]
Wong, Yoko Akama, and Ann Light
Robert Soden, Laura Devendorf, Richmond Y. Wong, Yoko Akama, and Ann Light. 2022. Modes of Uncertainty in HCI.Foundations and Trends in Human–Computer Interaction15, 4 (2022), 317–426. https://doi.org/10.1561/1100000085
-
[67]
Konstantin R. Strömel, Stanislas Henry, Tim Johansson, Jasmin Niess, and Paweł W. Woźniak. 2024. Narrating Fitness: Leveraging Large Language Models for Reflective Fitness Tracker Data Interpretation. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, N...
-
[68]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. 2023. Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting. InAdvances in Neural Information Processing Systems (NeurIPS 2023, Vol. 36). Curran Associates, Inc. https://arxiv.org/abs/2305.04388
-
[69]
Boxin Wang, Weixin Chen, Hengzhi Pei, Chulin Xie, Mintong Kang, Chenhui Zhang, Chejian Xu, Zidi Xiong, Ritik Dutta, Rylan Schaeffer, et al. 2023. DecodingTrust: A Comprehensive Assessment of Trustworthiness in {GPT} Models.Neural Information Processing Systems Datasets; Benchmarks Track(2023)
work page 2023
-
[70]
Rui Wang, Min S. H. Aung, Saeed Abdullah, Rachel Brian, Andrew T. Campbell, Tanzeem Choudhury, Marta Hauser, John Kane, Michael Merrill, and Emily A. Scherer. 2016. CrossCheck: Toward Passive Sensing and Detection of Mental Health Changes in People with Schizophrenia. InProceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous...
-
[71]
Rui Wang, Fanglin Chen, Zhenyu Chen, Tianxing Li, Gabriella Harari, Stefanie Tignor, Xia Zhou, Dror Ben-Zeev, and Andrew T. Campbell. 2014. StudentLife: Assessing Mental Health, Academic Performance and Behavioral Trends of College Students Using Smartphones. InProceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computin...
-
[72]
Rui Wang, Weichen Wang, Alex da Silva, Jeremy F. Huckins, William M. Kelley, Todd F. Heatherton, and Andrew T. Campbell. 2018. Tracking Depression Dynamics in College Students Using Mobile Phone and Wearable Sensing.Proc. ACM Interact. Mob. Wearable Ubiquitous Technol.2, 1, Article 43 (2018). https://doi.org/10.1145/3191775
-
[73]
Weichen Wang, Gabriella M Harari, Rui Wang, Sandrine R Müller, Shayan Mirjafari, Kizito Masaba, and Andrew T Campbell. 2018. Sensing Behavioral Change over Time: Using Within-Person Variability Features from Mobile Sensing to Predict Personality Traits. IMWUT(2018)
work page 2018
-
[74]
Jerry Wei, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Jie Huang, Dustin Tran, Daiyi Peng, Ruibo Liu, Da Huang, et al. 2024. Long-form factuality in large language models.Advances in Neural Information Processing Systems37 (2024), 80756–80827
work page 2024
-
[75]
Xuhai Xu, Prerna Chikersal, Janine M. Dutcher, Yasaman S. Sefidgar, Woosuk Seo, Michael J. Tumminia, Daniella K. Villalba, Sheldon Cohen, Kasey G. Creswell, J. David Creswell, Jennifer Mankoff, Afsaneh Doryab, and Anind K. Dey. 2021. Leveraging Collaborative- Filtering for Personalized Behavior Modeling: A Case Study of Depression Detection Among College ...
-
[76]
Xuhai Xu, Xin Liu, Han Zhang, Weichen Wang, Subigya Nepal, Yasaman Sefidgar, Woosuk Seo, Kevin S. Kuehn, Jeremy F. Huckins, Margaret E. Morris, Paula S. Nurius, Eve A. Riskin, Shwetak Patel, Tim Althoff, Andrew Campbell, Anind K. Dey, and Jennifer Mankoff
-
[77]
GLOBEM: Cross-Dataset Generalization of Longitudinal Human Behavior Modeling.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies6, 4, Article 190 (Dec. 2023). https://doi.org/10.1145/3569485
-
[78]
Bufang Yang, Siyang Jiang, Lilin Xu, Kaiwei Liu, Hai Li, Guoliang Xing, Hao Chen, Xiaofan Jiang, and Zheng Yan. 2024. DrHouse: An LLM-Empowered Diagnostic Reasoning System through Harnessing Outcomes from Sensor Data and Expert Knowledge. InProceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, Vol. 8. Association for Computi...
-
[79]
Xiaofan Yu, Lanxiang Hu, Benjamin Reichman, Dylan Chu, Rushil Chandrupatla, Xiyuan Zhang, Larry Heck, and Tajana S Rosing. 2025. Sensorchat: Answering qualitative and quantitative questions during long-term multimodal sensor interactions.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies9, 3 (2025), 1–35
work page 2025
-
[80]
Yiran Zhao, Jinghan Zhang, I Chern, Siyang Gao, Pengfei Liu, Junxian He, et al. 2023. Felm: Benchmarking factuality evaluation of large language models.Advances in Neural Information Processing Systems36 (2023), 44502–44523
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.