Recognition: 2 theorem links
· Lean TheoremAHD Agent: Agentic Reinforcement Learning for Automatic Heuristic Design
Pith reviewed 2026-05-12 01:10 UTC · model grok-4.3
The pith
A 4B-parameter agent trained with agentic reinforcement learning matches or surpasses larger models in automatic heuristic design.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
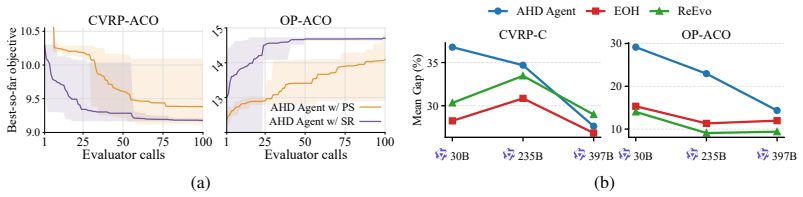
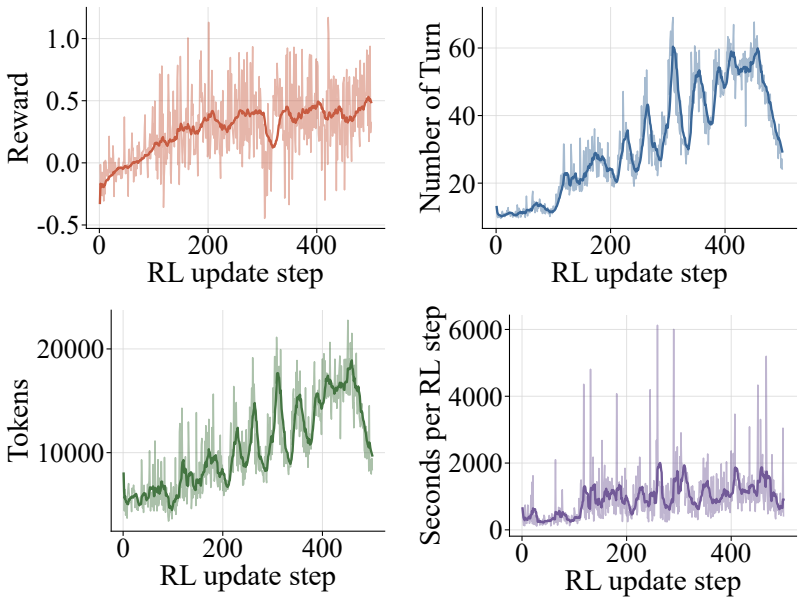
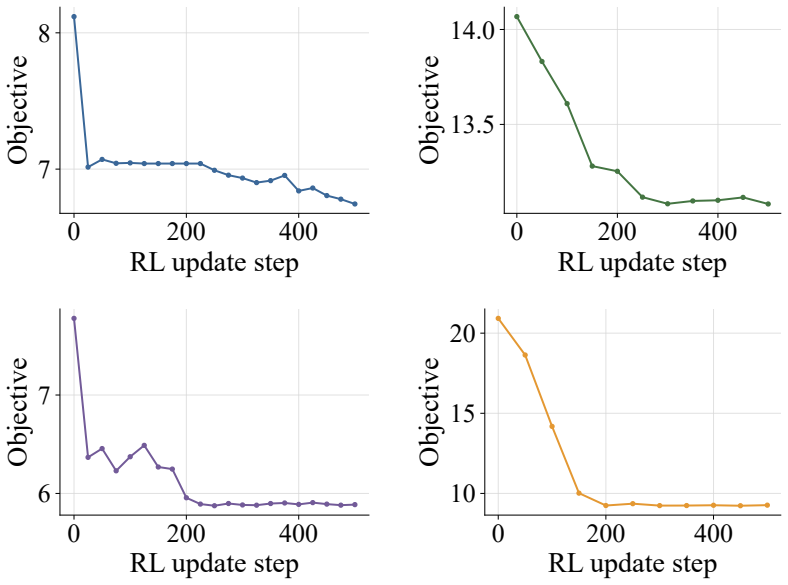
Framing automatic heuristic design as a multi-turn agentic process, where the model can choose at each step to generate a heuristic or invoke tools for targeted evidence, and then training the resulting policy with reinforcement learning on a novel environment synthesis pipeline, produces a 4B-parameter model whose performance matches or exceeds that of state-of-the-art baselines relying on substantially larger models while requiring significantly fewer evaluations on both training and held-out tasks.
What carries the argument
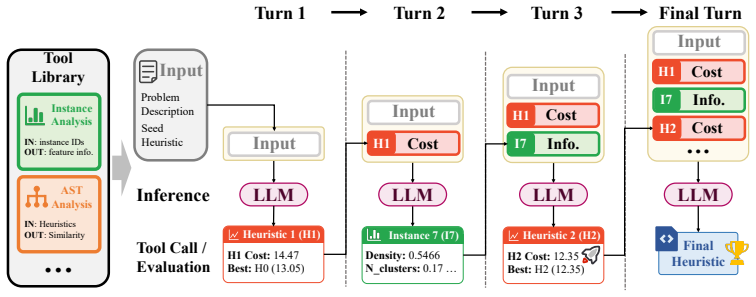
The AHD Agent: a tool-integrated multi-turn framework in which the language model proactively chooses between heuristic generation and tool invocation to retrieve state-dependent evidence.
If this is right
- Compact models become sufficient for competitive automatic heuristic design.
- Proactive tool use reduces the number of trials needed compared with passive generation.
- Performance extends to tasks absent from the reinforcement learning phase.
- The approach supplies a concrete trajectory toward fully autonomous heuristic discovery.
Where Pith is reading between the lines
- The same synthesis-plus-RL pattern could be tested for training agents in other domains that require adaptive tool selection.
- Lower evaluation counts may allow the method to scale to larger problem instances than current baselines can handle.
- If the decision policy proves robust, future versions could reduce reliance on hand-designed prompts in heuristic search systems.
Load-bearing premise
The environment synthesis pipeline generates training signals that produce decision-making skills transferable to optimization tasks the agent has not seen during reinforcement learning.
What would settle it
Showing that the 4B agent needs more evaluations or performs worse than larger baselines on a fresh collection of held-out combinatorial optimization tasks would falsify the claim of generalizable performance.
Figures






read the original abstract
Automatic heuristic design (AHD) has emerged as a promising paradigm for solving NP-hard combinatorial optimization problems (COPs). Recent works show that large language models (LLMs), when integrated into well-designed frameworks (i.e., LLM-AHD), can autonomously discover high-performing heuristics. However, existing LLM-AHD frameworks typically treat LLMs as passive generators within fixed workflows, where the model generates heuristics from manually designed, limited context. Such context may fail to capture state-dependent information (e.g., specific failure modes), leading to inefficient trial-and-error exploration. To overcome these limitations, we propose AHD Agent, a novel tool-integrated, multi-turn framework that empowers LLMs to proactively decide whether to generate heuristics or invoke tools to retrieve targeted evidence from the solving environment. To effectively train such a dynamic decision-making agent, we introduce an agentic reinforcement learning (RL) system, which leverages a novel environment synthesis pipeline to optimize a compact model's generalizable AHD capabilities. Experiments across eight diverse domains, including four held-out tasks, demonstrate that our 4B-parameter agent matches or surpasses state-of-the-art baselines using much larger models, while requiring significantly fewer evaluations. Model and inference scaling analysis further reveals that AHD Agent offers an effective trajectory toward truly autonomous heuristic design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AHD Agent, a tool-integrated multi-turn framework for automatic heuristic design (AHD) in NP-hard combinatorial optimization problems. LLMs are trained via agentic reinforcement learning on a novel environment synthesis pipeline to enable proactive decisions between generating heuristics and invoking tools for targeted evidence retrieval from the solving environment. The central claim is that the resulting 4B-parameter agent matches or surpasses state-of-the-art baselines (using much larger models) across eight diverse domains, including four held-out tasks, while requiring significantly fewer evaluations.
Significance. If the empirical results hold under rigorous scrutiny, the work could advance LLM-based AHD by moving beyond passive generation in fixed workflows to an active, tool-using agent trained with RL. The compact model size combined with reduced evaluations and apparent generalization to held-out tasks would indicate a practical path toward more efficient autonomous heuristic discovery. The environment synthesis pipeline for creating RL training signals is a potentially valuable technical contribution if it demonstrably supports out-of-distribution performance.
major comments (2)
- [Abstract] Abstract: The abstract asserts that the 4B-parameter agent 'matches or surpasses state-of-the-art baselines using much larger models, while requiring significantly fewer evaluations' across eight domains including four held-out tasks. However, it supplies no details on the baselines, metrics, number of independent runs, statistical tests, ablation studies, or experimental protocols. This prevents assessment of whether the data support the central performance claim.
- [Experiments section] Environment synthesis pipeline and held-out tasks (Experiments section): The generalizability claim to four held-out tasks is load-bearing and depends on the novel environment synthesis pipeline producing training signals that enable out-of-distribution AHD decision-making. The manuscript must provide explicit distribution-shift metrics or diversity controls demonstrating that synthesized environments differ structurally from the held-out set (e.g., in problem classes, constraint types, or instance distributions); absent this, the reported performance could reflect training-distribution overlap rather than the agentic multi-turn framework.
minor comments (1)
- [Abstract] The abstract uses 'significantly fewer evaluations' without any quantification or comparison numbers; adding approximate ratios or absolute figures would improve precision.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and have revised the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts that the 4B-parameter agent 'matches or surpasses state-of-the-art baselines using much larger models, while requiring significantly fewer evaluations' across eight domains including four held-out tasks. However, it supplies no details on the baselines, metrics, number of independent runs, statistical tests, ablation studies, or experimental protocols. This prevents assessment of whether the data support the central performance claim.
Authors: We agree that the abstract is high-level and omits specific experimental details due to length constraints. In the revised manuscript, we will expand the abstract to briefly name the primary baselines (including model sizes), the main metrics (solution quality and evaluation counts), and note that results are reported as averages over multiple independent runs with statistical tests detailed in the Experiments section. Full protocols, ablations, and significance results remain in the main text. This change directly addresses the concern while preserving abstract conciseness. revision: yes
-
Referee: [Experiments section] Environment synthesis pipeline and held-out tasks (Experiments section): The generalizability claim to four held-out tasks is load-bearing and depends on the novel environment synthesis pipeline producing training signals that enable out-of-distribution AHD decision-making. The manuscript must provide explicit distribution-shift metrics or diversity controls demonstrating that synthesized environments differ structurally from the held-out set (e.g., in problem classes, constraint types, or instance distributions); absent this, the reported performance could reflect training-distribution overlap rather than the agentic multi-turn framework.
Authors: We acknowledge the need for explicit evidence of distribution shift to support the held-out task claims. The environment synthesis pipeline (Section 3.2) generates training environments by varying problem parameters, constraint structures, and instance features across domains. In the revision, we add quantitative distribution-shift analyses, including comparisons of problem classes, constraint types, and instance distributions (via new tables and divergence metrics) between synthesized training data and the four held-out tasks. These demonstrate structural differences and reinforce that gains arise from the agentic RL framework. An ablation on the pipeline's role in generalization is also included. revision: yes
Circularity Check
No circularity: claims rest on empirical evaluation of a novel pipeline, not self-referential definitions or fits
full rationale
The paper presents an empirical method (AHD Agent) whose central claims are performance outcomes measured on eight domains including four held-out tasks. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or described methodology. The environment synthesis pipeline is introduced as an external innovation whose value is tested by downstream RL training and generalization metrics rather than being defined in terms of the target results. No load-bearing step reduces a prediction to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can learn effective dynamic decision policies for tool invocation versus generation through reinforcement learning on synthesized environments.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearAHD Agent treats the LLM as the decision-making agent in a multi-turn design process... GRPO... AHD environment synthesis pipeline
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearExperiments across eight diverse domains, including four held-out tasks
Reference graph
Works this paper leans on
-
[1]
Traveling salesman problem: an overview of ap- plications, formulations, and solution approaches,
R. Matai, S. P . Singh, and M. L. Mittal, “Traveling salesman problem: an overview of ap- plications, formulations, and solution approaches,” Traveling salesman problem, theory and applications, vol. 1, no. 1, pp. 1–25, 2010
work page 2010
-
[2]
Heuristic algorithm for scheduling in a flowshop to minimize total flowtime,
C. Rajendran, “Heuristic algorithm for scheduling in a flowshop to minimize total flowtime,” International Journal of Production Economics , vol. 29, no. 1, pp. 65–73, 1993
work page 1993
-
[3]
Heuristic and meta-heuristic algorithms and their relevance to the real world: a survey,
S. Desale, A. Rasool, S. Andhale, and P . Rane, “Heuristic and meta-heuristic algorithms and their relevance to the real world: a survey,” Int. J. Comput. Eng. Res. Trends , vol. 351, no. 5, pp. 2349–7084, 2015
work page 2015
-
[4]
A classification of hyper-heuristic approaches,
E. K. Burke, M. Hyde, G. Kendall, G. Ochoa, E. Özcan, and J. R. Woodward, “A classification of hyper-heuristic approaches,” in Handbook of metaheuristics. Springer, 2010, pp. 449–468
work page 2010
-
[5]
W. B. Langdon and R. Poli, F oundations of genetic programming. Springer, 2002, vol. 90
work page 2002
-
[6]
Explainable artificial intelligence by genetic programming: A survey,
Y . Mei, Q. Chen, A. Lensen, B. Xue, and M. Zhang, “Explainable artificial intelligence by genetic programming: A survey,” IEEE Transactions on Evolutionary Computation , vol. 27, no. 3, pp. 621–641, 2022
work page 2022
-
[7]
Mathematical discoveries from program search with large language models,
B. Romera-Paredes, M. Barekatain, A. Novikov, M. Balog, M. P . Kumar, E. Dupont, F. J. Ruiz, J. S. Ellenberg, P . Wang, O. Fawziet al., “Mathematical discoveries from program search with large language models,” Nature, vol. 625, no. 7995, pp. 468–475, 2024
work page 2024
-
[8]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
A. Novikov, N. V ˜u, M. Eisenberger, E. Dupont, P .-S. Huang, A. Z. Wagner, S. Shirobokov, B. Kozlovskii, F. J. Ruiz, A. Mehrabian et al., “Alphaevolve: A coding agent for scientific and algorithmic discovery,”arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Evolution of heuristics: Towards efficient automatic algorithm design using large language model,
F. Liu, X. Tong, M. Y uan, X. Lin, F. Luo, Z. Wang, Z. Lu, and Q. Zhang, “Evolution of heuristics: Towards efficient automatic algorithm design using large language model,” arXiv preprint arXiv:2401.02051, 2024
-
[10]
Reevo: Large language models as hyper-heuristics with reflective evolution,
H. Y e, J. Wang, Z. Cao, F. Berto, C. Hua, H. Kim, J. Park, and G. Song, “Reevo: Large language models as hyper-heuristics with reflective evolution,”Advances in neural information processing systems, vol. 37, pp. 43 571–43 608, 2024
work page 2024
-
[11]
Deepseek-v4: Towards highly efficient million-token context intelligence,
DeepSeek-AI, “Deepseek-v4: Towards highly efficient million-token context intelligence,” 2026
work page 2026
-
[12]
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Z. Wang, K. Wang, Q. Wang, P . Zhang, L. Li, Z. Y ang, K. Y u, M. N. Nguyen, L. Liu, E. Gottlieb et al. , “RAGEN: Understanding self-evolution in LLM agents via multi-turn reinforcement learning,” arXiv preprint arXiv:2504.20073, 2025
work page internal anchor Pith review arXiv 2025
-
[13]
Monte carlo tree search for comprehensive explo- ration in llm-based automatic heuristic design,
Z. Zheng, Z. Xie, Z. Wang, and B. Hooi, “Monte carlo tree search for comprehensive explo- ration in llm-based automatic heuristic design,” arXiv preprint arXiv:2501.08603, 2025
-
[14]
Eoh-s: Evolution of heuristic set using llms for automated heuristic design,
F. Liu, Y . Liu, Q. Zhang, T. Xialiang, and M. Y uan, “Eoh-s: Evolution of heuristic set using llms for automated heuristic design,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 43, 2026, pp. 37 090–37 098. 10
work page 2026
-
[15]
P . V . T. Dat, L. Doan, and H. T. T. Binh, “Hsevo: Elevating automatic heuristic design with diversity-driven harmony search and genetic algorithm using llms,” inProceedings of the AAAI Conference on Artificial Intelligence , vol. 39, no. 25, 2025, pp. 26 931–26 938
work page 2025
-
[16]
Generalizable heuristic generation through LLMs with meta-optimization,
Y . Shi, J. Zhou, W. Song, J. Bi, Y . Wu, Z. Cao, and J. Zhang, “Generalizable heuristic generation through LLMs with meta-optimization,” in The F ourteenth International Conference on Learning Representations , 2026. [Online]. Available: https://openreview.net/ forum?id=tIQZ7pVN6S
work page 2026
-
[17]
VRPAgent: LLM-driven discovery of heuristic operators for vehicle routing problems
A. Hottung, F. Berto, C. Hua, N. G. Zepeda, D. Wetzel, M. Römer, H. Y e, D. Zago, M. Poli, S. Massaroli et al., “Vrpagent: Llm-driven discovery of heuristic operators for vehicle routing problems,” arXiv preprint arXiv:2510.07073, 2025
-
[18]
R. Li, L. Wang, H. Sang, L. Y ao, and L. Pan, “Llm-assisted automatic memetic algorithm for lot-streaming hybrid job shop scheduling with variable sublots,” IEEE Transactions on Evolutionary Computation, 2025
work page 2025
-
[19]
Dhevo: Data-algorithm based heuristic evolution for generalizable milp solving,
Z. Zhang, S. Li, C. Li, F. Liu, M. Chen, K. Li, T. Zhong, B. An, and P . Liu, “Dhevo: Data-algorithm based heuristic evolution for generalizable milp solving,” arXiv preprint arXiv:2507.15615, 2025
-
[20]
Dasathco: Data-aware sat heuristics combinations optimization via large language models,
M. Chen and G. Li, “Dasathco: Data-aware sat heuristics combinations optimization via large language models,” arXiv preprint arXiv:2509.12602, 2025
-
[21]
Llm-driven instance-specific heuristic generation and selection,
S. Zhang, S. Liu, N. Lu, J. Wu, J. Liu, Y .-S. Ong, and K. Tang, “Llm-driven instance-specific heuristic generation and selection,” arXiv preprint arXiv:2506.00490, 2026
-
[22]
Algorithm discovery with LLMs: Evolutionary search meets reinforcement learning
A. Surina, A. Mansouri, L. Quaedvlieg, A. Seddas, M. Viazovska, E. Abbe, and C. Gulcehre, “Algorithm discovery with llms: Evolutionary search meets reinforcement learning,” arXiv preprint arXiv:2504.05108, 2025
-
[23]
Refining hybrid genetic search for CVRP via reinforcement learning-finetuned LLM,
R. Zhu, C. Zhang, and Z. Cao, “Refining hybrid genetic search for CVRP via reinforcement learning-finetuned LLM,” in The F ourteenth International Conference on Learning Representations, 2026. [Online]. Available: https://openreview.net/forum?id=aITKXFeivk
work page 2026
-
[24]
CALM: Co-evolution of algorithms and language model for automatic heuristic design,
Z. Huang, W. Wu, K. Wu, W.-B. Lee, and J. Wang, “CALM: Co-evolution of algorithms and language model for automatic heuristic design,” in The F ourteenth International Conference on Learning Representations , 2026. [Online]. Available: https: //openreview.net/forum?id=x6bG2Hoqdf
work page 2026
-
[25]
LLMOPT: learning to de- fine and solve general optimization problems from scratch,
C. Jiang, X. Shu, H. Qian, X. Lu, J. Zhou, A. Zhou, and Y . Y u, “LLMOPT: learning to de- fine and solve general optimization problems from scratch,” in Proceedings of the Thirteenth International Conference on Learning Representations (ICLR) , Singapore, Singapore, 2025
work page 2025
-
[26]
Large language models as evolutionary optimizers,
S. Liu, C. Chen, X. Qu, K. Tang, and Y .-S. Ong, “Large language models as evolutionary optimizers,” in 2024 IEEE Congress on Evolutionary Computation (CEC) . IEEE, 2024, pp. 1–8
work page 2024
-
[27]
K. Zhang, J. Li, G. Li, X. Shi, and Z. Jin, “CodeAgent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges,” in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2024, pp. 13 643–13 658
work page 2024
-
[28]
Y ou only look at screens: Multimodal chain-of-action agents,
Z. Zhang and A. Zhang, “Y ou only look at screens: Multimodal chain-of-action agents,” in Findings of the Association for Computational Linguistics ACL 2024 , 2024, pp. 3132–3149
work page 2024
-
[29]
The dawn of GUI agent: A preliminary case study with claude 3.5 computer use,
S. Hu, M. Ouyang, D. Gao, and M. Z. Shou, “The dawn of GUI agent: A preliminary case study with claude 3.5 computer use,” arXiv preprint arXiv:2411.10323, 2024
-
[30]
V oyager: An open-ended embodied agent with large language models,
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar, “V oyager: An open-ended embodied agent with large language models,” Transactions on Machine Learning Research , 2024. [Online]. Available: https://openreview.net/forum?id=ehfRiF0R3a 11
work page 2024
-
[31]
RT-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Y u, S. Xu, P . Xu, T. Xiao, F. Xia, J. Wu, P . Wohlhart, S. Welker, A. Wahid et al. , “RT-2: Vision-language-action models transfer web knowledge to robotic control,” in Conference on Robot Learning . PMLR, 2023, pp. 2165–2183
work page 2023
-
[32]
ReAct: Synergizing reasoning and acting in language models,
S. Y ao, J. Zhao, D. Y u, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” in The Eleventh International Conference on Learning Representations , 2023. [Online]. Available: https: //openreview.net/forum?id=WE_vluYUL-X
work page 2023
-
[33]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Y ao, “Reflexion: Language agents with verbal reinforcement learning,” Advances in Neural Information Processing Systems , vol. 36, 2024
work page 2024
-
[34]
J. Wang, H. Xu, H. Jia, X. Zhang, M. Y an, W. Shen, J. Zhang, F. Huang, and J. Sang, “Mobile- Agent-v2: Mobile device operation assistant with effective navigation via multi-agent collabo- ration,” Advances in Neural Information Processing Systems , vol. 37, pp. 2686–2710, 2024
work page 2024
-
[35]
Cradle: Empowering foundation agents towards general computer control,
W. Tan, W. Zhang, X. Xu, H. Xia, G. Ding, B. Li, B. Zhou, J. Y ue, J. Jiang, Y . Liet al., “Cradle: Empowering foundation agents towards general computer control,” inNeurIPS 2024 Workshop on Open-World Agents, 2024
work page 2024
-
[36]
Large language models can be guided to evade ai-generated text detection,
N. Lu, S. Liu, R. He, Y . Ong, Q. Wang, and K. Tang, “Large language models can be guided to evade ai-generated text detection,” TMLR, 2024
work page 2024
-
[37]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Y u, R. Dessì, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” Advances in Neural Information Processing Systems , vol. 36, pp. 68 539–68 551, 2023
work page 2023
-
[38]
OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments,
T. Xie, D. Zhang, J. Chen, X. Li, S. Zhao, R. Cao, T. J. Hua, Z. Cheng, D. Shin, F. Lei, Y . Liu, Y . Xu, S. Zhou, S. Savarese, C. Xiong, V . Zhong, and T. Y u, “OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments,” in The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , 2024
work page 2024
-
[39]
Why Agents Compromise Safety Under Pressure
H. Jiang and K. Tang, “Why agents compromise safety under pressure,” arXiv preprint arXiv:2603.14975, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
B. Jin, H. Zeng, Z. Y ue, J. Y oon, S. Arik, D. Wang, H. Zamani, and J. Han, “Search-r1: Train- ing llms to reason and leverage search engines with reinforcement learning,” arXiv preprint arXiv:2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Kevin: Multi-turn RL for generating CUDA kernels,
C. Baronio, P . Marsella, B. Pan, S. Guo, and S. Alberti, “Kevin: Multi-turn RL for generating CUDA kernels,” in The F ourteenth International Conference on Learning Representations , 2026
work page 2026
-
[42]
Is PRM necessary? problem-solving RL implicitly induces PRM capability in LLMs,
Z. Feng, Q. Chen, N. Lu, Y . Li, S. Cheng, S. Peng, D. Tang, S. Liu, and Z. Zhang, “Is PRM necessary? problem-solving RL implicitly induces PRM capability in LLMs,” in NeurIPS, 2025
work page 2025
-
[43]
J. Wu, N. Lu, S. Liu, K. Wang, Y . Y ang, L. Qing, and K. Tang, “Train at moving edge: Online- verified prompt selection for efficient rl training of large reasoning model,” arXiv preprint arXiv:2603.25184, 2026
-
[44]
Reasoning-aligned perception decoupling for scalable multi-modal reasoning,
Y . Gou, K. Chen, Z. Liu, L. HONG, X. Jin, Z. Li, J. Kwok, and Y . Zhang, “Reasoning-aligned perception decoupling for scalable multi-modal reasoning,” in The F ourteenth International Conference on Learning Representations, 2026
work page 2026
-
[45]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P . Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimiza- tion algorithms,” arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Mastering the game of go without human knowledge,
D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton et al. , “Mastering the game of go without human knowledge,” Nature, vol. 550, no. 7676, pp. 354–359, 2017. 12
work page 2017
-
[47]
Buy 4 reinforce samples, get a baseline for free!
W. Kool, H. van Hoof, and M. Welling, “Buy 4 reinforce samples, get a baseline for free!” in ICLR 2019 Workshop, 2019
work page 2019
-
[48]
The traveling salesman problem: a guided tour of combinatorial optimization,
E. L. Lawler, “The traveling salesman problem: a guided tour of combinatorial optimization,” Wiley-Interscience Series in Discrete Mathematics, 1985
work page 1985
-
[49]
Llm4ad: A platform for algorithm design with large language model
F. Liu, R. Zhang, Z. Xie, R. Sun, K. Li, Q. Hu, P . Guo, X. Lin, X. Tong, M. Y uan et al., “Llm4ad: A platform for algorithm design with large language model,” arXiv preprint arXiv:2412.17287, 2024
-
[50]
M. Dorigo, M. Birattari, and T. Stutzle, “Ant colony optimization,” IEEE computational intel- ligence magazine, vol. 1, no. 4, pp. 28–39, 2006
work page 2006
-
[51]
Evolve cost-aware acquisition functions using large language models,
Y . Y ao, F. Liu, J. Cheng, and Q. Zhang, “Evolve cost-aware acquisition functions using large language models,” in International Conference on Parallel Problem Solving from Nature. Springer, 2024, pp. 374–390
work page 2024
-
[52]
An analysis of several heuristics for the traveling salesman problem,
D. J. Rosenkrantz, R. E. Stearns, and P . M. Lewis, II, “An analysis of several heuristics for the traveling salesman problem,” SIAM journal on computing , vol. 6, no. 3, pp. 563–581, 1977
work page 1977
-
[53]
Improving ant colony optimization efficiency for solving large tsp in- stances,
R. Skinderowicz, “Improving ant colony optimization efficiency for solving large tsp in- stances,” Applied Soft Computing, vol. 120, p. 108653, 2022
work page 2022
-
[54]
A dynamic space reduction ant colony optimization for capacitated vehicle routing problem,
J. Cai, P . Wang, S. Sun, and H. Dong, “A dynamic space reduction ant colony optimization for capacitated vehicle routing problem,” Soft Computing, vol. 26, no. 17, pp. 8745–8756, 2022
work page 2022
-
[55]
Acs-ophs: Ant colony system for the orienteering problem with hotel selection,
S. Sohrabi, K. Ziarati, and M. Keshtkaran, “Acs-ophs: Ant colony system for the orienteering problem with hotel selection,” EURO Journal on Transportation and Logistics , vol. 10, p. 100036, 2021
work page 2021
-
[56]
Hybrid ant colony optimization algorithm for multiple knapsack problem,
S. Fidanova, “Hybrid ant colony optimization algorithm for multiple knapsack problem,” in 2020 5th IEEE International Conference on Recent Advances and Innovations in Engineering (ICRAIE). IEEE, 2020, pp. 1–5
work page 2020
-
[57]
A. Hurst, A. Lerer, A. P . Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford et al., “Gpt-4o system card,” arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Q. Team, “Qwen3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2505. 09388
work page 2025
-
[59]
Taking the human out of the loop: A review of bayesian optimization,
B. Shahriari, K. Swersky, Z. Wang, R. P . Adams, and N. De Freitas, “Taking the human out of the loop: A review of bayesian optimization,” Proceedings of the IEEE , vol. 104, no. 1, pp. 148–175, 2015
work page 2015
-
[60]
On bayesian methods for seeking the extremum,
J. Mo ˇckus, “On bayesian methods for seeking the extremum,” in IFIP Technical Conference on Optimization Techniques. Springer, 1974, pp. 400–404
work page 1974
-
[61]
Practical bayesian optimization of machine learning algorithms,
J. Snoek, H. Larochelle, and R. P . Adams, “Practical bayesian optimization of machine learning algorithms,” Advances in neural information processing systems , vol. 25, 2012
work page 2012
-
[62]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P . Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu et al. , “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
K. Helsgaun, “An extension of the lin-kernighan-helsgaun tsp solver for constrained traveling salesman and vehicle routing problems,” Roskilde: Roskilde University , vol. 12, pp. 966–980, 2017
work page 2017
-
[64]
Pyvrp: A high-performance vrp solver package,
N. A. Wouda, L. Lan, and W. Kool, “Pyvrp: A high-performance vrp solver package,” IN- FORMS Journal on Computing , vol. 36, no. 4, pp. 943–955, 2024
work page 2024
-
[65]
A revisited branch-and-cut algorithm for large-scale orienteering problems,
G. Kobeaga, J. Rojas-Delgado, M. Merino, and J. A. Lozano, “A revisited branch-and-cut algorithm for large-scale orienteering problems,” European Journal of Operational Research , vol. 313, no. 1, pp. 44–68, 2024
work page 2024
-
[66]
L. Perron and V . Furnon, “Or-tools,” Google. [Online]. Available: https://developers.google. com/optimization/ 13 A Details of Problem Domains A.1 Problem Domain Definitions We evaluate on eight problem domains spanning combinatorial and continuous optimization. Each subsection below states the mathematical formulation, the training/validation instance si...
-
[67]
InstanceAnalysis: summarize structural properties of the training instances, such as spacing, clustering, density, boundary statistics, and task-specific attributes when available
-
[68]
Optimal” and “Baseline heuristic
ASTNoveltyAnalyzer: compare the AST structure of a candidate against previously evaluated candidates. This interface is used only as a novelty checkpoint; final ranking is always deter- mined by train evaluation. Interaction rules. Use diagnostic feedback and train evaluation results to revise the code over multiple turns. Do not submit the initial code un...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.