Recognition: 2 theorem links
· Lean TheoremEvoMAS: Learning Execution-Time Workflows for Multi-Agent Systems
Pith reviewed 2026-05-12 02:25 UTC · model grok-4.3
The pith
EvoMAS learns to adapt multi-agent LLM workflows stage by stage during execution instead of fixing them upfront.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
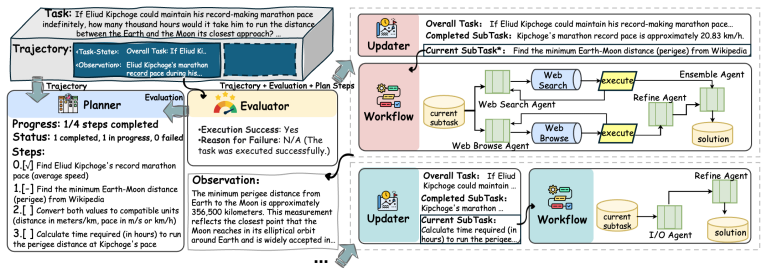
EvoMAS formulates multi-agent workflow construction as a meta-level sequential decision problem along a single task trajectory. At each execution stage it constructs an explicit task state through the Planner-Evaluator-Updater pipeline and uses a learned Workflow Adapter to instantiate a stage-specific layered workflow drawn from a fixed pool of candidate agents; the adapter is trained via policy gradients whose main signal is sparse terminal task success.
What carries the argument
The Workflow Adapter: a policy trained on terminal success that maps the current explicit task state to a stage-specific selection and layering of agents from a fixed candidate pool.
If this is right
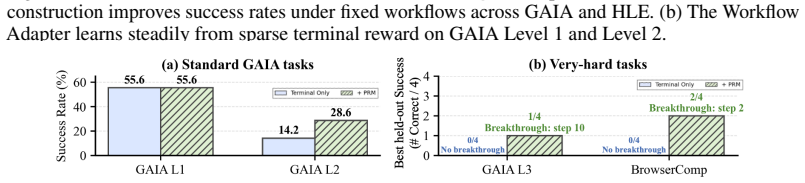
- Explicit task-state construction and learned workflow adaptation deliver complementary performance gains on the tested benchmarks.
- Process rewards provide the largest benefit precisely when terminal success signals are extremely sparse.
- The system changes its agent coordination patterns as the task state evolves, rather than reusing one structure throughout.
- The approach outperforms both single-agent baselines and existing automated multi-agent workflow design methods on GAIA, HLE, and DeepResearcher.
Where Pith is reading between the lines
- If the fixed agent pool is rich enough, this style of online adaptation could reduce the need for hand-engineering separate workflows for each new domain.
- The same meta-decision framing might apply to other sequential agent systems whose optimal structure shifts unpredictably midway through a task.
- When terminal rewards are dense, the extra machinery of process rewards may be unnecessary.
Load-bearing premise
That training an adapter on sparse terminal success alone, using only a fixed pool of candidate agents, is enough to produce useful stage-specific workflows that generalize to new long-horizon tasks.
What would settle it
A set of new long-horizon tasks in which EvoMAS’s stage-by-stage adapted workflows achieve no higher success rate than a single static workflow chosen once at the start of each task.
Figures





read the original abstract
Large language model (LLM)-based multi-agent systems have shown strong potential on complex tasks through agent specialization, tool use, and collaborative reasoning. However, most automated multi-agent system design methods still follow a one-shot paradigm: a workflow is optimized or selected before execution and then reused unchanged throughout the task. This static coordination strategy is ill-suited for long-horizon tasks whose subgoals, intermediate evidence, and information needs evolve over multiple execution stages. We propose EvoMAS, a framework for execution-time multi-agent workflow construction. EvoMAS formulates workflow construction as a meta-level sequential decision problem along a single task trajectory. At each stage, it constructs an explicit task state through a Planner-Evaluator-Updater pipeline and uses a learned Workflow Adapter to instantiate a stage-specific layered workflow from a fixed pool of candidate agents. The adapter is trained with policy gradients using sparse, verifiable terminal task success as the main supervision signal, while evaluator-based process reward is analyzed separately under very-hard sparse-reward settings. Experiments on GAIA, HLE, and DeepResearcher show that EvoMAS outperforms single-agent baselines and recent automated multi-agent workflow design methods. Our analyses further show that explicit task-state construction and learned workflow adaptation provide complementary benefits. Additional results indicate that process reward is most useful when terminal success is extremely sparse, and qualitative case studies illustrate that EvoMAS adapts agent coordination as the task state evolves.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EvoMAS, a framework for execution-time multi-agent workflow construction in LLM-based systems. It models workflow adaptation as a meta-level sequential decision process along a single task trajectory, using a Planner-Evaluator-Updater pipeline to construct explicit task states and a learned Workflow Adapter to instantiate stage-specific layered workflows from a fixed pool of candidate agents. The adapter is trained via policy gradients with sparse, verifiable terminal task success as the primary supervision signal. Experiments on the GAIA, HLE, and DeepResearcher benchmarks report that EvoMAS outperforms single-agent baselines and recent automated multi-agent workflow design methods, with additional analyses indicating complementary benefits from explicit task-state construction and learned adaptation, plus utility of process rewards under extremely sparse terminal success.
Significance. If the experimental claims hold under rigorous validation, this work would be significant for shifting multi-agent system design from static, one-shot workflows to dynamic, execution-time adaptation. The RL-based approach to learning stage-specific coordination from sparse terminal rewards, combined with the explicit state construction pipeline, addresses a clear limitation in handling long-horizon tasks with evolving subgoals. The reported complementary benefits between state construction and adaptation provide a concrete, testable insight that could guide future agent system architectures.
major comments (2)
- [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): The central claim of outperformance on GAIA, HLE, and DeepResearcher rests on reported gains without any quantitative metrics, error bars, ablation studies, or details on stabilization of the sparse-reward policy-gradient training. This absence prevents assessment of statistical reliability, effect sizes, or whether gains reduce to overfitting on the training distribution rather than true generalization to new long-horizon tasks.
- [§3 (Method)] §3 (Method): The weakest assumption—that a fixed pool of candidate agents plus a learned adapter trained only on terminal success can produce effective, generalizable stage-specific workflows—requires explicit discussion of how the pool is constructed, the risk of distribution shift, and any controls for overfitting. Without these, the complementary-benefit claim cannot be isolated from potential confounds in the experimental setup.
minor comments (2)
- [Figures and Tables] Ensure all figures include error bars or confidence intervals and that ablation tables clearly label the contribution of each component (state construction vs. adaptation).
- [§3 (Method)] Clarify notation for the Workflow Adapter and Planner-Evaluator-Updater pipeline to avoid ambiguity when describing the sequential decision process.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to strengthen the presentation of results and methodological details.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): The central claim of outperformance on GAIA, HLE, and DeepResearcher rests on reported gains without any quantitative metrics, error bars, ablation studies, or details on stabilization of the sparse-reward policy-gradient training. This absence prevents assessment of statistical reliability, effect sizes, or whether gains reduce to overfitting on the training distribution rather than true generalization to new long-horizon tasks.
Authors: We agree that the original submission did not provide sufficient quantitative detail to allow full assessment of the claims. In the revised manuscript, §4 now includes tables with exact success rates on each benchmark, standard errors computed over five independent runs, and expanded ablation studies that isolate the contributions of task-state construction versus learned adaptation. We have also added an appendix subsection on the policy-gradient procedure, including learning curves, variance-reduction methods (advantage normalization and baseline subtraction), and convergence diagnostics under sparse terminal rewards. These changes enable evaluation of effect sizes, statistical reliability, and generalization beyond the training distribution. revision: yes
-
Referee: [§3 (Method)] §3 (Method): The weakest assumption—that a fixed pool of candidate agents plus a learned adapter trained only on terminal success can produce effective, generalizable stage-specific workflows—requires explicit discussion of how the pool is constructed, the risk of distribution shift, and any controls for overfitting. Without these, the complementary-benefit claim cannot be isolated from potential confounds in the experimental setup.
Authors: We accept that the original §3 provided insufficient detail on pool construction and generalization safeguards. The revised §3.1 now explicitly describes the fixed pool as eight specialized agents whose capabilities (information retrieval, code execution, multi-step reasoning, etc.) are drawn from established tool-use literature. We discuss distribution-shift risks by noting that the adapter is trained on a broad task distribution and evaluated on completely disjoint benchmarks. Additional controls have been added, including training on a random subset of tasks and testing on the remainder, together with the existing ablations that separately disable state construction or adaptation. These revisions allow the complementary-benefit claim to be more cleanly isolated from setup confounds. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical RL-based training loop for a Workflow Adapter, using policy gradients supervised by external, verifiable terminal task success on benchmarks such as GAIA. The central claims rest on experimental outperformance and complementary benefits between explicit task-state construction and learned adaptation, without any derivation step that reduces a reported prediction or result to its own fitted inputs or self-referential definitions by construction. No load-bearing self-citation chains or ansatz smuggling appear in the provided description of the method.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EvoMAS formulates workflow construction as a meta-level sequential decision problem... uses a learned Workflow Adapter... trained with policy gradients using sparse, verifiable terminal task success
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The adapter is trained with policy gradients using sparse, verifiable terminal task success as the main supervision signal
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Automated multi-agent workflows for rtl design.arXiv preprint arXiv:2509.20182, 2025
Amulya Bhattaram, Janani Ramamoorthy, Ranit Gupta, Diana Marculescu, and Dimitrios Stamoulis. Automated multi-agent workflows for rtl design.arXiv preprint arXiv:2509.20182, 2025
-
[2]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors in agents, 2023
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chen Qian, Chi-Min Chan, Yujia Qin, Yaxi Lu, Ruobing Xie, Zhiyuan Liu, Maosong Sun, and Jie Zhou. Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors in agents, 2023
work page 2023
-
[4]
Multi-agent collaboration via evolving orchestration
Yufan Dang, Chen Qian, Xueheng Luo, Jingru Fan, Zihao Xie, Ruijie Shi, Weize Chen, Cheng Yang, Xiaoyin Che, Ye Tian, Xuantang Xiong, Lei Han, Zhiyuan Liu, and Maosong Sun. Multi-agent collaboration via evolving orchestration. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id= L0xZPXT3le
work page 2025
-
[5]
Mind2web: Towards a generalist agent for the web
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2023
work page 2023
-
[6]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate.CoRR, abs/2305.14325, 2023
work page internal anchor Pith review arXiv 2023
-
[7]
Promptbreeder: Self-referential self-improvement via prompt evolution,
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rock- täschel. Promptbreeder: Self-referential self-improvement via prompt evolution.arXiv preprint arXiv:2309.16797, 2023
-
[8]
Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, and Yujiu Yang. Connecting large language models with evolutionary algorithms yields powerful prompt optimizers.arXiv preprint arXiv:2309.08532, 2023
-
[9]
Metagpt: Meta programming for a multi-agent collaborative framework, 2024
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. Metagpt: Meta programming for a multi-agent collaborative framework, 2024
work page 2024
-
[10]
arXiv preprint arXiv:2410.16946 , year=
Yue Hu, Yuzhu Cai, Yaxin Du, Xinyu Zhu, Xiangrui Liu, Zijie Yu, Yuchen Hou, Shuo Tang, and Siheng Chen. Self-evolving multi-agent collaboration networks for software development. arXiv preprint arXiv:2410.16946, 2024
-
[11]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T Joshi, Hanna Moazam, et al. Dspy: Compiling declarative language model calls into self-improving pipelines.arXiv preprint arXiv:2310.03714, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang (Shane) Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[13]
CAMEL: communicative agents for "mind" exploration of large language model society
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: communicative agents for "mind" exploration of large language model society. InNeurIPS, 2023
work page 2023
-
[14]
API-bank: A comprehensive benchmark for tool-augmented LLMs
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. API-bank: A comprehensive benchmark for tool-augmented LLMs. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3102–3116, Singapore, December
work page 2023
-
[15]
API-Bank : A comprehensive benchmark for tool-augmented LLMs
Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.187. URLhttps://aclanthology.org/2023.emnlp-main.187/. 10
-
[16]
GAIA: a benchmark for General AI Assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants.arXiv preprint arXiv:2311.12983, 2023
work page internal anchor Pith review arXiv 2023
-
[17]
Babyagi.https://github.com/yoheinakajima/babyagi, 2023
Yohei Nakajima. Babyagi.https://github.com/yoheinakajima/babyagi, 2023
work page 2023
-
[18]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Anya Hilgard, Suchir Krishna, Miles Song, Nathan Lambert, Ryan Carroll, John Liu, Niharika Madhusudhan, Daniel Bishop, Yujia Weng, Eric Zelikman, Maxwell Nye, Long Ouyang Zhou, Jong Huang, Claire Kure, and John Schulman. WebGPT: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [19]
-
[20]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez. Memgpt: Towards llms as operating systems.arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive APIs.arXiv preprint arXiv:2305.15334, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Long Phan et al. Humanity’s last exam.arXiv preprint arXiv:2501.14249, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 16000+ real-world APIs.arXiv preprint arXiv:2307.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Auto-gpt: An autonomous gpt-4 experiment
Toran Bruce Richards and et al. Auto-gpt: An autonomous gpt-4 experiment. https:// github.com/Significant-Gravitas/Auto-GPT, 2023
work page 2023
-
[25]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36, 2023
work page 2023
-
[26]
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems, 36, 2023
work page 2023
-
[27]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Beck Labash, and Ashwin Gopinath. Reflexion: an autonomous agent with dynamic memory and self-reflection.arXiv preprint, abs/2303.11366, 2023. doi: 10.48550/ arXiv.2303.11366. URLhttps://doi.org/10.48550/arXiv.2303.11366
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.11366 2023
-
[28]
Yifan Song, Weimin Xiong, Dawei Zhu, Wenhao Wu, Han Qian, Mingbo Song, Hailiang Huang, Cheng Li, Ke Wang, Rong Yao, Ye Tian, and Sujian Li. RESTGPT: Connecting large language models with real-world applications via RESTful APIs.arXiv preprint arXiv:2306.06624, 2023
-
[29]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An Open-Ended Embodied Agent with Large Language Models.arXiv e-prints, art. arXiv:2305.16291, May 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
A Survey on Large Language Model based Autonomous Agents
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Ji-Rong Wen. A survey on large language model based autonomous agents.arXiv preprint arXiv:2308.11432, 2023
work page internal anchor Pith review arXiv 2023
-
[31]
Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Jiakai Tang, Xu Chen, Wayne Xin Zhao, and Ji-Rong Wen. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), 2023
work page 2023
-
[32]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isabella Ful- ford, Hyung Won Chung, Alexandre Tachard Passos, William Fedus, and Amelia Glaese. BrowseComp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516, 2025. URLhttps://arxiv.org/abs/2504.12516. 11
work page internal anchor Pith review arXiv 2025
-
[33]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. Autogen: Enabling next-gen llm applications via multi-agent conversation framework, August 01, 2023 2023
work page 2023
-
[34]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models, May 01, 2023 2023
work page 2023
-
[35]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[36]
Evoagent: Towards automatic multi-agent generation via evolutionary algorithms
Siyu Yuan, Kaitao Song, Jiangjie Chen, Xu Tan, Dongsheng Li, and Deqing Yang. Evoa- gent: Towards automatic multi-agent generation via evolutionary algorithms.arXiv preprint arXiv:2406.14228, 2024
-
[37]
Guibin Zhang, Yanwei Yue, Xiangguo Sun, Guancheng Wan, Miao Yu, Junfeng Fang, Kun Wang, Tianlong Chen, and Dawei Cheng. G-designer: Architecting multi-agent communication topologies via graph neural networks.arXiv preprint arXiv:2410.11782, 2024
-
[38]
Multi-agent architecture search via agentic supernet.arXiv preprint arXiv:2502.04180, 2025
Guibin Zhang, Luyang Niu, Junfeng Fang, Kun Wang, Lei Bai, and Xiang Wang. Multi-agent architecture search via agentic supernet.arXiv preprint arXiv:2502.04180, 2025
-
[39]
Cut the crap: An economical communication pipeline for LLM-based multi-agent systems
Guibin Zhang, Yanwei Yue, Zhixun Li, Sukwon Yun, Guancheng Wan, Kun Wang, Dawei Cheng, Jeffrey Xu Yu, and Tianlong Chen. Cut the crap: An economical communication pipeline for LLM-based multi-agent systems. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=LkzuPorQ5L
work page 2025
-
[40]
AFlow: Automating Agentic Workflow Generation
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, et al. Aflow: Automating agentic workflow generation.arXiv preprint arXiv:2410.10762, 2024
work page internal anchor Pith review arXiv 2024
-
[41]
arXiv preprint arXiv:2507.22606 , year=
Yaolun Zhang, Xiaogeng Liu, and Chaowei Xiao. Metaagent: Automatically constructing multi-agent systems based on finite state machines.arXiv preprint arXiv:2507.22606, 2025
-
[42]
Mingming Zhao, Xiaokang Wei, Yuanqi Shao, Kaiwen Zhou, Lin Yang, Siwei Rao, Junhui Zhan, and Zhitang Chen. a2f low: Automating agentic workflow generation via self-adaptive abstraction operators.arXiv preprint arXiv:2511.20693, 2025
-
[43]
DeepResearcher: Scaling deep research via reinforcement learning in real-world environments
Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, and Pengfei Liu. DeepResearcher: Scaling deep research via reinforcement learning in real-world environments. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025. URLhttps://aclanthology.org/2025.emnlp-main.22/
work page 2025
-
[44]
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[45]
Gptswarm: Language agents as optimizable graphs
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. Gptswarm: Language agents as optimizable graphs. InForty-first International Conference on Machine Learning, 2024. A Algorithmic Summary of EvoMAS This section provides a high-level pseudocode description of EvoMAS, summarizing the interaction between e...
work page 2024
-
[46]
Updated subtask list with status tags: [TODO / DONE / FAILED / NEED-REFINE]
-
[47]
Next active subtask: one sentence
-
[48]
Updated completed-subtasks summary: concise and reusable in later stages [RULES] - Mark a subtask DONE only when evaluator feedback indicates success. - If execution failed or evidence is missing, propose a repair/refinement subtask. - Keep the plan minimal and focused on the next execution stage. C.2 Evaluator Prompt The Evaluator is implemented as a too...
-
[49]
Analyze: Carefully examine the current solution in the context of the task requirements
-
[50]
Evaluate: Identify factual errors, missing information, incomplete aspects, logical inconsistencies
-
[51]
Refine: Correct all identified errors and supplement missing details. Important Guidelines: - If the task has multiple possible solutions, carefully evaluate whether the provided current solution is correct - do not blindly trust it - Base your analysis strictly on the task requirements - Correct factual errors and logical mistakes - Add missing details n...
-
[52]
ALWAYS call a tool - use web_searcher_tool to search or final_answer_tool to answer
-
[53]
Use clear and specific search queries to get relevant results
-
[54]
Never repeat the same search query
-
[56]
Include source URLs in your final answer - add 17 a "Sources:" section with URLs from the search results you used C.4.5 Web-browser Agent The Web-browser agent interacts with web pages, extracts information, and answers questions by browsing websites. Web-browser Agent prompt template. You are a web browser automation specialist assistant. Your role is to...
-
[57]
ALWAYS call a tool - use custom_browser_tool to browse and interact with web pages or final_answer_tool to answer
-
[58]
Navigate to relevant websites first, then browse and interact with web pages or final_answer_tool to answer
-
[59]
Navigate to relevant websites first, then interact with elements (click, input, scroll) as needed
-
[60]
Use extract_content action to get specific information from the current page
-
[61]
Always provide your final answer using final_answer_tool
-
[62]
Include source URLs in your final answer - add a "Sources:" section with URLs from the web pages you visited C.4.6 Early-exit Agent The Early-exit agent serves as a signal to terminate the multi-layer agent coordination process early. Early-exit Agent prompt template. You are an early exit signal agent. When selected by the Coordinator, you indicate that ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.