Recognition: no theorem link
LLaVA-UHD v4: What Makes Efficient Visual Encoding in MLLMs?
Pith reviewed 2026-05-12 02:02 UTC · model grok-4.3
The pith
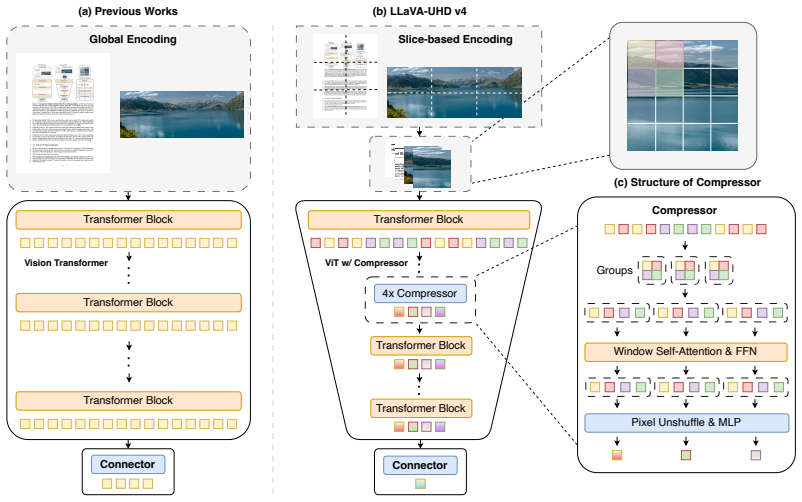
LLaVA-UHD v4 shows that slice-based encoding combined with early token compression inside the vision transformer reduces visual encoding FLOPs by 55.8 percent while matching or exceeding baseline performance on high-resolution tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLaVA-UHD v4 integrates intra-ViT early compression into a slice-based encoding framework, showing that this combination lowers visual-encoding FLOPs by 55.8 percent for high-resolution inputs while matching or surpassing the performance of prior global-encoding baselines on document understanding, OCR, and general VQA tasks.
What carries the argument
intra-ViT early compression inside the slice-based encoding framework, which reduces the token count in shallow vision transformer layers to avoid full quadratic attention cost before any later reduction.
If this is right
- High-resolution images become feasible in MLLMs with substantially lower visual-side computation.
- Performance on document understanding, OCR, and VQA tasks stays the same or improves under the reduced compute budget.
- Visual encoding cost becomes adjustable by choosing compression ratios in early ViT layers.
- Future high-resolution multimodal models can follow the slice-plus-early-compression pattern as a practical design choice.
Where Pith is reading between the lines
- The early-compression pattern could extend to other vision encoders beyond the specific ViT architecture used in the experiments.
- Lower visual FLOPs may allow deployment of detailed MLLMs on hardware with tighter memory or power limits.
- Different slice counts or compression schedules might yield further trade-offs not explored in the current benchmarks.
Load-bearing premise
That early token reduction inside the vision transformer layers preserves all necessary fine-grained visual information for the tested benchmarks without any hidden adjustments that affect the measured FLOPs savings.
What would settle it
An evaluation showing that the intra-ViT compression version produces lower accuracy than the uncompressed slice baseline specifically on fine-detail subtasks such as high-resolution text recognition or dense chart reading.
Figures


read the original abstract
Visual encoding constitutes a major computational bottleneck in Multimodal Large Language Models (MLLMs), especially for high-resolution image inputs. The prevailing practice typically adopts global encoding followed by post-ViT compression. Global encoding produces massive token sequences, while post-ViT compression incurs the full quadratic attention cost of the ViT before any token reduction takes place. In this work, we revisit this convention along two dimensions: the encoding strategy and visual token compression. First, controlled experiments show that slice-based encoding outperforms global encoding across benchmarks, suggesting that preserving local details through sliced views can be more beneficial than applying global attention for fine-grained perception. Second, we introduce intra-ViT early compression, which reduces tokens in shallow ViT layers and substantially lowers visual-encoding FLOPs while preserving downstream performance. By integrating intra-ViT compression into the slice-based encoding framework, we present LLaVA-UHD v4, an efficient and compute-controllable visual encoding scheme tailored for high-resolution inputs. Across a diverse set of benchmarks covering document understanding, OCR, and general VQA, LLaVA-UHD v4 reduces visual-encoding FLOPs by 55.8% while matching or even surpassing baseline performance. These results suggest that visual-encoding efficiency can be substantially improved without sacrificing downstream performance, providing a practical design direction for efficient high-resolution MLLMs. All model weights and code will be publicly released to support further research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents LLaVA-UHD v4, an MLLM visual encoding scheme that combines slice-based encoding (instead of global) with intra-ViT early compression in shallow layers. Controlled experiments are used to show that this yields a 55.8% reduction in visual-encoding FLOPs for high-resolution inputs while matching or exceeding baseline performance on document understanding, OCR, and general VQA benchmarks.
Significance. If the results hold under full scrutiny, the work offers a practical, compute-controllable alternative to the dominant global-encoding-plus-post-ViT-compression paradigm, with potential impact on scaling high-resolution MLLMs. The explicit plan to release weights and code is a clear strength that supports reproducibility.
major comments (2)
- [Abstract / Experimental results] Abstract and experimental results section: the central 55.8% FLOPs reduction claim is load-bearing but lacks an explicit statement of the baseline model version, the exact FLOPs accounting formula (including whether quadratic attention costs are measured before or after intra-ViT reduction), and the input resolution(s) used for the measurement.
- [Experimental results] Experimental results section: the assertion that performance is 'matching or even surpassing' the baseline rests on aggregate benchmark scores without reported error bars, number of runs, or statistical tests; this weakens confidence that the intra-ViT compression ratios preserve all necessary fine-grained information across tasks.
minor comments (2)
- Add a diagram or pseudocode clarifying the intra-ViT early compression mechanism (token reduction ratios per layer, how it integrates with slice-based inputs).
- The paper would benefit from a short limitations paragraph addressing whether the gains generalize beyond the tested ViT backbone or to resolutions substantially higher than those evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address each of the major comments below.
read point-by-point responses
-
Referee: [Abstract / Experimental results] Abstract and experimental results section: the central 55.8% FLOPs reduction claim is load-bearing but lacks an explicit statement of the baseline model version, the exact FLOPs accounting formula (including whether quadratic attention costs are measured before or after intra-ViT reduction), and the input resolution(s) used for the measurement.
Authors: We agree that these specifications are necessary to substantiate the central claim. In the revised manuscript, we will clearly state the baseline model version, provide the exact FLOPs accounting formula with details on when quadratic attention costs are measured (after intra-ViT reduction), and specify the input resolutions used. These clarifications will be added to the abstract and the experimental results section. revision: yes
-
Referee: [Experimental results] Experimental results section: the assertion that performance is 'matching or even surpassing' the baseline rests on aggregate benchmark scores without reported error bars, number of runs, or statistical tests; this weakens confidence that the intra-ViT compression ratios preserve all necessary fine-grained information across tasks.
Authors: We acknowledge that the absence of error bars and statistical tests limits the strength of the performance claims. Our results are from single runs, as is typical for such large models due to compute constraints. Nevertheless, the matching or surpassing performance is observed consistently across a variety of tasks. We will update the experimental results section to note this and discuss how the consistency supports the preservation of fine-grained information. A full statistical analysis would require additional experiments, which we note as a limitation. revision: partial
Circularity Check
No significant circularity; empirical claims are self-contained
full rationale
The paper advances an empirical proposal for efficient visual encoding in MLLMs by conducting controlled ablations of slice-based versus global encoding and introducing intra-ViT token compression, then measuring FLOPs and benchmark scores on document, OCR, and VQA tasks. No mathematical derivation chain, equations, or predictions appear that reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations. All central claims rest on directly reported experimental outcomes rather than any renaming, ansatz smuggling, or uniqueness theorem imported from prior author work, rendering the argument self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Early token reduction in shallow ViT layers does not degrade fine-grained perception on the target benchmarks
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
work page 2022
-
[2]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond, 2023
work page 2023
-
[3]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022
work page internal anchor Pith review arXiv 2022
-
[4]
Honeybee: Locality-enhanced projector for multimodal llm
Junbum Cha, Wooyoung Kang, Jonghwan Mun, and Byungseok Roh. Honeybee: Locality-enhanced projector for multimodal llm. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13817–13827, 2024
work page 2024
-
[5]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024
work page 2024
-
[6]
Sharegpt4v: Improving large multi-modal models with better captions
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. InEuropean Conference on Computer Vision, pages 370–387. Springer, 2024
work page 2024
-
[7]
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models?Advances in Neural Information Processing Systems, 37:27056–27087, 2024
work page 2024
-
[8]
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites.Science China Information Sciences, 67(12):220101, 2024
work page 2024
-
[9]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
work page 2024
-
[10]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing systems, 36:49250–49267, 2023
work page 2023
-
[11]
Mostafa Dehghani, Basil Mustafa, Josip Djolonga, Jonathan Heek, Matthias Minderer, Mathilde Caron, Andreas Steiner, Joan Puigcerver, Robert Geirhos, Ibrahim M Alabdulmohsin, et al. Patch n’pack: Navit, a vision transformer for any aspect ratio and resolution.Advances in Neural Information Processing Systems, 36:2252–2274, 2023
work page 2023
-
[12]
Multimodal autoregressive pre-training of large vision encoders
Enrico Fini, Mustafa Shukor, Xiujun Li, Philipp Dufter, Michal Klein, David Haldimann, Sai Aitharaju, Victor G Turrisi da Costa, Louis Béthune, Zhe Gan, et al. Multimodal autoregressive pre-training of large vision encoders. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9641–9654, 2025
work page 2025
-
[13]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pag...
work page 2024
-
[14]
Llava-uhd: an lmm perceiving any aspect ratio and high-resolution images
Zonghao Guo, Ruyi Xu, Yuan Yao, Junbo Cui, Zanlin Ni, Chunjiang Ge, Tat-Seng Chua, Zhiyuan Liu, and Gao Huang. Llava-uhd: an lmm perceiving any aspect ratio and high-resolution images. InEuropean Conference on Computer Vision, pages 390–406. Springer, 2024
work page 2024
-
[15]
mplug-docowl 1.5: Unified structure learning for ocr-free document understanding
Anwen Hu, Haiyang Xu, Jiabo Ye, Ming Yan, Liang Zhang, Bo Zhang, Ji Zhang, Qin Jin, Fei Huang, and Jingren Zhou. mplug-docowl 1.5: Unified structure learning for ocr-free document understanding. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 3096–3120, 2024. 10
work page 2024
-
[16]
Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Barun Patra, et al. Language is not all you need: Aligning perception with language models.Advances in Neural Information Processing Systems, 36:72096–72109, 2023
work page 2023
-
[17]
Gabriel Ilharco, Mitchell Wortsman, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, et al. Openclip.Zenodo, 2021
work page 2021
-
[18]
Prismatic VLMs: Investigating the design space of visually-conditioned language models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Prismatic VLMs: Investigating the design space of visually-conditioned language models. InInternational Conference on Machine Learning (ICML), 2024
work page 2024
-
[19]
A diagram is worth a dozen images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. InEuropean conference on computer vision, pages 235–251. Springer, 2016
work page 2016
-
[20]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[21]
Yanwei Li, Yuechen Zhang, Chengyao Wang, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, and Jiaya Jia. Mini-gemini: Mining the potential of multi-modality vision language models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[22]
Boosting multimodal large language models with visual tokens withdrawal for rapid inference
Zhihang Lin, Mingbao Lin, Luxi Lin, and Rongrong Ji. Boosting multimodal large language models with visual tokens withdrawal for rapid inference. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 5334–5342, 2025
work page 2025
-
[23]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
work page 2024
-
[24]
Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
work page 2024
-
[25]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[26]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? In European conference on computer vision, pages 216–233. Springer, 2024
work page 2024
-
[27]
Ocrbench: on the hidden mystery of ocr in large multimodal models
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. Ocrbench: on the hidden mystery of ocr in large multimodal models. Science China Information Sciences, 67(12):220102, 2024
work page 2024
-
[28]
Dongchen Lu, Yuyao Sun, Zilu Zhang, Leping Huang, Jianliang Zeng, Mao Shu, and Huo Cao. Internvl- x: Advancing and accelerating internvl series with efficient visual token compression.arXiv preprint arXiv:2503.21307, 2025
-
[29]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the association for computational linguistics: ACL 2022, pages 2263–2279, 2022
work page 2022
-
[31]
Minesh Mathew, Dimosthenis Karatzas, and C.V . Jawahar. DocVQA: A Dataset for VQA on Document Images. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2200–2209, 2021
work page 2021
-
[32]
Mm1: methods, analysis and insights from multimodal llm pre-training
Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Anton Belyi, et al. Mm1: methods, analysis and insights from multimodal llm pre-training. InEuropean Conference on Computer Vision, pages 304–323. Springer, 2024
work page 2024
-
[33]
Omnidocbench: Benchmarking diverse pdf document parsing with comprehensive annotations
Linke Ouyang, Yuan Qu, Hongbin Zhou, Jiawei Zhu, Rui Zhang, Qunshu Lin, Bin Wang, Zhiyuan Zhao, Man Jiang, Xiaomeng Zhao, et al. Omnidocbench: Benchmarking diverse pdf document parsing with comprehensive annotations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24838–24848, 2025. 11
work page 2025
-
[34]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world.arXiv preprint arXiv:2306.14824, 2023
work page internal anchor Pith review arXiv 2023
-
[35]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[36]
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949, 2021
work page 2021
-
[37]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale.arXiv preprint arXiv:2303.15389, 2023
work page internal anchor Pith review arXiv 2023
-
[38]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, et al. Cogvlm: Visual expert for pretrained language models.Advances in Neural Information Processing Systems, 37:121475–121499, 2024
work page 2024
-
[43]
V?: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V?: Guided visual search as a core mechanism in multimodal llms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13084– 13094, 2024
work page 2024
-
[44]
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, et al. Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction.arXiv preprint arXiv:2410.17247, 2024
-
[45]
Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer, and Christoph Feichtenhofer. Demystifying clip data.arXiv preprint arXiv:2309.16671, 2023
-
[46]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mplug-owl: Modularization empowers large language models with multimodality.arXiv preprint arXiv:2304.14178, 2023
work page Pith review arXiv 2023
-
[49]
A-vit: Adaptive tokens for efficient vision transformer
Hongxu Yin, Arash Vahdat, Jose M Alvarez, Arun Mallya, Jan Kautz, and Pavlo Molchanov. A-vit: Adaptive tokens for efficient vision transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10809–10818, 2022
work page 2022
-
[50]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567, 2024
work page 2024
-
[51]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023. 12
work page 2023
-
[52]
Yi-Fan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qingsong Wen, Zhang Zhang, et al. Mme-realworld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans?arXiv preprint arXiv:2408.13257, 2024
-
[53]
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. Sparsevlm: Visual token sparsification for efficient vision-language model inference.arXiv preprint arXiv:2410.04417, 2024
-
[54]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023. 13 A Related Work A.1 Vision Encoder Language-supervised contrastive models remain the dominant choice for MLLMs due to their natural pre-alignment with language....
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.