Recognition: no theorem link
From Traditional Taggers to LLMs: A Comparative Study of POS Tagging for Medieval Romance Languages
Pith reviewed 2026-05-12 03:33 UTC · model grok-4.3
The pith
Large language models outperform traditional taggers for part-of-speech tagging of medieval Romance languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
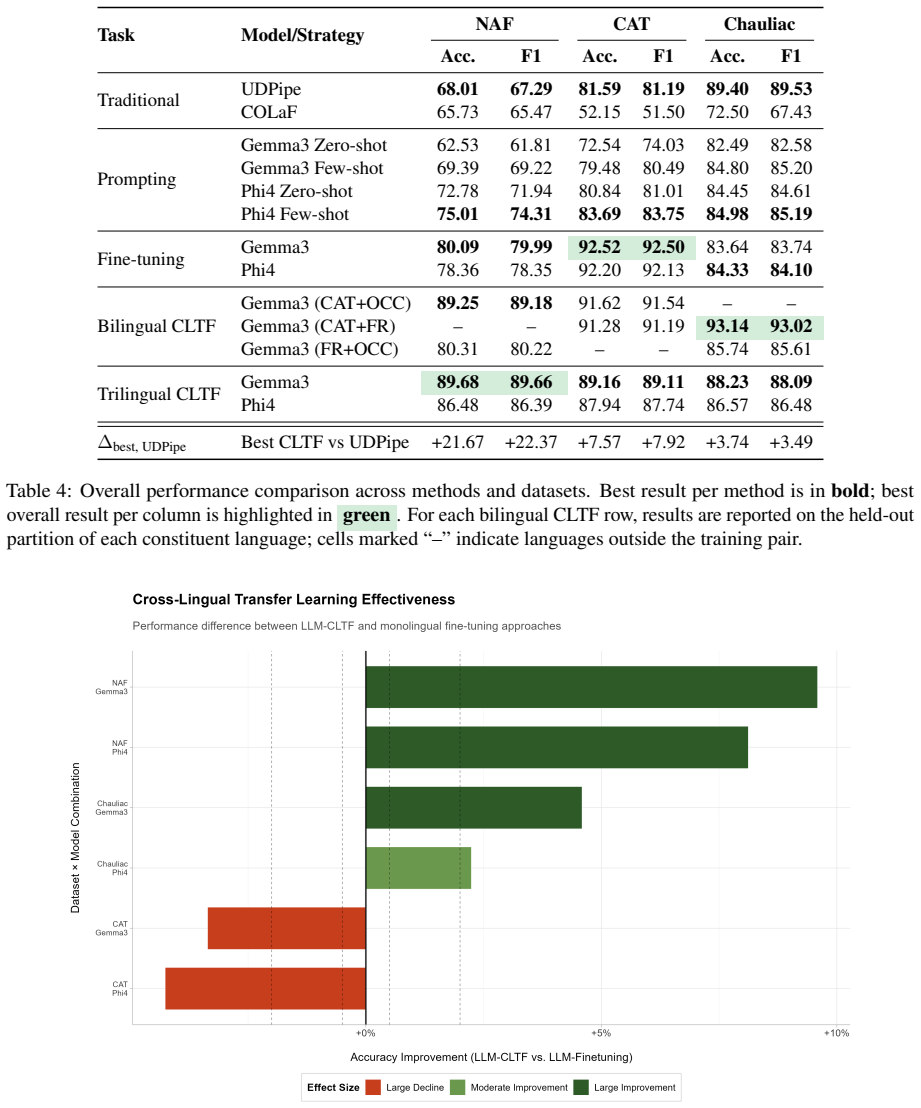
Experiments on historically grounded datasets show that LLM-based approaches consistently outperform traditional taggers, with fine-tuning and multilingual training yielding the largest improvements. In particular, cross-lingual transfer learning substantially benefits under-resourced varieties, while targeted bilingual training can outperform broader multilingual configurations for specific target languages. The results highlight the importance of linguistic proximity and dataset characteristics when designing transfer strategies for historical NLP.
What carries the argument
The evaluation of zero-shot prompting, few-shot prompting, monolingual fine-tuning, and cross-lingual transfer learning settings using open-source LLMs against rule-based and statistical taggers.
If this is right
- Fine-tuned LLMs achieve higher POS tagging accuracy than traditional taggers on these medieval languages.
- Multilingual training substantially improves results for under-resourced medieval varieties.
- Targeted bilingual training can exceed the performance of broader multilingual training for particular target languages.
- Linguistic proximity between languages influences how effective cross-lingual transfer will be.
- The findings supply practical guidance for deploying LLM-based tagging in digital humanities work on historical texts.
Where Pith is reading between the lines
- Higher tagging accuracy could support improved downstream analysis such as syntactic parsing or information retrieval from medieval manuscripts.
- The transfer strategies may extend to other historical language varieties that share similar spelling variation and data scarcity.
- Hybrid systems that combine LLM predictions with targeted traditional rules could be tested to further reduce errors on variant spellings.
Load-bearing premise
That performance differences arise only from the tagging methods and transfer strategies rather than from unstated differences in model scale, pretraining data overlap with historical texts, or biases in the medieval corpora.
What would settle it
A controlled re-run of the experiments using models matched for size and pretraining data, or an evaluation of the top configurations on an independent medieval text dataset not used in the original study.
Figures


read the original abstract
Part-of-speech (POS) tagging for Medieval Romance languages remains challenging due to orthographic variation, morphological complexity, and limited annotated resources. This paper presents a systematic empirical evaluation of large language models (LLMs) for POS tagging across three medieval varieties: Medieval Occitan, Medieval Catalan, and Medieval French. We compare traditional rule-based and statistical taggers with modern open-source LLMs under zero-shot prompting, few-shot prompting, monolingual fine-tuning, and cross-lingual transfer learning settings. Experiments on historically grounded datasets show that LLM-based approaches consistently outperform traditional taggers, with fine-tuning and multilingual training yielding the largest improvements. In particular, cross-lingual transfer learning substantially benefits under-resourced varieties, while targeted bilingual training can outperform broader multilingual configurations for specific target languages. The results highlight the importance of linguistic proximity and dataset characteristics when designing transfer strategies for historical NLP. These findings provide empirical insights into the applicability of modern neural methods to medieval text processing and provide practical guidance for deploying LLM-based POS tagging pipelines in digital humanities research. All code, models, and processed datasets are released for reproducibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This manuscript presents a systematic empirical comparison of traditional rule-based and statistical POS taggers against open-source LLMs for part-of-speech tagging on historically grounded datasets of Medieval Occitan, Medieval Catalan, and Medieval French. The authors evaluate zero-shot and few-shot prompting, monolingual fine-tuning, and cross-lingual transfer learning, claiming that LLM-based methods consistently outperform traditional taggers, with the largest gains from fine-tuning and multilingual training. Cross-lingual transfer particularly benefits under-resourced varieties, while targeted bilingual training can outperform broader multilingual setups for specific languages. The work stresses the importance of linguistic proximity and dataset characteristics, and releases all code, models, and processed datasets for reproducibility.
Significance. If the quantitative results hold under the reported controls, this study offers a valuable contribution to historical NLP by providing concrete evidence on the effectiveness of modern neural methods for low-resource medieval Romance languages. The emphasis on fine-tuning and cross-lingual strategies supplies practical guidance for digital humanities applications where annotated data is scarce. A notable strength is the full release of code, models, and datasets, which directly supports reproducibility and enables follow-up work. The paper bridges traditional computational linguistics with LLM techniques in a domain that has received limited attention.
minor comments (3)
- Abstract: The abstract asserts consistent outperformance and benefits of fine-tuning and cross-lingual transfer but omits any quantitative results, dataset sizes, or specific metrics. Adding one or two key numbers (e.g., accuracy deltas) would strengthen the summary without lengthening the paragraph.
- Section 4 (Experiments): While the full text supplies model names, hyperparameters, and dataset provenance as noted in the review, ensure that all tables reporting accuracy include error bars or statistical significance tests for the cross-lingual comparisons to support the claim of substantial benefits.
- Section 5 (Discussion): The discussion of linguistic proximity is insightful, but a brief paragraph on potential confounds (e.g., pretraining data overlap with historical texts) would address the main assumption raised in the review and strengthen the interpretation of transfer results.
Simulated Author's Rebuttal
We thank the referee for the positive and constructive review, which accurately summarizes our empirical comparison of traditional POS taggers and LLMs on medieval Occitan, Catalan, and French. We appreciate the recognition of our contributions to historical NLP, the practical guidance on fine-tuning and cross-lingual strategies, and the emphasis on reproducibility through released resources. We will incorporate minor revisions to further strengthen clarity and presentation as suggested.
Circularity Check
No significant circularity; empirical comparison only
full rationale
The paper is a straightforward empirical comparison of POS taggers (traditional vs. LLM-based) on three medieval Romance language datasets. It reports experimental outcomes under zero-shot, few-shot, fine-tuning, and cross-lingual settings, with explicit statements that code, models, and datasets are released. No mathematical derivation chain, fitted parameters renamed as predictions, self-definitional equations, or load-bearing self-citations appear in the abstract or described structure. The central claims rest on reproducible experimental results rather than any reduction to inputs by construction. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption POS tagging remains a meaningful and evaluable task for medieval Romance languages despite orthographic variation and morphological complexity.
Reference graph
Works this paper leans on
-
[1]
2025 , month = may, howpublished =
Wiedner, Marinus , title =. doi:10.5281/zenodo.15300719 , url =
-
[2]
doi:10.5281/zenodo.5615759 , url =
Pujol i Campeny, Afra and Meelen, Marieke , title =. doi:10.5281/zenodo.5615759 , url =
- [3]
-
[4]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Gago Jover, Francisco , year=. Cirugía mayor , url=. Spanish Medical Texts. Digital Library of Old Spanish Texts. , publisher=
-
[8]
Gago Jover, Francisco , year=. Tratado de cirugía , url=. Spanish Medical Texts. Digital Library of Old Spanish Texts. , publisher=
-
[9]
Tittel, Sabine , address =. Die "Anathomie" in der "Grande Chirurgie" des Gui de Chauliac : wort- und sachgeschichtliche Untersuchungen und Edition , year =. Die "Anathomie" in der "Grande Chirurgie" des Gui de Chauliac Wort- und Sachgeschichtliche Untersuchungen und Edition , isbn =
- [10]
-
[11]
The Oxford handbook of the French language , publisher =
Philippe Caron , title =. The Oxford handbook of the French language , publisher =. 2024 , pages =
work page 2024
-
[12]
Versione occitanica della prima metà del Trecento , year =
Abū’l Qāsim Halaf Ibn 'Abbās az-Zahrāwī, La Chirurgia. Versione occitanica della prima metà del Trecento , year =
-
[13]
Lapidaire en prose , publisher =
- [14]
-
[15]
Manuel de linguistique occitane , publisher =
Jean Sibille , title =. Manuel de linguistique occitane , publisher =. 2024 , pages =
work page 2024
-
[16]
Trotter, D. A. , title = ". Forum for Modern Language Studies , volume =. 1999 , issn =
work page 1999
-
[17]
Poujade, Clamenca , title =
-
[18]
Wiedner, Marinus , year =. Old
- [19]
-
[20]
Part-of-Speech Tagging on 16th-Century
St. Part-of-Speech Tagging on 16th-Century. 2023 , publisher =
work page 2023
-
[21]
Improving Lemmatization of Non-Standard Languages with Joint Learning
Manjavacas, Enrique and K \'a d \'a r, \'A kos and Kestemont, Mike. Improving Lemmatization of Non-Standard Languages with Joint Learning. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1153
-
[22]
Nédey, Oriane and Janès, Juliette and Sagot, Benoît and Bawden, Rachel and Clérice, Thibault , title =
-
[23]
Miletic, Aleksandra and Bernhard, Delphine and Bras, Myriam and Ligozat, Anne-Laure and Vergez-Couret, Marianne , URL =
-
[24]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
- [25]
-
[26]
Dan Gusfield , title =. 1997
work page 1997
-
[27]
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
work page 2015
-
[28]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[29]
A Grounded Unsupervised Universal Part-of-Speech Tagger for Low-Resource Languages
Cardenas, Ronald and Lin, Ying and Ji, Heng and May, Jonathan. A Grounded Unsupervised Universal Part-of-Speech Tagger for Low-Resource Languages. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1252
-
[30]
Unsupervised Cross-Lingual Part-of-Speech Tagging for Truly Low-Resource Scenarios
Eskander, Ramy and Muresan, Smaranda and Collins, Michael. Unsupervised Cross-Lingual Part-of-Speech Tagging for Truly Low-Resource Scenarios. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.391
-
[31]
Automatic Transcription of Handwritten Old O ccitan Language
Garces Arias, Esteban and Pai, Vallari and Sch. Automatic Transcription of Handwritten Old O ccitan Language. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.953
-
[32]
International Conference on Computational Linguistics , year=
Part-of-Speech Tagging on an Endangered Language: a Parallel Griko-Italian Resource , author=. International Conference on Computational Linguistics , year=
-
[33]
Olga Scrivner and Sandra K. Building an old. Proceedings of KONVENS 2012 , pages =. 2012 , editor =
work page 2012
-
[34]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Weakly supervised pos taggers perform poorly on truly low-resource languages , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[35]
Decoding Decoded: Understanding Hyperparameter Effects in Open-Ended Text Generation
Garces Arias, Esteban and Li, Meimingwei and Heumann, Christian and Assenmacher, Matthias. Decoding Decoded: Understanding Hyperparameter Effects in Open-Ended Text Generation. Proceedings of the 31st International Conference on Computational Linguistics. 2025
work page 2025
-
[36]
Adaptive Contrastive Search: Uncertainty-Guided Decoding for Open-Ended Text Generation
Garces Arias, Esteban and Rodemann, Julian and Li, Meimingwei and Heumann, Christian and A enmacher, Matthias. Adaptive Contrastive Search: Uncertainty-Guided Decoding for Open-Ended Text Generation. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.885
-
[37]
Hierarchical neural story generation
Fan, Angela and Lewis, Mike and Dauphin, Yann. Hierarchical Neural Story Generation. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1082
-
[38]
Beam Search Strategies for Neural Machine Translation , url=
Freitag, Markus and Al-Onaizan, Yaser , year=. Beam Search Strategies for Neural Machine Translation , url=. doi:10.18653/v1/w17-3207 , booktitle=
-
[39]
A Contrastive Framework for Neural Text Generation , author=. 2022 , eprint=
work page 2022
-
[40]
A learning algorithm for Boltzmann machines , author=. Cognitive science , volume=. 1985 , publisher=
work page 1985
- [41]
-
[42]
The Curious Case of Neural Text Degeneration
The curious case of neural text degeneration , author=. arXiv preprint arXiv:1904.09751 , year=
work page internal anchor Pith review arXiv 1904
-
[43]
doi:10.5281/zenodo.3883589 , url =
Clérice, Thibault , title =. doi:10.5281/zenodo.3883589 , url =
- [44]
- [45]
-
[46]
Gemma 2: Improving Open Language Models at a Practical Size , author=. 2024 , eprint=
work page 2024
-
[47]
Aya 23: Open Weight Releases to Further Multilingual Progress , author=. 2024 , eprint=
work page 2024
- [48]
-
[49]
Improving Low-Resource POS Tagging with Transfer Learning: A Case in Cantonese , author=
-
[50]
Make the Best of Cross-lingual Transfer: Evidence from POS Tagging with over 100 Languages
de Vries, Wietse and Wieling, Martijn and Nissim, Malvina. Make the Best of Cross-lingual Transfer: Evidence from POS Tagging with over 100 Languages. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.529
-
[51]
C orpus A ri \`e ja: Building an Annotated Corpus with Variation in O ccitan
Poujade, Clamenca and Bras, Myriam and Urieli, Assaf. C orpus A ri \`e ja: Building an Annotated Corpus with Variation in O ccitan. Proceedings of the 3rd Annual Meeting of the Special Interest Group on Under-resourced Languages @ LREC-COLING 2024. 2024
work page 2024
-
[52]
Modeling Orthographic Variation in O ccitan`s Dialects
Hopton, Zachary and Aepli, No. Modeling Orthographic Variation in O ccitan`s Dialects. Proceedings of the Eleventh Workshop on NLP for Similar Languages, Varieties, and Dialects (VarDial 2024). 2024. doi:10.18653/v1/2024.vardial-1.6
-
[53]
Moeller, Sarah and Liu, Ling and Hulden, Mans. To POS Tag or Not to POS Tag: The Impact of POS Tags on Morphological Learning in Low-Resource Settings. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.1865...
-
[54]
Development of Part-of-Speech tagger for a low-resource endangered language , year=
Gore, Toshal and Khatavkar, Vaibhav , booktitle=. Development of Part-of-Speech tagger for a low-resource endangered language , year=
-
[55]
Advances in Neural Information Processing Systems , volume=
Language Models are Few-Shot Learners , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
Journal of Machine Learning Research , volume=
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author=. Journal of Machine Learning Research , volume=
-
[57]
Natural Language Processing for Historical Texts , author=. 2012 , publisher=
work page 2012
-
[58]
Natural Language Engineering , volume=
Natural Language Processing for Similar Languages, Varieties, and Dialects: A Survey , author=. Natural Language Engineering , volume=. 2019 , publisher=
work page 2019
-
[59]
High-Resource Methodological Bias in Low-Resource Investigations , author=. 2022 , eprint=
work page 2022
-
[60]
Weakly Supervised POS Taggers Perform Poorly on Truly Low-Resource Languages , author=. 2020 , eprint=
work page 2020
-
[61]
How Low is Too Low? A Computational Perspective on Extremely Low-Resource Languages , author=. 2021 , eprint=
work page 2021
-
[62]
Parameter Space Factorization for Zero-Shot Learning across Tasks and Languages , author=. 2020 , eprint=
work page 2020
-
[63]
Zero Resource Cross-Lingual Part Of Speech Tagging , author=. 2024 , eprint=
work page 2024
-
[64]
Recipe for Zero-shot POS Tagging: Is It Useful in Realistic Scenarios? , author=. 2024 , eprint=
work page 2024
-
[65]
ToPro: Token-Level Prompt Decomposition for Cross-Lingual Sequence Labeling Tasks , author=. 2024 , eprint=
work page 2024
-
[66]
Improving Zero-shot Cross-lingual Transfer between Closely Related Languages by injecting Character-level Noise , author=. 2022 , eprint=
work page 2022
-
[67]
Does Manipulating Tokenization Aid Cross-Lingual Transfer? A Study on POS Tagging for Non-Standardized Languages , author=. 2023 , eprint=
work page 2023
-
[68]
Graph-Based Multilingual Label Propagation for Low-Resource Part-of-Speech Tagging , author=. 2022 , eprint=
work page 2022
-
[69]
Yunshan Cup 2020: Overview of the Part-of-Speech Tagging Task for Low-resourced Languages , author=. 2022 , eprint=
work page 2020
-
[70]
Bridging Pre-trained Language Models and Hand-crafted Features for Unsupervised POS Tagging , author=. 2022 , eprint=
work page 2022
-
[71]
Corpus and Models for Lemmatisation and POS-tagging of Old French , author=. 2021 , eprint=
work page 2021
-
[72]
Part of Speech Tagging and Lemmatization of Medieval Latin Texts.A Cross-Genre Survey , author=
eFontes. Part of Speech Tagging and Lemmatization of Medieval Latin Texts.A Cross-Genre Survey , author=. 2024 , eprint=
work page 2024
-
[73]
A Falta de Pan, Buenas Son Tortas: The Efficacy of Predicted UPOS Tags for Low Resource UD Parsing , author=. 2021 , eprint=
work page 2021
-
[74]
From FreEM to D'AlemBERT: a Large Corpus and a Language Model for Early Modern French , author=. 2022 , eprint=
work page 2022
-
[75]
Part-of-Speech Tagging on an Endangered Language: a Parallel Griko-Italian Resource , author=. 2018 , eprint=
work page 2018
-
[76]
The Importance of Context in Very Low Resource Language Modeling , author=. 2022 , eprint=
work page 2022
-
[77]
Leveraging Pretrained Word Embeddings for Part-of-Speech Tagging of Code Switching Data , url=
AlGhamdi, Fahad and Diab, Mona , year=. Leveraging Pretrained Word Embeddings for Part-of-Speech Tagging of Code Switching Data , url=. doi:10.18653/v1/w19-1410 , booktitle=
-
[78]
Reducing Confusion in Active Learning for Part-Of-Speech Tagging , author=. 2020 , eprint=
work page 2020
-
[79]
Distant Supervision from Disparate Sources for Low-Resource Part-of-Speech Tagging , author=. 2018 , eprint=
work page 2018
-
[80]
Low-Resource Name Tagging Learned with Weakly Labeled Data , author=. 2019 , eprint=
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.