Recognition: 2 theorem links
· Lean TheoremCornerstones or Stumbling Blocks? Deciphering the Rock Tokens in On-Policy Distillation
Pith reviewed 2026-05-12 02:28 UTC · model grok-4.3
The pith
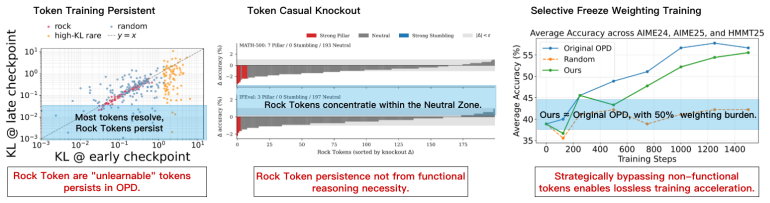
High-loss Rock Tokens in on-policy distillation resist training yet add almost nothing to reasoning performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
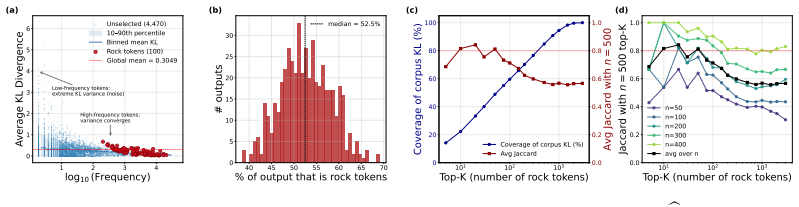
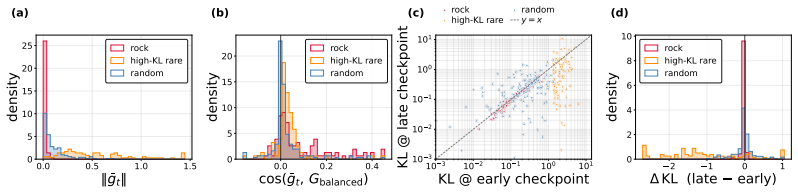
Even after on-policy distillation reaches apparent saturation, a substantial subset of tokens continues to exhibit persistently high loss. These Rock Tokens can account for up to 18% of the tokens in generated outputs. They provide a disproportionately large share of total gradient norms yet remain stagnant throughout training and resist teacher-driven corrections. Through causal intervention, these tokens are shown to provide negligible functional contribution to the model's actual reasoning performance, indicating that optimization bandwidth is spent on structural and discourse residuals that the student cannot or need not internalize.
What carries the argument
Rock Tokens: the persistently high-loss tokens under the per-token KL objective that resist correction while showing negligible downstream effect on reasoning.
Load-bearing premise
The tests that change or remove these high-loss tokens accurately capture whether they affect the model's final reasoning outputs.
What would settle it
Performing the causal intervention on Rock Tokens and observing clear changes in the model's reasoning accuracy or outputs would show the contribution is not negligible.
Figures


read the original abstract
While recent work in Reinforcement Learning with Verifiable Rewards (RLVR) has shown that a small subset of critical tokens disproportionately drives reasoning gains, an analogous token-level understanding of On-Policy Distillation (OPD) remains largely unexplored. In this work, we investigate high-loss tokens, a token type that--as the most direct signal of student-teacher mismatch under OPD's per-token KL objective--should progressively diminish as training converges according to existing studies; however, our empirical analysis shows otherwise. Even after OPD training reaches apparent saturation, a substantial subset of tokens continues to exhibit persistently high loss; these tokens, which we term Rock Tokens, can account for up to 18\% of the tokens in generated outputs. Our investigation reveals two startling paradoxes. First, despite their high occurrence frequency providing a disproportionately large share of total gradient norms, Rock Tokens themselves remain stagnant throughout training, resisting teacher-driven corrections. Second, through causal intervention, we find that these tokens provide negligible functional contribution to the model's actual reasoning performance. These findings suggest that a vast amount of optimization bandwidth is spent on structural and discourse residuals that the student model cannot or need not internalize. By deconstructing these dynamics, we demonstrate that strategically bypassing these ``stumbling blocks'' can significantly streamline the alignment process, challenging the necessity of uniform token weighting and offering a more efficient paradigm for large-scale model distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates persistently high-loss tokens in on-policy distillation (OPD) for language models, termed 'Rock Tokens.' These tokens persist after apparent training saturation, comprise up to 18% of generated outputs, and account for a disproportionate share of gradient norms while resisting teacher corrections. Through causal interventions, the authors claim these tokens contribute negligibly to reasoning performance, suggesting that strategically bypassing them can streamline distillation by challenging uniform token weighting.
Significance. If the causal interventions are shown to isolate token contributions without confounding effects, the work would provide a valuable empirical lens on token-level dynamics in OPD, highlighting optimization inefficiencies and motivating targeted weighting schemes for more efficient large-scale distillation. The manuscript is credited for its observational analysis of training saturation and the application of causal interventions to probe functional contributions.
major comments (1)
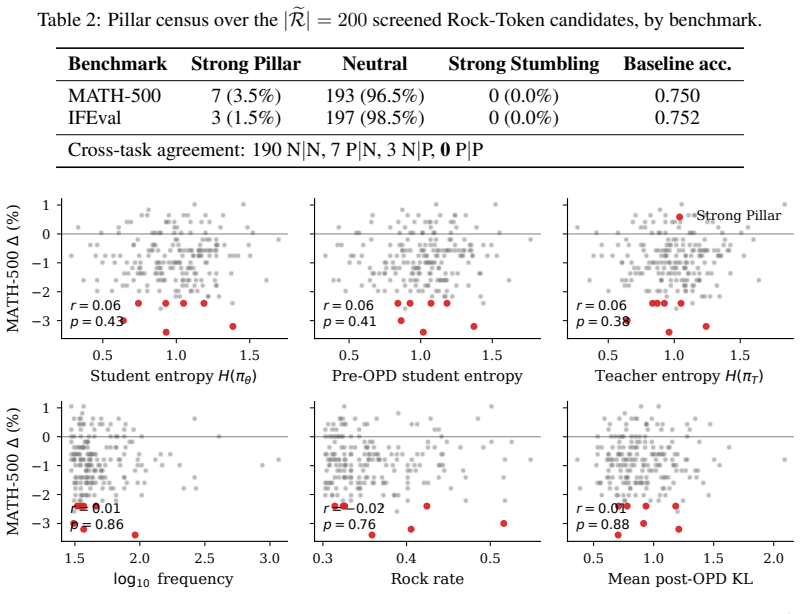
- Abstract: the central claim that causal interventions demonstrate negligible functional contribution of Rock Tokens to reasoning performance is load-bearing for the proposal to bypass them. However, in autoregressive generation, masking or altering specific tokens necessarily alters the conditioning context for all subsequent tokens. A null effect on final outputs could therefore reflect compensatory adjustments by later tokens rather than true lack of causal weight from the Rock Tokens. Without explicit controls for sequence position, length, or matched comparisons to non-Rock high-loss tokens, the intervention does not cleanly isolate the claimed negligible contribution.
minor comments (2)
- Abstract and methods: details on dataset sizes, exact intervention methods (e.g., masking vs. replacement), statistical controls, and the operational definition of 'saturation' are missing, hindering verification of the empirical observations and gradient dominance claims.
- The paper should include a dedicated section contrasting the OPD findings with prior token-level analyses in RLVR to clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies a substantive methodological consideration in our causal analysis. We address the concern directly below and describe the revisions we will make.
read point-by-point responses
-
Referee: Abstract: the central claim that causal interventions demonstrate negligible functional contribution of Rock Tokens to reasoning performance is load-bearing for the proposal to bypass them. However, in autoregressive generation, masking or altering specific tokens necessarily alters the conditioning context for all subsequent tokens. A null effect on final outputs could therefore reflect compensatory adjustments by later tokens rather than true lack of causal weight from the Rock Tokens. Without explicit controls for sequence position, length, or matched comparisons to non-Rock high-loss tokens, the intervention does not cleanly isolate the claimed negligible contribution.
Authors: We agree that autoregressive dependencies represent a potential confounder and that stronger isolation of token-level effects requires additional controls. Our original interventions replaced Rock Tokens with the teacher's token at the same position while continuing generation, yielding no measurable change in final reasoning accuracy. To address the referee's point, the revised manuscript will add: (i) position-stratified results (early/mid/late sequence interventions), (ii) length-matched sequence cohorts, and (iii) parallel interventions on non-Rock high-loss tokens at matched positions and loss magnitudes. These controls will be reported alongside the original findings to demonstrate that compensatory effects do not explain the null result for Rock Tokens specifically. revision: partial
Circularity Check
No significant circularity: purely observational and interventional analysis
full rationale
The paper reports empirical measurements of token losses during on-policy distillation, identifies persistently high-loss 'Rock Tokens' via direct observation, and assesses their functional contribution through causal interventions on generated sequences. No equations, closed-form derivations, or parameter-fitting steps are present that would reduce any reported quantity (e.g., gradient norms, loss values, or performance deltas) to a fitted input defined by the same data. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The central claims rest on external experimental benchmarks rather than self-referential reductions, satisfying the criteria for a self-contained observational study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-loss tokens are the most direct signal of student-teacher mismatch under the per-token KL objective
invented entities (1)
-
Rock Tokens
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearEven after OPD training reaches apparent saturation, a substantial subset of tokens continues to exhibit persistently high loss; these tokens, which we term Rock Tokens... through causal intervention, we find that these tokens provide negligible functional contribution to the model's actual reasoning performance.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclearWe define the initial Rock Score as R(v) = ℓ̄v · Freq(v)... context-consistent rock rate CCR(v) = |R(v)| / Freq(v).
Reference graph
Works this paper leans on
-
[1]
R. Agarwal, N. Vieillard, Y . Zhou, P. Stanczyk, S. R. Garea, M. Geist, and O. Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe twelfth international conference on learning representations, 2024
work page 2024
-
[2]
Z. Al Nazi, S. R. Dipta, and S. Kar. † dagger: Distractor-aware graph generation for executable reasoning in math problems.arXiv e-prints, pages arXiv–2601, 2026
work page 2026
- [3]
-
[4]
Deepseek-v4: Towards highly efficient million-token context intelligence.Technical Report, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence.Technical Report, 2026
work page 2026
-
[5]
J. Dekoninck, N. Jovanovi’c, T. Gehrunger, K. Rognvalddson, I. Petrov, C. Sun, and M. T. Vechev. Beyond benchmarks: Matharena as an evaluation platform for mathematics with llms. 2026. 11
work page 2026
- [6]
-
[7]
S. R. Dipta, K. Mahbub, and N. Najjar. Ganitllm: Difficulty-aware bengali mathematical reasoning through curriculum-grpo.arXiv preprint arXiv:2601.06767, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Y . Fu, H. Huang, K. Jiang, Y . Zhu, and D. Zhao. Revisiting on-policy distillation: Empirical failure modes and simple fixes.ArXiv preprint, 2026
work page 2026
-
[9]
L. Gao, J. Tow, B. Abbasi, S. Biderman, S. Black, A. DiPofi, C. Foster, L. Golding, J. Hsu, A. Le Noac’h, H. Li, K. McDonell, N. Muennighoff, C. Ociepa, J. Phang, L. Reynolds, H. Schoelkopf, A. Skowron, L. Sutawika, E. Tang, A. Thite, B. Wang, K. Wang, and A. Zou. The language model evaluation harness, 2024
work page 2024
-
[10]
E. Guha, R. Marten, S. S. Keh, N. Raoof, G. Smyrnis, H. Bansal, M. Nezhurina, J.-P. Mercat, T. Vu, Z. Sprague, A. Suvarna, B. Feuer, L. Chen, Z. Khan, E. Frankel, S. Grover, C. Choi, N. Muennighoff, S. Su, W. Zhao, J. Yang, S. Pimpalgaonkar, K. Sharma, C. C.-J. Ji, Y . Deng, S. Pratt, V . Ramanujan, J. Saad-Falcon, J. Li, A. Dave, A. Albalak, K. Arora, B....
work page internal anchor Pith review doi:10.48550/arxiv.2506.04178 2025
-
[11]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
A. Gupta, J. Yeung, G. Anumanchipalli, and A. A. Ivanova. How do llms use their depth?arXiv.org, 2025. doi: 10.48550/arxiv.2510.18871
-
[13]
J. Hübotter, F. Lübeck, L. Behric, A. Baumann, M. Bagatella, D. Marta, I. Hakimi, I. Shenfeld, T. K. Buening, C. Guestrin, et al. Reinforcement learning via self-distillation.ArXiv preprint, 2026
work page 2026
-
[14]
SCRIBE: Structured Mid-Level Supervision for Tool-Using Language Models
Y . Jiang and F. Ferraro. Scribe: Structured mid-level supervision for tool-using language models, 2026. URLhttps://arxiv.org/abs/2601.03555
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Y . Jiang, D. Li, and F. Ferraro. Drp: Distilled reasoning pruning with skill-aware step decomposition for efficient large reasoning models.arXiv preprint arXiv:2505.13975, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
F. Kunstner, R. Yadav, A. Milligan, M. Schmidt, and A. Bietti. Heavy-tailed class imbalance and why adam outperforms gradient descent on language models, 2024. URL https://arxiv.org/abs/2402.19449
-
[17]
D. Li, Z. Tan, T. Chen, and H. Liu. Contextualization distillation from large language model for knowledge graph completion. InFindings of the Association for Computational Linguistics: EACL 2024, pages 458–477, 2024
work page 2024
-
[18]
D. Li, B. Jiang, L. Huang, A. Beigi, C. Zhao, Z. Tan, A. Bhattacharjee, Y . Jiang, C. Chen, T. Wu, K. Shu, L. Cheng, and H. Liu. From generation to judgment: Opportunities and challenges of LLM- as-a-judge. In C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language P...
- [19]
-
[20]
Y . Li, Y . Zuo, B. He, J. Zhang, C. Xiao, C. Qian, T. Yu, H. Gao, W. Yang, Z. Liu, and N. Ding. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.ArXiv preprint, 2026
work page 2026
-
[21]
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
work page 2024
-
[22]
K. Lu and T. M. Lab. On-policy distillation.Thinking Machines Lab: Connectionism, 2025. doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on-policy-distillation
-
[23]
H. Meng, K. Huang, S. Wei, C. Ma, S. Yang, X. Wang, G. Wang, B. Ding, and J. Zhou. Sparse but critical: A token-level analysis of distributional shifts in rlvr fine-tuning of llms.ArXiv preprint, 2026. 12
work page 2026
-
[24]
I. Shenfeld, M. Damani, J. Hübotter, and P. Agrawal. Self-distillation enables continual learning.ArXiv preprint, 2026
work page 2026
-
[25]
Z. Tan, D. Li, S. Wang, A. Beigi, B. Jiang, A. Bhattacharjee, M. Karami, J. Li, L. Cheng, and H. Liu. Large language models for data annotation and synthesis: A survey. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 930–957, 2024
work page 2024
-
[26]
Y . Tong, D. Li, S. Wang, Y . Wang, F. Teng, and J. Shang. Can llms learn from previous mistakes? investigating llms’ errors to boost for reasoning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3065–3080, 2024
work page 2024
-
[27]
S. Wang, L. Yu, C. Gao, C. Zheng, S. Liu, R. Lu, K. Dang, X.-h. Chen, J. Yang, Z. Zhang, Y . Liu, A. Yang, A. Zhao, Y . Yue, S. Song, B. Yu, G. Huang, and J. Lin. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning. InarXiv.org, 2025. doi: 10.48550/arxiv.2506.01939
work page internal anchor Pith review doi:10.48550/arxiv.2506.01939 2025
-
[28]
S. Wang, L. Yu, C. Gao, C. Zheng, S. Liu, R. Lu, K. Dang, X.-H. Chen, J. Yang, Z. Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[29]
C.-C. Wu, Z. R. Tam, C.-Y . Lin, H.-y. Lee, and Y .-N. Chen. Mitigating forgetting in llm fine-tuning via low-perplexity token learning.ArXiv preprint, 2025
work page 2025
-
[30]
X. Xiao, B. Xia, B. Yang, B. Gao, B. Shen, C. Zhang, C. He, C. Lou, F. Luo, G. Wang, G. Xie, H. Zhang, H. Lv, H. Li, H. Chen, H.-M. Xu, H. Zhang, H. Liu, J. Duo, J. Wei, J. Xiao, J. Dong, J.-M. Shi, J. Hu, K. Bao, K. Zhou, L. Li, L. Zhao, L. Zhang, P. Li, Q. Chen, S.-y. Liu, S.-l. Yu, S. Cao, S. Chen, S. Yu, S. Liu, T.-Y . Zhou, W. Su, W. Wang, W. Ma, X. ...
work page internal anchor Pith review doi:10.48550/arxiv.2601.02780 2026
-
[31]
N. Xu, Y . Jiang, S. R. Dipta, and Z. Hengyuan. Learning how to use tools, not just when: Pattern-aware tool-integrated reasoning.MATH-AI @ NeurIPS 2025, 2025
work page 2025
-
[32]
Y . Xu, H. Sang, Z. Zhou, R. He, Z. Wang, and A. Geramifard. Tip: Token importance in on-policy distillation, 2026
work page 2026
-
[33]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
N. Yang, H. Lin, Y . Liu, B. Tian, G. Liu, and H. Zhang. Token-importance guided direct preference optimization.arXiv.org, 2025. doi: 10.48550/arxiv.2505.19653
-
[35]
Find Your Optimal Teacher: Personalized Data Synthesis via Router-Guided Multi-Teacher Distillation
H. Zhang, S. Yang, X. Liang, C. Shang, Y . Jiang, C. Tao, J. Xiong, H. K.-H. So, R. Xie, A. X. Chang, et al. Find your optimal teacher: Personalized data synthesis via router-guided multi-teacher distillation.arXiv preprint arXiv:2510.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [36]
-
[37]
S. Zhao, Z. Xie, M. Liu, J. Huang, G. Pang, F. Chen, and A. Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv.org, 2026. doi: 10.48550/arxiv.2601.18734
work page internal anchor Pith review doi:10.48550/arxiv.2601.18734 2026
-
[38]
J. Zhou, T. Lu, S. Mishra, S. Brahma, S. Basu, Y . Luan, D. Zhou, and L. Hou. Instruction-following evaluation for large language models.ArXiv preprint, 2023. 13 A Limitations First, our empirical evaluations rely predominantly on competitive mathematical reasoning; the functional role of Rock Tokens may differ in open-ended generation or coding tasks whe...
work page 2023
-
[39]
LaTeX and math delimiters— $’, \\, $$, =, ^, {, }, frac, (, ). These mark transitions into and out of math mode and operate at the syntactic boundary between prose and formula
-
[40]
These delimit logical units (paragraphs, section headers, bold spans)
Markdown and whitespace structure— **’, \n’, \n\n’, :\n\n’, —\n\n’, ###’. These delimit logical units (paragraphs, section headers, bold spans)
-
[41]
These open new reasoning steps and signal turns in the chain of thought
Discourse markers at sentence-initial position— So’, Let’, We’, But’, Now’, Wait’, Then’, Since’, This’. These open new reasoning steps and signal turns in the chain of thought
-
[42]
Digits— every digit 0’ through 9’ appears in R, each with frequency in the thousands and a non-trivial mean per-token KL. These are tokens that punctuate quantitative statements. Contrast with the frequency-matched control set. The control set Sctrl, sampled at the same frequency distribution, is qualitatively different: it consists predominantly of conte...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.