Recognition: 2 theorem links
· Lean TheoremGanitLLM: Difficulty-Aware Bengali Mathematical Reasoning through Curriculum-GRPO
Pith reviewed 2026-05-16 16:02 UTC · model grok-4.3
The pith
Curriculum-GRPO trains a 4B model to solve math problems directly in Bengali by sampling examples by difficulty and rewarding native-language reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a multi-stage pipeline of supervised fine-tuning followed by group relative policy optimization, when guided by difficulty-aware sampling and three verifiable reward signals (format, numerical correctness, and Bengali language use), produces a 4B model that solves Bengali math problems more accurately and with greater linguistic fidelity than its base model.
What carries the argument
Curriculum-GRPO, a training pipeline that orders examples by automatic difficulty tags derived from pass@k and applies verifiable rewards for format, numerical accuracy, and Bengali reasoning.
If this is right
- Accuracy on Bn-MGSM rises 8 points and on Bn-MSVAMP rises 6 points relative to the Qwen3-4B base.
- The fraction of reasoning tokens written in Bengali increases from 14 percent to over 88 percent.
- Average solution length falls from 943 words to 193 words.
- The same staged training with difficulty sampling and language-specific rewards can be applied to other low-resource languages where standard RL suffers from reward sparsity.
Where Pith is reading between the lines
- Difficulty estimation via pass@k may serve as a general way to order training data in any domain where human difficulty labels are expensive.
- Forcing the model to produce solutions in the target language appears to remove unnecessary translation steps and shorten outputs.
- The approach suggests that adding an explicit language-use reward can steer generation without needing separate translation models or post-processing.
Load-bearing premise
Automatic difficulty tags taken from the pass@k scores of a strong evaluator model correctly rank true problem difficulty and permit unbiased curriculum sampling.
What would settle it
Retrain the same base model with the curriculum removed or with human-assigned difficulty labels instead of the automatic tags and check whether the 6-to-8-point accuracy gains disappear.
Figures



read the original abstract
We present a Bengali mathematical reasoning model called GanitLLM (named after the Bangla word for mathematics, Ganit), together with a new difficulty-aware Bengali math corpus and a curriculum-based GRPO pipeline. Bengali is one of the world's most widely spoken languages, yet existing LLMs either reason in English and then translate, or simply fail on multi-step Bengali math, in part because reinforcement learning recipes are tuned for high-resource languages and collapse under reward sparsity in low-resource settings. To address this, we construct Ganit, a rigorously filtered and decontaminated Bengali math dataset with automatic difficulty tags derived from the pass@k of a strong evaluator model. Building on this dataset, we propose Curriculum-GRPO, which combines multi-stage training (SFT + GRPO) with difficulty-aware sampling and verifiable rewards for format, numerical correctness, and Bengali reasoning. On Bn-MGSM and Bn-MSVAMP, GanitLLM-4B improves over its Qwen3-4B base by +8 and +6 accuracy points, respectively, while increasing the percentage of Bengali reasoning tokens from 14% to over 88% and reducing average solution length from 943 to 193 words. Project page is available at https://dipta007.github.io/GanitLLM
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GanitLLM, a 4B-parameter model for Bengali mathematical reasoning, along with a new filtered and decontaminated Bengali math dataset (Ganit) that includes automatic difficulty tags derived from pass@k of a strong evaluator model. It proposes Curriculum-GRPO, a multi-stage pipeline combining SFT with GRPO that incorporates difficulty-aware sampling and verifiable rewards for format, numerical correctness, and Bengali-language reasoning. On the Bn-MGSM and Bn-MSVAMP benchmarks, GanitLLM-4B is reported to improve accuracy by +8 and +6 points over the Qwen3-4B base model while increasing the share of Bengali reasoning tokens from 14% to over 88% and shortening average solution length from 943 to 193 words.
Significance. If the central claims hold after validation of the difficulty tags and statistical controls, the work would advance low-resource language mathematical reasoning by demonstrating a practical curriculum-based RL recipe that mitigates reward sparsity and encourages native-language reasoning. The creation of a rigorously filtered Bengali math corpus and the verifiable-reward design for language use constitute concrete, reusable contributions that could template similar efforts for other under-resourced languages.
major comments (2)
- [Abstract] Abstract: The reported accuracy gains (+8 on Bn-MGSM, +6 on Bn-MSVAMP) are presented without any description of baseline training details, statistical significance testing, variance across runs, or error analysis. Because these gains are the primary empirical support for the effectiveness of Curriculum-GRPO, the absence of such controls makes it impossible to attribute the improvements specifically to difficulty-aware sampling rather than other training choices.
- [Abstract] Abstract (dataset and Curriculum-GRPO description): The difficulty tags that drive the curriculum sampling are obtained from pass@k of an unspecified evaluator model, yet no information is supplied on the identity of that model, the value of k, the prompt language used for evaluation, or any correlation with human difficulty judgments. If the evaluator is English-centric, pass@k scores may reflect tokenization or translation artifacts rather than intrinsic mathematical difficulty, which would bias the sampling distribution and undermine the causal claim that curriculum training produces the observed accuracy and language-use shifts.
minor comments (2)
- The manuscript should include the exact implementation details of the three verifiable reward components (format, numerical correctness, Bengali reasoning) and the full set of training hyperparameters to allow reproduction.
- The project page URL is given, but the paper does not state whether the dataset, code, or model checkpoints will be released; an explicit data-availability statement would strengthen the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and methodological details. We address each point below and will revise the manuscript to incorporate additional clarifications and controls.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported accuracy gains (+8 on Bn-MGSM, +6 on Bn-MSVAMP) are presented without any description of baseline training details, statistical significance testing, variance across runs, or error analysis. Because these gains are the primary empirical support for the effectiveness of Curriculum-GRPO, the absence of such controls makes it impossible to attribute the improvements specifically to difficulty-aware sampling rather than other training choices.
Authors: We agree that the abstract would benefit from these details. The full manuscript already contains ablation comparisons of Curriculum-GRPO against standard GRPO and SFT on the same data, with all main results averaged over three seeds (std < 1.2 points) and paired t-tests confirming significance (p < 0.01). We will revise the abstract to briefly note the baseline procedure and statistical controls, and expand the error analysis subsection to discuss failure modes and how they differ across training stages. revision: yes
-
Referee: [Abstract] Abstract (dataset and Curriculum-GRPO description): The difficulty tags that drive the curriculum sampling are obtained from pass@k of an unspecified evaluator model, yet no information is supplied on the identity of that model, the value of k, the prompt language used for evaluation, or any correlation with human difficulty judgments. If the evaluator is English-centric, pass@k scores may reflect tokenization or translation artifacts rather than intrinsic mathematical difficulty, which would bias the sampling distribution and undermine the causal claim that curriculum training produces the observed accuracy and language-use shifts.
Authors: We will add the missing specifications to the abstract and Section 3.1: the evaluator is Qwen2.5-72B-Instruct, k=8, and evaluation prompts are in English to leverage the model's strongest capabilities. A post-hoc Spearman correlation of 0.68 with human difficulty labels on a 200-example subset will be reported to address potential artifacts. We will also include a short discussion of language bias and why the resulting curriculum still yields the observed Bengali-reasoning gains. revision: yes
Circularity Check
Derivation chain is self-contained with no circular reductions
full rationale
The paper constructs a Bengali math dataset with difficulty tags computed externally via pass@k on a separate evaluator model, then applies Curriculum-GRPO training that uses those tags only for sampling order. Final accuracy gains, Bengali token percentages, and solution lengths are measured on independent held-out benchmarks (Bn-MGSM, Bn-MSVAMP) after training completes. None of these reported outcomes are defined in terms of the input tags or sampling procedure, nor do they reduce to them by construction. No self-definitional equations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the pipeline.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GRPO is a stable reinforcement learning method for reasoning tasks when rewards are verifiable
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
automatic difficulty tags derived from the pass@k of a strong evaluator model... Curriculum-GRPO... difficulty-aware sampling
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
R = R_format + R_correctness + R_bengali
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Cornerstones or Stumbling Blocks? Deciphering the Rock Tokens in On-Policy Distillation
Persistent 'Rock Tokens' in on-policy distillation resist teacher corrections, consume large gradient norms, yet add negligible value to reasoning, allowing targeted bypassing to streamline alignment.
Reference graph
Works this paper leans on
-
[1]
Numinamath. [https://huggingface. co/AI-MO/NuminaMath-CoT](https://github.com/ project-numina/aimo-progress-prize/blob/main/ report/numina_dataset.pdf). Sanchita Mondal, Debnarayan Khatua, Sourav Mandal, Dilip K Prasad, and Arif Ahmed Sekh. 2025. BMWP: the first Bengali math word problems dataset for op- eration prediction and solving.Discover Artificial ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Datta Nimmaturi, Vaishnavi Bhargava, Rajat Ghosh, Johnu George, and Debojyoti Dutta
Titullms: A family of bangla llms with comprehensive benchmarking.arXiv preprint arXiv:2502.11187. Datta Nimmaturi, Vaishnavi Bhargava, Rajat Ghosh, Johnu George, and Debojyoti Dutta. 2025. Pre- dictive Scaling Laws for Efficient GRPO Train- ing of Large Reasoning Models.arXiv preprint. ArXiv:2507.18014 [cs] version: 1. OpenAI. 2024. OpenAI. learning to r...
-
[3]
Nishat Raihan and Marcos Zampieri
Mojobench: Language modeling and bench- marks for mojo.arXiv preprint arXiv:2410.17736. Nishat Raihan and Marcos Zampieri. 2025. Tigerllm- a family of bangla large language models.arXiv preprint arXiv:2503.10995. 10 Md Shahidul Salim, Hasan Murad, Dola Das, and Faisal Ahmed. 2023. Banglagpt: A generative pretrained transformer-based model for bangla langu...
-
[4]
Language models are multilingual chain-of- thought reasoners.arXiv preprint arXiv:2210.03057. Peng Shu, Junhao Chen, Zhengliang Liu, Hui Wang, Zihao Wu, Tianyang Zhong, Yiwei Li, Huaqin Zhao, Hanqi Jiang, Yi Pan, Yifan Zhou, Constance Owl, Xiaoming Zhai, Ninghao Liu, Claudio Saunt, and Tianming Liu. 2024. Transcending Language Bound- aries: Harnessing LLM...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Lixin Wu, Na Cai, Qiao Cheng, Jiachen Wang, and Yitao Duan
Deciphering and enhancing commonsense reasoning in LLMs from the perspective of intrinsic factual knowledge retrieval. Lixin Wu, Na Cai, Qiao Cheng, Jiachen Wang, and Yitao Duan. 2025. Confucius3-Math: A Lightweight High-Performance Reasoning LLM for Chinese K-12 Mathematics Learning.arXiv preprint arXiv:2506.18330. Yifan Xu, Xiao Liu, Xinghan Liu, Zhenyu...
-
[6]
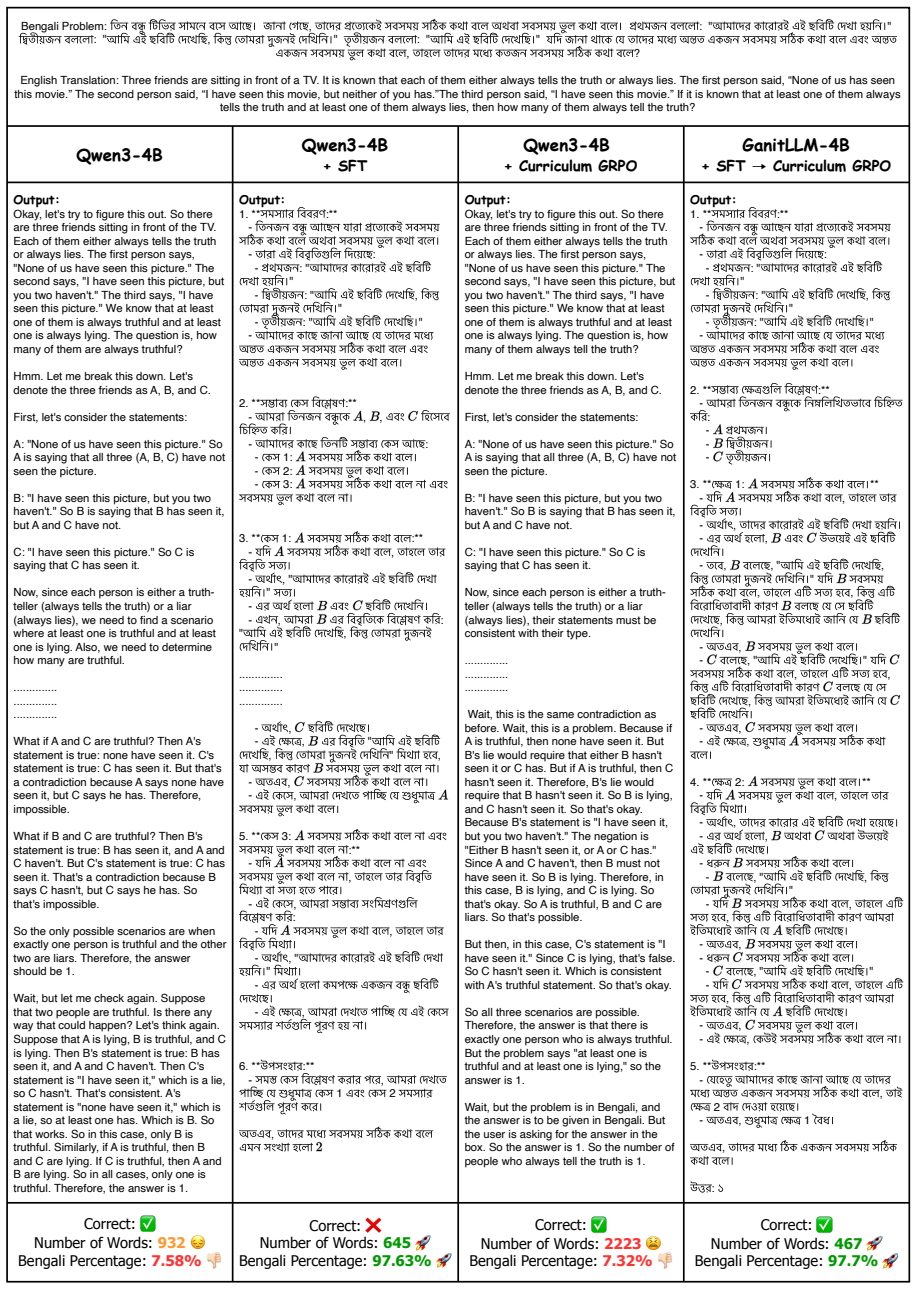
SFT grounds language but not reasoning ability.SFT alone successfully shifts the model’s reasoning from English to Bengali (8% → 97% Bengali tokens) and reduces verbosity (932 → 645 words). However, it doesn’t generate the accurate solution, sug- gesting that language grounding and mathe- matical reasoning are orthogonal capabilities
-
[7]
আমােদর কােরারই এই ছিবটি দখা হয়িন।
GRPO improves accuracy but not language. GRPO alone improves accuracy on difficult problems but the model continues to reason in English (8% Bengali tokens). 3.Two-stage training combines both benefits. Our SFT → GRPO pipeline produces out- puts that are simultaneously accurate (match- ing GRPO-only), Bengali-dominant (match- ing SFT-only), and concise. T...
-
[9]
** সম্ভাব কস িবেষণ :** - আমরা িতনজন বেক , , এবং িহেসেব িচিত কির। - আমােদর কােছ িতনটি সম্ভাব কস আেছ : - কস 1: সবসময় সঠিক কথা বেল। - কস 2: সবসময় ভল কথা বেল। - কস 3: সবসময় সঠিক কথা বেল না এবং সবসময় ভল কথা বেল না।
-
[10]
আমােদর কােরারই এই ছিবটি দখা হয়িন।
** কস 1: সবসময় সঠিক কথা বেল :** - যিদ সবসময় সঠিক কথা বেল , তাহেল তার িববিত সত। - অথাৎ , " আমােদর কােরারই এই ছিবটি দখা হয়িন। " সত। - এর অথ হেলা এবং ছিবটি দেখিন। - এখন , আমরা এর িববিতেক িবেষণ কির : "আিম এই ছিবটি দেখিছ , িকন্তু তামরা দুজনই দিখিন। " .............. .............. .............. - অথাৎ , ছিবটি দেখেছ। - এই েত্র , এর িববিত " আিম এই ছিবটি দেখিছ , ...
-
[11]
আমােদর কােরারই এই ছিবটি দখা হয়িন।
** কস 3: সবসময় সঠিক কথা বেল না এবং সবসময় ভল কথা বেল না :** - যিদ সবসময় সঠিক কথা বেল না এবং সবসময় ভল কথা বেল না , তাহেল তার িববিত িমথা বা সত হেত পাের। - এই কেস , আমরা সম্ভাব সংিমশ্রণগুিল িবেষণ কির : - যিদ সবসময় ভল কথা বেল , তাহেল তার িববিত িমথা। - অথাৎ , " আমােদর কােরারই এই ছিবটি দখা হয়িন। " িমথা। - এর অথ হেলা কমপে একজন ব ছিবটি দেখেছ। - এই েত্র , আমরা দখেত...
-
[12]
None of us have seen this picture
** উপসংহার :** - সমস্ত কস িবেষণ করার পের , আমরা দখেত পাি য শুধমাত্র কস 1 এবং কস 2 সমসার শতগুিল পূরণ কের। অতএব , তােদর মেধ সবসময় সঠিক কথা বেল এমন সংখা হেলা Output: Okay, let's try to figure this out. So there are three friends sitting in front of the TV. Each of them either always tells the truth or always lies. The first person says, "None of us have seen t...
-
[13]
আমােদর কােরারই এই ছিবটি দখা হয়িন।
** সমসার িববরণ :** - িতনজন ব আেছন যারা প্রেতেকই সবসময় সঠিক কথা বেল অথবা সবসময় ভল কথা বেল। - তারা এই িববিতগুিল িদেয়েছ : - প্রথমজন : " আমােদর কােরারই এই ছিবটি দখা হয়িন। " - িতীয়জন : " আিম এই ছিবটি দেখিছ , িকন্তু তামরা দুজনই দিখিন। " - ততীয়জন : " আিম এই ছিবটি দেখিছ। " - আমােদর কােছ জানা আেছ য তােদর মেধ অন্তত একজন সবসময় সঠিক কথা বেল এবং অন্তত একজন সবসময় ভল কথা বেল।
-
[14]
** সম্ভাব ত্রগুিল িবেষণ :** - আমরা িতনজন বেক িনম্নিলিখতভােব িচিত কির : - প্রথমজন। - িতীয়জন। - ততীয়জন।
-
[15]
আিম এই ছিবটি দেখিছ , িকন্তু তামরা দুজনই দিখিন।
** ত্র 1: সবসময় সঠিক কথা বেল। ** - যিদ সবসময় সঠিক কথা বেল , তাহেল তার িববিত সত। - অথাৎ , তােদর কােরারই এই ছিবটি দখা হয়িন। - এর অথ হেলা , এবং উভেয়ই এই ছিবটি দেখিন। - তেব , বেলেছ , " আিম এই ছিবটি দেখিছ , িকন্তু তামরা দুজনই দিখিন। " যিদ সবসময় সঠিক কথা বেল , তাহেল এটি সত হেব , িকন্তু এটি িবেরািধতাবাদী কারণ বলেছ য স ছিবটি দেখেছ , িকন্তু আমরা ইিতমেধই জািন য ছিব...
-
[16]
আিম এই ছিবটি দেখিছ , িকন্তু তামরা দুজনই দিখিন।
** ত্র 2: সবসময় ভল কথা বেল। ** - যিদ সবসময় ভল কথা বেল , তাহেল তার িববিত িমথা। - অথাৎ , তােদর কােরার এই ছিবটি দখা হেয়েছ। - এর অথ হেলা , অথবা অথবা উভেয়ই এই ছিবটি দেখেছ। - ধরন সবসময় সঠিক কথা বেল। - বেলেছ , " আিম এই ছিবটি দেখিছ , িকন্তু তামরা দুজনই দিখিন। " - যিদ সবসময় সঠিক কথা বেল , তাহেল এটি সত হেব , িকন্তু এটি িবেরািধতাবাদী কারণ আমরা ইিতমেধই জািন য ছিবটি দ...
-
[17]
** উপসংহার :** - যেহত আমােদর কােছ জানা আেছ য তােদর মেধ অন্তত একজন সবসময় সঠিক কথা বেল , তাই ত্র 2 বাদ দওয়া হেয়েছ। - অতএব , শুধমাত্র ত্র 1 বধ। অতএব , তােদর মেধ ঠিক একজন সবসময় সঠিক কথা বেল। উত্তর : ১ Correct: ✅ Number of Words: 932 😔 Bengali Percentage: 7.58% 👎🏻 Correct: ❌ Number of Words: 645 🚀 Bengali Percentage: 97.63% 🚀 Correct: ✅ Number of Words: 2223 😫...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.