Recognition: no theorem link
MC²: Monte Carlo Correction for Fast Elliptic PDE Solving
Pith reviewed 2026-05-12 04:01 UTC · model grok-4.3
The pith
MC² corrects low-budget Monte Carlo PDE estimates with a neural network to match 1000× more compute accuracy
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
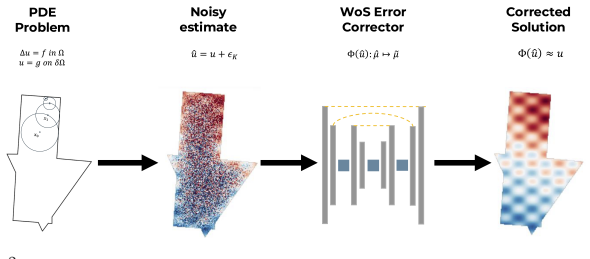
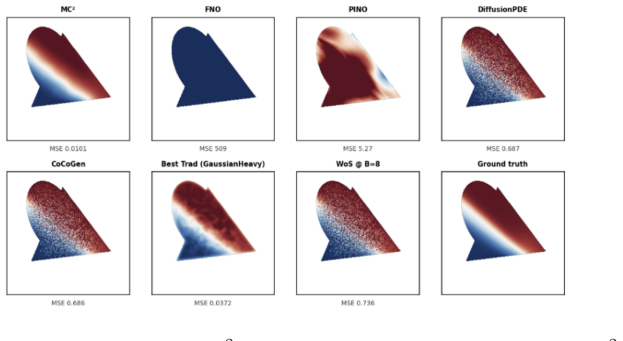
MC² treats a low-budget Monte Carlo solution as a structured estimator of the true field and learns a single-pass neural correction to recover a high-fidelity solution. This matches the accuracy of solutions using over 1000× more Monte Carlo compute and outperforms all evaluated classical, denoising, and neural-operator baselines across five elliptic PDE families and arbitrary geometric compositions.
What carries the argument
Hybrid WoS-NN solver that applies a learned neural correction to low-budget Walk-on-Spheres estimates of the solution field
Load-bearing premise
The structured error present in low-budget Monte Carlo solutions is learnable by a neural network that generalizes across five elliptic PDE families and arbitrary geometric compositions.
What would settle it
Failure of the neural correction to reach high-budget Monte Carlo accuracy on an elliptic PDE family or geometry outside the five families used for training would falsify the central claim.
Figures


read the original abstract
Partial differential equation (PDE) solvers underpin scientific computing, but real-world deployment is bounded by compute. Classical Monte Carlo solvers such as Walk-on-Spheres (WoS) are unbiased and geometry-agnostic but are slow. Learned solvers are fast but biased and brittle under distribution shift. We present \textbf{MC$^2$}, a hybrid WoS-Neural Network (WoS-NN) PDE solver that treats a low-budget Monte Carlo solution as a structured estimator of the true field and learns a single-pass neural correction to recover a high-fidelity solution. MC$^2$ matches the accuracy of solutions using over $1000\times$ more Monte Carlo compute, outperforming all evaluated classical, denoising, and neural-operator baselines. To enable reproducible study of finite-compute PDE solving, we additionally release \textbf{PDEZoo}, the largest standardized elliptic PDE benchmark to date: 2M PDEs spanning five elliptic families and unlimited geometric compositions, with analytic ground truth and multi-budget Monte Carlo trajectories. Together \textbf{MC$^2$} and \textbf{PDEZoo} (1) empirically establish that finite-sample Monte Carlo error is structured, learnable, and correctable in a single forward pass, (2) show that we can solve PDEs $\sim$\textbf{1000x} faster than with just WoS, and (3) provide the evaluation infrastructure the field has so far lacked.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MC², a hybrid PDE solver that applies a neural network correction to low-budget Walk-on-Spheres Monte Carlo solutions for elliptic problems, claiming to recover accuracy equivalent to over 1000× more Monte Carlo samples while outperforming classical, denoising, and neural-operator baselines. It additionally releases PDEZoo, a benchmark of 2M elliptic PDE instances spanning five families with analytic ground truth and multi-budget trajectories, to support reproducible evaluation of finite-compute solvers.
Significance. If the central empirical claims hold, the work demonstrates that finite-sample Monte Carlo error in elliptic PDEs is sufficiently structured to be corrected in a single forward pass, offering a practical route to fast yet accurate solvers. The release of PDEZoo with standardized analytic ground truth and multi-budget trajectories is a clear strength that addresses the field's lack of reproducible benchmarks and could enable systematic study of error learnability across operators and geometries.
major comments (2)
- [§5 (Experiments) and abstract] §5 (Experiments) and abstract: The headline claim that a single network trained on PDEZoo recovers high-fidelity solutions for arbitrary geometric compositions across five PDE families is load-bearing for the 1000× speedup and outperformance assertions, yet the reported tests do not include explicit out-of-distribution evaluation on topologies or coefficient heterogeneities materially different from the training distribution (e.g., multiply-connected domains or sharp coefficient jumps); without such controls the generalization risk identified in the stress-test note remains unaddressed.
- [Table 3 (baseline comparison)] Table 3 (or equivalent baseline comparison table): The reported accuracy gains versus neural-operator and high-budget WoS baselines are presented without per-instance error distributions or statistical significance tests across the full 2M set; this makes it difficult to verify that the correction consistently closes the gap rather than succeeding only on average or on in-distribution subsets.
minor comments (2)
- [§3 (Method)] §3 (Method): The precise encoding of the low-budget WoS field into the correction network (grid sampling, point cloud, or implicit representation) and any associated invariance properties should be stated explicitly to clarify how geometry-agnostic behavior is achieved.
- [Figures] Figure captions: Several figures showing PDE solutions would benefit from explicit labels indicating the Monte Carlo sample budget used for the input field and the corresponding error norm relative to analytic ground truth.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline planned revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§5 (Experiments) and abstract] The headline claim that a single network trained on PDEZoo recovers high-fidelity solutions for arbitrary geometric compositions across five PDE families is load-bearing for the 1000× speedup and outperformance assertions, yet the reported tests do not include explicit out-of-distribution evaluation on topologies or coefficient heterogeneities materially different from the training distribution (e.g., multiply-connected domains or sharp coefficient jumps); without such controls the generalization risk identified in the stress-test note remains unaddressed.
Authors: We acknowledge the referee's point that explicit OOD testing on multiply-connected domains and sharp coefficient discontinuities would more rigorously substantiate the generalization claims. PDEZoo's training and test splits already incorporate substantial geometric diversity and coefficient variations within the five families, and the stress-test note in the manuscript flags related risks. To directly address this, we will add a new subsection in §5 with dedicated OOD experiments on multiply-connected domains and sharp jumps, reporting errors relative to high-budget WoS and neural-operator baselines. revision: yes
-
Referee: [Table 3 (baseline comparison)] The reported accuracy gains versus neural-operator and high-budget WoS baselines are presented without per-instance error distributions or statistical significance tests across the full 2M set; this makes it difficult to verify that the correction consistently closes the gap rather than succeeding only on average or on in-distribution subsets.
Authors: We agree that per-instance distributions and formal significance testing would improve verifiability of consistent gains. The current Table 3 reports mean errors with standard deviations over the test sets. In revision we will expand the table and associated text to include per-instance error histograms (or violin plots) across the full 2M instances and add paired statistical tests (e.g., Wilcoxon signed-rank) to quantify that MC² improvements are significant and not confined to averages or in-distribution subsets. revision: yes
Circularity Check
No circularity; empirical hybrid solver with independent benchmark validation
full rationale
The paper's derivation chain consists of an empirical proposal: train a neural network on low-budget Walk-on-Spheres trajectories paired with analytic ground truth from the released PDEZoo dataset to learn a single-pass correction. All headline claims (1000× speedup, outperformance vs. baselines) are established by direct comparison on held-out PDE instances across five families and arbitrary geometries, not by any equation that reduces to its own inputs, a fitted parameter renamed as prediction, or a self-citation chain. No uniqueness theorems, ansatzes, or renamings of known results are invoked; the work is self-contained against external benchmarks and does not rely on prior author results for its central premise.
Axiom & Free-Parameter Ledger
free parameters (2)
- Monte Carlo sample budget
- neural network weights
axioms (1)
- standard math Elliptic PDEs admit unique solutions given suitable boundary conditions
Reference graph
Works this paper leans on
-
[1]
Jens Berg and Kaj Nyström. A unified deep artificial neural network approach to partial differential equations in complex geometries.Neurocomputing, 317:28–41, 2018
work page 2018
-
[2]
The rate of convergence of the Walk on Spheres algorithm
Ilia Binder and Mark Braverman. The rate of convergence of the Walk on Spheres algorithm. Geometric and Functional Analysis, 22(3):558–587, 2012. doi: 10.1007/s00039-012-0161-z
-
[3]
Mario Botsch, Leif Kobbelt, Mark Pauly, Pierre Alliez, and Bruno Lévy.Polygon Mesh Processing. CRC Press, 2010
work page 2010
-
[4]
Susanne Brenner and Ridgway Scott.The Mathematical Theory of Finite Element Methods. Springer, 3rd edition, 2008
work page 2008
-
[5]
Briggs, Van Emden Henson, and Steve F
William L. Briggs, Van Emden Henson, and Steve F. McCormick.A Multigrid Tutorial. SIAM, 2nd edition, 2000
work page 2000
-
[6]
Digital geometry processing with discrete exterior calculus.ACM SIGGRAPH 2013 Courses, 2013
Keenan Crane, Fernando de Goes, Mathieu Desbrun, and Peter Schröder. Digital geometry processing with discrete exterior calculus.ACM SIGGRAPH 2013 Courses, 2013
work page 2013
-
[7]
Salvatore Cuomo, Vincenzo Schiano Di Cola, Fabio Giampaolo, Gianluigi Rozza, Maziar Raissi, and Francesco Piccialli. Scientific machine learning through physics–informed neural networks: Where we are and what’s next.Journal of Scientific Computing, 92(3):88, 2022
work page 2022
-
[8]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large- scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255. IEEE, 2009. doi: 10.1109/CVPR.2009.5206848
-
[9]
Data science at the singularity.Harvard Data Science Review, 6(1), 2024
David Donoho. Data science at the singularity.Harvard Data Science Review, 6(1), 2024. doi: 10.1162/99608f92.b91339ef
-
[10]
SUNet: Swin transformer UNet for image denoising
Chi-Mao Fan, Tsung-Jung Liu, and Kuan-Hsien Liu. SUNet: Swin transformer UNet for image denoising. In2022 IEEE International Symposium on Circuits and Systems (ISCAS). IEEE, May 2022. doi: 10.1109/iscas48785.2022.9937486
-
[11]
Neural networks and the bias/variance dilemma.Neural Computation, 4(1):1–58, 1992
Stuart Geman, Elíe Bienenstock, and René Doursat. Neural networks and the bias/variance dilemma.Neural Computation, 4(1):1–58, 1992
work page 1992
-
[12]
Towards multi-spatiotemporal-scale generalized pde modeling.arXiv preprint arXiv:2209.15616, 2022
Jayesh K. Gupta and Johannes Brandstetter. Towards multi-spatiotemporal-scale generalized pde modeling.arXiv preprint arXiv:2209.15616, 2022
-
[13]
Trevor Hastie, Robert Tibshirani, and Jerome Friedman.The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer, 2 edition, 2009
work page 2009
-
[14]
Po- seidon: Efficient foundation models for pdes
Maximilian Herde, Nils Wandel, Siddhartha Mishra, Nils Thuerey, and Bogdan Raonic. Po- seidon: Efficient foundation models for pdes. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[15]
Physics-embedded neural networks: Graph neural pde solvers with mixed boundary conditions
Masanobu Horie and Naoto Mitsume. Physics-embedded neural networks: Graph neural pde solvers with mixed boundary conditions. InAdvances in Neural Information Processing Systems, volume 35, pages 23218–23229. Curran Associates, Inc., 2022
work page 2022
-
[16]
Jiahe Huang, Guandao Yang, Zichen Wang, and Jeong Joon Park. Diffusionpde: Generative pde-solving under partial observation.Advances in Neural Information Processing Systems, 37: 130291–130323, 2024
work page 2024
-
[17]
Christian Jacobsen, Yilin Zhuang, and Karthik Duraisamy. Cocogen: Physically consistent and conditioned score-based generative models for forward and inverse problems.SIAM Journal on Scientific Computing, 2024
work page 2024
-
[18]
Zichao Jiang, Junyang Jiang, Qinghe Yao, and Gengchao Yang. A neural network-based pde solving algorithm with high precision.Scientific Reports, 13(1):4479, 2023
work page 2023
-
[19]
Guoliang Jin, Lin Chen, and Jiamei Dong. Monte carlo finite element method of structure reliability analysis.Reliability Engineering & System Safety, 40(1), 1993. doi: 10.1016/ 0951-8320(93)90121-E. 10
work page 1993
-
[20]
Denoising diffusion restoration models
Bahjat Kawar, Michael Elad, Stefano Ermon, and Jiaming Song. Denoising diffusion restoration models. InAdvances in Neural Information Processing Systems, volume 35, pages 23593–23606, 2022
work page 2022
-
[21]
Yuehaw Khoo, Jianfeng Lu, and Lexing Ying. Solving parametric pde problems with artificial neural networks.European Journal of Applied Mathematics, 32(3):421–435, 2021
work page 2021
-
[22]
Erich L Lehmann and George Casella.Theory of Point Estimation. Springer, 2 edition, 1998
work page 1998
-
[23]
Neural caches for monte carlo partial differential equation solvers
Zilu Li, Guandao Yang, Xi Deng, Christopher De Sa, Bharath Hariharan, and Steve Marschner. Neural caches for monte carlo partial differential equation solvers. InSIGGRAPH Asia 2023 Conference Papers, SA ’23. Association for Computing Machinery, 2023. doi: 10.1145/ 3610548.3618141
-
[24]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, Burigede liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. InInternational Conference on Learning Representations, 2021. URLhttps://openreview.net/forum?id=c8P9NQVtmnO
work page 2021
-
[25]
arXiv preprint arXiv:2111.03794 , year =
Zongyi Li, Hongkai Zheng, Nikola B. Kovachki, David Jin, Haoxuan Chen, Burigede Liu, Kamyar Azizzadenesheli, and Anima Anandkumar. Physics-informed neural operator for learning partial differential equations.CoRR, abs/2111.03794, 2021. URL https://arxiv. org/abs/2111.03794
-
[26]
Michael Mascagni and Chi-Ok Hwang. ϵ-Shell error analysis for “Walk On Spheres” algorithms. Mathematics and Computers in Simulation, 63(2):93–104, 2003. doi: 10.1016/S0378-4754(03) 00038-7
-
[27]
M. Muller. Some continuous monte carlo methods for the dirichlet problem.Ann. Math. Statist., 27(3), 1956
work page 1956
-
[28]
Maziar Raissi, Paris Perdikaris, and George Em Karniadakis. Physics informed deep learning (part i): Data-driven solutions of nonlinear partial differential equations, 2017
work page 2017
-
[29]
Challenges in training PINNs: A loss landscape perspective, 2024
Pratik Rathore, Weimu Lei, Zachary Frangella, Lu Lu, and Madeleine Udell. Challenges in training PINNs: A loss landscape perspective, 2024
work page 2024
-
[30]
Rohan Sawhney and Keenan Crane. Monte carlo geometry processing: A grid-free approach to pde-based methods on volumetric domains.ACM Trans. Graph., 39(4), 2020
work page 2020
-
[31]
Rohan Sawhney, Dario Seyb, Wojciech Jarosz, and Keenan Crane. Grid-free monte carlo for pdes with spatially varying coefficients.ACM Trans. Graph., 41(4), July 2022. ISSN 0730-0301. doi: 10.1145/3528223.3530134
-
[32]
Walk on stars: A grid-free monte carlo method for pdes with neumann boundary conditions.ACM Trans
Rohan Sawhney, Dario Seyb, Wojciech Jarosz, and Keenan Crane. Walk on stars: A grid-free monte carlo method for pdes with neumann boundary conditions.ACM Trans. Graph., 2023
work page 2023
-
[33]
Ryusuke Sugimoto, Terry Chen, Yiti Jiang, Christopher Batty, and Toshiya Hachisuka. A practical walk-on-boundary method for boundary value problems.ACM Transactions on Graphics, 42(4):1–16, July 2023. ISSN 1557-7368. doi: 10.1145/3592109
-
[34]
Pdebench: An extensive benchmark for scientific machine learning
Makoto Takamoto, Timothy Praditia, Raphael Leiteritz, Daniel MacKinlay, Francesco Alesiani, Dirk Pflüger, and Mathias Niepert. Pdebench: An extensive benchmark for scientific machine learning. InNeurIPS Datasets and Benchmarks Track, 2022
work page 2022
-
[35]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 353–355, Brussels, Belgium, 2018. Association for Computational Linguis...
-
[36]
Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. SuperGLUE: A stickier benchmark for general-purpose language understanding systems. InAdvances in Neural Information Processing Systems, volume 32, 2019. 11
work page 2019
-
[37]
Sifan Wang, Xinling Yu, and Paris Perdikaris. When and why pinns fail to train: A neural tangent kernel perspective.Journal of Computational Physics, 449:110768, 2022
work page 2022
-
[38]
Monte carlo neural pde solver for learning pdes via probabilistic representation, 2023
Rui Zhang, Qi Meng, Rongchan Zhu, Yue Wang, Wenlei Shi, Shihua Zhang, Zhi-Ming Ma, and Tie-Yan Liu. Monte carlo neural pde solver for learning pdes via probabilistic representation, 2023. A PDEZoo: Detailed Specifications A.1 Solution Atom Types Each solution u(x, y) is constructed as a sum of n randomly chosen atoms, where n is sampled uniformly from [2,...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.