Recognition: 2 theorem links
· Lean TheoremReinforcement Learning Measurement Model
Pith reviewed 2026-05-12 02:28 UTC · model grok-4.3
The pith
The RLMM scales psychometric measurement of sequential decisions to larger tasks by sharing a parametric action-value function across individuals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
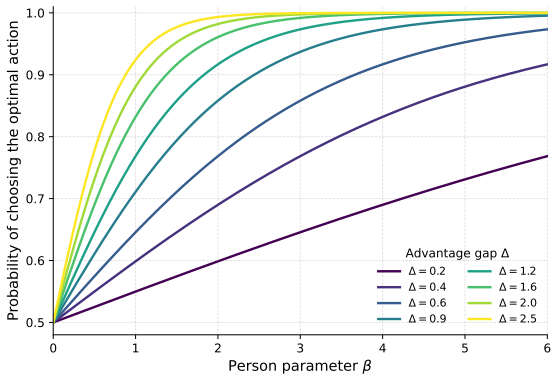
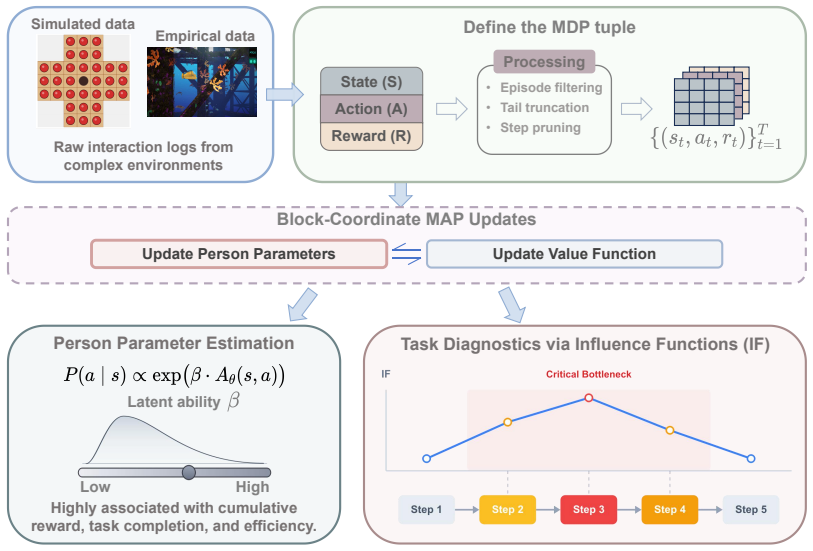
The RLMM combines a Boltzmann choice rule with normalized advantages, a soft Bellman consistency penalty, and block-coordinate MAP estimation around a shared parametric action-value function, yielding stable person parameters and step-level influence diagnostics while extending decision-process measurement to larger, more realistic environments.
What carries the argument
The shared parametric action-value function that encodes task structure independently of any one person's parameters.
If this is right
- Estimation becomes feasible for tasks whose state spaces exceed what per-person tables can handle.
- Step-level influence diagnostics identify which decisions most affect the measured trait.
- The resulting person parameter remains interpretable as a decision-quality trait linked to observable performance.
Where Pith is reading between the lines
- The decoupling could support transfer of the learned value function to new but structurally similar tasks.
- Hierarchical extensions might add group-level structure without sacrificing the scaling benefit.
- The same machinery could be tested on other sequential environments such as educational simulations or training logs.
Load-bearing premise
A single shared parametric action-value function can capture the essential task structure for all individuals without needing large person-specific deviations.
What would settle it
Run the RLMM and the original MDP-MM on peg-solitaire boards with increasing state-space size and check whether accuracy or runtime advantages disappear; or test whether the estimated person parameters lose their positive association with reward and efficiency on new held-out gameplay logs.
Figures









read the original abstract
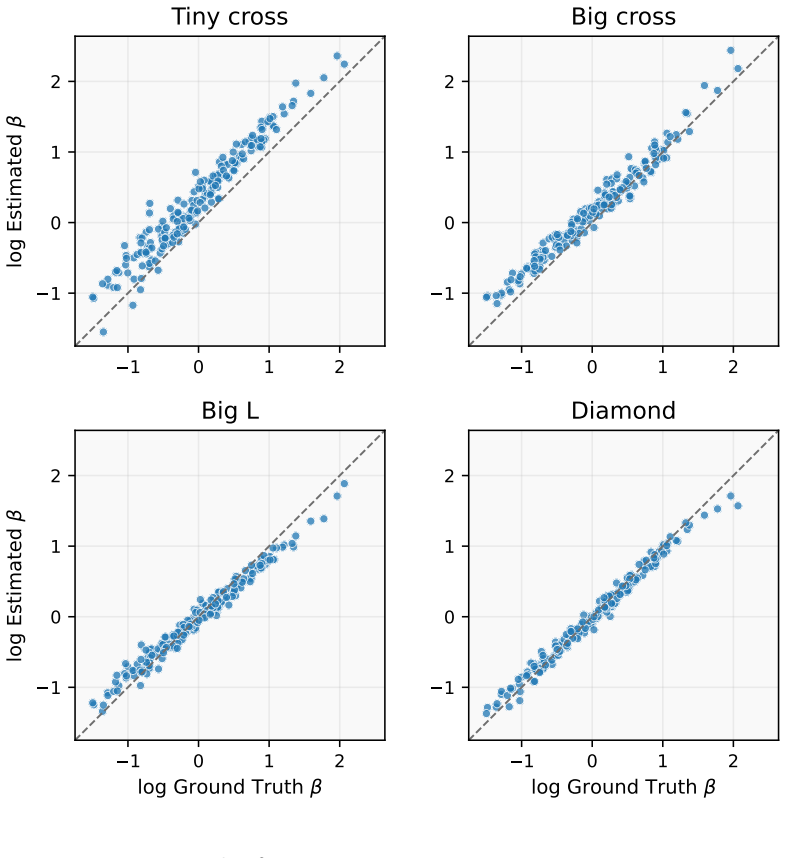
Interactive assessments generate sequential process data that are not well handled by conventional item response models. Existing MDP-based measurement approaches, such as the Markov decision process measurement model (MDP-MM, LaMar, 2018), link action choices to state-action values, but their reliance on person-specific tabular value functions makes them difficult to scale beyond small, fully enumerated tasks. We propose the Reinforcement Learning Measurement Model (RLMM), a measurement framework that decouples person-level choice sensitivity from task-level value representation through a shared parametric action-value function, making estimation more computationally efficient for larger process-data settings. The model combines a Boltzmann choice rule with normalized advantages, a soft Bellman consistency penalty, and a block-coordinate MAP procedure for joint estimation, while also yielding step-level influence diagnostics for identifying behaviorally critical decisions. In peg-solitaire simulations, the RLMM achieved higher estimation accuracy and substantially lower runtime than the original MDP-MM, with advantages increasing as task complexity grew. In AQUALAB gameplay logs, the estimated person parameter was positively associated with cumulative reward, task completion, and behavioral efficiency. These results show that the RLMM extends decision-process-based psychometric models to larger and more behaviorally realistic environments while preserving an interpretable latent trait tied to decision making steps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Reinforcement Learning Measurement Model (RLMM) as an extension of the MDP-MM for sequential process data in interactive assessments. It decouples person-specific choice sensitivity (via Boltzmann rule with normalized advantages) from a shared parametric action-value function Q(s,a; θ), incorporates a soft Bellman consistency penalty, and uses block-coordinate MAP estimation. Simulations on peg-solitaire tasks show higher estimation accuracy and lower runtime than the original MDP-MM, with gains increasing in task complexity. In AQUALAB gameplay logs, the estimated person parameter correlates positively with cumulative reward, task completion, and behavioral efficiency. The model also provides step-level influence diagnostics.
Significance. If the homogeneity assumption holds and estimation is properly validated, the RLMM offers a scalable framework for psychometric modeling of decision processes in larger environments while preserving an interpretable latent trait. The computational efficiency improvements, simulation comparisons to MDP-MM, and provision of step-level diagnostics are concrete strengths that could advance the field beyond small tabular tasks.
major comments (3)
- [Section 4 (Estimation procedure)] Section 4 (Estimation procedure): The block-coordinate MAP jointly estimates person parameters and the shared Q-function parameters on the same data. This creates a risk that the positive associations reported in the AQUALAB analysis (Section 5.2) between the person parameter and outcomes such as cumulative reward partly reflect the optimization objective rather than independent validation of the latent trait.
- [Section 3.1 (Model formulation)] Section 3.1 (Model formulation): The central modeling choice of a single shared parametric Q(s,a; θ) assumes homogeneous task structure across individuals, with individual differences captured only by the scalar sensitivity parameter. No diagnostic or sensitivity check is provided for person-specific deviations in value representation; if violated, this could bias the person parameter estimates, undermining the simulation accuracy claims where data are generated under the model.
- [Section 5.1 (Peg-solitaire simulations)] Section 5.1 (Peg-solitaire simulations): The reported higher estimation accuracy and runtime advantages lack details on exact parameter counts, quantitative error metrics (e.g., bias or RMSE), data exclusion rules, and whether comparisons are out-of-sample. Without these, it is difficult to evaluate whether the advantages over MDP-MM are robust or partly due to optimization choices.
minor comments (2)
- [Section 3] The abstract and Section 3 mention normalized advantages and the soft Bellman penalty; explicit equations for these components would improve clarity and allow readers to verify the consistency penalty implementation.
- [Section 5.2] Section 5.2 would benefit from reporting the exact sample size, any preprocessing steps for AQUALAB logs, and whether the reported correlations are Pearson or Spearman to facilitate interpretation.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important considerations for the clarity and robustness of our proposed RLMM framework. We address each major comment below and will revise the manuscript to incorporate clarifications and additional analyses where appropriate.
read point-by-point responses
-
Referee: [Section 4 (Estimation procedure)] Section 4 (Estimation procedure): The block-coordinate MAP jointly estimates person parameters and the shared Q-function parameters on the same data. This creates a risk that the positive associations reported in the AQUALAB analysis (Section 5.2) between the person parameter and outcomes such as cumulative reward partly reflect the optimization objective rather than independent validation of the latent trait.
Authors: We acknowledge the validity of this concern. Because the person-specific sensitivity parameter is estimated jointly with the shared Q-function parameters via block-coordinate MAP on the same data, the reported correlations with external performance metrics could partly arise from the optimization process rather than purely reflecting an independent latent trait. The outcomes themselves (cumulative reward, task completion) are observed directly from the logs and not generated by the model, but this does not fully eliminate the dependence. In the revised manuscript we will add an explicit discussion of this limitation in Section 5.2 and will explore, where computationally feasible, a supplementary analysis that holds out a subset of trials for validating the person parameters after fitting on the remainder. revision: yes
-
Referee: [Section 3.1 (Model formulation)] Section 3.1 (Model formulation): The central modeling choice of a single shared parametric Q(s,a; θ) assumes homogeneous task structure across individuals, with individual differences captured only by the scalar sensitivity parameter. No diagnostic or sensitivity check is provided for person-specific deviations in value representation; if violated, this could bias the person parameter estimates, undermining the simulation accuracy claims where data are generated under the model.
Authors: The referee correctly identifies that the RLMM deliberately imposes a homogeneous parametric Q-function across persons, with all individual differences channeled through the scalar sensitivity parameter. This choice is central to the model's scalability relative to person-specific tabular representations. The simulation results in Section 5.1 are generated exactly under the model's assumptions, so the reported accuracy gains are conditional on that data-generating process. In real data, unmodeled person-specific deviations in value representation would constitute model misspecification and could bias the sensitivity estimates. We will revise the manuscript to include a brief sensitivity discussion and, if space permits, a simple diagnostic (e.g., person-level residual analysis or comparison against a more flexible baseline) to help readers assess the homogeneity assumption. revision: yes
-
Referee: [Section 5.1 (Peg-solitaire simulations)] Section 5.1 (Peg-solitaire simulations): The reported higher estimation accuracy and runtime advantages lack details on exact parameter counts, quantitative error metrics (e.g., bias or RMSE), data exclusion rules, and whether comparisons are out-of-sample. Without these, it is difficult to evaluate whether the advantages over MDP-MM are robust or partly due to optimization choices.
Authors: We agree that the simulation section would benefit from greater quantitative transparency. The current text states qualitative improvements without supplying the precise figures the referee requests. In the revised manuscript we will expand Section 5.1 to report: (i) the exact number of free parameters for both RLMM and MDP-MM under each task size, (ii) bias and RMSE values for the recovered person and Q-function parameters, (iii) any data-exclusion criteria applied, and (iv) explicit confirmation that the reported comparisons are in-sample (as is standard for recovery simulations) together with any supplementary out-of-sample checks performed. revision: yes
Circularity Check
No significant circularity detected in derivation or claims
full rationale
The RLMM framework is defined by decoupling a scalar person sensitivity parameter from a shared parametric Q-function via the Boltzmann rule with normalized advantages, plus a soft Bellman penalty and block-coordinate MAP estimation. These are standard modeling choices presented as an extension of MDP-MM rather than a derivation that reduces to its own inputs. Simulation accuracy comparisons and real-data correlations between estimated person parameters and external outcomes (reward, completion) are reported as empirical results, not as first-principles predictions or quantities forced by construction. No self-citations, uniqueness theorems, or ansatz smuggling appear in the provided text, and the central modeling steps remain independent of the target associations.
Axiom & Free-Parameter Ledger
free parameters (2)
- person-specific choice sensitivity parameter
- parameters of the shared action-value function
axioms (2)
- domain assumption Boltzmann choice rule governs action selection given value estimates
- domain assumption Soft Bellman consistency holds approximately for the estimated values
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearshared parametric action-value function Qθ(s,a) ... centered and globally normalized ... soft Bellman consistency penalty ... block-coordinate MAP
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearBoltzmann choice rule with normalized advantages ... person parameter βj
Reference graph
Works this paper leans on
-
[1]
Multivariate Behavioral Research , year =
Liang, Kangjun and Tu, Dongbo and Cai, Yan , title =. Multivariate Behavioral Research , year =
-
[2]
Zhan, Peida and Qiao, Xin , title =. Psychometrika , year =. doi:10.1007/s11336-022-09855-9 , publisher =
-
[3]
British Journal of Mathematical and Statistical Psychology , year =
Zhan, Peida and Jiao, Hong and Liao, Dandan , title =. British Journal of Mathematical and Statistical Psychology , year =
-
[4]
Wang, Shiyu and Chen, Yinghan , title =. Psychometrika , year =. doi:10.1007/s11336-020-09717-2 , publisher =
-
[5]
and Malone, Jonathan , title =
Zhan, Peida and Man, Kaiwen and Wind, Stefanie A. and Malone, Jonathan , title =. Journal of Educational and Behavioral Statistics , year =
-
[6]
Frontiers in Psychology , year =
Zhang, Jiwei and Lu, Jing and Yang, Jing and Zhang, Zhaoyuan and Sun, Shanshan , title =. Frontiers in Psychology , year =
-
[7]
British Journal of Mathematical and Statistical Psychology , year =
Liao, Manqian and Jiao, Hong , title =. British Journal of Mathematical and Statistical Psychology , year =
-
[8]
Journal of Educational and Behavioral Statistics , year =
Wei, Junhuan and Luo, Liufen and Cai, Yan and Tu, Dongbo , title =. Journal of Educational and Behavioral Statistics , year =
-
[9]
Behavior Research Methods , year =
Han, Yuting and Ji, Feng and Wang, Pujue and Liu, Hongyun , title =. Behavior Research Methods , year =. doi:10.3758/s13428-025-02658-7 , publisher =
-
[10]
Multivariate Behavioral Research , year =
Han, Yuting and Liu, Hongyun and Ji, Feng , title =. Multivariate Behavioral Research , year =
-
[11]
Han, Yuting and Ji, Feng and Chen, Yunxiao and Gan, Kaiyu and Liu, Hongyun , year =. Analyzing Group Differences and Measurement Fairness in Process Data: A Sequential Response Model With Covariates , volume =. Methodology , doi =
-
[12]
Journal of Educational and Behavioral Statistics , year =
Han, Yuting and Wang, Pujue and Ji, Feng and Liu, Hongyun , title =. Journal of Educational and Behavioral Statistics , year =
-
[13]
Behavior Research Methods , year =
Fu, Yanbin and Zhan, Peida and Chen, Qipeng and Jiao, Hong , title =. Behavior Research Methods , year =. doi:10.3758/s13428-023-02178-2 , publisher =
-
[14]
British Journal of Mathematical and Statistical Psychology , year =
Xu, Haochen and Fang, Guanhua and Ying, Zhiliang , title =. British Journal of Mathematical and Statistical Psychology , year =
-
[15]
Kang, Hyeon-Ah , title =. Psychometrika , year =. doi:10.1017/psy.2025.10029 , publisher =
-
[16]
Chen, Yunxiao , title =. Psychometrika , year =. doi:10.1007/s11336-020-09734-1 , publisher =
- [17]
-
[18]
Markov decision process measurement model , author=. Psychometrika , volume=. 2018 , publisher=
work page 2018
- [19]
-
[20]
Statistical Theories of Mental Test Scores , editor =
Birnbaum, Allan , title =. Statistical Theories of Mental Test Scores , editor =. 1968 , pages =
work page 1968
- [21]
-
[22]
Darrell and Aitkin, Murray , title =
Bock, R. Darrell and Aitkin, Murray , title =. Psychometrika , year =
- [23]
-
[24]
Ramanarayanan, Vikram and LaMar, Michelle. Toward Automatically Measuring Learner Ability from Human-Machine Dialog Interactions using Novel Psychometric Models. Proceedings of the Thirteenth Workshop on Innovative Use of NLP for Building Educational Applications. 2018. doi:10.18653/v1/W18-0512
-
[25]
Rafferty, Anna N. and LaMar, Michelle M. and Griffiths, Thomas L. Inferring learners' knowledge from their actions. Cognitive Science. 2015. doi:10.1111/cogs.12157
-
[26]
Baker and Rebecca Saxe and Joshua B
Chris L. Baker and Rebecca Saxe and Joshua B. Tenenbaum , editor =. Bayesian Theory of Mind: Modeling Joint Belief-Desire Attribution , booktitle =. 2011 , url =
work page 2011
-
[27]
Wake: Tales from the Aqualab Gameplay Logs , year =
-
[28]
Gagnon, David J. and Swanson, Luke , title =. Serious Games , editor =. 2023 , doi =
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.