Recognition: unknown
Building a Precise Video Language with Human-AI Oversight
Pith reviewed 2026-05-10 00:34 UTC · model grok-4.3
The pith
A structured video description language refined by human critique lets open models outperform closed-source systems like Gemini-3.1-Pro on precise captioning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a precise, human-curated specification for video content combined with critique-based human-AI oversight produces captions accurate enough to train open-source models that surpass closed-source models such as Gemini-3.1-Pro, and that the same captions enable video generation models to follow detailed prompts with improved control over camera motion, angle, lens, focus, point of view, and framing.
What carries the argument
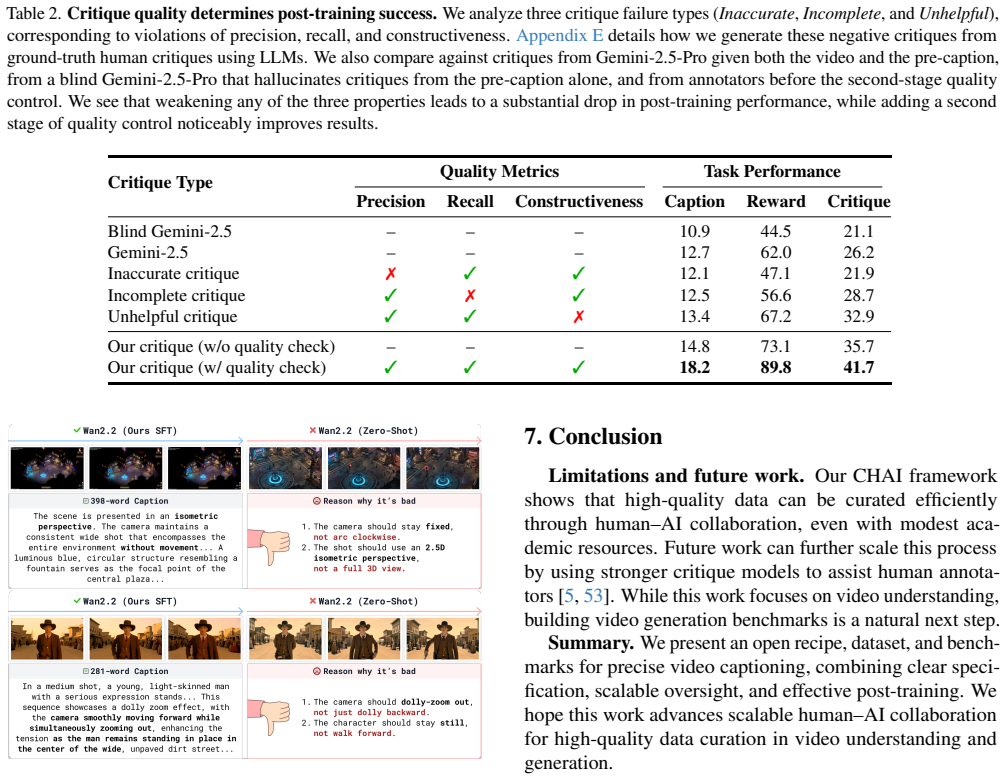
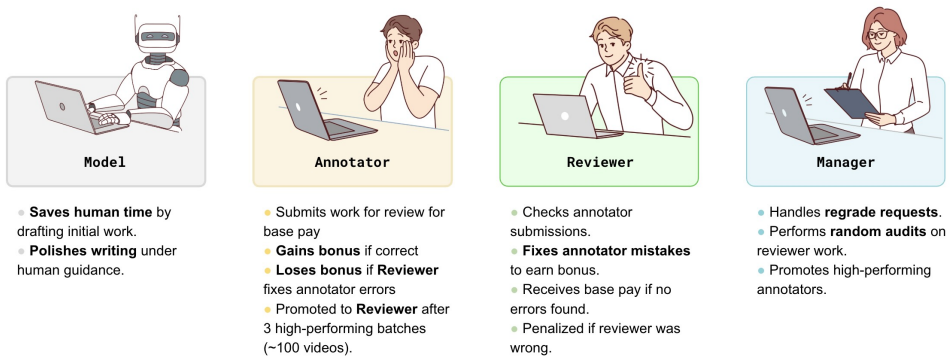
The CHAI framework: models generate pre-captions from a structured specification of hundreds of visual primitives, experts critique them to produce post-captions, and the resulting pairs plus preferences supply supervision for SFT, DPO, and inference-time scaling.
If this is right
- Higher critique quality in precision, recall, and constructiveness produces correspondingly better captioning, reward modeling, and critique generation in the downstream models.
- The same re-captioned professional footage can be used to fine-tune video generators for longer, more controllable prompts up to 400 words.
- Open models can reach professional-level performance on video understanding and generation with only modest amounts of expert supervision.
- The division of labor between model text generation and human verification improves annotation efficiency while raising final caption accuracy.
Where Pith is reading between the lines
- The same primitive-based specification and critique loop could be extended to audio tracks or 3D scene descriptions if equivalent primitives are defined.
- Once the initial specification and critique pipeline is built, the cost of scaling high-quality video data may drop because most of the text generation is off-loaded to models.
- Widespread adoption of this style of precise video language would make it easier to audit and correct generative video systems for unwanted cinematic biases or omissions.
Load-bearing premise
That the fixed set of visual primitives captures every necessary video detail without systematic omission or bias and that the experts' critiques are consistently accurate and transferable beyond the videos they reviewed.
What would settle it
Apply the trained model to a fresh collection of professional videos never seen during captioning or critique collection and measure whether human raters still judge its captions more precise and complete than those from Gemini-3.1-Pro.
Figures




































read the original abstract
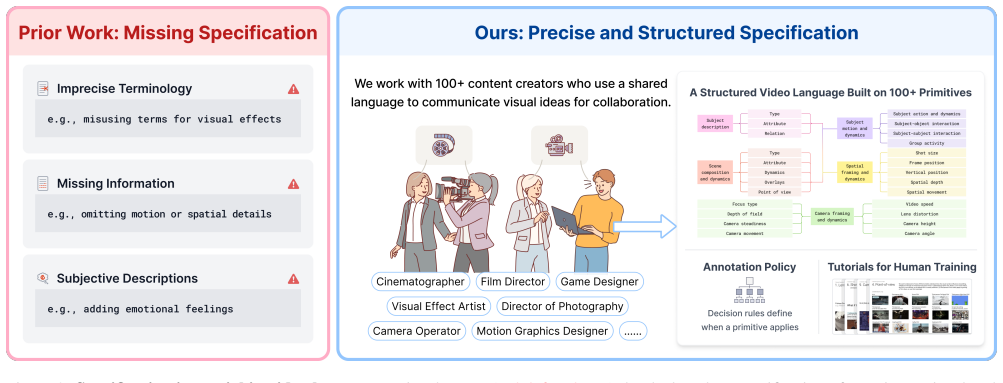
Video-language models (VLMs) learn to reason about the dynamic visual world through natural language. We introduce a suite of open datasets, benchmarks, and recipes for scalable oversight that enable precise video captioning. First, we define a structured specification for describing subjects, scenes, motion, spatial, and camera dynamics, grounded by hundreds of carefully defined visual primitives developed with professional video creators such as filmmakers. Next, to curate high-quality captions, we introduce CHAI (Critique-based Human-AI Oversight), a framework where trained experts critique and revise model-generated pre-captions into improved post-captions. This division of labor improves annotation accuracy and efficiency by offloading text generation to models, allowing humans to better focus on verification. Additionally, these critiques and preferences between pre- and post-captions provide rich supervision for improving open-source models (Qwen3-VL) on caption generation, reward modeling, and critique generation through SFT, DPO, and inference-time scaling. Our ablations show that critique quality in precision, recall, and constructiveness, ensured by our oversight framework, directly governs downstream performance. With modest expert supervision, the resulting model outperforms closed-source models such as Gemini-3.1-Pro. Finally, we apply our approach to re-caption large-scale professional videos (e.g., films, commercials, games) and fine-tune video generation models such as Wan to better follow detailed prompts of up to 400 words, achieving finer control over cinematography including camera motion, angle, lens, focus, point of view, and framing. Our results show that precise specification and human-AI oversight are key to professional-level video understanding and generation. Data and code are available on our project page: https://linzhiqiu.github.io/papers/chai/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a structured specification for video descriptions grounded in hundreds of visual primitives developed with professional filmmakers, along with the CHAI (Critique-based Human-AI Oversight) framework. In CHAI, experts critique and revise model-generated pre-captions into higher-quality post-captions; the resulting preference data is used for SFT and DPO training of open VLMs (e.g., Qwen3-VL) on captioning, reward modeling, and critique generation. Ablations link critique quality (precision, recall, constructiveness) to downstream gains. The approach is applied to re-caption professional videos and fine-tune video generation models (e.g., Wan) for detailed 400-word prompts controlling cinematography. The central claim is that precise specification plus modest human-AI oversight enables professional-level video understanding and generation, with the resulting open model outperforming Gemini-3.1-Pro.
Significance. If the empirical claims hold under rigorous evaluation, the work is significant for providing open datasets, benchmarks, and reproducible recipes that demonstrate scalable oversight can yield open models competitive with or superior to closed frontier systems. The release of data and code, the involvement of professional video creators in defining primitives, and the explicit separation of generation from verification in CHAI are strengths that support reproducibility and broader adoption in video-language research.
major comments (3)
- Experimental results section: the claim that the final model outperforms Gemini-3.1-Pro is central to the paper's contribution, yet the manuscript provides no quantitative metrics (e.g., human preference scores, automatic metrics, or exact evaluation protocol), dataset splits, or statistical tests in the main text or tables, preventing verification of the outperformance and its attribution to CHAI rather than other factors such as data volume or base model choice.
- Ablations subsection: the statement that critique quality in precision, recall, and constructiveness 'directly governs' downstream performance is load-bearing for the oversight framework's value, but the experiments do not appear to isolate this variable from confounds such as total annotation time, expert training, or the specific pre-caption model used; a controlled comparison holding other factors fixed is required.
- Video generation fine-tuning section: the application to Wan for 400-word prompts claims finer control over camera motion, angle, lens, etc., but no quantitative metrics (e.g., user study win rates or automated cinematography adherence scores) versus the base Wan model or other baselines are reported, weakening the claim that the approach transfers to generation.
minor comments (3)
- Abstract: the expansion of CHAI is given only in the body; repeating the full name on first use in the abstract would improve readability.
- Notation: the manuscript uses 'pre-captions' and 'post-captions' without a dedicated definition table or figure illustrating the CHAI loop; adding such a diagram would clarify the division of labor.
- References: several standard video captioning benchmarks (e.g., ActivityNet Captions, MSR-VTT) are mentioned but not compared against in the evaluation; adding a brief related-work discussion would situate the new datasets.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments identify important areas where the manuscript can be strengthened for clarity and rigor. We address each major comment point-by-point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: Experimental results section: the claim that the final model outperforms Gemini-3.1-Pro is central to the paper's contribution, yet the manuscript provides no quantitative metrics (e.g., human preference scores, automatic metrics, or exact evaluation protocol), dataset splits, or statistical tests in the main text or tables, preventing verification of the outperformance and its attribution to CHAI rather than other factors such as data volume or base model choice.
Authors: We agree that the main text should contain the supporting quantitative evidence rather than relying primarily on the appendix and project page. We will revise the experimental results section to include a consolidated table with human preference win rates, automatic metrics (CIDEr, SPICE), the precise evaluation protocol (including rater instructions, number of raters, and inter-annotator agreement), dataset splits, and statistical tests. This will make the attribution to the CHAI framework more transparent by also showing the base-model ablation. revision: yes
-
Referee: Ablations subsection: the statement that critique quality in precision, recall, and constructiveness 'directly governs' downstream performance is load-bearing for the oversight framework's value, but the experiments do not appear to isolate this variable from confounds such as total annotation time, expert training, or the specific pre-caption model used; a controlled comparison holding other factors fixed is required.
Authors: We acknowledge the need for tighter isolation. While our existing ablations already hold annotation time roughly constant and use the same pre-caption model, we will add a new controlled experiment that fixes the expert pool, time budget, and pre-caption source while systematically varying only critique quality (via graduated training levels and simulated low-quality critiques). The revised ablations subsection will present these results to more convincingly demonstrate the causal link. revision: yes
-
Referee: Video generation fine-tuning section: the application to Wan for 400-word prompts claims finer control over camera motion, angle, lens, etc., but no quantitative metrics (e.g., user study win rates or automated cinematography adherence scores) versus the base Wan model or other baselines are reported, weakening the claim that the approach transfers to generation.
Authors: We agree that quantitative evidence is required to support the transfer claim. We will expand the video generation section with results from a user study measuring adherence to specific cinematographic elements and automated parsing-based scores for prompt compliance. These metrics, together with comparisons against the base Wan model, will be added to the main text. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical pipeline: a structured visual-primitive specification developed with external professionals, the CHAI human-AI critique loop for data curation, standard SFT/DPO training on the resulting preference data, and direct comparisons to external closed-source models (Gemini-3.1-Pro). Ablations measure critique quality against downstream gains via held-out evaluation rather than fitting parameters to the target metric. No equations, self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the provided description; the central claims rest on external benchmarks and human-verified data rather than reducing to the inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
CHAI (Critique-based Human-AI Oversight) framework
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Offline Preference Optimization for Rectified Flow with Noise-Tracked Pairs
PNAPO augments preference data with prior noise pairs and uses straight-line interpolation to create a tighter surrogate objective for offline alignment of rectified flow models.
Reference graph
Works this paper leans on
-
[1]
Critique-out-loud re- ward models.arXiv preprint arXiv:2408.11791, 2024
Zachary Ankner, Mansheej Paul, Brandon Cui, Jonathan D Chang, and Prithviraj Ammanabrolu. Critique-out-loud re- ward models.arXiv preprint arXiv:2408.11791, 2024. 3
-
[2]
Cycle consistency as reward: Learning image-text alignment without human preferences
Hyojin Bahng, Caroline Chan, Fredo Durand, and Phillip Isola. Cycle consistency as reward: Learning image-text alignment without human preferences. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22934–22946, 2025. 1
2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 2, 3, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Improving image generation with better captions.https://cdn.openai
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions.https://cdn.openai. com/papers/dall-e-3.pdf, 2023. 1, 3, 8
2023
-
[5]
Samuel R Bowman, Jeeyoon Hyun, Ethan Perez, Edwin Chen, Craig Pettit, Scott Heiner, Kamil˙e Lukoši¯ut˙e, Amanda Askell, Andy Jones, Anna Chen, et al. Measuring progress on scal- able oversight for large language models.arXiv preprint arXiv:2211.03540, 2022. 2, 3, 5, 9
-
[6]
Activation reward models for few-shot model alignment
Tianning Chai, Chancharik Mitra, Brandon Huang, Gau- tam Rajendrakumar Gare, Zhiqiu Lin, Assaf Arbelle, Leonid Karlinsky, Rogerio Feris, Trevor Darrell, Deva Ramanan, et al. Activation reward models for few-shot model alignment. arXiv preprint arXiv:2507.01368, 2025. 3
-
[7]
Auroracap: Efficient, performant video detailed captioning and a new benchmark
Wenhao Chai, Enxin Song, Yilun Du, Chenlin Meng, Vashisht Madhavan, Omer Bar-Tal, Jenq-Neng Hwang, Saining Xie, and Christopher D Manning. Auroracap: Efficient, perfor- mant video detailed captioning and a new benchmark.arXiv preprint arXiv:2410.03051, 2024. 3, 14, 15, 19, 21
-
[8]
Agneet Chatterjee, Rahim Entezari, Maksym Zhuravinskyi, Maksim Lapin, Reshinth Adithyan, Amit Raj, Chitta Baral, Yezhou Yang, and Varun Jampani. Stable cinemetrics: Struc- tured taxonomy and evaluation for professional video genera- tion.arXiv preprint arXiv:2509.26555, 2025. 8
-
[9]
How people use chatgpt
Aaron Chatterji, Thomas Cunningham, David J Deming, Zoe Hitzig, Christopher Ong, Carl Yan Shan, and Kevin Wadman. How people use chatgpt. Technical report, National Bureau of Economic Research, 2025. 2, 5
2025
-
[10]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585,
work page internal anchor Pith review arXiv
-
[11]
SkyReels-V2: Infinite-length Film Generative Model
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Juncheng Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengchen Ma, et al. Skyreels- v2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074, 2025. 3, 8
work page internal anchor Pith review arXiv 2025
-
[12]
Sharegpt4video: Improving video understanding and generation with better captions.Advances in Neural Information Processing Systems, 37:19472–19495, 2025
Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Zhenyu Tang, Li Yuan, et al. Sharegpt4video: Improving video understanding and generation with better captions.Advances in Neural Information Processing Systems, 37:19472–19495, 2025. 1, 2, 3, 8, 14, 15, 18, 20
2025
-
[13]
Panda-70m: Captioning 70m videos with multiple cross- modality teachers
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Eka- terina Deyneka, Hsiang-wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming-Hsuan Yang, et al. Panda-70m: Captioning 70m videos with multiple cross- modality teachers. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 13320–13331, 2024. 1, 2, 3
2024
-
[14]
Dress: Instructing large vision-language models to align and interact with humans via natural lan- guage feedback
Yangyi Chen, Karan Sikka, Michael Cogswell, Heng Ji, and Ajay Divakaran. Dress: Instructing large vision-language models to align and interact with humans via natural lan- guage feedback. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14239– 14250, 2024. 3
2024
-
[15]
arXiv preprint arXiv:2504.13180 , year=
Jang Hyun Cho, Andrea Madotto, Effrosyni Mavroudi, Tri- antafyllos Afouras, Tushar Nagarajan, Muhammad Maaz, Yale Song, Tengyu Ma, Shuming Hu, Hanoona Rasheed, Peize Sun, Po-Yao Huang, Daniel Bolya, Suyog Jain, Miguel Martin, Huiyu Wang, Vivian Lee, Andrew Westbury, Salman Khan, Philipp Krähenbühl, Piotr Dollár, Lorenzo Torresani, Kristen Grauman, and Chr...
-
[16]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long con- text, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 8, 43
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Jisheng Dang, Yizhou Zhang, Hao Ye, Teng Wang, Sim- ing Chen, Huicheng Zheng, Yulan Guo, Jianhuang Lai, and Bin Hu. Synpo: Synergizing descriptiveness and preference optimization for video detailed captioning.arXiv preprint arXiv:2506.00835, 2025. 3, 8
-
[18]
Ties mat- ter: Meta-evaluating modern metrics with pairwise accuracy and tie calibration
Daniel Deutsch, George Foster, and Markus Freitag. Ties mat- ter: Meta-evaluating modern metrics with pairwise accuracy and tie calibration. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12914–12929, 2023. 40, 43
2023
-
[19]
Yipeng Du, Tiehan Fan, Kepan Nan, Rui Xie, Penghao Zhou, Xiang Li, Jian Yang, Zhenheng Yang, and Ying Tai. Mo- tionsight: Boosting fine-grained motion understanding in multimodal llms.arXiv preprint arXiv:2506.01674, 2025. 8
-
[20]
Improving clip training with language rewrites
Lijie Fan, Dilip Krishnan, Phillip Isola, Dina Katabi, and Yon- glong Tian. Improving clip training with language rewrites. Advances in Neural Information Processing Systems, 36: 35544–35575, 2023. 1
2023
-
[21]
Brian Gordon, Yonatan Bitton, Andreea Marzoca, Yasumasa Onoe, Xiao Wang, Daniel Cohen-Or, and Idan Szpektor. Un- blocking fine-grained evaluation of detailed captions: An explaining autorater and critic-and-revise pipeline.arXiv preprint arXiv:2506.07631, 2025. 3, 6, 7
-
[22]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning 10 capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Captioning images taken by people who are blind
Danna Gurari, Yinan Zhao, Meng Zhang, and Nilavra Bhat- tacharya. Captioning images taken by people who are blind. InEuropean Conference on Computer Vision, pages 417–434. Springer, 2020. 3, 4
2020
-
[24]
Miradata: A large-scale video dataset with long durations and structured captions.Advances in Neural Information Processing Systems, 37:48955–48970, 2024
Xuan Ju, Yiming Gao, Zhaoyang Zhang, Ziyang Yuan, Xintao Wang, Ailing Zeng, Yu Xiong, Qiang Xu, and Ying Shan. Miradata: A large-scale video dataset with long durations and structured captions.Advances in Neural Information Processing Systems, 37:48955–48970, 2024. 2, 3
2024
-
[25]
Tuna: Comprehensive fine-grained temporal understanding evaluation on dense dynamic videos
Fanheng Kong, Jingyuan Zhang, Hongzhi Zhang, Shi Feng, Daling Wang, Linhao Yu, Xingguang Ji, Yu Tian, Victoria W., and Fuzheng Zhang. Tuna: Comprehensive fine-grained temporal understanding evaluation on dense dynamic videos. arXiv preprint arXiv:2505.20124, 2025. 3, 4, 5, 6, 14, 15, 20, 22
-
[26]
Dense-captioning events in videos
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense-captioning events in videos. In Proceedings of the IEEE international conference on com- puter vision, pages 706–715, 2017. 1, 3, 14, 15, 18, 20
2017
-
[27]
Yogesh Kulkarni and Pooyan Fazli. Videopasta: 7k preference pairs that matter for video-llm alignment.arXiv preprint arXiv:2504.14096, 2025. 8
-
[28]
Sicong Leng, Jing Wang, Jiaxi Li, Hao Zhang, Zhiqiang Hu, Boqiang Zhang, Yuming Jiang, Hang Zhang, Xin Li, Lidong Bing, et al. Mmr1: Enhancing multimodal reasoning with variance-aware sampling and open resources.arXiv preprint arXiv:2509.21268, 2025. 8
-
[29]
Evaluating and improving compositional text-to-visual generation
Baiqi Li, Zhiqiu Lin, Deepak Pathak, Jiayao Li, Yixin Fei, Kewen Wu, Xide Xia, Pengchuan Zhang, Graham Neubig, and Deva Ramanan. Evaluating and improving compositional text-to-visual generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5290–5301, 2024. 3, 40
2024
-
[30]
Naturalbench: Evalu- ating vision-language models on natural adversarial samples
Baiqi Li, Zhiqiu Lin, Wenxuan Peng, Jean de Dieu Nyandwi, Daniel Jiang, Zixian Ma, Simran Khanuja, Ranjay Krishna, Graham Neubig, and Deva Ramanan. Naturalbench: Evalu- ating vision-language models on natural adversarial samples. InThe Thirty-eight Conference on Neural Information Pro- cessing Systems Datasets and Benchmarks Track, 2024. 41
2024
-
[31]
Fire: A dataset for feedback integration and refinement evalu- ation of multimodal models.Advances in Neural Information Processing Systems, 37:101618–101640, 2024
Pengxiang Li, Zhi Gao, Bofei Zhang, Tao Yuan, Yuwei Wu, Mehrtash Harandi, Yunde Jia, Song-Chun Zhu, and Qing Li. Fire: A dataset for feedback integration and refinement evalu- ation of multimodal models.Advances in Neural Information Processing Systems, 37:101618–101640, 2024. 3
2024
-
[32]
Long Lian, Yifan Ding, Yunhao Ge, Sifei Liu, Hanzi Mao, Boyi Li, Marco Pavone, Ming-Yu Liu, Trevor Darrell, Adam Yala, et al. Describe anything: Detailed localized image and video captioning.arXiv preprint arXiv:2504.16072, 2025. 3
-
[33]
Multimodality helps unimodality: Cross- modal few-shot learning with multimodal models, 2023
Zhiqiu Lin, Samuel Yu, Zhiyi Kuang, Deepak Pathak, and Deva Ramanan. Multimodality helps unimodality: Cross- modal few-shot learning with multimodal models, 2023. 3
2023
-
[34]
Revisiting the role of language priors in vision-language models.arXiv preprint arXiv:2306.01879,
Zhiqiu Lin, Xinyue Chen, Deepak Pathak, Pengchuan Zhang, and Deva Ramanan. Revisiting the role of language priors in vision-language models.arXiv preprint arXiv:2306.01879,
-
[35]
Evaluating text-to-visual generation with image-to-text generation
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Eval- uating text-to-visual generation with image-to-text generation. arXiv preprint arXiv:2404.01291, 2024. 7, 40, 42
-
[36]
Towards un- derstanding camera motions in any video
Zhiqiu Lin, Siyuan Cen, Daniel Jiang, Jay Karhade, Hewei Wang, Chancharik Mitra, Yu Tong Tiffany Ling, Yuhan Huang, Sifan Liu, Mingyu Chen, Rushikesh Zawar, Xue Bai, Yilun Du, Chuang Gan, and Deva Ramanan. Towards un- derstanding camera motions in any video. 2025. 1, 3, 4, 21, 23
2025
-
[37]
Shihong Liu, Zhiqiu Lin, Samuel Yu, Ryan Lee, Tiffany Ling, Deepak Pathak, and Deva Ramanan. Language models as black-box optimizers for vision-language models.arXiv preprint arXiv:2309.05950, 2023. 3
-
[38]
Inference-time scaling for generalist reward modeling
Zijun Liu, Peiyi Wang, Runxin Xu, Shirong Ma, Chong Ruan, Peng Li, Yang Liu, and Yu Wu. Inference-time scaling for generalist reward modeling.arXiv preprint arXiv:2504.02495,
-
[39]
Zhihang Liu, Chen-Wei Xie, Bin Wen, Feiwu Yu, Jixuan Chen, Boqiang Zhang, Nianzu Yang, Pandeng Li, Yinglu Li, Zuan Gao, et al. What is a good caption? a comprehensive visual caption benchmark for evaluating both correctness and thoroughness.arXiv preprint arXiv:2502.14914, 2025. 1
-
[40]
Omni-captioner: Data pipeline, models, and benchmark for omni detailed perception,
Ziyang Ma, Ruiyang Xu, Zhenghao Xing, Yunfei Chu, Yux- uan Wang, Jinzheng He, Jin Xu, Pheng-Ann Heng, Kai Yu, Junyang Lin, et al. Omni-captioner: Data pipeline, models, and benchmark for omni detailed perception.arXiv preprint arXiv:2510.12720, 2025. 3, 8
-
[41]
Self-refine: It- erative refinement with self-feedback.Advances in Neural Information Processing Systems, 36:46534–46594, 2023
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hal- linan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: It- erative refinement with self-feedback.Advances in Neural Information Processing Systems, 36:46534–46594, 2023. 3
2023
-
[42]
Native language pro- motes access to visual consciousness.Psychological Science, 29(11):1757–1772, 2018
Martin Maier and Rasha Abdel Rahman. Native language pro- motes access to visual consciousness.Psychological Science, 29(11):1757–1772, 2018. 1
2018
-
[43]
Nat McAleese, Rai Michael Pokorny, Juan Felipe Ceron Uribe, Evgenia Nitishinskaya, Maja Trebacz, and Jan Leike. Llm critics help catch llm bugs.arXiv preprint arXiv:2407.00215, 2024. 3, 6
-
[44]
Desen Meng, Rui Huang, Zhilin Dai, Xinhao Li, Yifan Xu, Jun Zhang, Zhenpeng Huang, Meng Zhang, Lingshu Zhang, Yi Liu, et al. Videocap-r1: Enhancing mllms for video caption- ing via structured thinking.arXiv preprint arXiv:2506.01725,
-
[45]
Enhancing few- shot vision-language classification with large multimodal model features
Chancharik Mitra, Brandon Huang, Tianning Chai, Zhiqiu Lin, Assaf Arbelle, Rogerio Feris, Leonid Karlinsky, Trevor Darrell, Deva Ramanan, and Roei Herzig. Enhancing few- shot vision-language classification with large multimodal model features. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 2760–2772,
-
[46]
Language can shape the perception of oriented objects
Eduardo Navarrete, Michele Miozzo, and Francesca Peres- sotti. Language can shape the perception of oriented objects. Scientific reports, 10(1):8409, 2020. 1
2020
-
[47]
Docci: De- scriptions of connected and contrasting images
Yasumasa Onoe, Sunayana Rane, Zachary Berger, Yonatan Bitton, Jaemin Cho, Roopal Garg, Alexander Ku, Zarana 11 Parekh, Jordi Pont-Tuset, Garrett Tanzer, et al. Docci: De- scriptions of connected and contrasting images. InEuropean Conference on Computer Vision, pages 291–309. Springer,
-
[48]
OpenAI. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 8, 43
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744,
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Car- roll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744,
-
[50]
The neglected tails of vision-language models.arXiv preprint arXiv:2401.12425, 2024
Shubham Parashar, Zhiqiu Lin, Tian Liu, Xiangjue Dong, Yanan Li, Deva Ramanan, James Caverlee, and Shu Kong. The neglected tails of vision-language models.arXiv preprint arXiv:2401.12425, 2024. 3
-
[51]
Direct prefer- ence optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct prefer- ence optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023. 2, 3, 7
2023
-
[52]
Moodio: Making anyone a professional video studio, 2026
Ryan Rao, Ruihuang Yang, George Liu, Chancharik Mitra, Siyuan Cen, Yuhan Huang, Shihang Zhu, Jiaxi Li, Ruojin Li, Hewei Wang, Yu Tong Tiffany Ling, Yili Han, Yilun Du, Graham Neubig, Deva Ramanan, and Zhiqiu Lin. Moodio: Making anyone a professional video studio, 2026. Under review. 1, 4, 5, 23
2026
-
[53]
Self-critiquing models for assisting human evaluators
William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, and Jan Leike. Self-critiquing models for assisting human evaluators.arXiv preprint arXiv:2206.05802, 2022. 2, 3, 5, 7, 8, 9, 35, 36, 37
-
[54]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv e-prints, abs/1707.06347, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Transnet v2: An effective deep network architecture for fast shot transition detection
Tomás Soucek and Jakub Lokoc. Transnet v2: An effective deep network architecture for fast shot transition detection. InProceedings of the 32nd ACM International Conference on Multimedia, pages 11218–11221, 2024. 47
2024
-
[56]
Univ of California Press, 1969
Raymond Spottiswoode.A grammar of the film: An analysis of film technique. Univ of California Press, 1969. 1, 4
1969
-
[57]
Going beyond one-size- fits-all image descriptions to satisfy the information wants of people who are blind or have low vision
Abigale Stangl, Nitin Verma, Kenneth R Fleischmann, Mered- ith Ringel Morris, and Danna Gurari. Going beyond one-size- fits-all image descriptions to satisfy the information wants of people who are blind or have low vision. InProceedings of the 23rd international ACM SIGACCESS conference on computers and accessibility, pages 1–15, 2021. 3
2021
-
[58]
Changli Tang, Yixuan Li, Yudong Yang, Jimin Zhuang, Guangzhi Sun, Wei Li, Zejun Ma, and Chao Zhang. video- salmonn 2: Captioning-enhanced audio-visual large language models.arXiv preprint arXiv:2506.15220, 2025. 3, 8
-
[59]
Granite Vision Team, Leonid Karlinsky, Assaf Arbelle, Abra- ham Daniels, Ahmed Nassar, Amit Alfassi, Bo Wu, Eli Schwartz, Dhiraj Joshi, Jovana Kondic, et al. Granite vision: a lightweight, open-source multimodal model for enterprise intelligence.arXiv preprint arXiv:2502.09927, 2025. 8
-
[60]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jin- gren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fan...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Jiawei Wang, Liping Yuan, Yuchen Zhang, and Haomiao Sun. Tarsier: Recipes for training and evaluating large video description models.arXiv preprint arXiv:2407.00634, 2024. 1, 3, 6, 14, 15, 19, 21
-
[62]
Spatialvid: A large-scale video dataset with spatial annotations.arXiv preprint arXiv:2509.09676,
Jiahao Wang, Yufeng Yuan, Rujie Zheng, Youtian Lin, Jian Gao, Lin-Zhuo Chen, Yajie Bao, Yi Zhang, Chang Zeng, Yanxi Zhou, et al. Spatialvid: A large-scale video dataset with spatial annotations.arXiv preprint arXiv:2509.09676,
-
[63]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025. 8
work page internal anchor Pith review arXiv 2025
-
[64]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in lan- guage models.arXiv preprint arXiv:2203.11171, 2022. 45
work page internal anchor Pith review arXiv 2022
-
[65]
Xiyao Wang, Zhengyuan Yang, Chao Feng, Hongjin Lu, Lin- jie Li, Chung-Ching Lin, Kevin Lin, Furong Huang, and Lijuan Wang. Sota with less: Mcts-guided sample selection for data-efficient visual reasoning self-improvement.arXiv preprint arXiv:2504.07934, 2025. 3
-
[66]
Yubo Wang, Xiang Yue, and Wenhu Chen. Critique fine- tuning: Learning to critique is more effective than learning to imitate.arXiv preprint arXiv:2501.17703, 2025. 3
-
[67]
Perception in reflection.arXiv preprint arXiv:2504.07165, 2025
Yana Wei, Liang Zhao, Kangheng Lin, En Yu, Yuang Peng, Runpei Dong, Jianjian Sun, Haoran Wei, Zheng Ge, Xi- angyu Zhang, et al. Perception in reflection.arXiv preprint arXiv:2504.07165, 2025. 3
-
[68]
Russian blues reveal effects of language on color discrimination.Proceedings of the national academy of sciences, 104(19):7780–7785, 2007
Jonathan Winawer, Nathan Witthoft, Michael C Frank, Lisa Wu, Alex R Wade, and Lera Boroditsky. Russian blues reveal effects of language on color discrimination.Proceedings of the national academy of sciences, 104(19):7780–7785, 2007. 1
2007
-
[69]
Tractatus logico-philosophicus
Ludwig Wittgenstein. Tractatus logico-philosophicus. 1922. 1
1922
-
[70]
Peiran Wu, Yunze Liu, Zhengdong Zhu, Enmin Zhou, and Shawn Shen. Ugc-videocaptioner: An omni ugc video de- tail caption model and new benchmarks.arXiv preprint arXiv:2507.11336, 2025. 3
-
[71]
Visco: Benchmarking 12 fine-grained critique and correction towards self-improvement in visual reasoning
Xueqing Wu, Yuheng Ding, Bingxuan Li, Pan Lu, Da Yin, Kai-Wei Chang, and Nanyun Peng. Visco: Benchmarking 12 fine-grained critique and correction towards self-improvement in visual reasoning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9527–9537, 2025. 3
2025
-
[72]
Msr-vtt: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5288–5296, 2016. 1, 3, 14, 15, 18
2016
-
[73]
Zhucun Xue, Jiangning Zhang, Teng Hu, Haoyang He, Yinan Chen, Yuxuan Cai, Yabiao Wang, Chengjie Wang, Yong Liu, Xiangtai Li, et al. Ultravideo: High-quality uhd video dataset with comprehensive captions.arXiv preprint arXiv:2506.13691, 2025. 2, 3, 14, 15, 19, 21
-
[74]
Videochat-r1. 5: Visual test-time scaling to reinforce multimodal reasoning by iterative perception,
Ziang Yan, Xinhao Li, Yinan He, Zhengrong Yue, Xiangyu Zeng, Yali Wang, Yu Qiao, Limin Wang, and Yi Wang. Videochat-r1. 5: Visual test-time scaling to reinforce mul- timodal reasoning by iterative perception.arXiv preprint arXiv:2509.21100, 2025. 8
-
[75]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
Kwai keye-vl 1.5 technical report.arXiv preprint arXiv:2509.01563, 2025
Biao Yang, Bin Wen, Boyang Ding, Changyi Liu, Chenglong Chu, Chengru Song, Chongling Rao, Chuan Yi, Da Li, Dunju Zang, et al. Kwai keye-vl 1.5 technical report.arXiv preprint arXiv:2509.01563, 2025. 3
-
[77]
Vript: A video is worth thousands of words.Advances in Neural Information Processing Systems, 37:57240–57261, 2024
Dongjie Yang, Suyuan Huang, Chengqiang Lu, Xiaodong Han, Haoxin Zhang, Yan Gao, Yao Hu, and Hai Zhao. Vript: A video is worth thousands of words.Advances in Neural Information Processing Systems, 37:57240–57261, 2024. 3
2024
-
[78]
Michihiro Yasunaga, Luke Zettlemoyer, and Marjan Ghazvininejad. Multimodal rewardbench: Holistic evalu- ation of reward models for vision language models.arXiv preprint arXiv:2502.14191, 2025. 3
-
[79]
Hanrong Ye, Chao-Han Huck Yang, Arushi Goel, Wei Huang, Ligeng Zhu, Yuanhang Su, Sean Lin, An-Chieh Cheng, Zhen Wan, Jinchuan Tian, et al. Omnivinci: Enhancing architecture and data for omni-modal understanding llm.arXiv preprint arXiv:2510.15870, 2025. 8
-
[80]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xi- aochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.