Recognition: 2 theorem links
· Lean TheoremCLR-voyance: Reinforcing Open-Ended Reasoning for Inpatient Clinical Decision Support with Outcome-Aware Rubrics
Pith reviewed 2026-05-12 04:25 UTC · model grok-4.3
The pith
Outcome-aware rubrics from full patient journeys let an 8B model outperform larger medical LLMs on inpatient clinical reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
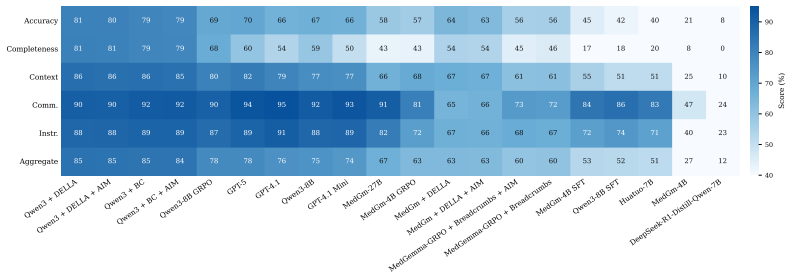
CLR-voyance reformulates inpatient clinical reasoning as a Partially Observable Markov Decision Process (POMDP) that partitions each patient journey into a policy-visible past and an oracle-only future. Using only the visible past, an oracle LLM generates a case-specific, verifiable rubric; these rubrics then supervise post-training of base models such as Qwen3-8B with GRPO followed by merging. The trained CLR-voyance-8B reaches 84.91 percent on CLR-POMDP, exceeding GPT-5 at 77.83 percent and MedGemma-27B at 66.66 percent, with comparable or better results on standard medical benchmarks and validation through a large-scale clinician alignment study.
What carries the argument
Outcome-aware rubric: a case-specific, verifiable query-answer pair generated by an oracle LLM from the full patient journey to score reasoning performed with only the admission history.
If this is right
- The trained models retain or improve performance on existing general medical benchmarks.
- The approach supports direct hospital deployment for drafting reasoning-heavy inpatient notes.
- Clinician pairwise preferences and rubric curation provide data on LLM-as-judge reliability in medical settings.
Where Pith is reading between the lines
- The POMDP framing could transfer to other high-stakes sequential domains where decisions must be justified before outcomes are known.
- If rubric generation can be approximated from partial data alone, the method might support online reinforcement without waiting for full patient resolution.
- Smaller domain-tuned models may become the practical choice for privacy-sensitive or low-resource clinical environments.
Load-bearing premise
Rubrics generated by an oracle from the complete patient record remain unbiased and non-leaking when used to judge reasoning that never saw that future information.
What would settle it
A head-to-head clinician evaluation in which the same models are scored on reasoning quality using only admission data and blinded rubrics that ignore the eventual outcome.
Figures




read the original abstract
Inpatient clinical reasoning is a sequential decision under partial observability: the clinician sees the admission so far and must choose the next action whose downstream consequences are not yet visible. Existing clinical-LLM evaluations and RL rewards signals collapse this into closed-form retrieval, clinical journey leakage, or unanchored LLM-as-judge scoring. We introduce CLR-voyance, a framework that reformulates inpatient reasoning as a Partially Observable Markov Decision Process (POMDP) and supervises it with rewards that are simultaneously outcome-grounded and clinician-validated. We instantiate the formulation as CLR-POMDP, which partitions successful patient journeys into a policy-visible past and an oracle-only future. Using the past information, an oracle LLM generates a case-specific query-answer pair, and the first adaptive rubric for clinical reasoning which is verifiable in the future of the patient journey. These rubrics are used for both post-training and evaluation of models for inpatient clinical reasoning. We post-train Qwen3-8B and MedGemma-4B with GRPO followed by model merging, yielding state-of-the-art inpatient clinical reasoning while retaining generalist capabilities. CLR-voyance-8B achieves 84.91% on CLR-POMDP, ahead of frontier medical reasoning models like GPT-5 (77.83%) and MedGemma-27B (66.66%) and has comparable or better performance on existing medical benchmarks. To ensure a clinically meaningful setting, we conduct a large-scale clinician alignment study, where physicians curate per-case rubrics, grade candidate responses, and provide blinded pairwise preferences of model reasoning. This study provides insights on clinical LLM-as-a-judge and clinical preference-model selection, which can inform the community at large. CLR-voyance has been deployed for 6+ months at a partner public hospital, drafting thousands of reasoning-heavy inpatient notes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CLR-voyance, a framework reformulating inpatient clinical reasoning as a POMDP supervised by outcome-aware rubrics. It constructs the CLR-POMDP benchmark by partitioning successful patient journeys into policy-visible past and oracle-only future, with an oracle LLM generating case-specific queries, answers, and adaptive rubrics used for both GRPO post-training and evaluation. Post-training Qwen3-8B and MedGemma-4B yields CLR-voyance-8B, which scores 84.91% on CLR-POMDP (outperforming GPT-5 at 77.83% and MedGemma-27B at 66.66%) while retaining generalist performance; the work also reports a clinician alignment study and 6+ months of hospital deployment.
Significance. If the rubric-based rewards prove independent of leakage and the POMDP formulation holds, the work could advance clinical LLM research by supplying a benchmark and training signal that better captures sequential decision-making under partial observability, together with practical evidence from clinician validation and deployment. The retention of general capabilities after GRPO and merging is a notable strength.
major comments (1)
- CLR-POMDP construction (abstract and methods): the rubric generation step grants the oracle LLM access to the full patient journey, including the oracle-only future, to produce adaptive rubrics that are then applied identically for GRPO training and final CLR-POMDP scoring. This creates a circularity risk in which reported gains (e.g., the 84.91% vs. 77.83% margin) may partly reflect alignment with oracle-embedded future criteria rather than improved policy quality under true partial observability; the clinician curation study on a subset of cases does not retroactively validate the automated pipeline used for the headline numbers.
minor comments (2)
- Abstract: the phrase 'state-of-the-art inpatient clinical reasoning' should be qualified with the precise set of baselines, statistical tests, and controls for data leakage that support the claim.
- Clinician study section: reporting the number of physicians, cases, inter-rater agreement metrics, and blinding protocol would improve reproducibility of the preference and rubric validation results.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which raises an important point about the CLR-POMDP construction. We clarify our design rationale below and outline targeted revisions to improve transparency.
read point-by-point responses
-
Referee: CLR-POMDP construction (abstract and methods): the rubric generation step grants the oracle LLM access to the full patient journey, including the oracle-only future, to produce adaptive rubrics that are then applied identically for GRPO training and final CLR-POMDP scoring. This creates a circularity risk in which reported gains (e.g., the 84.91% vs. 77.83% margin) may partly reflect alignment with oracle-embedded future criteria rather than improved policy quality under true partial observability; the clinician curation study on a subset of cases does not retroactively validate the automated pipeline used for the headline numbers.
Authors: We appreciate the referee highlighting this potential issue. The oracle LLM does access the full journey solely during rubric generation to produce outcome-aware rubrics that are verifiable against actual future events; this is intentional to ground the reward in real clinical outcomes rather than unanchored judgments. Once generated, each rubric is fixed and applied identically to all models. The policy model (in both GRPO training and evaluation) receives only the policy-visible past and must produce reasoning that aligns with rubric criteria without any future information or knowledge of how the rubric was constructed. This provides a POMDP-appropriate training signal that rewards reasoning predictive of successful trajectories. Relative gains (e.g., 84.91% vs. 77.83%) therefore reflect superior alignment with outcome-grounded criteria under identical evaluation conditions. The clinician curation study was performed on a diverse, representative subset with high inter-rater agreement to validate the automated pipeline; we agree this does not constitute exhaustive validation of every case in the headline benchmark. We will revise the Methods section to explicitly delineate information available to the oracle versus the policy model, add a dedicated paragraph in the Discussion addressing circularity risks and mitigation, and expand reporting of clinician validation statistics and selection criteria for the subset. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper defines CLR-POMDP by partitioning patient journeys and generating outcome-aware rubrics via an oracle LLM, then applies GRPO training using those rubrics as the reward signal before reporting the 84.91% score on the same rubric-based evaluation. This is an empirical training outcome rather than a quantity equivalent to the inputs by construction; the model must actually learn to produce responses that score highly under the rubric, and the paper contrasts the result against untuned frontier models (GPT-5 at 77.83%, MedGemma-27B at 66.66%) on the identical benchmark. The clinician alignment study supplies an external check on a subset of cases. No equation, parameter fit, or self-citation reduces the central performance claim to a renaming or tautology of the framework's own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Inpatient clinical reasoning can be accurately modeled as a POMDP with policy-visible past and oracle-only future
invented entities (1)
-
CLR-POMDP and outcome-aware rubrics
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce CLR-POMDP, which partitions successful patient journeys into a policy-visible past and an oracle-only future... These rubrics are used for both post-training and evaluation... r_rub(ŷ|d) = clip[0,1](∑_{i:j_i=true} p_i / ∑_{i:p_i>0} p_i)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The Grounded Judge... generates... per-case multi-axis rubric conditioned on that patient’s actual future
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alternating Reinforcement Learning for Rubric-Based Reward Modeling in Non-Verifiable LLM Post-Training , author=. arXiv preprint arXiv:2602.01511 , year=
-
[2]
Editgrpo: Reinforcement learning with post-rollout edits for clinically accurate chest x-ray report generation , author=. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , pages=
-
[3]
Limitations of large language models in clinical problem-solving arising from inflexible reasoning , author=. Scientific reports , volume=. 2025 , publisher=
work page 2025
-
[4]
Beyond distillation: Pushing the limits of medical llm reasoning with minimalist rule-based rl , author=. arXiv preprint arXiv:2505.17952 , year=
-
[5]
Medxpertqa: Benchmarking expert-level medical reasoning and understanding , author=. arXiv preprint arXiv:2501.18362 , year=
-
[6]
arXiv preprint arXiv:2508.02808 , year=
Clinically Grounded Agent-based Report Evaluation: An Interpretable Metric for Radiology Report Generation , author=. arXiv preprint arXiv:2508.02808 , year=
-
[7]
arXiv preprint arXiv:2601.06193 , year=
MLB: A Scenario-Driven Benchmark for Evaluating Large Language Models in Clinical Applications , author=. arXiv preprint arXiv:2601.06193 , year=
-
[8]
arXiv preprint arXiv:2512.01241 , year=
First, do NOHARM: towards clinically safe large language models , author=. arXiv preprint arXiv:2512.01241 , year=
-
[9]
arXiv preprint arXiv:2511.14439 , year=
MedBench v4: A Robust and Scalable Benchmark for Evaluating Chinese Medical Language Models, Multimodal Models, and Intelligent Agents , author=. arXiv preprint arXiv:2511.14439 , year=
-
[10]
EHR-R1: A Reasoning-Enhanced Foundational Language Model for Electronic Health Record Analysis , author=. arXiv preprint arXiv:2510.25628 , year=
-
[11]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
Medground-r1: Advancing medical image grounding via spatial-semantic rewarded group relative policy optimization , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2025 , organization=
work page 2025
-
[12]
OpenThoughts: Data Recipes for Reasoning Models
Openthoughts: Data recipes for reasoning models , author=. arXiv preprint arXiv:2506.04178 , year=
work page internal anchor Pith review arXiv
-
[13]
arXiv preprint arXiv:2506.00711 , year=
Qoq-med: Building multimodal clinical foundation models with domain-aware grpo training , author=. arXiv preprint arXiv:2506.00711 , year=
-
[14]
arXiv preprint arXiv:2505.19538 , year=
Doctorrag: Medical rag fusing knowledge with patient analogy through textual gradients , author=. arXiv preprint arXiv:2505.19538 , year=
-
[15]
arXiv preprint arXiv:2505.06912 , year=
Building a human-verified clinical reasoning dataset via a human LLM hybrid pipeline for trustworthy medical AI , author=. arXiv preprint arXiv:2505.06912 , year=
-
[16]
Large language models with temporal reasoning for longitudinal clinical summarization and prediction , author=. Findings of ACL. EMNLP. Conference on Empirical Methods in Natural Language Processing , volume=
-
[17]
arXiv preprint arXiv:2409.12741 , year=
Fine tuning large language models for medicine: The role and importance of direct preference optimization , author=. arXiv preprint arXiv:2409.12741 , year=
-
[18]
arXiv preprint arXiv:2408.12055 , year=
Aligning (medical) llms for (counterfactual) fairness , author=. arXiv preprint arXiv:2408.12055 , year=
-
[19]
arXiv preprint arXiv:2401.05654 , year=
Towards conversational diagnostic AI , author=. arXiv preprint arXiv:2401.05654 , year=
-
[20]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Medalign: A clinician-generated dataset for instruction following with electronic medical records , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[21]
arXiv preprint arXiv:2403.06609 , year=
Guiding clinical reasoning with large language models via knowledge seeds , author=. arXiv preprint arXiv:2403.06609 , year=
-
[22]
Medhelm: Holistic evaluation of large language models for medical tasks , author=. arXiv preprint arXiv:2505.23802 , year=
-
[23]
arXiv preprint arXiv:2512.10691 , year=
Enhancing Radiology Report Generation and Visual Grounding using Reinforcement Learning , author=. arXiv preprint arXiv:2512.10691 , year=
-
[24]
arXiv preprint arXiv:2510.05194 , year=
Reinforcement Learning for Clinical Reasoning: Aligning LLMs with ACR Imaging Appropriateness Criteria , author=. arXiv preprint arXiv:2510.05194 , year=
-
[25]
ER-Reason: A Benchmark Dataset for LLM Clinical Reasoning in the Emergency Room
Er-reason: A benchmark dataset for llm-based clinical reasoning in the emergency room , author=. arXiv preprint arXiv:2505.22919 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Rm-r1: Reward modeling as reasoning.arXiv preprint arXiv:2505.02387, 2025
Rm-r1: Reward modeling as reasoning , author=. arXiv preprint arXiv:2505.02387 , year=
-
[27]
arXiv preprint arXiv:2503.04691 , year=
Quantifying the reasoning abilities of llms on real-world clinical cases , author=. arXiv preprint arXiv:2503.04691 , year=
-
[28]
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
Huatuogpt-o1, towards medical complex reasoning with llms , author=. arXiv preprint arXiv:2412.18925 , year=
work page internal anchor Pith review arXiv
-
[29]
arXiv preprint arXiv:2403.06728 , year=
Large model driven radiology report generation with clinical quality reinforcement learning , author=. arXiv preprint arXiv:2403.06728 , year=
-
[30]
arXiv preprint arXiv:2505.22338 , year=
Text2Grad: Reinforcement Learning from Natural Language Feedback , author=. arXiv preprint arXiv:2505.22338 , year=
-
[31]
Systematic review of large language models for patient care: current applications and challenges , author=. MedRxiv , pages=. 2024 , publisher=
work page 2024
-
[32]
arXiv preprint arXiv:2504.18080 , year=
Stabilizing reasoning in medical llms with continued pretraining and reasoning preference optimization , author=. arXiv preprint arXiv:2504.18080 , year=
-
[33]
Sequential Diagnosis with Language Models
Sequential diagnosis with language models , author=. arXiv preprint arXiv:2506.22405 , year=
- [34]
-
[35]
Advances in Neural Information Processing Systems , volume=
Rule based rewards for language model safety , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Rubrics as rewards: Reinforcement learning beyond verifiable domains , author=. arXiv preprint arXiv:2507.17746 , year=
work page internal anchor Pith review arXiv
-
[37]
arXiv preprint arXiv:2506.16507 , year=
Robust reward modeling via causal rubrics , author=. arXiv preprint arXiv:2506.16507 , year=
-
[38]
Reinforcement learning with rubric anchors.arXiv preprint arXiv:2508.12790,
Reinforcement learning with rubric anchors , author=. arXiv preprint arXiv:2508.12790 , year=
-
[39]
Reinforcement learning and its clinical applications within healthcare: A systematic review of precision medicine and dynamic treatment regimes , author=. Healthcare , volume=. 2025 , organization=
work page 2025
-
[40]
The twelfth international conference on learning representations , year=
On-policy distillation of language models: Learning from self-generated mistakes , author=. The twelfth international conference on learning representations , year=
-
[41]
Detecting Data Deviations in Electronic Health Records , author=
-
[42]
arXiv preprint arXiv:2508.00669 , year=
Medical reasoning in the era of LLMs: a systematic review of enhancement techniques and applications , author=. arXiv preprint arXiv:2508.00669 , year=
-
[43]
arXiv preprint arXiv:2510.11390 , year=
Medical Interpretability and Knowledge Maps of Large Language Models , author=. arXiv preprint arXiv:2510.11390 , year=
-
[44]
Medreason: Eliciting factual medical reasoning steps in llms via knowledge graphs , author=. arXiv preprint arXiv:2504.00993 , year=
-
[45]
International Journal of Medical Sciences , volume=
Large language models in medicine: applications, challenges, and future directions , author=. International Journal of Medical Sciences , volume=
-
[46]
arXiv preprint arXiv:2503.04748 , year=
Large language models in healthcare , author=. arXiv preprint arXiv:2503.04748 , year=
-
[47]
Proceedings of the AAAI conference on artificial intelligence , volume=
Large language models are clinical reasoners: Reasoning-aware diagnosis framework with prompt-generated rationales , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[48]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Healthbench: Evaluating large language models towards improved human health , author=. arXiv preprint arXiv:2505.08775 , year=
work page internal anchor Pith review arXiv
-
[49]
arXiv preprint arXiv:2305.12788 , year=
Graphcare: Enhancing healthcare predictions with personalized knowledge graphs , author=. arXiv preprint arXiv:2305.12788 , year=
-
[50]
JMIR Medical Education , volume=
Empathy and equity: key considerations for large language model adoption in health care , author=. JMIR Medical Education , volume=. 2023 , publisher=
work page 2023
-
[51]
Advances in Neural Information Processing Systems , volume=
Ehrshot: An ehr benchmark for few-shot evaluation of foundation models , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
Large language models in healthcare and medical domain: A review , author=. Informatics , volume=. 2024 , organization=
work page 2024
-
[53]
Cpllm: Clinical prediction with large language models , author=. PLOS Digital Health , volume=. 2024 , publisher=
work page 2024
-
[54]
bench: Diagnostic reasoning benchmark for clinical natural language processing , author=
Dr. bench: Diagnostic reasoning benchmark for clinical natural language processing , author=. Journal of biomedical informatics , volume=. 2023 , publisher=
work page 2023
-
[55]
Interactive Journal of Medical Research , volume=
Benefits and risks of AI in health care: narrative review , author=. Interactive Journal of Medical Research , volume=. 2024 , publisher=
work page 2024
-
[56]
arXiv preprint arXiv:2412.19792 , year=
Infalign: Inference-aware language model alignment , author=. arXiv preprint arXiv:2412.19792 , year=
-
[57]
arXiv preprint arXiv:2502.21321
Llm post-training: A deep dive into reasoning large language models , author=. arXiv preprint arXiv:2502.21321 , year=
-
[58]
A scalable framework for evaluating health language models , author=. npj Digital Medicine , year=
- [59]
-
[60]
Assessment of large language models in clinical reasoning: a novel benchmarking study , author=. NEJM AI , volume=. 2025 , publisher=
work page 2025
-
[61]
A PHYSICIAN’S GUIDE TO CLINICAL DOCUMENTATION IMPROVEMENT: ALIGNING CDI TO HEALTH INFORMATION PRACTICE , author=
-
[62]
A survey of frontiers in llm reasoning: Inference scaling, learning to reason, and agentic systems , author=. arXiv preprint arXiv:2504.09037 , year=
-
[63]
A survey of large language models in medicine: Progress, application, and challenge
A survey of large language models in medicine: Progress, application, and challenge , author=. arXiv preprint arXiv:2311.05112 , year=
-
[64]
International Journal of Machine Learning and Cybernetics , volume=
Large language models for medicine: a survey , author=. International Journal of Machine Learning and Cybernetics , volume=. 2025 , publisher=
work page 2025
-
[65]
Nature Reviews Bioengineering , volume=
Application of large language models in medicine , author=. Nature Reviews Bioengineering , volume=. 2025 , publisher=
work page 2025
-
[66]
BMC Medical Informatics and Decision Making , volume=
A systematic review of large language model (LLM) evaluations in clinical medicine , author=. BMC Medical Informatics and Decision Making , volume=. 2025 , publisher=
work page 2025
-
[67]
AI-Driven Clinical Care Guidelines Can Lead to Better Patient Outcomes—healthtechmagazine. net , author=. Link, year , year=
-
[68]
Journal of Medical Internet Research , volume=
Accuracy of large language models when answering clinical research questions: systematic review and network meta-analysis , author=. Journal of Medical Internet Research , volume=. 2025 , publisher=
work page 2025
-
[69]
Journal of medical Internet research , volume=
Adoption of large language model ai tools in everyday tasks: multisite cross-sectional qualitative study of Chinese hospital administrators , author=. Journal of medical Internet research , volume=. 2025 , publisher=
work page 2025
-
[70]
Advancedif: Rubric-based benchmarking and reinforcement learning for advancing llm instruction following , author=. arXiv preprint arXiv:2511.10507 , year=
-
[71]
Aligning llms to ask good questions a case study in clinical reasoning , author=. arXiv e-prints , pages=
-
[72]
Chinese Medical Journal , volume=
Application of large language models in disease diagnosis and treatment , author=. Chinese Medical Journal , volume=. 2025 , publisher=
work page 2025
-
[73]
Applications of large language models in clinical practice: path, challenges, and future perspectives , author=. OSF Prepr , year=
-
[74]
Journal of Biomedical Informatics , pages=
Clinical pathway-aware large language models for reliable and transparent medical dialogue , author=. Journal of Biomedical Informatics , pages=. 2025 , publisher=
work page 2025
-
[75]
npj Digital Medicine , volume=
Artificial intelligence should genuinely support clinical reasoning and decision making to bridge the translational gap , author=. npj Digital Medicine , volume=. 2025 , publisher=
work page 2025
-
[76]
The British journal of general practice , volume=
Artificial intelligence in medicine: current trends and future possibilities , author=. The British journal of general practice , volume=
-
[77]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Ask patients with patience: Enabling llms for human-centric medical dialogue with grounded reasoning , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[78]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Assessing Automated Fact-Checking for Medical LLM Responses with Knowledge Graphs , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[79]
Automating expert-level medical reasoning evaluation of large language models , author=. npj Digital Medicine , year=
-
[80]
ethical physician care , author=
Black-box assisted medical decisions: AI power vs. ethical physician care , author=. Medicine, health care and philosophy , volume=. 2023 , publisher=
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.