Recognition: unknown
On-Policy Distillation with Best-of-N Teacher Rollout Selection
Pith reviewed 2026-05-14 21:09 UTC · model grok-4.3
The pith
BRTS selects the best teacher rollout from multiple samples to reduce noise in on-policy distillation for reasoning models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Augmenting on-policy distillation with best-of-N teacher rollout selection, ordered by correctness then student alignment and supplemented by a ground-truth recovery step, produces more reliable supervision signals and measurable performance gains on challenging math reasoning benchmarks.
What carries the argument
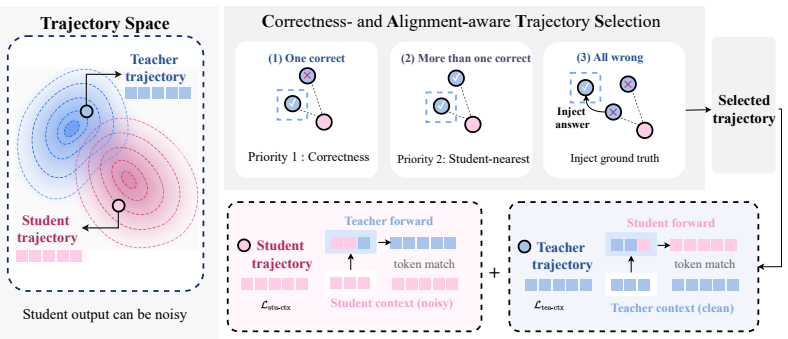
The BRTS priority rule that ranks teacher trajectories first by correctness and second by alignment with the student's sampled behavior, together with the ground-truth-conditioned recovery mechanism that elicits natural derivations when unconditioned sampling fails.
If this is right
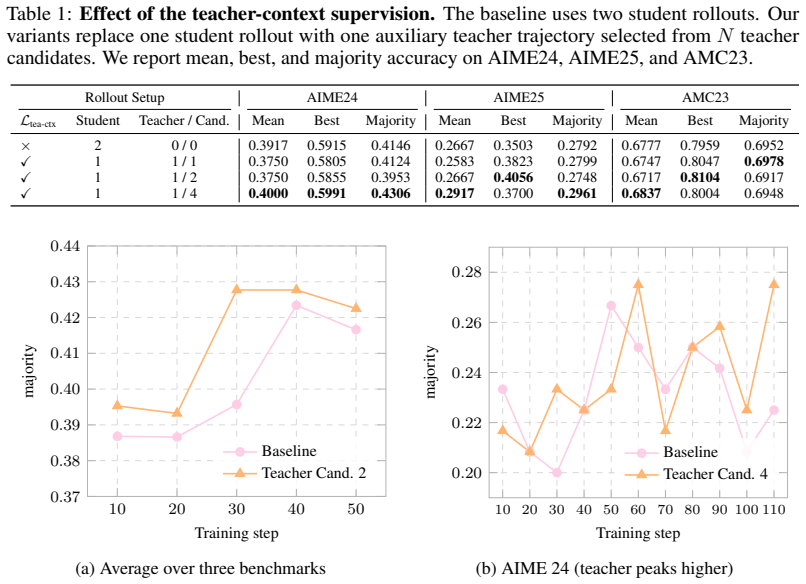
- The auxiliary loss on the curated teacher trajectory supplies an additional stable training signal inside the OPD loop.
- Gains are largest on harder datasets, indicating the method helps most when single-rollout supervision is most unreliable.
- The teacher-context branch operates alongside the standard student-context branch without altering the core OPD objective.
Where Pith is reading between the lines
- The same selection logic could be applied to other on-policy methods that suffer from rollout variance, such as certain preference optimization loops.
- If correctness can be verified automatically in non-math domains, the framework might extend beyond competition problems without requiring new human labels.
- Over repeated distillation rounds the curated trajectories could gradually reduce distribution shift between teacher and student.
Load-bearing premise
The correctness-first priority rule plus the ground-truth recovery step will reliably produce higher-quality supervision trajectories without introducing selection bias or overfitting to the chosen paths.
What would settle it
If replacing the priority-based selection with random rollout choice yields no performance difference on AIME or AMC benchmarks, the claim that the curation rule drives the gains would be falsified.
Figures



read the original abstract
On-policy distillation (OPD), which supervises a student on its own sampled trajectories, has emerged as a data-efficient post-training method for improving reasoning while avoiding the reward dependence of reinforcement learning and the catastrophic forgetting often observed in standard supervised fine-tuning. However, standard OPD typically computes teacher supervision under noisy student-generated contexts and often relies on a single stochastic teacher rollout per prompt. As a result, the supervision signal can be high-variance: the sampled teacher trajectory can be incorrect, uninformative, or poorly matched to the student's current reasoning behavior. To address this limitation, we propose BRTS, a Best-of-N Rollout Teacher Selection framework for on-policy distillation. BRTS augments standard student-context OPD with a teacher-context supervision branch constructed from the curated teacher trajectory. Rather than distilling from the first sampled teacher rollout, BRTS samples a small pool of teacher trajectories and selects the auxiliary trajectory using a simple priority rule: correctness first, student alignment second. When multiple correct teacher trajectories are available, BRTS chooses the one most aligned with the student's current behavior; when unconditioned teacher samples fail on harder prompts, it invokes a ground-truth-conditioned recovery step to elicit a natural derivation. The selected trajectory is then used to provide reliable teacher-context supervision inside the OPD loop, augmented with an auxiliary loss on the teacher trajectory. Experiments on AIME 2024, AIME 2025, and AMC 2023 show that BRTS improves over standard OPD on challenging reasoning benchmarks, with the largest gains on harder datasets. Our code is available at https://github.com/BWGZK-keke/BRTS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BRTS (Best-of-N Rollout Teacher Selection), an augmentation to on-policy distillation (OPD) for reasoning models. Standard OPD uses noisy student-context teacher rollouts that can be incorrect or poorly aligned; BRTS instead samples N teacher trajectories, selects via a priority rule (correctness first, then student alignment), and falls back to a ground-truth-conditioned recovery step on hard prompts to supply a correct derivation. The selected trajectory supplies an auxiliary teacher-context supervision signal inside the OPD loop. Experiments on AIME 2024, AIME 2025, and AMC 2023 report that BRTS outperforms standard OPD, with the largest gains on the hardest datasets.
Significance. If the gains are shown to be robust and attributable to the selection mechanism rather than the recovery step, BRTS would provide a simple, data-efficient way to improve supervision quality in on-policy distillation without introducing reward models or full SFT. The open-sourced code at the provided GitHub link supports reproducibility and is a clear strength.
major comments (3)
- [Experiments] Experiments section: no error bars, standard deviations across seeds, or statistical significance tests are reported for the benchmark gains on AIME 2024/2025 and AMC 2023. This makes it impossible to determine whether the observed improvements exceed run-to-run variance.
- [Experiments] Experiments section: no ablation is presented that isolates the best-of-N selection rule (correctness + alignment) from the ground-truth-conditioned recovery step. Because the recovery step supplies correct derivations that standard OPD never receives, it is unclear whether the reported gains are driven by the priority rule or by the recovery mechanism itself.
- [Method] Method section: the precise definition and computation of 'student alignment' (used as the secondary selection criterion) is not specified with sufficient detail to allow replication or to assess whether it introduces selection bias toward the student's current (possibly flawed) behavior.
minor comments (2)
- [Abstract] Abstract: the phrase 'natural derivation' in the recovery step description is vague; a brief clarification of what conditioning is applied would improve readability.
- [Experiments] The manuscript would benefit from an explicit statement of the value of N used in the reported experiments and any sensitivity analysis around this hyper-parameter.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving experimental rigor and methodological clarity, and we have revised the paper accordingly to address them.
read point-by-point responses
-
Referee: [Experiments] Experiments section: no error bars, standard deviations across seeds, or statistical significance tests are reported for the benchmark gains on AIME 2024/2025 and AMC 2023. This makes it impossible to determine whether the observed improvements exceed run-to-run variance.
Authors: We agree that the lack of error bars and statistical tests limits the strength of the claims. In the revised manuscript, we have rerun all experiments across three random seeds, added mean and standard deviation values to the main results tables, and included paired t-test p-values demonstrating that the gains over standard OPD are statistically significant (p < 0.05) on AIME 2024 and AIME 2025. revision: yes
-
Referee: [Experiments] Experiments section: no ablation is presented that isolates the best-of-N selection rule (correctness + alignment) from the ground-truth-conditioned recovery step. Because the recovery step supplies correct derivations that standard OPD never receives, it is unclear whether the reported gains are driven by the priority rule or by the recovery mechanism itself.
Authors: This is a fair point. We have added a dedicated ablation subsection in the revised Experiments section that isolates the components. The new results compare (i) standard OPD, (ii) BRTS without recovery (priority rule only on unconditioned samples), (iii) recovery with random selection among correct trajectories, and (iv) full BRTS. These show that the priority rule provides measurable additional gains beyond recovery alone, especially on the hardest prompts. revision: yes
-
Referee: [Method] Method section: the precise definition and computation of 'student alignment' (used as the secondary selection criterion) is not specified with sufficient detail to allow replication or to assess whether it introduces selection bias toward the student's current (possibly flawed) behavior.
Authors: We thank the referee for highlighting this omission. The revised Method section now defines student alignment explicitly as the cosine similarity between sentence-transformer embeddings of the student's partial solution trace and each candidate teacher trajectory. We have included the exact embedding model, pseudocode for the selection procedure, and a short discussion of potential bias toward the student's current policy. revision: yes
Circularity Check
No circularity: empirical heuristic evaluated on held-out benchmarks
full rationale
The paper presents BRTS as a procedural selection rule (correctness priority, alignment tie-breaker, ground-truth recovery fallback) inside on-policy distillation. No mathematical derivations, predictions, or first-principles results are claimed; the method is a heuristic whose performance is measured directly on external benchmarks (AIME 2024/2025, AMC 2023). No equations reduce to fitted parameters by construction, no self-citation chains support load-bearing premises, and no ansatz or renaming is introduced. The approach is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
free parameters (1)
- N (number of teacher rollouts)
axioms (1)
- domain assumption Correctness of teacher trajectories can be reliably determined from ground truth
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe Twelfth International Conference on Learning Representations (ICLR), 2024. URLhttps://openreview.net/forum?id=3zKtaqxLhW
2024
-
[2]
Mislav Balunovi ´c, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi ´c, and Martin Vechev. MathArena: Evaluating LLMs on uncontaminated math competitions.arXiv preprint arXiv:2505.23281, 2025
-
[3]
Scheduled sampling for sequence prediction with recurrent neural networks
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2015
2015
-
[4]
Howard Chen, Noam Razin, Karthik Narasimhan, and Danqi Chen. Retaining by doing: The role of on-policy data in mitigating forgetting.arXiv preprint arXiv:2510.18874, 2025
-
[5]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V . Le, Sergey Levine, and Yi Ma. SFT memorizes, RL generalizes: A comparative study of foundation model post-training.arXiv preprint arXiv:2501.17161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
arXiv preprint arXiv:2603.23871 , year =
Ken Ding. HDPO: Hybrid distillation policy optimization via privileged self-distillation.arXiv preprint arXiv:2603.23871, 2026
-
[8]
RAFT: Reward ranked finetuning for generative foundation model alignment
Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, KaShun Shum, and Tong Zhang. RAFT: Reward ranked finetuning for generative foundation model alignment. InTransactions on Machine Learning Research, 2023
2023
-
[9]
Yao Fu, Hao Peng, Litu Ou, Ashish Sabharwal, and Tushar Khot. Specializing smaller language models towards multi-step reasoning.arXiv preprint arXiv:2301.12726, 2023
-
[10]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Yuanheng Zhu, and Dongbin Zhao. Revisiting on- policy distillation: Empirical failure modes and simple fixes.arXiv preprint arXiv:2603.25562, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
GLM-5: from Vibe Coding to Agentic Engineering
GLM-5 Team, Aohan Zeng, Xin Lv, Zhenyu Hou, et al. GLM-5: From vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Maybank, and Dacheng Tao
Jianping Gou, Baosheng Yu, Stephen J. Maybank, and Dacheng Tao. Knowledge distillation: A survey.International Journal of Computer Vision, 2021
2021
-
[13]
MiniLLM: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: Knowledge distillation of large language models. 2024
2024
-
[14]
OpenThoughts: Data Recipes for Reasoning Models
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, et al. OpenThoughts: Data recipes for reasoning models.arXiv preprint arXiv:2506.04178, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.Nature, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.Nature, 2025
2025
-
[16]
JustRL: Scaling a 1.5B LLM with a simple RL recipe.arXiv preprint arXiv:2512.16649, 2025
Bingxiang He, Zekai Qu, Zeyuan Liu, Yinghao Chen, Yuxin Zuo, Cheng Qian, Kaiyan Zhang, Weize Chen, Chaojun Xiao, Ganqu Cui, et al. JustRL: Scaling a 1.5B LLM with a simple RL recipe.arXiv preprint arXiv:2512.16649, 2025
-
[17]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015. 10
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[18]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Stable On-Policy Distillation through Adaptive Target Reformulation
Ijun Jang, Jewon Yeom, Juan Yeo, Hyunggu Lim, and Taesup Kim. Stable on-policy distillation through adaptive target reformulation.arXiv preprint arXiv:2601.07155, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
TinyBERT: Distilling BERT for natural language understanding
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. TinyBERT: Distilling BERT for natural language understanding. InFindings of the Association for Computational Linguistics: EMNLP 2020, 2020
2020
-
[21]
arXiv preprint arXiv:2603.07079 , year =
Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee. Entropy-aware on-policy distillation of language models. arXiv preprint arXiv:2603.07079, 2026
-
[22]
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dohyung Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Yang. Why does self-distillation (sometimes) degrade the reasoning capability of LLMs?arXiv preprint arXiv:2603.24472, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Yoon Kim and Alexander M. Rush. Sequence-level knowledge distillation. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2016
2016
-
[24]
arXiv preprint arXiv:2603.11137 , year =
Jongwoo Ko, Sara Abdali, Young Jin Kim, Tianyi Chen, and Pashmina Cameron. Scaling reasoning efficiently via relaxed on-policy distillation.arXiv preprint arXiv:2603.11137, 2026
-
[25]
Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Yann Fleureau, Guillaume Lample, and Stanislas Polu
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q. Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Yann Fleureau, Guillaume Lample, and Stanislas Polu. NuminaMath: The largest public dataset in AI4Maths with 860k pairs of competition math problems and solutions. Hugging Face repository, 2024
2024
-
[26]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding. Rethinking on-policy dis- tillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Small models struggle to learn from strong reasoners
Yuetai Li, Xiang Yue, Zhangchen Xu, Fengqing Jiang, Luyao Niu, Bill Yuchen Lin, Bhaskar Ra- masubramanian, and Radha Poovendran. Small models struggle to learn from strong reasoners. 2025
2025
-
[28]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Thinking Machines Lab: Connectionism , year =
Kevin Lu and Thinking Machines Lab. On-policy distillation.Thinking Machines Lab: Con- nectionism, 2025. doi: 10.64434/tml.20251026
-
[30]
An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing, 2025
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing, 2025
2025
-
[31]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christo- pher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. WebGPT: Browser-assisted question-answering with human feedback. InarXiv preprint arXiv:2112.09332, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
Privileged information distillation for language models, 2026
Emiliano Penaloza, Dheeraj Vattikonda, Nicolas Gontier, Alexandre Lacoste, Laurent Charlin, and Massimo Caccia. Privileged information distillation for language models, 2026
2026
-
[33]
A reduction of imitation learning and structured prediction to no-regret online learning
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics (AISTATS), 2011
2011
-
[34]
DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. InProceedings of the 5th Workshop on Energy Efficient Machine Learning and Cognitive Computing (NeurIPS Workshop), 2019. 11
2019
-
[35]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
RL’s razor: Why online reinforcement learning forgets less.arXiv preprint arXiv:2509.04259, 2025
Idan Shenfeld, Jyothish Pari, and Pulkit Agrawal. RL’s razor: Why online reinforcement learning forgets less.arXiv preprint arXiv:2509.04259, 2025
-
[38]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J
Avi Singh, John D. Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J. Liu, James Harrison, Jaehoon Lee, Kelvin Xu, Aaron Parisi, Abhishek Kumar, Alex Alemi, Alex Rizkowsky, Azade Nova, Ben Adlam, Bernd Bohnet, Gamaleldin Elsayed, Hanie Sedghi, Igor Mordatch, et al. Beyond human data: Scaling self-training for problem-solving wi...
2024
-
[40]
Learning by distilling context, 2022
Charlie Snell, Dan Klein, and Ruiqi Zhong. Learning by distilling context, 2022
2022
-
[41]
Christiano
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F. Christiano. Learning to summarize with human feedback. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[42]
MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in Neural Information Processing Systems, 33:5776–5788, 2020
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in Neural Information Processing Systems, 33:5776–5788, 2020
2020
-
[43]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. 2023
2023
-
[44]
MiMo-V2-Flash Technical Report
Xiaomi LLM-Core Team, Bangjun Xiao, Bingquan Xia, Bo Yang, et al. MiMo-V2-Flash technical report.arXiv preprint arXiv:2601.02780, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Error bounds of imitating policies and environments.Advances in Neural Information Processing Systems, 33, 2020
Tian Xu, Ziniu Li, and Yang Yu. Error bounds of imitating policies and environments.Advances in Neural Information Processing Systems, 33, 2020
2020
-
[46]
Wenda Xu, Rujun Han, Zifeng Wang, Long T Le, Dhruv Madeka, Lei Li, William Yang Wang, Rishabh Agarwal, Chen-Yu Lee, and Tomas Pfister. Speculative knowledge distillation: Bridging the teacher-student gap through interleaved sampling.arXiv preprint arXiv:2410.11325, 2024
-
[47]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled RLVR.arXiv preprint arXiv:2604.03128, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
arXiv preprint arXiv:2602.12125 , year=
Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yankai Lin. Learning beyond teacher: Generalized on-policy distillation with reward extrapolation.arXiv preprint arXiv:2602.12125, 2026
-
[50]
Black-box on-policy distillation of large language models, 2026
Tianzhu Ye, Li Dong, Zewen Chi, Xun Wu, Shaohan Huang, and Furu Wei. Black-box on-policy distillation of large language models, 2026
2026
-
[51]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. DAPO: An open-source LLM reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
STaR: Bootstrapping reasoning with reasoning.Advances in Neural Information Processing Systems, 2022
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. STaR: Bootstrapping reasoning with reasoning.Advances in Neural Information Processing Systems, 2022
2022
-
[54]
Towards the law of capacity gap in distilling language models
Chen Zhang, Qiuchi Li, Dawei Song, Zheyu Ye, Yan Gao, and Yao Hu. Towards the law of capacity gap in distilling language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 22504–22528, 2025
2025
-
[55]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026. 13 This appendix provides additional details to support the reproducibility and interpretation of our results. Appendix A describes the model, data...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
NEVER mention, quote, paraphrase, or allude to it anywhere –- not in <think>, not in your answer
-
[57]
NEVER say things like ‘the key says’, ‘based on the hint’, ‘the answer is given’, ‘I can see the correct answer is’, or any equivalent phrasing
-
[58]
Your entire chain of thought must be derived from what you observe in the problem
-
[59]
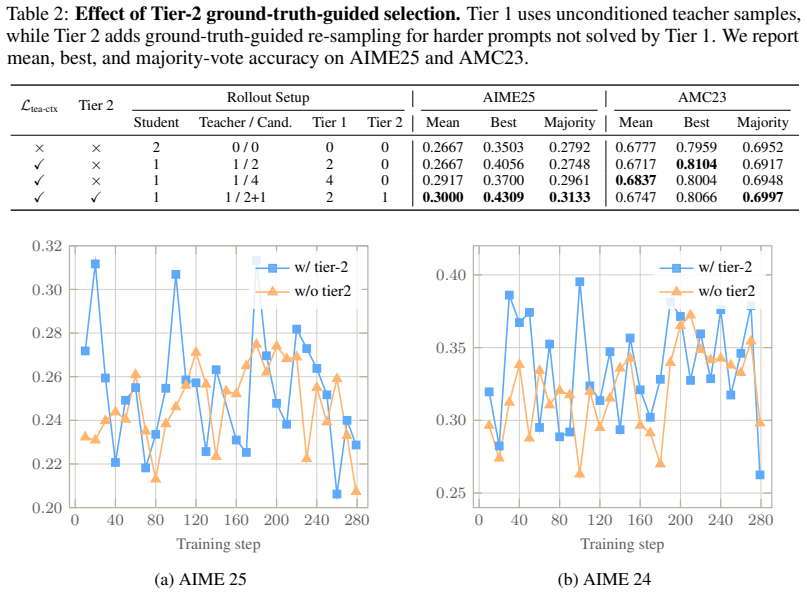
Only use the validation key silently as a final sanity-check after you have already reasoned to a conclusion –- never as a starting point or shortcut. The resulting Tier-2 rollout is retained only if its extracted answer matches y⋆; samples for which Tier-2 also fails fall through to Tier-3, in which BRTS picks the most overlap-similar Tier-1 rollout as a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.