Recognition: no theorem link
Trajectory Supervision for Continual Tool-Use Learning in LLMs
Pith reviewed 2026-05-12 03:09 UTC · model grok-4.3
The pith
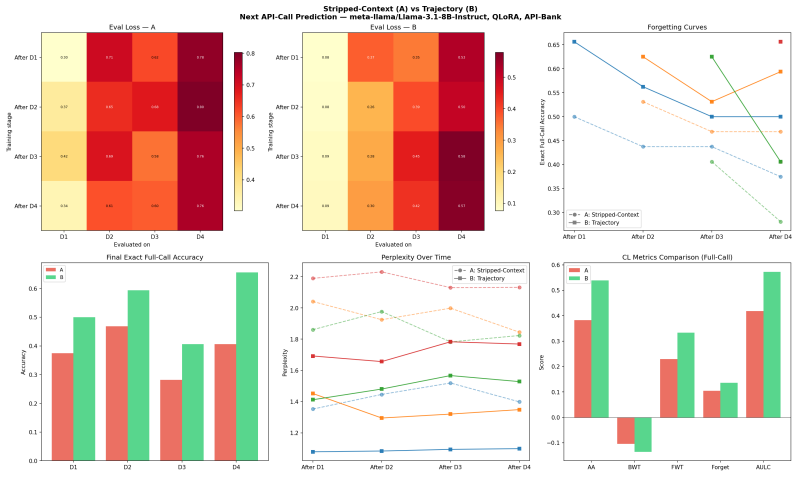
Keeping full tool-use trajectories during sequential training raises next-call accuracy from 39 percent to 57 percent compared with final-call-only prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that retaining tool-use trajectories as supervision context when fine-tuning on sequential API domain blocks produces higher held-out next-call prediction accuracy than stripping those trajectories and training on isolated final calls. In the single-seed pilot the trajectory condition achieves 56.9 percent exact full-call accuracy and a 7.7-point gain in API-name accuracy while using 25.1 percent more training tokens; the evaluation remains next-call prediction rather than full ongoing dialogue success.
What carries the argument
Trajectory supervision, the mechanism of keeping prior API request and response lines inside the training prompt so the model predicts the next call in the context of the full interaction history across domain blocks.
Load-bearing premise
That next-call prediction accuracy measured on held-out data will serve as a reliable proxy for successful tool use inside real, ongoing multi-turn dialogues.
What would settle it
A multi-seed evaluation that measures exact full-call accuracy inside complete multi-turn user dialogues rather than isolated next-call prompts would show whether the reported gap disappears or persists.
Figures



read the original abstract
Most language-model training data shows final artifacts, not the process that produced them. We study a tractable version of this question in tool use: when a model learns a stream of new API domains, does keeping tool-use trajectories help compared with stripping the intermediate API trace? We fine-tune Llama 3.1 8B Instruct with QLoRA on API-Bank using four sequential domain blocks. Condition A strips previous API request/response lines from the prompt and trains the model to predict the next API call. Condition B keeps the trajectory context. In a single-seed pilot, full held-out generation evaluation shows that Condition B reaches 56.9\% final exact full-call accuracy compared with 39.2\% for Condition A. B also improves final API-name accuracy by 7.7 points. However, B uses 25.1\% more training tokens, the run uses one seed, and the task is next-call prediction rather than full dialogue success.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines whether retaining full tool-use trajectories during sequential fine-tuning on new API domains improves continual learning compared to training solely on the next API call without prior context. Using Llama 3.1 8B Instruct with QLoRA on API-Bank split into four sequential domain blocks, it compares Condition A (stripped prompts predicting next call) against Condition B (trajectory context retained). In a single-seed pilot, full held-out generation shows Condition B reaching 56.9% exact full-call accuracy versus 39.2% for A, with a 7.7-point gain in API-name accuracy, though B consumes 25.1% more tokens and evaluation is limited to next-call prediction.
Significance. If the observed gains prove robust, the result would indicate that trajectory supervision supports better retention and application of tool-use knowledge across sequential domains, offering a practical data-curation insight for continual learning in LLM tool-use systems. The work provides a clear, controlled empirical comparison on a public benchmark and explicitly notes its pilot limitations, which is a strength for transparency. No machine-checked proofs or parameter-free derivations are present, but the direct measurement of two training conditions is reproducible in principle.
major comments (3)
- [Abstract / Results] Abstract and results: The central claim of a 17.7-point exact full-call accuracy lift (56.9% vs 39.2%) and 7.7-point API-name improvement rests on a single training seed with no error bars, multiple runs, or statistical tests reported. This makes it impossible to determine whether the gap is stable or an artifact of initialization, directly undermining confidence in the superiority of trajectory supervision.
- [Evaluation / Abstract] Evaluation protocol: The reported metric is next-call exact-match accuracy on held-out single examples, yet the motivating use case is ongoing multi-turn tool-use dialogues in which errors accumulate and recovery is required. No evidence or discussion is provided that single-step accuracy is a faithful proxy for full-dialogue success, which is load-bearing for claims about improved continual tool-use learning.
- [Experimental setup] Condition comparison: Condition B uses 25.1% more training tokens than A. The manuscript does not include a control (e.g., extended training of A to equal token count) to isolate whether the accuracy difference arises from trajectory context or simply from additional optimization steps.
minor comments (2)
- [Abstract] The abstract already flags the single-seed and token-count limitations; the main text should expand this into a dedicated limitations subsection with concrete suggestions for follow-up experiments (multiple seeds, full-dialogue evaluation).
- [Method] Provide the exact prompt templates for Conditions A and B (including how trajectories are formatted) in an appendix or figure to allow precise reproduction.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our pilot study. We address each of the major concerns below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results: The central claim of a 17.7-point exact full-call accuracy lift (56.9% vs 39.2%) and 7.7-point API-name improvement rests on a single training seed with no error bars, multiple runs, or statistical tests reported. This makes it impossible to determine whether the gap is stable or an artifact of initialization, directly undermining confidence in the superiority of trajectory supervision.
Authors: We agree that a single seed provides limited statistical reliability for the observed differences. The manuscript already characterizes the work as a 'single-seed pilot' and highlights this limitation. In the revised version, we will conduct the experiments across multiple random seeds (at least three), report average accuracies with standard deviations or error bars, and perform statistical tests to assess the significance of the differences between conditions. revision: yes
-
Referee: [Evaluation / Abstract] Evaluation protocol: The reported metric is next-call exact-match accuracy on held-out single examples, yet the motivating use case is ongoing multi-turn tool-use dialogues in which errors accumulate and recovery is required. No evidence or discussion is provided that single-step accuracy is a faithful proxy for full-dialogue success, which is load-bearing for claims about improved continual tool-use learning.
Authors: The experiment is designed to measure the effect of trajectory supervision on learning and retaining tool-use patterns across sequential domains in a controlled next-call prediction setting. This isolates the contribution of retained context without introducing variables from multi-turn interactions. We will add a dedicated discussion section in the revision explaining the rationale for using next-call accuracy as a proxy and acknowledging that it does not directly measure full-dialogue performance or error recovery. However, we do not have empirical data from full multi-turn evaluations in this pilot. revision: partial
-
Referee: [Experimental setup] Condition comparison: Condition B uses 25.1% more training tokens than A. The manuscript does not include a control (e.g., extended training of A to equal token count) to isolate whether the accuracy difference arises from trajectory context or simply from additional optimization steps.
Authors: We acknowledge that the difference in training token count between the conditions is a potential confound, as Condition B receives more optimization steps. The current pilot did not include a matched-token-budget control. In the revised manuscript, we will include an additional experiment in which Condition A is trained with extra epochs or augmented data to match the token count of Condition B, thereby better isolating the effect of trajectory retention. revision: yes
Circularity Check
No significant circularity in empirical comparison
full rationale
The paper reports a direct empirical comparison of two fine-tuning conditions on API-Bank data: Condition A strips prior API traces while Condition B retains full trajectories. The key results (56.9% vs 39.2% exact full-call accuracy and +7.7 points in API-name accuracy) are measured outcomes from held-out generation evaluation after sequential training on four domain blocks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the central claim is an observed accuracy difference rather than a reduction of any quantity to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption QLoRA fine-tuning on Llama 3.1 8B Instruct produces stable updates comparable to prior literature
Reference graph
Works this paper leans on
-
[1]
QLoRA: Efficient finetuning of quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized LLMs. NeurIPS, 2023
work page 2023
-
[2]
Abhimanyu Dubey et al. The Llama 3 herd of models. arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. ICLR, 2022
work page 2022
-
[4]
Api-bank: A comprehensive benchmark for tool-augmented llms
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. API-Bank: A comprehensive benchmark for tool-augmented LLMs. arXiv:2304.08244, 2023
-
[5]
Hunter Lightman et al. Let's verify step by step. arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin et al. ToolLLM: Facilitating large language models to master 16000+ real-world APIs. arXiv:2307.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. NeurIPS, 2023
work page 2023
-
[8]
arXiv preprint arXiv:2310.06762 , year=
Xiao Wang et al. TRACE: A comprehensive benchmark for continual learning in large language models. arXiv:2310.06762, 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.