Recognition: 3 theorem links
· Lean TheoremKV-RM: Regularizing KV-Cache Movement for Static-Graph LLM Serving
Pith reviewed 2026-05-12 03:50 UTC · model grok-4.3
The pith
Regularizing KV-cache movement lets static-graph LLM decoders absorb variable request lengths without over-reserving memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KV-RM decouples logical KV histories from physical storage, tracks active KV state through a block pager, and materializes each decode step through a single committed descriptor after a merge-staged transport path coalesces non-contiguous mappings into a small number of large transfer groups. The design absorbs variability from differing lengths and asynchronous events below the fixed decode interface; optional bounded far-history summaries can be added but are not required. On a 2-GPU NVIDIA A100 node this yields higher mixed-length throughput, lower tail latency, reduced reserved KV memory across workloads, and removal of severe burst-time spikes under production-trace replay.
What carries the argument
The merge-staged transport path that coalesces non-contiguous KV mappings into a small number of large transfer groups before a fixed-shape attention kernel consumes them under a single committed descriptor per decode step.
If this is right
- Mixed-length decoding throughput rises on 2-GPU A100 nodes relative to an unmodified static-graph baseline.
- Tail latency falls for the same mixed workloads.
- Reserved KV memory drops across families of production workloads.
- Severe burst-time latency spikes disappear when the system replays real production traces.
Where Pith is reading between the lines
- Movement regularization can serve as an alternative interface for runtime flexibility when dynamic kernel shapes are unavailable.
- Static-graph serving may scale to more heterogeneous request mixes if the coalescing strategy generalizes beyond the evaluated traces.
- The optional far-history summaries could be combined with the core mechanism to further reduce memory pressure in long-context settings.
Load-bearing premise
Variability from differing request lengths, asynchronous EOS events, and fragmented histories can be absorbed below a fixed decode interface primarily through KV-cache movement regularization.
What would settle it
A production-trace workload in which the merge-staged transport still produces many small transfers, leaving throughput, tail latency, and reserved memory unchanged or worse than the static-graph baseline.
Figures



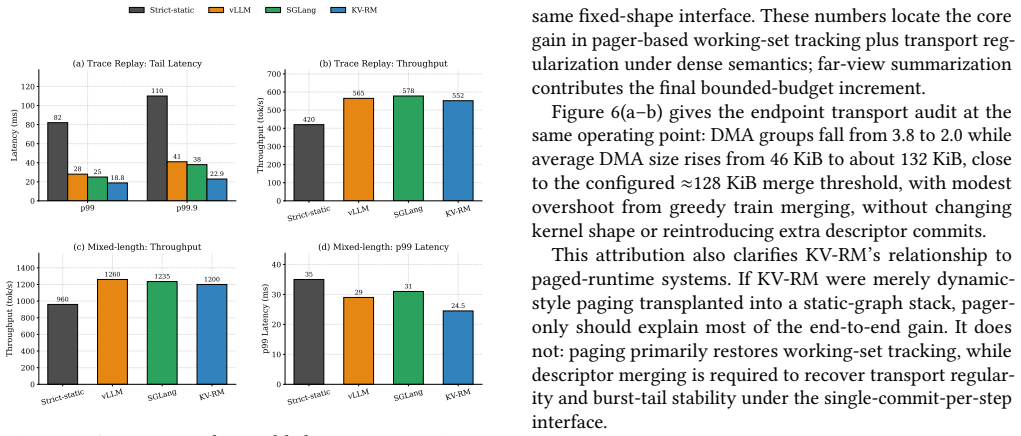


read the original abstract
Static-graph LLM decoders provide predictable launches, fixed tensor shapes, and low submission overhead, but online decoding exposes highly irregular KV-cache behavior: request lengths differ, EOS events arrive asynchronously, and logical histories fragment over time. Dynamic runtimes recover flexibility through paged KV management and step-level scheduling, while static-graph executors often over-reserve memory and suffer burst-time latency outliers. This paper studies whether much of this variability can be absorbed below a fixed decode interface. We present KV-RM, a runtime design that regularizes KV-cache movement beneath a static-graph LLM decoder. KV-RM decouples logical KV histories from physical storage, tracks active KV state through a block pager, and materializes each decode step through a single committed descriptor. A merge-staged transport path coalesces non-contiguous KV mappings into a small number of large transfer groups before a fixed-shape attention kernel consumes them. Optional bounded far-history summaries can be enabled under the same interface, but the core design does not depend on them. On a 2-GPU NVIDIA A100 node, KV-RM improves mixed-length decoding throughput and tail latency relative to a static-graph baseline, reduces reserved KV memory across workload families, and removes severe burst-time latency spikes under production-trace replay. These results suggest that KV-cache movement, rather than kernel shape, can be an effective boundary for recovering runtime flexibility in static-graph LLM serving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KV-RM, a runtime design to regularize KV-cache movement beneath a static-graph LLM decoder. It decouples logical KV histories from physical storage via a block pager, materializes each decode step with a single committed descriptor, and uses merge-staged transport to coalesce non-contiguous KV mappings into large transfers for a fixed-shape attention kernel. Optional bounded far-history summaries are supported but stated to be non-essential. On a 2-GPU NVIDIA A100 node, the design is reported to improve mixed-length decoding throughput and tail latency versus a static-graph baseline, reduce reserved KV memory across workloads, and eliminate severe burst-time latency spikes under production-trace replay.
Significance. If the central claims hold after addressing the experimental gaps, KV-RM would demonstrate that KV-cache movement regularization can recover substantial runtime flexibility for static-graph LLM serving without altering kernel shapes or adopting fully dynamic runtimes. This targets a practical production challenge and could influence the design of efficient, predictable LLM inference systems.
major comments (1)
- The abstract states that 'the core design does not depend on' the optional bounded far-history summaries and that variability from differing request lengths, asynchronous EOS events, and fragmented histories 'can be absorbed below a fixed decode interface' primarily via KV-cache movement regularization (block pager, single committed descriptor, merge-staged coalescing). However, the evaluation provides no ablation that disables the summaries while keeping the rest of the KV-RM path fixed. This omission is load-bearing because the reported gains in throughput, tail latency, memory reduction, and spike elimination could still rely on the summaries to bound fragmentation rather than the regularization mechanism alone.
minor comments (2)
- The abstract describes empirical improvements on A100 hardware with mixed workloads and production traces but supplies no quantitative numbers, error bars, baseline details, or workload exclusion criteria. Adding at least one key metric (e.g., throughput delta or p99 latency reduction) would make the summary more informative.
- The design entities ('block pager', 'merge-staged transport path', 'single committed descriptor') are introduced without accompanying pseudocode, diagram, or interface specification in the provided description; explicit definitions and an illustration of the coalescing step would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: The abstract states that 'the core design does not depend on' the optional bounded far-history summaries and that variability from differing request lengths, asynchronous EOS events, and fragmented histories 'can be absorbed below a fixed decode interface' primarily via KV-cache movement regularization (block pager, single committed descriptor, merge-staged coalescing). However, the evaluation provides no ablation that disables the summaries while keeping the rest of the KV-RM path fixed. This omission is load-bearing because the reported gains in throughput, tail latency, memory reduction, and spike elimination could still rely on the summaries to bound fragmentation rather than the regularization mechanism alone.
Authors: We agree that an explicit ablation disabling the optional bounded far-history summaries (while keeping the block pager, single committed descriptor, and merge-staged transport fixed) would strengthen the claim that the gains derive primarily from KV-cache movement regularization. The manuscript already states that the summaries are optional and non-essential, serving only to optionally compress far-history tokens under the same fixed interface; the core mechanisms are designed to absorb length variability, asynchronous EOS, and fragmentation independently. In the revised manuscript we will add this ablation study to quantify the incremental contribution of the summaries versus the regularization path alone. revision: yes
Circularity Check
No significant circularity; empirical engineering design with runtime measurements
full rationale
The paper describes an engineering runtime design (KV-RM) for regularizing KV-cache movement under a static-graph LLM decoder, evaluated via direct throughput, latency, and memory measurements on a 2-GPU A100 node against a baseline. No derivation chain, equations, first-principles predictions, or fitted parameters exist that could reduce to self-defined inputs. Claims rest on implementation choices (block pager, single descriptor, merge-staged coalescing) and observed outcomes, with optional far-history summaries explicitly stated as non-dependent. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Static-graph LLM decoders can maintain a fixed decode interface while absorbing request variability through lower-level KV-cache regularization.
invented entities (2)
-
block pager
no independent evidence
-
merge-staged transport path
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KV-RM decouples logical KV histories from physical storage, tracks active KV state through a block pager, and materializes each decode step through a single committed descriptor. A merge-staged transport path coalesces non-contiguous KV mappings...
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The core dense-semantic KV-RM path consists of three mechanisms: the static sliding kernel, the KV pager, and merge-staged transport.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
On a 2× NVIDIA A100 node, KV-RM improves mixed-length decoding throughput and tail latency...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ram- jee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. InProceedings of the 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USENIX Associ- ation, Berkeley, CA, USA, 103–12...
work page 2024
-
[2]
Reza Yazdani Aminabadi, Samyam Rajbhandari, Ammar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Olatunji Ruwase, Shaden Smith, Min- jia Zhang, Jeff Rasley, and Yuxiong He. 2022. DeepSpeed-inference: enabling efficient inference of transformer models at unprecedented scale. InProceedings of the International Conference on High Perfor- mance Computing, Networki...
-
[3]
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, and Wen Xiao. 2024. PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling. arXiv preprint arXiv:2406.02069.https://arxiv.org/abs/24 06.02069
work page internal anchor Pith review arXiv 2024
-
[4]
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yu Hu, Luis Ceze, et al. 2018. TVM: An automated end-to-end optimizing compiler for deep learning. In13th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USENIX Association, Berkeley, CA, USA, 578–594.https://www.usenix.org...
work page 2018
- [5]
-
[6]
Yihua Cheng, Yuhan Liu, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaoting Feng, Yuyang Huang, Samuel Shen, Kuntai Du, and Junchen Jiang
-
[7]
LMCache: An Efficient KV Cache Layer for Enterprise-Scale LLM Inference. arXiv preprint arXiv:2510.09665.https://arxiv.org/ab s/2510.09665
-
[8]
Tri Dao. 2024. FlashAttention-2: Faster Attention with Better Paral- lelism and Work Partitioning. International Conference on Learning Representations (ICLR).https://arxiv.org/abs/2307.08691
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Tri Dao, Daniel Y Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
-
[10]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 35. Curran Associates, Inc., Red Hook, NY, USA, 16344– 16359.https://arxiv.org/abs/2205.14135
work page internal anchor Pith review arXiv
-
[11]
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt Gardner. 2021. A Dataset of Information-Seeking Ques- tions and Answers Anchored in Research Papers. arXiv preprint arXiv:2105.03011.https://arxiv.org/abs/2105.03011
- [12]
-
[13]
Graphcore. 2023. Poplar SDK Documentation.https://docs.graphcore .ai/
work page 2023
-
[14]
Graphcore Research. 2024. SparQ Attention: Speed up LLM inference with top-k Value reads.https://graphcore-research.github.io/posts/s parq/
work page 2024
-
[15]
Arpan Gujarati, Reza Karrell, Seth Ganesan, Avinash Vachharajani, H Ramachandran, et al. 2020. Serving DNNs like Clockwork: Perfor- mance Predictability from the Bottom Up. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USENIX As- sociation, Berkeley, CA, USA, 443–462.https://www.usenix.org/con ference/osdi20/presentation/gujarati
work page 2020
-
[16]
Huanle He, Lin Jin, Yizhe Cai, Jeeyong Kim, Taejoon Kang, Simin Chen, Ran Tian, Yifeng Zhang, Sizhe Zheng, Yi Yang, et al . 2025. WaferLLM: Large Language Model Inference at Wafer Scale. In19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25). USENIX Association, Berkeley, CA, USA, 41–57.https: //www.usenix.org/conference/osdi25/p...
work page 2025
-
[17]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. 2024. RULER: What’s the Real Context Size of Your Long-Context Language Models? arXiv preprint arXiv:2404.06654.https://arxiv.org/abs/2404.06654
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Ziyu Hu, Zhiqing Zhong, Weijian Zheng, Zhijing Ye, Xuwei Tan, Xueru Zhang, Zheng Xie, Rajkumar Kettimuthu, and Xiaodong Yu. 2025. DABench-LLM: Standardized and In-Depth Benchmarking of Post- Moore Dataflow AI Accelerators for LLMs . In2025 IEEE International Symposium on Workload Characterization (IISWC). IEEE Computer Society, Los Alamitos, CA, USA, 127–...
- [19]
-
[20]
Norm Jouppi, George Kurian, Sheng Li, Peter Ma, Rahul Nagarajan, Lifeng Nai, Nishant Patil, Suvinay Subramanian, Andy Swing, Brian Towles, et al. 2023. TPU v4: An optically reconfigurable supercom- puter for machine learning with hardware support for embeddings. In Proceedings of the 50th Annual International Symposium on Computer Architecture (ISCA). Ass...
-
[21]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E Gonzalez, Hao Zhang, and Ion Stoica
-
[22]
InProceedings of the 29th Symposium on Operating Systems Principles (SOSP)
Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP). Association for Computing Machinery, New York, NY, USA, 611–626.https://arxiv.org/abs/2309 .06180
-
[23]
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen
-
[24]
SnapKV: LLM Knows What You are Looking for Before Generation
SnapKV: LLM knows what you are looking for before gener- ation. InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada)(NIPS ’24). Curran Associates Inc., Red Hook, NY, USA, Article 722, 24 pages. https://arxiv.org/abs/2404.14469
work page internal anchor Pith review arXiv
-
[25]
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E Gonzalez, and Ion Stoica. 2023. AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving. 17th USENIX Symposium on Operating Systems Design and Implementation (OSDI).https: //www.usenix.org/conference/osdi...
work page 2023
- [26]
-
[27]
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Anantha- narayanan, et al. 2024. Cachegen: Kv cache compression and stream- ing for fast large language model serving. InProceedings of the ACM SIGCOMM 2024 Conference. Association for Computing Machinery, New York, NY, USA, 38–56. doi:10.1...
-
[28]
Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, Luis Ceze, Alex Beutel, and Christopher Ré. 2023. Deja Vu: Contextual sparsity for efficient LLMs at inference time. InInternational Conference on Machine Learning (ICML). PMLR, PMLR, Honolulu, HI, USA, 22137–22176.https://arxiv.org/abs/2310.1 7157
work page 2023
-
[29]
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen (Henry) Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. 2024. KIVI: a tuning- free asymmetric 2bit quantization for KV cache. InProceedings of the 41st International Conference on Machine Learning(Vienna, Austria) (ICML’24). JMLR.org, Cambridge, MA, USA, Article 1311, 13 pages. https://arxiv.org/...
work page internal anchor Pith review arXiv 2024
-
[30]
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher
-
[31]
Pointer Sentinel Mixture Models
Pointer Sentinel Mixture Models. International Conference on Learning Representations (ICLR).https://arxiv.org/abs/1609.07843
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Microsoft. 2023. AzureLLMInferenceDataset2023.https://github.com /Azure/AzurePublicDataset/blob/master/AzureLLMInferenceDatas et2023.md
work page 2023
-
[33]
NVIDIA. 2023. TensorRT-LLM: A High-Performance Library for LLM Inference.https://github.com/NVIDIA/TensorRT-LLM
work page 2023
-
[34]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aagan Shah, Iñigo Goiri Wisniewski, David Koufaty, et al. 2024. Splitwise: Efficient Generative LLM Inference Using Phase Splitting. InProceedings of the 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, Los Alamitos, CA, USA, 211–224. doi:10.1109/ISCA59077.2024.00019
-
[35]
Raghu Prabhakar, Ram Sivaramakrishnan, Darshan Gandhi, Yun Du, Mingran Wang, Xiangyu Song, Kejie Zhang, Tianren Gao, Angela Wang, Xiaoyan Li, Yongning Sheng, Joshua Brot, Denis Sokolov, Apurv Vivek, Calvin Leung, Arjun Sabnis, Jiayu Bai, Tuowen Zhao, Mark Gottscho, David Jackson, Mark Luttrell, Manish K. Shah, Zhengyu Chen, Kaizhao Liang, Swayambhoo Jain,...
-
[36]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Mooncake: Trading More Storage for Less Computation — A KVCache-centric Architecture for Serving LLM Chatbot. In23rd USENIX Conference on File and Storage Technologies (FAST 25). USENIX Association, Santa Clara, CA, 155–170.https://www.us...
work page 2025
-
[37]
Amit Sabne. 2020. XLA: Compiling machine learning for peak per- formance. Proceedings of the 3rd Conference on Machine Learning and Systems (MLSys).https://research.google/pubs/xla-compiling- machine-learning-for-peak-performance/
work page 2020
-
[38]
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. 2024. Llumnix: Dynamic Scheduling for Large Language Model Serving. 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI).https://www.usenix.org /conference/osdi24/presentation/sun-biaoUSENIX Association
work page 2024
-
[39]
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. 2024. QUEST: query-aware sparsity for efficient long- context LLM inference. InProceedings of the 41st International Con- ference on Machine Learning(Vienna, Austria)(ICML’24). JMLR.org, Cambridge, MA, USA, Article 1955, 11 pages.https://arxiv.org/abs/24 06.10774 13
work page 2024
-
[40]
Bingyang Wu, Yinmin Zhong, Zizheng Gupta, Whan Huang, Christo- pher Ré, DA Ce, and Kai Li. 2023. FastServe: Lean-quanta imple- mentation of preemptive scheduling for distributed LLM serving. In Proceedings of the 17th USENIX Symposium on Operating Systems De- sign and Implementation (OSDI). USENIX Association, Berkeley, CA, USA, 1197–1213.https://arxiv.or...
-
[41]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. Efficient Streaming Language Models with Attention Sinks.https://arxiv.org/abs/2309.17453
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP).https://arxiv.org/abs/1809.09600
work page internal anchor Pith review arXiv 2018
-
[43]
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. 2025. CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion. InProceedings of the Twentieth European Conference on Com- puter Systems. Association for Computing Machinery, New York, NY, USA, 94–109. doi:10.1145/36...
- [44]
-
[45]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A distributed serving system for Transformer-based generative models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USENIX Associ- ation, Berkeley, CA, USA, 521–538.https://www.usenix.org/confere nce/osdi22/presentation/yu
work page 2022
-
[46]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. 2024. H2O: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems (NeurIPS).https://arxiv.org/abs/2306.14048
-
[47]
SGLang: Efficient Execution of Structured Language Model Programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: efficient execution of structured language model programs. InPro- ceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC,...
work page internal anchor Pith review arXiv 2024
-
[48]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI).https://www.usenix.org/conference/osdi24 /presentation/zhong-yinminUSENIX Ass...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.