Recognition: no theorem link
EgoMemReason: A Memory-Driven Reasoning Benchmark for Long-Horizon Egocentric Video Understanding
Pith reviewed 2026-05-12 04:32 UTC · model grok-4.3
The pith
Current AI models reach only 39.6 percent accuracy on memory-driven reasoning over week-long egocentric videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
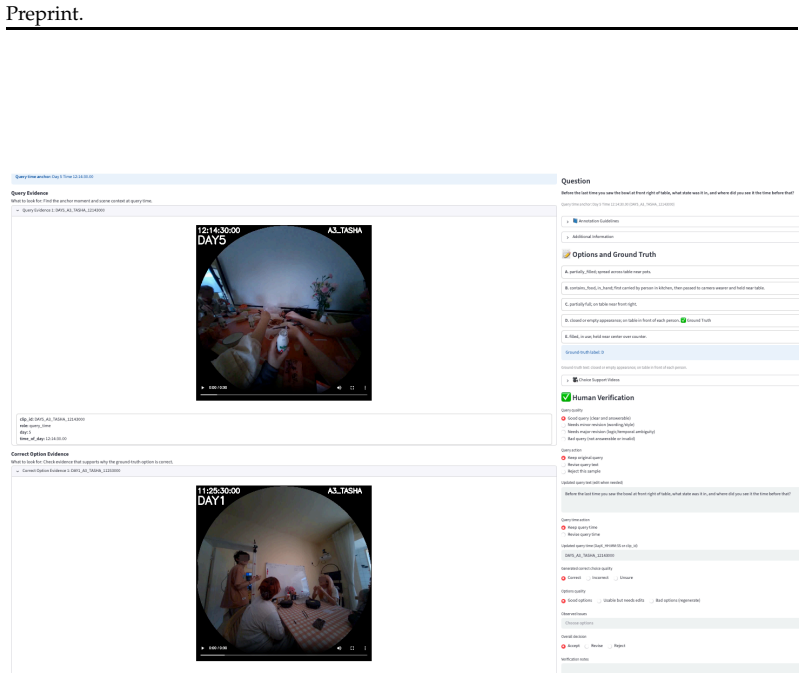
EgoMemReason supplies 500 questions across entity memory, event memory, and behavior memory. Each question draws on an average of 5.1 video segments and requires backtracking through as much as 25.9 hours of footage. Evaluation of seventeen multimodal models and agent frameworks establishes that no current approach exceeds 39.6 percent accuracy. The three memory categories exhibit different failure modes, and accuracy declines steadily with longer temporal distances between evidence clips.
What carries the argument
EgoMemReason benchmark, organized around three memory types that each require accumulation, recall, and abstraction of evidence scattered across multiple days of egocentric video.
If this is right
- Models will require new architectures that explicitly accumulate and index information over multi-day spans.
- Performance falls as the interval between relevant evidence increases, so temporal modeling must scale beyond current context windows.
- Entity, event, and behavior memory each break for different reasons, implying that progress needs targeted components rather than uniform scaling.
- Practical always-on visual assistants cannot be deployed until accuracy on these tasks rises substantially.
Where Pith is reading between the lines
- Success on this benchmark could directly improve reliability of personal AI systems that maintain ongoing context from a user's daily visual stream.
- The same question format could be adapted to test memory in other continuous data streams such as audio or sensor logs.
- Better long-horizon memory mechanisms would also raise new questions about selective forgetting and privacy management in always-recording devices.
Load-bearing premise
The benchmark questions force genuine cross-day memory use rather than being answerable from short clips or surface patterns alone.
What would settle it
A model that scores above 70 percent on the full set of questions while processing only short local segments without any explicit long-term storage would falsify the claim that long-horizon memory remains unsolved.
Figures







read the original abstract
Next-generation visual assistants, such as smart glasses, embodied agents, and always-on life-logging systems, must reason over an entire day or more of continuous visual experience. In ultra-long video settings, relevant information is sparsely distributed across hours or days, making memory a fundamental challenge: models must accumulate information over time, recall prior states, track temporal order, and abstract recurring patterns. However, existing week-long video benchmarks are primarily designed for perception and recognition, such as moment localization or global summarization, rather than reasoning that requires integrating evidence across multiple days. To address this gap, we introduce EgoMemReason, a comprehensive benchmark that systematically evaluates week-long egocentric video understanding through memory-driven reasoning. EgoMemReason evaluates three complementary memory types: entity memory, tracking how object states evolve and change across days; event memory, recalling and ordering activities separated by hours or days; and behavior memory, abstracting recurring patterns from sparse, repeated observations over the whole week period. EgoMemReason comprises 500 questions across three memory types and six core challenges, with an average of 5.1 video segments of evidence per question and 25.9 hours of memory backtracking. We evaluate EgoMemReason on 17 methods across MLLMs and agentic frameworks, revealing that even the best model achieves only 39.6% overall accuracy. Further analysis shows that the three memory types fail for distinct reasons and that performance degrades as evidence spans longer temporal horizons, revealing that long-horizon memory remains far from solved. We believe EgoMemReason establishes a strong foundation for evaluating and advancing long-context, memory-aware multimodal systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EgoMemReason, a benchmark for memory-driven reasoning over week-long egocentric videos. It defines three memory types (entity memory for object state changes, event memory for ordering activities across hours/days, and behavior memory for abstracting recurring patterns) across six core challenges, comprising 500 questions with an average of 5.1 evidence segments and 25.9 hours of backtracking per question. Evaluation of 17 MLLM and agentic methods shows a best-case accuracy of 39.6%, with further analysis indicating distinct failure modes per memory type and degradation over longer temporal spans, leading to the conclusion that long-horizon memory remains far from solved.
Significance. If the benchmark questions are confirmed to require genuine cross-day evidence integration, this work would provide a valuable new resource for evaluating memory capabilities in multimodal systems, addressing a gap left by existing week-long video benchmarks focused on perception or summarization. The categorization into complementary memory types, the scale of evidence backtracking, and the consistent low performance across diverse methods offer concrete directions for future model development in applications such as smart glasses and life-logging agents. The explicit reporting of average evidence segments and temporal horizons is a positive aspect of the design.
major comments (1)
- [§3] §3 (Benchmark Construction): The manuscript provides no details on question generation process, validation that questions necessitate multi-day memory integration (vs. single-segment or superficial cues), inter-annotator agreement, or explicit controls for dataset biases and shortcuts. This is load-bearing for the central claim, as the reported 39.6% ceiling accuracy and the assertion that 'long-horizon memory remains far from solved' (abstract) rest on the 500 questions accurately measuring the three intended memory types without artifacts.
minor comments (2)
- [Abstract] Abstract: Specify the identity of the single best model achieving 39.6% overall accuracy and include a brief per-memory-type breakdown to make the headline result more informative.
- [§5] §5 (Experiments): Ensure the six core challenges are explicitly enumerated and linked to the three memory types with example questions for reader clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps strengthen the manuscript. We address the major comment on benchmark construction below and will revise accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The manuscript provides no details on question generation process, validation that questions necessitate multi-day memory integration (vs. single-segment or superficial cues), inter-annotator agreement, or explicit controls for dataset biases and shortcuts. This is load-bearing for the central claim, as the reported 39.6% ceiling accuracy and the assertion that 'long-horizon memory remains far from solved' (abstract) rest on the 500 questions accurately measuring the three intended memory types without artifacts.
Authors: We agree that the original §3 provided insufficient detail on the construction pipeline, which is critical for validating the benchmark's claims. In the revised manuscript we will expand §3 with a dedicated subsection on question generation: questions were created by human annotators who first reviewed complete week-long timelines to identify sparse evidence spanning multiple days, then formulated queries requiring integration across those segments. We will add quantitative validation showing that >90% of questions cannot be solved from any single segment (via per-question evidence ablation) and that superficial cues were filtered through a multi-stage review. Inter-annotator agreement (Cohen's κ) for memory-type labeling and evidence-segment selection will be reported. Finally, we will include explicit bias controls, such as content diversity checks across subjects and environments plus shortcut analysis (e.g., lexical overlap or temporal heuristics). These additions directly substantiate that the 39.6% ceiling reflects genuine long-horizon memory demands rather than artifacts. revision: yes
Circularity Check
No significant circularity: independent benchmark with empirical evaluation only
full rationale
The paper introduces EgoMemReason as a new benchmark with 500 questions across three memory types, constructed from week-long egocentric videos with specified evidence requirements (average 5.1 segments, 25.9h backtracking). It then reports direct accuracy results from evaluating 17 existing MLLM and agentic methods, with the 39.6% top score presented as an empirical observation rather than a derived quantity. No equations, fitted parameters, self-definitional claims, or load-bearing self-citations appear in the abstract or described construction. The evaluation chain is self-contained: question design and model testing are independent of any prior author derivations, making the low-performance conclusion falsifiable on the benchmark itself without reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Entity memory, event memory, and behavior memory constitute the primary complementary challenges for long-horizon egocentric video reasoning.
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
Gemini 3.1 Pro Model Card , year =
-
[3]
StreamingVLM: Real-Time Understanding for Infinite Video Streams , author=. 2025 , eprint=
work page 2025
-
[4]
arXiv preprint arXiv:2507.05257 , year=
Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions , author=. arXiv preprint arXiv:2507.05257 , year=
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Islam, Md Mohaiminul and Nagarajan, Tushar and Wang, Huiyu and Bertasius, Gedas and Torresani, Lorenzo , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[6]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Islam, Md Mohaiminul and Ho, Ngan and Yang, Xitong and Nagarajan, Tushar and Torresani, Lorenzo and Bertasius, Gedas , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[7]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,
A Simple LLM Framework for Long-Range Video Question-Answering , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,
work page 2024
-
[8]
URL https://openreview.net/forum?id=ehfRiF0R3a
Mem- : Learning Memory Construction via Reinforcement Learning , author=. arXiv preprint arXiv:2509.25911 , year=
-
[9]
arXiv preprint arXiv:2506.13356 , year=
Storybench: A dynamic benchmark for evaluating long-term memory with multi turns , author=. arXiv preprint arXiv:2506.13356 , year=
-
[10]
arXiv preprint arXiv:2603.07392 , year=
Can Large Language Models Keep Up? Benchmarking Online Adaptation to Continual Knowledge Streams , author=. arXiv preprint arXiv:2603.07392 , year=
-
[11]
RULER: What's the Real Context Size of Your Long-Context Language Models? , author=. 2024 , journal=
work page 2024
-
[12]
Advances in Neural Information Processing Systems , volume=
Babilong: Testing the limits of llms with long context reasoning-in-a-haystack , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei , title =. arxiv , year =
-
[14]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory , author=. 2024 , eprint=
work page 2024
-
[15]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis , author=. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
work page 2025
-
[16]
LVBench: An Extreme Long Video Understanding Benchmark , author=. ArXiv , year=
-
[17]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
MLVU: Benchmarking Multi-task Long Video Understanding , author=. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
work page 2025
-
[18]
LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding , author=. ArXiv , year=
-
[19]
arXiv preprint arXiv:2510.23981 , year=
TeleEgo: Benchmarking Egocentric AI Assistants in the Wild , author=. arXiv preprint arXiv:2510.23981 , year=
-
[20]
Towards Multimodal Lifelong Understanding: A Dataset and Agentic Baseline , author=. 2026 , eprint=
work page 2026
-
[21]
Organization of Memory , editor =
Tulving, Endel , title =. Organization of Memory , editor =. 1972 , pages =
work page 1972
- [22]
- [23]
-
[24]
arXiv preprint arXiv:2504.13079 , year=
Retrieval-augmented generation with conflicting evidence , author=. arXiv preprint arXiv:2504.13079 , year=
-
[25]
CORG: Generating answers from complex, interrelated contexts , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2025
-
[26]
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[27]
Advances in Neural Information Processing Systems , year=
HourVideo: 1-Hour Video-Language Understanding , author=. Advances in Neural Information Processing Systems , year=
-
[28]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Nagrani, Arsha and Menon, Sachit and Iscen, Ahmet and Buch, Shyamal and Mehran, Ramin and Jha, Nilpa and Hauth, Anja and Zhu, Yukun and Vondrick, Carl and Sirotenko, Mikhail and Schmid, Cordelia and Weyand, Tobias , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
work page 2025
-
[29]
Deep Video Discovery: Agentic Search with Tool Use for Long-form Video Understanding , author=. arXiv preprint arXiv:2505.18079 , year=
-
[30]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Wang, Weihan and He, Zehai and Hong, Wenyi and Cheng, Yean and Zhang, Xiaohan and Qi, Ji and Ding, Ming and Gu, Xiaotao and Huang, Shiyu and Xu, Bin and Dong, Yuxiao and Tang, Jie , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2025 , pages =
work page 2025
-
[31]
Cambrian-s: Towards spatial supersens- ing in video.arXiv preprint arXiv:2511.04670, 2025
Cambrian-S: Towards Spatial Supersensing in Video , author=. arXiv preprint arXiv:2511.04670 , year=
-
[32]
Adversarial NLI : A new benchmark for natural language understanding
Nie, Yixin and Williams, Adina and Dinan, Emily and Bansal, Mohit and Weston, Jason and Kiela, Douwe. Adversarial NLI : A New Benchmark for Natural Language Understanding. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.441
-
[33]
Zaranis, Emmanouil and Farinhas, Ant. Movie Facts and Fibs (MF \^. arXiv preprint arXiv:2506.06275 , year=
-
[34]
arXiv preprint arXiv:2505.22657 , year=
3dllm-mem: Long-term spatial-temporal memory for embodied 3d large language model , author=. arXiv preprint arXiv:2505.22657 , year=
-
[35]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
3D-mem: 3D scene memory for embodied exploration and reasoning , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[36]
Generative Agents: Interactive Simulacra of Human Behavior , author =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST) , year =
-
[37]
ACM Transactions on Information Systems , year =
A Survey on the Memory Mechanism of Large Language Model based Agents , author =. ACM Transactions on Information Systems , year =
-
[38]
Tan, Haoran and Zhang, Zeyu and Ma, Chen and Chen, Xu and Dai, Quanyu and Dong, Zhenhua , booktitle =
-
[39]
Psychological Review , volume =
Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory , author =. Psychological Review , volume =. 1995 , doi =
work page 1995
-
[40]
Kumaran, Dharshan and Hassabis, Demis and McClelland, James L. , journal =. What learning systems do intelligent agents need?. 2016 , doi =
work page 2016
-
[41]
Philosophical Transactions of the Royal Society B , volume =
Distinct mechanisms and functions of episodic memory , author =. Philosophical Transactions of the Royal Society B , volume =. 2024 , doi =
work page 2024
-
[42]
ACM Transactions on Information Systems , year =
A Survey on the Memory Mechanism of Large Language Model based Agents , author =. ACM Transactions on Information Systems , year =. doi:10.1145/3748302 , note =
-
[43]
Liu, Shichun and others , journal =. From Human Memory to. 2025 , url =
work page 2025
-
[44]
Memory in Large Language Models: Mechanisms, Evaluation and Evolution , author =. arXiv preprint arXiv:2509.18868 , year =
-
[45]
Liang, Jiafeng and Li, Hao and Li, Chang and Zhou, Jiaqi and Jiang, Shixin and Wang, Zekun and Ji, Changkai and Zhu, Zhihao and Liu, Runxuan and Ren, Tao and Fu, Jinlan and Ng, See-Kiong and Liang, Xia and Liu, Ming and Qin, Bing , journal =. 2025 , url =
work page 2025
-
[46]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Guti. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[47]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
A Machine with Short-Term, Episodic, and Semantic Memory Systems , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2023 , doi =
work page 2023
-
[48]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Movieqa: Understanding stories in movies through question-answering , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[49]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
Tvqa: Localized, compositional video question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
work page 2018
-
[50]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Tgif-qa: Toward spatio-temporal reasoning in visual question answering , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[51]
TALL: Temporal Activity Localization via Language Query , author=. ICCV , year=
- [52]
-
[53]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Tvqa+: Spatio-temporal grounding for video question answering , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[54]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Next-qa: Next phase of question-answering to explaining temporal actions , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[55]
STAR: A Benchmark for Situ- ated Reasoning in Real-World Videos.arXiv e-prints, art
Star: A benchmark for situated reasoning in real-world videos , author=. arXiv preprint arXiv:2405.09711 , year=
-
[56]
Is space-time attention all you need for video understanding? , author=. Icml , volume=
-
[57]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Vivit: A video vision transformer , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[58]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Multiscale vision transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[59]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Slowfast networks for video recognition , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[60]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Long-term feature banks for detailed video understanding , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[61]
World models , author=. arXiv preprint arXiv:1803.10122 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
MA-EgoQA: Question Answering over Egocentric Videos from Multiple Embodied Agents , author=. arXiv preprint arXiv:2603.09827 , year=
-
[63]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[64]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[65]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Episodic memory question answering , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[66]
arXiv preprint arXiv:2510.12422 , year=
VideoLucy: Deep Memory Backtracking for Long Video Understanding , author=. arXiv preprint arXiv:2510.12422 , year=
-
[67]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[68]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Ma-lmm: Memory-augmented large multimodal model for long-term video understanding , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[69]
Advances in Neural Information Processing Systems , volume=
Streaming long video understanding with large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[70]
Seeing, listening, remembering, and reasoning: A multimodal agent with long-term memory
Seeing, listening, remembering, and reasoning: A multimodal agent with long-term memory , author=. arXiv preprint arXiv:2508.09736 , year=
-
[71]
arXiv preprint arXiv:2601.03515 , year=
Mem-gallery: Benchmarking multimodal long-term conversational memory for mllm agents , author=. arXiv preprint arXiv:2601.03515 , year=
-
[72]
Active Video Perception: Iterative Evidence Seeking for Agentic Long Video Understanding , author=. arXiv preprint arXiv:2512.05774 , year=
-
[73]
arXiv preprint arXiv:2510.09608 , year=
Streamingvlm: Real-time understanding for infinite video streams , author=. arXiv preprint arXiv:2510.09608 , year=
-
[74]
arXiv preprint arXiv:2512.04540 , year=
VideoMem: Enhancing Ultra-Long Video Understanding via Adaptive Memory Management , author=. arXiv preprint arXiv:2512.04540 , year=
-
[75]
arXiv preprint arXiv:2510.04428 , year=
AIR: Enabling Adaptive, Iterative, and Reasoning-based Frame Selection For Video Question Answering , author=. arXiv preprint arXiv:2510.04428 , year=
-
[76]
arXiv preprint arXiv:2603.05484 , year=
Towards Multimodal Lifelong Understanding: A Dataset and Agentic Baseline , author=. arXiv preprint arXiv:2603.05484 , year=
-
[77]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Adaptive keyframe sampling for long video understanding , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[78]
European Conference on Computer Vision , pages=
Videoagent: Long-form video understanding with large language model as agent , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[79]
European Conference on Computer Vision , pages=
Videoagent: A memory-augmented multimodal agent for video understanding , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[80]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Moviechat: From dense token to sparse memory for long video understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.