Recognition: 2 theorem links
· Lean TheoremAct Wisely: Cultivating Meta-Cognitive Tool Use in Agentic Multimodal Models
Pith reviewed 2026-05-10 18:30 UTC · model grok-4.3
The pith
By reframing tool efficiency as a conditional objective rather than a competing reward, multimodal agents can achieve both fewer tool calls and higher accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HDPO maintains two orthogonal optimization channels: an accuracy channel that maximizes task correctness across all trajectories, and an efficiency channel that applies conditional advantage estimation to enforce execution economy only within accurate trajectories, thereby inducing meta-cognitive behavior that reduces tool invocations while raising accuracy.
What carries the argument
HDPO, the framework that decouples accuracy maximization from efficiency enforcement via conditional advantage estimation applied exclusively on accurate trajectories.
If this is right
- The agent follows a natural curriculum, achieving task correctness before refining tool economy.
- Tool invocations decrease by orders of magnitude on the same tasks.
- Reasoning accuracy rises at the same time, removing the usual efficiency-accuracy trade-off.
- No scalar penalty is needed, eliminating the dilemma of reward variance swallowing the efficiency signal.
- The agent learns to arbitrate between internal knowledge and external utilities without reflexive tool calls.
Where Pith is reading between the lines
- The same conditional-channel approach could extend to other multi-objective agent settings where one goal must not interfere with another, such as speed versus completeness.
- Deployment latency in interactive multimodal applications would drop substantially once tool calls are limited to genuinely necessary cases.
- Testing the same separation on language-only agents could reveal whether meta-cognitive self-reliance emerges in non-visual domains.
- If the curriculum effect holds, future work might deliberately stage training to first saturate accuracy before activating efficiency constraints.
Load-bearing premise
The two optimization channels remain independent in practice and conditional advantage estimation on accurate trajectories alone suffices to produce the desired meta-cognitive behavior without introducing instabilities or biases.
What would settle it
A side-by-side evaluation on tasks solvable from raw visual context alone, showing either persistent high tool usage rates or a drop in accuracy when the efficiency channel is active, would disprove the claim.
Figures







read the original abstract
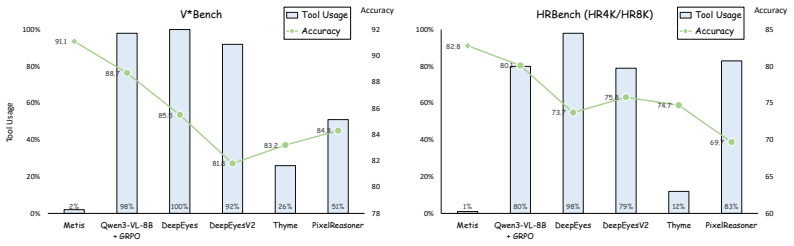
The advent of agentic multimodal models has empowered systems to actively interact with external environments. However, current agents suffer from a profound meta-cognitive deficit: they struggle to arbitrate between leveraging internal knowledge and querying external utilities. Consequently, they frequently fall prey to blind tool invocation, resorting to reflexive tool execution even when queries are resolvable from the raw visual context. This pathological behavior precipitates severe latency bottlenecks and injects extraneous noise that derails sound reasoning. Existing reinforcement learning protocols attempt to mitigate this via a scalarized reward that penalizes tool usage. Yet, this coupled formulation creates an irreconcilable optimization dilemma: an aggressive penalty suppresses essential tool use, whereas a mild penalty is entirely subsumed by the variance of the accuracy reward during advantage normalization, rendering it impotent against tool overuse. To transcend this bottleneck, we propose HDPO, a framework that reframes tool efficiency from a competing scalar objective to a strictly conditional one. By eschewing reward scalarization, HDPO maintains two orthogonal optimization channels: an accuracy channel that maximizes task correctness, and an efficiency channel that enforces execution economy exclusively within accurate trajectories via conditional advantage estimation. This decoupled architecture naturally induces a cognitive curriculum-compelling the agent to first master task resolution before refining its self-reliance. Extensive evaluations demonstrate that our resulting model, Metis, reduces tool invocations by orders of magnitude while simultaneously elevating reasoning accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that current agentic multimodal models exhibit a meta-cognitive deficit leading to excessive tool invocation even when internal knowledge suffices. It identifies an optimization dilemma in scalarized RL rewards for tool efficiency and proposes HDPO, which decouples accuracy maximization (on all trajectories) from efficiency enforcement (via conditional advantage estimation only on accurate trajectories). This is said to induce a cognitive curriculum and yield the Metis model, which reduces tool invocations by orders of magnitude while increasing reasoning accuracy.
Significance. If the central claims hold and the orthogonality of channels is empirically validated without hidden interactions or selection bias, the work would represent a meaningful methodological advance for training efficient agentic systems. The reframing of efficiency as a strictly conditional objective rather than a competing scalar term could influence RL design for tool-using agents more broadly, particularly in multimodal settings where latency and noise from unnecessary tool calls are costly.
major comments (2)
- [Abstract] Abstract: The description of HDPO provides no equations, pseudocode, or derivation for the conditional advantage estimation procedure or the two orthogonal channels. Without these, it is impossible to verify whether the accuracy and efficiency signals remain decoupled in practice or whether they interact through the shared policy and value networks, which is load-bearing for the claim that scalarization is avoided.
- [Abstract] Abstract: The manuscript states that 'extensive evaluations demonstrate' orders-of-magnitude reduction in tool use with simultaneous accuracy gains, yet supplies no accuracy rates on trajectories, difficulty stratification, advantage variance within the conditioned subset, or ablation results. This leaves the central empirical claim unverifiable and does not address the risk that conditioning efficiency solely on accurate trajectories could introduce selection bias on low-complexity queries.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed report. The comments highlight important aspects of clarity in the HDPO description and the presentation of empirical results. We address each major comment below and indicate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The description of HDPO provides no equations, pseudocode, or derivation for the conditional advantage estimation procedure or the two orthogonal channels. Without these, it is impossible to verify whether the accuracy and efficiency signals remain decoupled in practice or whether they interact through the shared policy and value networks, which is load-bearing for the claim that scalarization is avoided.
Authors: We agree that the abstract, due to length constraints, presents HDPO at a conceptual level without equations or pseudocode. The full manuscript (Section 3) defines the two channels explicitly: the accuracy channel computes standard advantages over all trajectories to maximize correctness, while the efficiency channel computes conditional advantages exclusively on accurate trajectories (i.e., advantage masked by an accuracy indicator function). This formulation avoids scalarization by design, as the efficiency term is never added to the accuracy reward and does not alter value estimates for inaccurate trajectories. Shared policy and value networks are used, but the objectives remain orthogonal because efficiency updates are gated and do not create a competing gradient with accuracy. To improve verifiability, we will revise the abstract to include a concise statement of the conditional advantage procedure and reference the key formulation from the main text. revision: yes
-
Referee: [Abstract] Abstract: The manuscript states that 'extensive evaluations demonstrate' orders-of-magnitude reduction in tool use with simultaneous accuracy gains, yet supplies no accuracy rates on trajectories, difficulty stratification, advantage variance within the conditioned subset, or ablation results. This leaves the central empirical claim unverifiable and does not address the risk that conditioning efficiency solely on accurate trajectories could introduce selection bias on low-complexity queries.
Authors: The referee is correct that the abstract itself contains no numerical results or stratification details. The full experimental section reports aggregate accuracy improvements alongside tool-use reductions, with some difficulty-based breakdowns and ablations on the conditional mechanism. However, specific per-trajectory accuracy rates, advantage variance within the accurate subset, and explicit selection-bias diagnostics are not currently tabulated. Conditioning on accuracy does not inherently bias toward low-complexity queries because the accuracy channel remains unconditional and must be satisfied across the full distribution before efficiency refinement occurs; this curriculum structure encourages self-reliance on harder cases as well. To make the claims fully verifiable, we will expand the abstract with a brief summary of key metrics and add the requested stratification, variance statistics, and bias analysis to the experiments section in the revision. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces HDPO as a methodological reframing that separates accuracy maximization from conditional efficiency enforcement on accurate trajectories only. This is presented as an independent architectural choice whose benefits are demonstrated via evaluations on the resulting Metis model. No equations, derivations, or self-citations are shown that reduce the claimed orthogonality, cognitive curriculum, or performance gains to fitted parameters, prior self-work, or definitional tautologies. The central claims rest on empirical results rather than any load-bearing reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearHDPO maintains two orthogonal optimization channels: an accuracy channel that maximizes task correctness, and an efficiency channel that enforces execution economy exclusively within accurate trajectories via conditional advantage estimation.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction unclearThis decoupled architecture naturally induces a cognitive curriculum—compelling the agent to first master task resolution before refining its self-reliance.
Forward citations
Cited by 2 Pith papers
-
TRACER: Verifiable Generative Provenance for Multimodal Tool-Using Agents
TRACER attaches verifiable sentence-level provenance records to multimodal agent outputs using tool-turn alignment and semantic relations, yielding 78.23% answer accuracy and fewer tool calls than baselines on TRACE-Bench.
-
Hallucinations Undermine Trust; Metacognition is a Way Forward
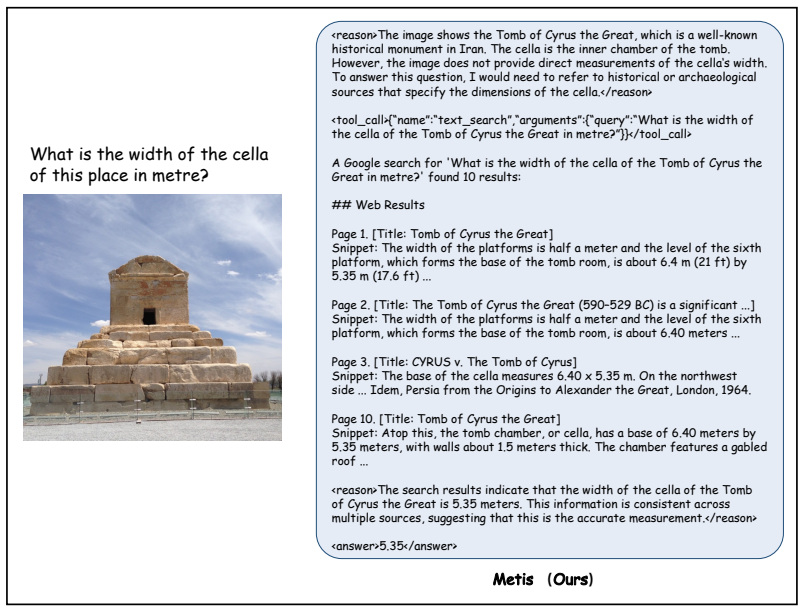
LLMs need metacognition to align expressed uncertainty with their actual knowledge boundaries, moving beyond knowledge expansion to reduce confident errors.
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Sft or rl? an early investigation into training r1-like reasoning large vision-language models
Hardy Chen, Haoqin Tu, Fali Wang, Hui Liu, Xianfeng Tang, Xinya Du, Yuyin Zhou, and Cihang Xie. Sft or rl? an early investigation into training r1-like reasoning large vision-language models.arXiv preprint arXiv:2504.11468, 2025
-
[5]
Yong Xien Chng, Tao Hu, Wenwen Tong, Xueheng Li, Jiandong Chen, Haojia Yu, Jiefan Lu, Hewei Guo, Hanming Deng, Chengjun Xie, et al. Sensenova-mars: Empowering multimodal agentic reasoning and search via reinforcement learning.arXiv preprint arXiv:2512.24330, 2025
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Gemini 3.1 pro: A smarter model for your most complex tasks, 2026
Google. Gemini 3.1 pro: A smarter model for your most complex tasks, 2026. Accessed: 2026-02-19
2026
-
[8]
Deepeyesv2: Toward agentic multimodal model
Jack Hong, Chenxiao Zhao, ChengLin Zhu, Weiheng Lu, Guohai Xu, and Xing Yu. Deepeyesv2: Toward agentic multimodal model.arXiv preprint arXiv:2511.05271, 2025
-
[9]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
work page Pith review arXiv 2025
-
[11]
Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
2022
-
[12]
Mini-o3: Scaling up reasoning patterns and interaction turns for visual search
Xin Lai, Junyi Li, Wei Li, Tao Liu, Tianjian Li, and Hengshuang Zhao. Mini-o3: Scaling up reasoning patterns and interaction turns for visual search.arXiv preprint arXiv:2509.07969, 2025
-
[13]
Latent visual reasoning.arXiv preprint arXiv:2509.24251, 2025
Bangzheng Li, Ximeng Sun, Jiang Liu, Ze Wang, Jialian Wu, Xiaodong Yu, Hao Chen, Emad Barsoum, Muhao Chen, and Zicheng Liu. Latent visual reasoning.arXiv preprint arXiv:2509.24251, 2025
-
[14]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Bohao Li, Yuying Ge, Yi Chen, Yixiao Ge, Ruimao Zhang, and Ying Shan. Seed-bench-2-plus: Benchmarking multimodal large language models with text-rich visual comprehension.arXiv preprint arXiv:2404.16790, 2024
-
[16]
Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
2024
-
[17]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[18]
Visual-RFT: Visual Reinforcement Fine-Tuning
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual-rft: Visual reinforcement fine-tuning.arXiv preprint arXiv:2503.01785, 2025
work page internal anchor Pith review arXiv 2025
-
[19]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023. 14
work page internal anchor Pith review arXiv 2023
-
[20]
Mm-eureka: Exploring visual aha moment with rule-based large-scale reinforcement learning.CoRR, 2025
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Botian Shi, Wenhai Wang, Junjun He, Kaipeng Zhang, et al. Mm-eureka: Exploring visual aha moment with rule-based large-scale reinforcement learning.CoRR, 2025
2025
-
[21]
Runqi Qiao, Qiuna Tan, Guanting Dong, MinhuiWu MinhuiWu, Chong Sun, Xiaoshuai Song, Jiapeng Wang, Zhuoma Gongque, Shanglin Lei, Yifan Zhang, et al. We-math: Does your large multimodal model achieve human-like mathematical reasoning? InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 200...
2025
-
[22]
V-thinker: Interactive thinking with images.arXiv preprint arXiv:2511.04460, 2025
Runqi Qiao, Qiuna Tan, Minghan Yang, Guanting Dong, Peiqing Yang, Shiqiang Lang, Enhui Wan, Xiaowan Wang, Yida Xu, Lan Yang, et al. V-thinker: Interactive thinking with images.arXiv preprint arXiv:2511.04460, 2025
-
[23]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, et al. Vlm-r1: A stable and generalizable r1-style large vision-language model.arXiv preprint arXiv:2504.07615, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
Zoomeye: Enhancing multimodal llms with human-like zooming capabilities through tree-based image exploration
Haozhan Shen, Kangjia Zhao, Tiancheng Zhao, Ruochen Xu, Zilun Zhang, Mingwei Zhu, and Jianwei Yin. Zoomeye: Enhancing multimodal llms with human-like zooming capabilities through tree-based image exploration. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6613–6629, 2025
2025
-
[27]
arXiv preprint arXiv:2512.17312 (2025)
Qi Song, Honglin Li, Yingchen Yu, Haoyi Zhou, Lin Yang, Song Bai, Qi She, Zilong Huang, and Yunqing Zhao. Codedance: A dynamic tool-integrated mllm for executable visual reasoning.arXiv preprint arXiv:2512.17312, 2025
-
[28]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, et al. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers.arXiv preprint arXiv:2506.23918, 2025
work page internal anchor Pith review arXiv 2025
-
[29]
Sketch-in-latents: Eliciting unified reasoning in mllms.CoRR, abs/2512.16584, 2025
Jintao Tong, Jiaqi Gu, Yujing Lou, Lubin Fan, Yixiong Zou, Yue Wu, Jieping Ye, and Ruixuan Li. Sketch-in-latents: Eliciting unified reasoning in mllms.arXiv preprint arXiv:2512.16584, 2025
-
[30]
Emosync: Multi-stage reasoning with multimodal large language models for fine-grained emotion recognition
Jintao Tong, Shiwei Li, Zijian Zhuang, Jinghan Hu, and Yixiong Zou. Emosync: Multi-stage reasoning with multimodal large language models for fine-grained emotion recognition. InProceedings of the 3rd International Workshop on Multimodal and Responsible Affective Computing, pages 95–99, 2025
2025
-
[31]
Jintao Tong, Shilin Yan, Hongwei Xue, Xiaojun Tang, Kunyu Shi, Guannan Zhang, Ruixuan Li, and Yixiong Zou. Swimbird: Eliciting switchable reasoning mode in hybrid autoregressive mllms.arXiv preprint arXiv:2602.06040, 2026
-
[32]
AdaTooler-V: Adaptive Tool-Use for Images and Videos
Chaoyang Wang, Kaituo Feng, Dongyang Chen, Zhongyu Wang, Zhixun Li, Sicheng Gao, Meng Meng, Xu Zhou, Manyuan Zhang, Yuzhang Shang, et al. Adatooler-v: Adaptive tool-use for images and videos. arXiv preprint arXiv:2512.16918, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Vl- rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. Vl-rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning.arXiv preprint arXiv:2504.08837, 2025
-
[34]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Haozhe Wang, Alex Su, Weiming Ren, Fangzhen Lin, and Wenhu Chen. Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning.arXiv preprint arXiv:2505.15966, 2025
work page internal anchor Pith review arXiv 2025
-
[35]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025. 15
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models
Wenbin Wang, Liang Ding, Minyan Zeng, Xiabin Zhou, Li Shen, Yong Luo, Wei Yu, and Dacheng Tao. Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 7907–7915, 2025
2025
-
[38]
Xiyao Wang, Zhengyuan Yang, Chao Feng, Hongjin Lu, Linjie Li, Chung-Ching Lin, Kevin Lin, Furong Huang, and Lijuan Wang. Sota with less: Mcts-guided sample selection for data-efficient visual reasoning self-improvement.arXiv preprint arXiv:2504.07934, 2025
-
[39]
Charxiv: Charting gaps in realistic chart understanding in multimodal llms.Advances in Neural Information Processing Systems, 37:113569–113697, 2024
Zirui Wang, Mengzhou Xia, Luxi He, Howard Chen, Yitao Liu, Richard Zhu, Kaiqu Liang, Xindi Wu, Haotian Liu, Sadhika Malladi, et al. Charxiv: Charting gaps in realistic chart understanding in multimodal llms.Advances in Neural Information Processing Systems, 37:113569–113697, 2024
2024
-
[40]
Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[41]
Mmsearch-r1: Incentivizing lmms to search.arXiv preprint arXiv:2506.20670, 2025
Jinming Wu, Zihao Deng, Wei Li, Yiding Liu, Bo You, Bo Li, Zejun Ma, and Ziwei Liu. Mmsearch-r1: Incentivizing lmms to search.arXiv preprint arXiv:2506.20670, 2025
-
[42]
V?: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V?: Guided visual search as a core mechanism in multimodal llms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13084– 13094, 2024
2024
-
[43]
Yijia Xiao, Edward Sun, Tianyu Liu, and Wei Wang. Logicvista: Multimodal llm logical reasoning benchmark in visual contexts.arXiv preprint arXiv:2407.04973, 2024
-
[44]
Llava-cot: Let vision language models reason step-by-step
Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vision language models reason step-by-step. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2087–2098, 2025
2087
-
[45]
Crosslmm: Decoupling long video sequences from lmms via dual cross-attention mechanisms
Shilin Yan, Jiaming Han, Joey Tsai, Hongwei Xue, Rongyao Fang, Lingyi Hong, Ziyu Guo, and Ray Zhang. Crosslmm: Decoupling long video sequences from lmms via dual cross-attention mechanisms. arXiv preprint arXiv:2505.17020, 2025
-
[46]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[47]
En Yu, Kangheng Lin, Liang Zhao, Jisheng Yin, Yana Wei, Yuang Peng, Haoran Wei, Jianjian Sun, Chunrui Han, Zheng Ge, et al. Perception-r1: Pioneering perception policy with reinforcement learning.arXiv preprint arXiv:2504.07954, 2025
-
[48]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9556–9567, 2024
2024
- [49]
-
[50]
Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InEuropean Conference on Computer Vision, pages 169–186
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InEuropean Conference on Computer Vision, pages 169–186. Springer, 2024
2024
-
[51]
Thyme: Think beyond images.arXiv preprint arXiv:2508.11630, 2025
Yi-Fan Zhang, Xingyu Lu, Shukang Yin, Chaoyou Fu, Wei Chen, Xiao Hu, Bin Wen, Kaiyu Jiang, Changyi Liu, Tianke Zhang, et al. Thyme: Think beyond images.arXiv preprint arXiv:2508.11630, 2025
-
[52]
Yi-Fan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qingsong Wen, Zhang Zhang, et al. Mme-realworld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans?arXiv preprint arXiv:2408.13257, 2024
-
[53]
Yifan Zhang, Liang Hu, Haofeng Sun, Peiyu Wang, Yichen Wei, Shukang Yin, Jiangbo Pei, Wei Shen, Peng Xia, Yi Peng, et al. Skywork-r1v4: Toward agentic multimodal intelligence through interleaved thinking with images and deepresearch.arXiv preprint arXiv:2512.02395, 2025. 16
-
[54]
Think3d: Thinking with space for spatial reasoning
Zaibin Zhang, Yuhan Wu, Lianjie Jia, Yifan Wang, Zhongbo Zhang, Yijiang Li, Binghao Ran, Fuxi Zhang, Zhuohan Sun, Zhenfei Yin, et al. Think3d: Thinking with space for spatial reasoning.arXiv preprint arXiv:2601.13029, 2026
-
[55]
arXiv preprint arXiv:2507.07998 (2025)
Shitian Zhao, Haoquan Zhang, Shaoheng Lin, Ming Li, Qilong Wu, Kaipeng Zhang, and Chen Wei. Pyvision: Agentic vision with dynamic tooling.arXiv preprint arXiv:2507.07998, 2025
-
[56]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing" thinking with images" via reinforcement learning.arXiv preprint arXiv:2505.14362, 2025
work page internal anchor Pith review arXiv 2025
-
[57]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Chengke Zou, Xingang Guo, Rui Yang, Junyu Zhang, Bin Hu, and Huan Zhang. Dynamath: A dynamic visual benchmark for evaluating mathematical reasoning robustness of vision language models.arXiv preprint arXiv:2411.00836, 2024. 17 Appendix A System Prompt The system prompt is presented in Figure 6. It explicitly defines the available tool, its calling format,...
-
[59]
ISTRRE-PULA\
Be decisive:Once you are confident in your answer, provide it immediately. Verification is worthwhile only when you are genuinely uncertain about a critical detail, not as a routine step. # Output Format Always start with<reason>...</reason>, then choose one: Option 1 — Use a tool: <reason>Why this tool call is necessary and what you expect to learn.</rea...
-
[60]
[Die Buchtvon Nizza -the bay of nice by Marc Chagall: (1962) ArtPrintPoster | AntiquariatReinhold Berg eKInh. R.Berg]
1962
-
[61]
[Sold at Auction: Marc Chagall, Signed and Attributed to Marc Chagall Lithograph]
-
[62]
Die Buchtvon Nizza
[Sold at Auction: Marc Chagall, MARC CHAGALL (1887-1985)]… … <reason>The image search results suggest that the painting is titled "Die Buchtvon Nizza" by Marc Chagall and was completed in 1962. The information is consistent across multiple search results, indicating that the year of completion is 1962.</reason><answer>1962</answer> Metis (Ours) Figure 8:S...
1985
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.