Recognition: no theorem link
StereoPolicy: Improving Robotic Manipulation Policies via Stereo Perception
Pith reviewed 2026-05-12 03:52 UTC · model grok-4.3
The pith
StereoPolicy processes synchronized stereo image pairs with 2D encoders and a fusion transformer to improve robotic manipulation policies without explicit 3D reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
StereoPolicy directly leverages synchronized stereo image pairs to strengthen geometric reasoning in robot policies. It employs pretrained 2D vision encoders to process each image independently and fuses the resulting representations through a Stereo Transformer. This design implicitly captures spatial correspondence and disparity cues without requiring explicit 3D reconstruction or camera calibration. The framework integrates seamlessly with diffusion-based and pretrained vision-language-action policies and delivers consistent improvements over RGB, RGB-D, point cloud, and multi-view baselines.
What carries the argument
The Stereo Transformer, which fuses feature representations from independent 2D encoders applied to each image in a stereo pair to extract implicit spatial and disparity information.
If this is right
- Consistent gains over RGB, RGB-D, point cloud, and multi-view baselines hold across RoboMimic, RoboCasa, and OmniGibson simulation environments.
- The same framework transfers to real-robot tabletop and bimanual mobile manipulation without additional calibration.
- StereoPolicy combines directly with both diffusion policies and pretrained vision-language-action models.
- Stereo vision functions as a scalable input modality that connects 2D pretrained representations to 3D geometric reasoning.
Where Pith is reading between the lines
- Standard stereo camera rigs could replace depth sensors in many manipulation setups while retaining compatibility with existing 2D encoders.
- The implicit fusion may generalize more readily than explicit 3D reconstruction when camera intrinsics vary across deployments.
- Similar stereo fusion could be tested on navigation or grasping tasks where precise relative positioning matters.
- An open extension is whether adding a lightweight explicit stereo-matching head on top of the transformer would yield further gains.
Load-bearing premise
That independent processing of each stereo view by pretrained 2D encoders followed by transformer-based fusion is sufficient to recover the needed spatial correspondence and depth cues.
What would settle it
An ablation or comparison experiment in which removing the stereo fusion step or switching to monocular input eliminates the reported performance gains on depth-critical manipulation tasks.
Figures











read the original abstract
Recent advances in robot imitation learning have yielded powerful visuomotor policies capable of manipulating a wide variety of objects directly from monocular visual inputs. However, monocular observations inherently lack reliable depth cues and spatial awareness, which are critical for precise manipulation in cluttered or geometrically complex scenes. To address this limitation, we introduce StereoPolicy, a new visuomotor policy learning framework that directly leverages synchronized stereo image pairs to strengthen geometric reasoning, without requiring explicit 3D reconstruction or camera calibration. StereoPolicy employs pretrained 2D vision encoders to process each image independently and fuses the resulting representations through a Stereo Transformer. This design implicitly captures spatial correspondence and disparity cues. The framework integrates seamlessly with diffusion-based and pretrained vision-language-action (VLA) policies, delivering consistent improvements over RGB, RGB-D, point cloud, and multi-view baselines across three simulation benchmarks: RoboMimic, RoboCasa, and OmniGibson. We further validate StereoPolicy on real-robot experiments spanning both tabletop and bimanual mobile manipulation settings. Our results underscore stereo vision as a scalable and robust modality that bridges 2D pretrained representations with 3D geometric understanding for robotic manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces StereoPolicy, a visuomotor policy framework for robotic manipulation that processes synchronized stereo image pairs using independent pretrained 2D vision encoders whose outputs are fused by a Stereo Transformer. This design is claimed to implicitly capture spatial correspondence and disparity cues without explicit 3D reconstruction or camera calibration. The framework integrates with diffusion-based and vision-language-action policies and is reported to deliver consistent improvements over RGB, RGB-D, point-cloud, and multi-view baselines on the RoboMimic, RoboCasa, and OmniGibson simulation benchmarks, with additional validation on real-robot tabletop and bimanual mobile manipulation tasks.
Significance. If the empirical gains are robust and can be attributed to stereo-induced geometric reasoning rather than increased input capacity, the work would offer a practical, calibration-free route to strengthen spatial awareness in existing 2D-pretrained policy architectures. This could be valuable for scaling manipulation policies in cluttered or geometrically complex scenes where monocular depth cues are insufficient.
major comments (2)
- [Abstract] Abstract and results sections: the central claim of 'consistent improvements' across three simulation benchmarks and real-robot settings is asserted without any quantitative metrics, success rates, error bars, or statistical significance tests in the provided abstract; the full results must be examined to verify whether the gains are large enough to support the geometric-reasoning interpretation.
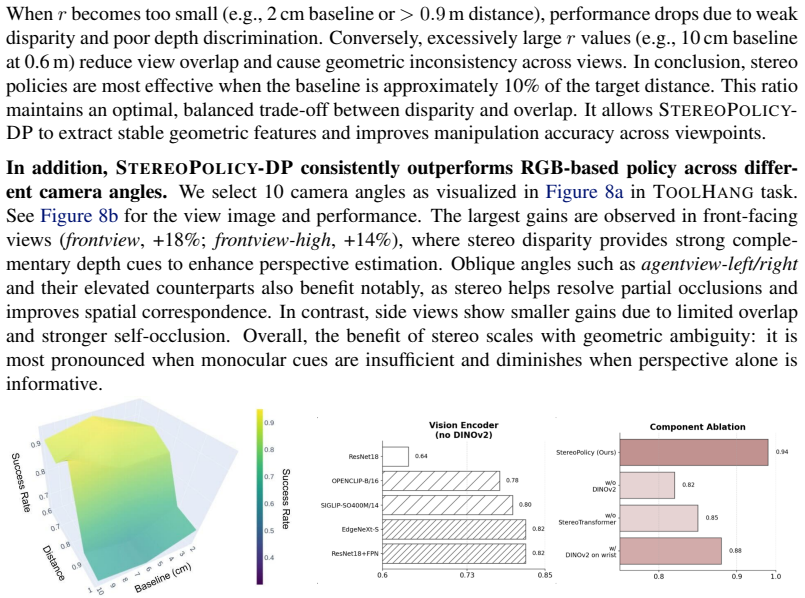
- [Method] Method description of the Stereo Transformer: the assertion that independent 2D-pretrained encoders plus generic transformer fusion 'implicitly captures spatial correspondence and disparity cues' lacks supporting evidence such as attention-map visualizations, disparity estimation accuracy, or an ablation that applies the identical fusion module to non-stereo multi-view pairs; without these, the reported gains could be explained by the extra synchronized view alone rather than 3D understanding.
minor comments (2)
- The paper should provide explicit details on training procedures, hyperparameters, and data augmentation for both simulation and real-robot experiments to support reproducibility.
- Figure captions for real-robot experiments would benefit from additional description of camera setup, baseline comparisons, and failure modes observed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and have revised the manuscript to improve the presentation of quantitative results and to provide additional supporting evidence for the Stereo Transformer's role in capturing geometric cues.
read point-by-point responses
-
Referee: [Abstract] Abstract and results sections: the central claim of 'consistent improvements' across three simulation benchmarks and real-robot settings is asserted without any quantitative metrics, success rates, error bars, or statistical significance tests in the provided abstract; the full results must be examined to verify whether the gains are large enough to support the geometric-reasoning interpretation.
Authors: We agree that the abstract would be strengthened by including concrete metrics. In the revised manuscript we have added representative success-rate improvements and consistency notes drawn from the full experimental tables. The complete results (Sections 4–5) report means and standard deviations over multiple random seeds together with direct comparisons to all baselines; the observed gains remain larger than those obtained from multi-view or RGB-D inputs, supporting the geometric-reasoning interpretation. revision: yes
-
Referee: [Method] Method description of the Stereo Transformer: the assertion that independent 2D-pretrained encoders plus generic transformer fusion 'implicitly captures spatial correspondence and disparity cues' lacks supporting evidence such as attention-map visualizations, disparity estimation accuracy, or an ablation that applies the identical fusion module to non-stereo multi-view pairs; without these, the reported gains could be explained by the extra synchronized view alone rather than 3D understanding.
Authors: We acknowledge that additional evidence strengthens the claim. The existing multi-view baselines already apply comparable fusion to non-stereo image pairs and yield smaller gains than stereo pairs, indicating that the benefit is not explained by input count alone. In the revision we have added attention-map visualizations (new figure in the supplement) that illustrate cross-view correspondence only when stereo pairs are used. We do not report explicit disparity-estimation accuracy because the architecture is trained end-to-end for policy performance rather than depth prediction; the policy-level ablations and real-robot results in geometrically demanding tasks serve as the primary validation. revision: partial
Circularity Check
No circularity: empirical architecture validated on benchmarks
full rationale
The paper introduces StereoPolicy as an empirical architecture: pretrained 2D encoders process stereo pairs independently, a Stereo Transformer fuses them, and the resulting policy is trained and tested on RoboMimic, RoboCasa, OmniGibson plus real-robot tasks. No equations, closed-form derivations, or predictions are presented that reduce the claimed gains to inputs by construction. The implicit-capture claim is a hypothesis tested via ablation and baseline comparisons rather than a tautological redefinition. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
URLhttps://arxiv.org/abs/1504.00702
- [3]
-
[4]
Cliport: What and where pathways for robotic manipulation
M. Shridhar, L. Manuelli, and D. Fox. Cliport: What and where pathways for robotic manipu- lation.arXiv preprint arXiv: Arxiv-2109.12098, 2021
-
[5]
S. Reed, K. Zolna, E. Parisotto, S. G. Colmenarejo, A. Novikov, G. Barth-Maron, M. Gimenez, Y . Sulsky, J. Kay, J. T. Springenberg, T. Eccles, J. Bruce, A. Razavi, A. Edwards, N. Heess, Y . Chen, R. Hadsell, O. Vinyals, M. Bordbar, and N. de Freitas. A generalist agent.arXiv preprint arXiv: Arxiv-2205.06175, 2022
work page internal anchor Pith review arXiv 2022
-
[6]
VIMA : General robot manipulation with multimodal prompts
Y . Jiang, A. Gupta, Z. Zhang, G. Wang, Y . Dou, Y . Chen, L. Fei-Fei, A. Anandkumar, Y . Zhu, and L. Fan. Vima: General robot manipulation with multimodal prompts.arXiv preprint arXiv: 2210.03094, 2022
-
[7]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. J. Joshi, R. C. Julian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Manju- nath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Per...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.06817 2022
-
[8]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, K. Choromanski, T. Ding, D. Driess, K. A. Dubey, C. Finn, P. R. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Haus- man, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. J. Joshi, R. C. Julian, D. Kalashnikov, Y . Kuang, I. Leal, S. Levine, H. Michalewski, I. Mordatch, K. Pertsch, K. Rao, K. Rey- ma...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.15818 2023
-
[9]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 2024. 10
work page 2024
-
[10]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. In K. E. Bekris, K. Hauser, S. L. Herbert, and J. Yu, editors,Robotics: Science and Systems XIX, Daegu, Republic of Korea, July 10-14, 2023, 2023. doi:10.15607/ RSS.2023.XIX.016. URLhttps://doi.org/10.15607/RSS.2023.XIX.016
-
[11]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id=ZMnD6QZAE6
work page 2024
-
[12]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv: 2410...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Y...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition, 2015. URL https://arxiv.org/abs/1512.03385
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[15]
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational Conference on Machine Learning, pages 8748–8763. PMLR, 2021
work page 2021
-
[16]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. De- hghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021. URLhttps: //arxiv.org/abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [17]
- [18]
- [19]
-
[20]
Y . Jiang, R. Zhang, J. Wong, C. Wang, Y . Ze, H. Yin, C. Gokmen, S. Song, J. Wu, and L. Fei- Fei. BEHA VIOR robot suite: Streamlining real-world whole-body manipulation for everyday household activities. In9th Annual Conference on Robot Learning, 2025. URLhttps:// openreview.net/forum?id=v2KevjWScT
work page 2025
-
[21]
Homer: Learn- ing in-the-wild mobile manipulation via hybrid imitation and whole- body control,
P. Sundaresan, R. Malhotra, P. Miao, J. Yang, J. Wu, H. Hu, R. Antonova, F. Engelmann, D. Sadigh, and J. Bohg. Homer: Learning in-the-wild mobile manipulation via hybrid imitation and whole-body control, 2025. URLhttps://arxiv.org/abs/2506.01185
-
[22]
Y . Qin, B. Huang, Z.-H. Yin, H. Su, and X. Wang. Dexpoint: Generalizable point cloud reinforcement learning for sim-to-real dexterous manipulation.Conference on Robot Learning,
-
[23]
doi:10.48550/arXiv.2211.09423. 11
- [24]
-
[25]
D. Marr and T. Poggio. Cooperative computation of stereo disparity.Science, 194(4262):283– 287, 1976. doi:10.1126/science.968482. URLhttps://www.science.org/doi/abs/10. 1126/science.968482
-
[26]
F. Zhang, X. Qi, R. Yang, V . Prisacariu, B. Wah, and P. Torr. Domain-invariant stereo matching networks. In A. Vedaldi, H. Bischof, T. Brox, and J.-M. Frahm, editors,Computer Vision – ECCV 2020, pages 420–439, Cham, 2020. Springer International Publishing. ISBN 978-3- 030-58536-5
work page 2020
- [27]
- [28]
-
[29]
L. Lipson, Z. Teed, and J. Deng. Raft-stereo: Multilevel recurrent field transforms for stereo matching. In2021 International Conference on 3D Vision (3DV), pages 218–227, 2021. doi: 10.1109/3DV53792.2021.00032
-
[30]
Z. Li, X. Liu, N. Drenkow, A. Ding, F. X. Creighton, R. H. Taylor, and M. Unberath. Revis- iting stereo depth estimation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6197–6206, October 2021
work page 2021
-
[31]
Z. Shen, Y . Dai, and Z. Rao. Cfnet: Cascade and fused cost volume for robust stereo match- ing.2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13901–13910, 2021
work page 2021
-
[32]
J. Li, P. Wang, P. Xiong, T. Cai, Z. Yan, L. Yang, J. Liu, H. Fan, and S. Liu. Practical stereo matching via cascaded recurrent network with adaptive correlation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16263– 16272, June 2022
work page 2022
-
[33]
P. Weinzaepfel, T. Lucas, V . Leroy, Y . Cabon, V . Arora, R. Br´egier, G. Csurka, L. Antsfeld, B. Chidlovskii, and J. Revaud. Croco v2: Improved cross-view completion pre-training for stereo matching and optical flow. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 17969–17980, October 2023
work page 2023
-
[34]
G. Xu, X. Wang, X. Ding, and X. Yang. Iterative geometry encoding volume for stereo match- ing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21919–21928, June 2023
work page 2023
- [35]
-
[36]
K. Shankar, M. Tjersland, J. Ma, K. Stone, and M. Bajracharya. A learned stereo depth system for robotic manipulation in homes, 2021. URLhttps://arxiv.org/abs/2109.11644
-
[37]
R. Yang, G. Yang, and X. Wang. Neural volumetric memory for visual locomotion con- trol.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1430–1440, 2023. 12
work page 2023
- [38]
-
[40]
URLhttps://arxiv.org/abs/2403.03954v7
work page internal anchor Pith review arXiv
- [41]
-
[42]
Are we ready for autonomous driving? the KITTI vision benchmark suite,
A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 3354–3361, 2012. doi:10.1109/CVPR.2012.6248074
-
[43]
M. Menze and A. Geiger. Object scene flow for autonomous vehicles. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015
work page 2015
-
[44]
D. Scharstein, H. Hirschm ¨uller, Y . Kitajima, G. Krathwohl, N. Neˇsi´c, X. Wang, and P. West- ling. High-resolution stereo datasets with subpixel-accurate ground truth. In X. Jiang, J. Hornegger, and R. Koch, editors,Pattern Recognition, pages 31–42, Cham, 2014. Springer International Publishing. ISBN 978-3-319-11752-2
work page 2014
-
[45]
C. Qi, H. Su, K. Mo, and L. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation.Computer Vision and Pattern Recognition, 2016. doi:10.1109/CVPR.2017. 16
-
[46]
C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
work page 2017
- [47]
-
[48]
H. Zhao, L. Jiang, J. Jia, P. H. S. Torr, and V . Koltun. Point transformer.2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 16239–16248, 2020
work page 2021
-
[49]
Perceiver: General perception with iterative attention
A. Jaegle, F. Gimeno, A. Brock, A. Zisserman, O. Vinyals, and J. Carreira. Perceiver: General perception with iterative attention.arXiv preprint arXiv: Arxiv-2103.03206, 2021
-
[50]
X. Wu, Y . Lao, L. Jiang, X. Liu, and H. Zhao. Point transformer v2: Grouped vector attention and partition-based pooling. In S. Koyejo, S. Mohamed, A. Agar- wal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Informa- tion Processing Systems, volume 35, pages 33330–33342. Curran Associates, Inc.,
-
[51]
URLhttps://proceedings.neurips.cc/paper_files/paper/2022/file/ d78ece6613953f46501b958b7bb4582f-Paper-Conference.pdf
work page 2022
-
[52]
X. Wu, L. Jiang, P.-S. Wang, Z. Liu, X. Liu, Y . Qiao, W. Ouyang, T. He, and H. Zhao. Point transformer v3: Simpler, faster, stronger.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4840–4851, 2023
work page 2024
-
[53]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Cou- prie, J. Mairal, H. J ´egou, P. Labatut, and P. Bojanowski. Dinov3, 2025. URLhttps: //arxiv.org/...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Learning Transferable Visual Models From Natural Language Supervision
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision, 2021. URLhttps://arxiv.org/abs/2103.00020. 13
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [55]
- [56]
- [57]
-
[58]
X. Wu, L. Jiang, P.-S. Wang, Z. Liu, X. Liu, Y . Qiao, W. Ouyang, T. He, and H. Zhao. Point transformer v3: Simpler, faster, stronger, 2024. URLhttps://arxiv.org/abs/2312. 10035
work page 2024
-
[59]
S. Xie, J. Gu, D. Guo, C. R. Qi, L. J. Guibas, and O. Litany. Pointcontrast: Unsupervised pre-training for 3d point cloud understanding, 2020. URLhttps://arxiv.org/abs/2007. 10985
work page 2020
- [60]
-
[61]
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng. Nerf: Representing scenes as neural radiance fields for view synthesis, 2020. URLhttps://arxiv. org/abs/2003.08934
- [62]
- [63]
-
[64]
A., Holynski, A., and Kanazawa, A
A. Haque, M. Tancik, A. A. Efros, A. Holynski, and A. Kanazawa. Instruct-nerf2nerf: Editing 3d scenes with instructions, 2023. URLhttps://arxiv.org/abs/2303.12789
-
[65]
K. Liu, F. Zhan, J. Zhang, M. Xu, Y . Yu, A. E. Saddik, C. Theobalt, E. Xing, and S. Lu. Weakly supervised 3d open-vocabulary segmentation, 2024. URLhttps://arxiv.org/abs/2305. 14093
work page 2024
- [66]
-
[67]
arXiv preprint arXiv:2412.04472 , year=
L. Bartolomei, F. Tosi, M. Poggi, and S. Mattoccia. Stereo anywhere: Robust zero-shot deep stereo matching even where either stereo or mono fail, 2025. URLhttps://arxiv.org/ abs/2412.04472
- [68]
- [69]
-
[70]
J.-R. Chang and Y .-S. Chen. Pyramid stereo matching network, 2018. URLhttps://arxiv. org/abs/1803.08669
- [71]
- [72]
- [73]
- [74]
-
[75]
V . Pradeep, C. Rhemann, S. Izadi, C. Zach, M. Bleyer, and S. Bathiche. Monofusion: Real- time 3d reconstruction of small scenes with a single web camera. In2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), pages 83–88. IEEE, 2013
work page 2013
- [76]
- [77]
- [78]
-
[79]
H. Li, Z. Li, N. U. Akmandor, H. Jiang, Y . Wang, and T. Padir. Stereovoxelnet: Real-time ob- stacle detection based on occupancy voxels from a stereo camera using deep neural networks,
- [80]
-
[81]
Dextrah- rgb: Visuomotor policies to grasp anything with dexterous hands,
R. Singh, A. Allshire, A. Handa, N. Ratliff, and K. Van Wyk. Dextrah-rgb: Visuomotor policies to grasp anything with dexterous hands.arXiv preprint arXiv:2412.01791, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.