Recognition: 2 theorem links
· Lean TheoremTRACE: Distilling Where It Matters via Token-Routed Self On-Policy Alignment
Pith reviewed 2026-05-12 02:52 UTC · model grok-4.3
The pith
Routing self-distillation to annotator-marked critical spans improves math reasoning while preserving out-of-distribution accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
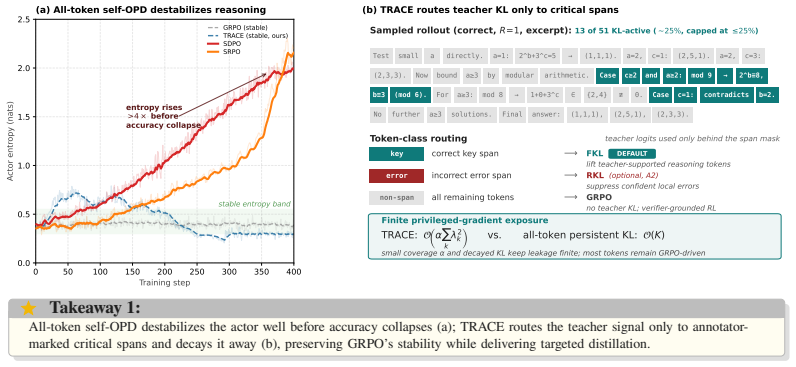
TRACE shows that token-routed self on-policy alignment limited to critical spans outperforms GRPO by an average of 2.76 percentage points on four held-out math benchmarks plus GPQA-Diamond. It achieves this while preserving the base Qwen3-8B out-of-distribution score on GPQA-Diamond, where both GRPO and all-token self-OPD degrade. The method applies forward KL to key correct spans, reverse KL to localized errors when beneficial, and GRPO elsewhere, with annealing to bound privileged effects. Gains remain when critical spans are obtained via online self-annotation rather than strong external APIs.
What carries the argument
Token-routed loss assignment that directs forward or reverse KL divergence only to annotator-marked critical spans while applying GRPO to all other tokens, combined with annealing of the distillation channel.
If this is right
- Delivers a 2.76 percentage point average improvement over GRPO on held-out math benchmarks and GPQA-Diamond.
- Maintains base-model out-of-distribution accuracy on GPQA-Diamond where full-response methods degrade.
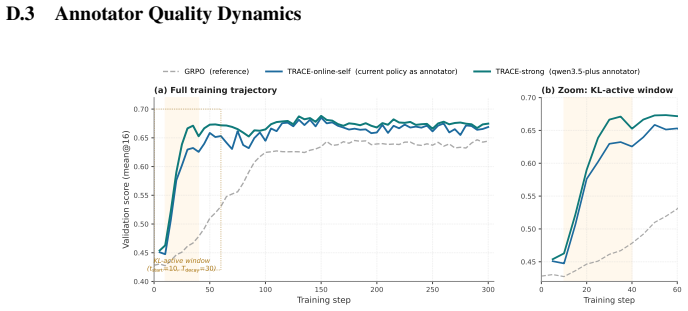
- Retains roughly 69 percent of the strong-API gain when critical spans are supplied by online self-annotation.
- Optimal routing choice varies by scale, with forward KL on correct spans preferred for 8B models and reverse KL on error spans for 1.7B models.
Where Pith is reading between the lines
- The finite-exposure principle may generalize to other privileged-information alignment settings where uniform distillation risks collapse.
- Self-annotation viability suggests the approach could scale without constant external labeling in resource-limited environments.
Load-bearing premise
The reported gains arise from the token-routing and span-masking mechanism rather than from the quality or selection process of the annotator-marked critical spans.
What would settle it
An ablation that applies the KL distillation uniformly across all tokens while retaining the same annotation pipeline, which should recover the entropy rise and OOD degradation of the all-token baseline if routing and masking are the operative factors.
Figures





read the original abstract
On-policy self-distillation (self-OPD) densifies reinforcement learning with verifiable rewards (RLVR) by letting a policy teach itself under privileged context. We find that when this guidance spans the full response, all-token KL spends gradients on mostly redundant positions and amplifies privileged-information leakage, causing entropy rise, shortened reasoning, and out-of-distribution degradation in long-horizon math training. We propose Token-Routed Alignment for Critical rEasoning (TRACE), which distills only on annotator-marked critical spans: forward KL on key spans of correct rollouts, optional reverse KL on localized error spans, and GRPO on all remaining tokens, with the KL channel annealed away after a short warm-up. Our analysis explains TRACE through two effects: forward KL provides non-vanishing lift to teacher-supported tokens that the student under-allocates, while span masking and decay keep cumulative privileged-gradient exposure finite. On four held-out math benchmarks plus GPQA-Diamond, TRACE improves over GRPO by 2.76 percentage points on average and preserves the Qwen3-8B base OOD score on GPQA-Diamond, where GRPO and all-token self-OPD baselines degrade. Gains persist under online self-annotation (+1.90 percentage points, about 69% of the strong-API gain), reducing the concern that TRACE merely imports external annotator capability. Across scales, the best routed action is base-dependent: on Qwen3-8B it is forward KL on key spans, while on Qwen3-1.7B it shifts to reverse KL on error spans.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TRACE (Token-Routed Alignment for Critical rEasoning), a token-routed variant of on-policy self-distillation (self-OPD) for RLVR on math reasoning. It restricts forward KL to annotator-marked key spans of correct rollouts and optional reverse KL to localized error spans, applies GRPO to all other tokens, and anneals the KL channel after a short warm-up. The central claim is that this avoids redundant gradient allocation and privileged-information leakage that cause entropy rise, shortened reasoning, and OOD degradation in all-token self-OPD. Empirically, TRACE yields a 2.76 pp average gain over GRPO across four held-out math benchmarks plus GPQA-Diamond while preserving the Qwen3-8B base OOD score (where GRPO and all-token baselines degrade); gains persist at +1.90 pp under online self-annotation.
Significance. If the reported gains are attributable to the routing and span-masking mechanics rather than annotator span quality, the work supplies a concrete mechanism for limiting privileged-gradient exposure while retaining non-vanishing lift on under-allocated tokens. The two-effect analysis and the online self-annotation result would be useful for scaling self-distillation without external APIs. The base-dependent choice of forward vs. reverse KL also highlights that optimal routing is model-scale dependent.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments section: The headline 2.76 pp average improvement and OOD preservation on GPQA-Diamond are reported without variance, standard errors, statistical significance tests, or the exact span-marking protocol (criteria, inter-annotator agreement, or length statistics). This leaves the central empirical claim under-supported for verification.
- [Experiments] Experiments section: No ablation replaces the annotator-marked critical spans with random or length-matched tokens while preserving the KL schedule, GRPO on remaining tokens, and annealing. Without this control, it is impossible to isolate whether the token-routed mechanism (rather than the quality or selection process of the marked spans) produces the claimed non-vanishing lift and finite privileged-gradient exposure.
- [Analysis] Analysis section: The two-effect explanation (forward KL supplying non-vanishing lift to teacher-supported tokens; span masking plus decay keeping cumulative privileged exposure finite) is invoked to explain the results, yet the manuscript supplies no equations, quantitative derivation, or direct linkage showing these effects are load-bearing for the 2.76 pp gain versus the baselines.
minor comments (2)
- [Abstract] The abstract lists KL annealing schedule and warm-up length as free parameters but provides neither their concrete values nor sensitivity results.
- Hyperparameter details for routing thresholds, span selection, and the exact GRPO implementation on non-critical tokens are missing, hindering reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that strengthen the empirical support and analysis without altering the core claims of the work.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The headline 2.76 pp average improvement and OOD preservation on GPQA-Diamond are reported without variance, standard errors, statistical significance tests, or the exact span-marking protocol (criteria, inter-annotator agreement, or length statistics). This leaves the central empirical claim under-supported for verification.
Authors: We agree that variance estimates, standard errors, and significance testing would improve verifiability of the reported gains. In the revised manuscript we will add standard deviations computed over multiple random seeds for all main results, include paired statistical significance tests against the GRPO and all-token baselines, and expand the Experiments section (plus appendix) with the precise span-marking criteria, inter-annotator agreement metrics, and length-distribution statistics for the marked spans. revision: yes
-
Referee: [Experiments] Experiments section: No ablation replaces the annotator-marked critical spans with random or length-matched tokens while preserving the KL schedule, GRPO on remaining tokens, and annealing. Without this control, it is impossible to isolate whether the token-routed mechanism (rather than the quality or selection process of the marked spans) produces the claimed non-vanishing lift and finite privileged-gradient exposure.
Authors: We concur that a random or length-matched span ablation is the cleanest way to isolate the routing mechanism from span quality. We will add this control experiment in the revised version, keeping the KL schedule, GRPO application on non-routed tokens, and annealing schedule identical, so that any performance difference can be attributed to the choice of routed positions rather than the annotators' selection process. revision: yes
-
Referee: [Analysis] Analysis section: The two-effect explanation (forward KL supplying non-vanishing lift to teacher-supported tokens; span masking plus decay keeping cumulative privileged exposure finite) is invoked to explain the results, yet the manuscript supplies no equations, quantitative derivation, or direct linkage showing these effects are load-bearing for the 2.76 pp gain versus the baselines.
Authors: We accept that the current analysis is largely qualitative. In the revision we will augment the Analysis section with explicit equations formalizing the non-vanishing lift under forward KL on under-allocated tokens and the finite cumulative privileged exposure under span masking plus annealing. Where possible we will provide a quantitative sketch linking these terms to the observed gap versus all-token self-OPD and GRPO. revision: yes
Circularity Check
No circularity: empirical gains on held-out benchmarks with mechanistic description
full rationale
The paper reports experimental improvements (2.76 pp average lift over GRPO, OOD preservation on GPQA-Diamond) from implementing token-routed forward/reverse KL on annotator-marked spans plus GRPO elsewhere, with annealing. No equations, derivations, or self-citations are shown that reduce the claimed performance deltas to quantities defined by the method's own fitted parameters, span selections, or prior author results. The two-effect analysis is a post-hoc interpretation of observed training dynamics rather than a closed loop that forces the result by construction. Results are framed as direct comparisons on external benchmarks, satisfying the self-contained empirical standard.
Axiom & Free-Parameter Ledger
free parameters (2)
- KL annealing schedule and warm-up length
- Critical span marking criteria
axioms (1)
- domain assumption Annotators can reliably identify critical reasoning spans that correspond to positions where the student under-allocates probability mass
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearTRACE routes teacher signal only to annotator-marked critical spans... FKL on key spans of correct rollouts, optional reverse KL on localized error spans, GRPO on all remaining tokens, with the KL channel annealed away after a short warm-up.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearOur analysis explains TRACE through two effects: forward KL provides non-vanishing lift... while span masking and decay keep cumulative privileged-gradient exposure finite.
Reference graph
Works this paper leans on
-
[1]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training. arXiv preprint arXiv:2501.17161,
work page internal anchor Pith review arXiv
-
[2]
Minillm: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models. InInternational Conference on Learning Representations, volume 2024, pages 32694–32717,
work page 2024
-
[3]
OpenThoughts: Data Recipes for Reasoning Models
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, et al. Openthoughts: Data recipes for reasoning models.arXiv preprint arXiv:2506.04178,
work page internal anchor Pith review arXiv
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation. arXiv preprint arXiv:2601.20802,
work page internal anchor Pith review arXiv
-
[6]
arXiv preprint arXiv:2510.13786 , year=
Devvrit Khatri, Lovish Madaan, Rishabh Tiwari, Rachit Bansal, Sai Surya Duvvuri, Manzil Zaheer, Inderjit S Dhillon, David Brandfonbrener, and Rishabh Agarwal. The art of scaling reinforcement learning compute for llms.arXiv preprint arXiv:2510.13786,
-
[7]
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dohyung Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Yang. Why does self-distillation (sometimes) degrade the reasoning capability of llms?arXiv preprint arXiv:2603.24472,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Yoon Kim and Alexander M. Rush. Sequence-level knowledge distillation. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1317–1327,
work page 2016
-
[9]
10 Gengsheng Li, Tianyu Yang, Junfeng Fang, Mingyang Song, Mao Zheng, Haiyun Guo, Dan Zhang, Jinqiao Wang, and Tat-Seng Chua. Unifying group-relative and self-distillation policy optimization via sample routing. arXiv preprint arXiv:2604.02288, 2026a. Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wen...
-
[10]
URLhttps://thinkingmachines.ai/blog/on-policy-distillation. Changze Lv, Jie Zhou, Wentao Zhao, Jingwen Xu, Zisu Huang, Muzhao Tian, Shihan Dou, Tao Gui, Le Tian, Xiao Zhou, et al. Learning query-specific rubrics from human preferences for deepresearch report generation. arXiv preprint arXiv:2602.03619,
- [11]
-
[12]
com/wiki/index.php/AMC_12_Problems_and_Solutions
https://artofproblemsolving. com/wiki/index.php/AMC_12_Problems_and_Solutions. Mathematical Association of America. AIME 2024 problems,
work page 2024
-
[13]
Mathematical Association of America
https://artofproblemsolving.com/ wiki/index.php/AIME_Problems_and_Solutions. Mathematical Association of America. AIME 2025 problems,
work page 2025
-
[14]
Privileged information distillation for language models.arXiv preprint arXiv:2602.04942, 2026
Emiliano Penaloza, Dheeraj Vattikonda, Nicolas Gontier, Alexandre Lacoste, Laurent Charlin, and Massimo Caccia. Privileged information distillation for language models.arXiv preprint arXiv:2602.04942,
-
[15]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning. arXiv preprint arXiv:2601.19897,
work page internal anchor Pith review arXiv
-
[18]
Ktae: A model-free algorithm to key-tokens advantage estimation in mathematical reasoning, 2025
Wei Sun, Wen Yang, Pu Jian, Qianlong Du, Fuwei Cui, Shuo Ren, and Jiajun Zhang. Ktae: A model-free algorithm to key-tokens advantage estimation in mathematical reasoning.arXiv preprint arXiv:2505.16826,
-
[19]
TIP: Token Importance in On-Policy Distillation
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, Zhipeng Wang, and Alborz Geramifard. Tip: Token importance in on-policy distillation.arXiv preprint arXiv:2604.14084,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled rlvr.arXiv preprint arXiv:2604.03128,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734,
work page internal anchor Pith review arXiv
-
[23]
A Notation and Preliminaries Notation.Let πθ be a language model parameterized by θ. Given a problem x, y= (y 1, . . . , yT ) is generated autoregressively; R(x, y)∈ {0,1} is a binary verifier; c denotesprivileged information(a verified reasoning trace, environment feedback, or coarse type label). The student is πS(· |x) := πθ(· |x) and the privileged-con...
work page 2026
-
[24]
B.5 Distribution-space mass dynamics on a token set Lemma 10(Natural-gradient mass dynamics).Under simplex updates with the natural gradient (Fisher-information metric) of KLF (πT , πθ), the mass πθ(U) moves monotonically toward πT (U). In particular, ifπ θ(U)> π T (U)initially, the mass strictly decreases towardπ T (U). Proof. The natural gradient of a d...
work page 1998
-
[25]
The condition is local — one correct token with low teacher probability suffices — and is empirically common in math reasoning, where the privileged context is typically a single canonical solution and the student may sample valid alternatives. Independent of Yang et al. [2026]’s mutual-information ill-posedness; the two viewpoints are complementary. Proo...
work page 2026
-
[26]
Under the convention0/0 = 0 used in practical GRPO implementations, the per-rollout advantage A(i) = (R(i) −µ G)/σG = 0/0 = 0 for every i. Token-level advantageA(i) t =A (i) = 0 for every t, hence the GRPO loss −P t A(i) t logπ θ(y(i) t ) has zero gradient. Part 2.By Prop. 5, the TRACE gradient on y(i) decomposes additively into a span piece onSy(i) and a...
work page 2048
-
[27]
[2026a] propose SRPO with sample-level routing
formalize an information- asymmetric ill-posedness with an irreducible mutual-information gap and propose RLSD which uses the teacher’s log-probability ratio as a magnitude multiplier within GRPO; Li et al. [2026a] propose SRPO with sample-level routing. TRACE departs from the GKD line by treating divergence direction as a per-token-class action (§3), and...
work page 2025
-
[28]
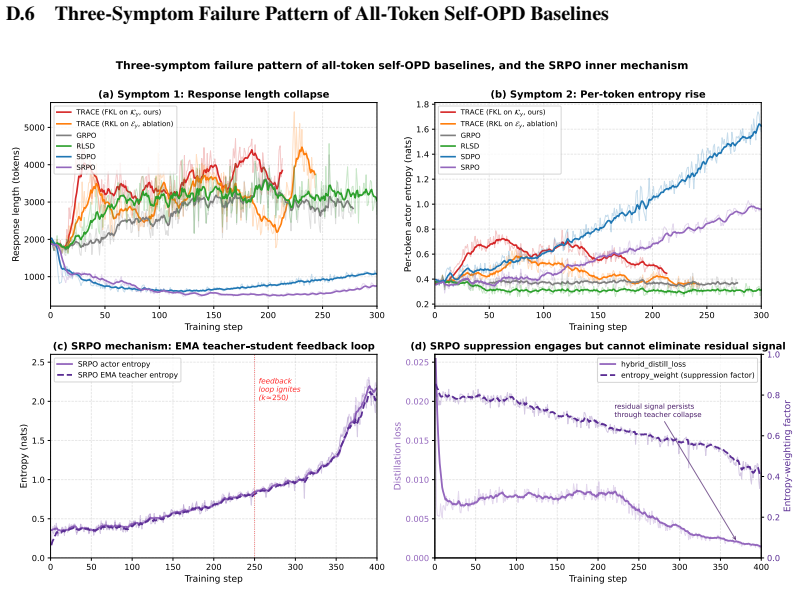
The gap to the original SDPO/SRPO reports is plausibly due to the change in domain (math vs scientific / code), feedback channel, base model (Qwen3-8B), and long-horizon Think-mode generation; we do not isolate a single cause. 25 D.6 Three-Symptom Failure Pattern of All-Token Self-OPD Baselines 0 50 100 150 200 250 300 Training step 1000 2000 3000 4000 50...
work page 2000
-
[29]
SDPO collapses from 2027→1042 tokens (min
(c) SRPO mechanism: EMA teacher student feedback loop SRPO actor entropy SRPO EMA teacher entropy 0 50 100 150 200 250 300 350 400 Training step 0.000 0.005 0.010 0.015 0.020 0.025Distillation loss residual signal persists through teacher collapse (d) SRPO suppression engages but cannot eliminate residual signal hybrid_distill_loss entropy_weight (suppres...
work page 2027
-
[30]
This is the EMA feedback loop predicted by Kim et al. [2026]: student errors are absorbed into the next teacher snapshot, which then amplifies them.(d)SRPO’s entropy-aware suppression weight does decrease from 0.85→0.39 as teacher entropy rises, but never approaches zero; the residual hybrid_distill_loss continues to be applied throughout the collapse pha...
work page 2026
-
[31]
26 Table 9:Asymmetric thinking ablation.Training: teacher Think, student NoThink; eval: think- mode
recovers in-distribution math without losing the OOD gain. 26 Table 9:Asymmetric thinking ablation.Training: teacher Think, student NoThink; eval: think- mode. GRPO row matches Tab. 2 (the asymmetric/symmetric distinction does not apply to GRPO since it has no teacher). Method (asymmetric training) MATH-500 AIME 24 AIME 25 AMC 23 GPQA-D A VG Qwen3-8B base...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.