Recognition: no theorem link
PowerStep: Memory-Efficient Adaptive Optimization via ell_p-Norm Steepest Descent
Pith reviewed 2026-05-12 03:28 UTC · model grok-4.3
The pith
PowerStep achieves coordinate-wise adaptivity for large Transformer training by applying a nonlinear transform to the momentum buffer, matching Adam while halving optimizer memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PowerStep is obtained by replacing the usual second-moment normalization with a nonlinear function applied to the momentum buffer, an operation that arises naturally as the steepest-descent step under an ℓ_p-norm geometry. The method therefore supplies per-coordinate adaptivity while storing only first-moment information. The authors prove that the resulting algorithm attains the optimal O(1/√T) convergence rate for non-convex stochastic optimization and that, on Transformer models from 124 M to 235 B parameters, it matches Adam’s wall-clock convergence speed while using half the optimizer memory; when combined with int8 quantization it remains stable and reduces memory by a factor of eight.
What carries the argument
The nonlinear transform applied to the momentum buffer under ℓ_p-norm steepest descent, which induces effective per-coordinate learning rates without explicit second-moment storage.
Load-bearing premise
The nonlinear transform on the momentum buffer produces per-coordinate effective learning rates sufficiently close to those of second-moment methods for both the convergence proof and empirical parity to hold across model scales and data regimes.
What would settle it
A controlled experiment in which PowerStep either diverges or converges materially slower than Adam on a Transformer exceeding 100 B parameters while using the same hyperparameters and data schedule.
Figures

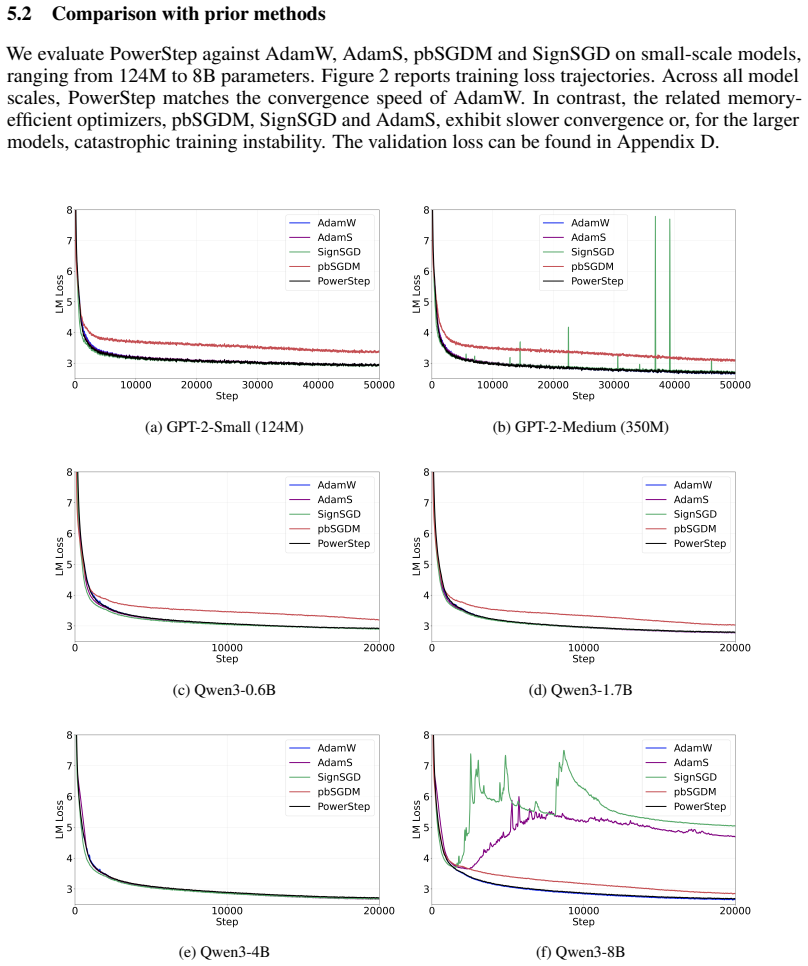


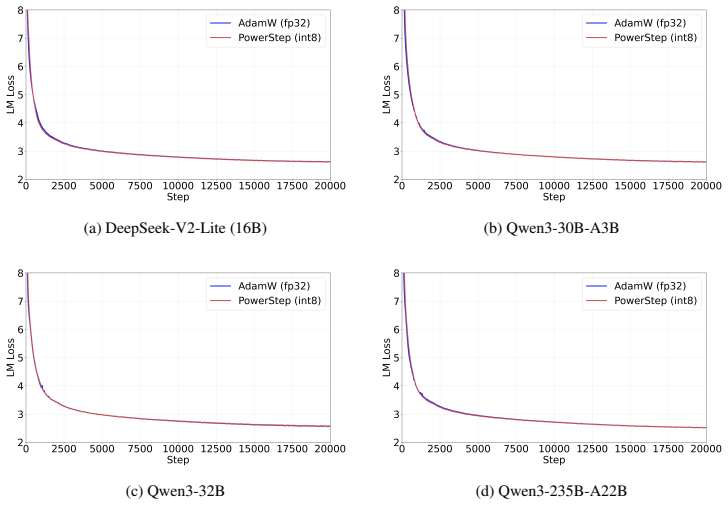
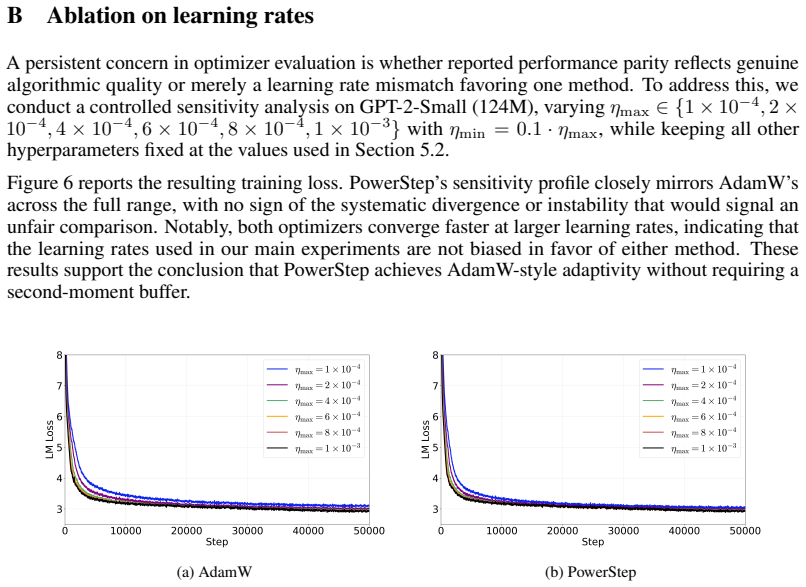

read the original abstract
Adaptive optimizers, most notably Adam, have become the default standard for training large-scale neural networks such as Transformers. These methods maintain running estimates of gradient first and second moments, incurring substantial memory overhead. We introduce PowerStep, a memory-efficient optimizer that achieves coordinate-wise adaptivity without storing second-moment statistics. Motivated by steepest descent under an $\ell_p$-norm geometry, we show that applying a nonlinear transform directly to a momentum buffer yields coordinate-wise adaptivity. We prove that PowerStep converges at the optimal $O(1/\sqrt{T})$ rate for non-convex stochastic optimization. Extensive experiments on Transformer models ranging from 124M to 235B parameters demonstrate that PowerStep matches Adam's convergence speed while halving optimizer memory. Furthermore, when combined with aggressive \texttt{int8} quantization, PowerStep remains numerically stable and reduces optimizer memory by $\sim\!8\times$ compared to full-precision Adam. PowerStep thus provides a principled, scalable and resource-efficient alternative for large-scale training. Code is available at https://github.com/yaolubrain/PowerStep.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PowerStep, an adaptive optimizer motivated by ℓ_p-norm steepest descent. It applies a nonlinear transform directly to a first-moment (momentum) buffer to obtain coordinate-wise adaptivity without maintaining second-moment statistics. The central claims are a proof of O(1/√T) convergence for non-convex stochastic optimization and empirical results showing that PowerStep matches Adam's convergence speed on Transformer models from 124M to 235B parameters while halving optimizer memory (and achieving ~8× reduction with int8 quantization).
Significance. If the convergence analysis holds and the large-scale experiments are reproducible, the result would be significant for resource-constrained training of very large models. The geometric motivation from ℓ_p steepest descent provides a principled alternative to heuristic second-moment methods, and the public code release is a positive contribution. The memory reduction is practically relevant for scaling Transformers.
major comments (2)
- [convergence theorem (§4)] The convergence theorem (abstract and §4) claims the optimal O(1/√T) rate for non-convex stochastic optimization. However, the analysis requires that the nonlinear transform applied to the momentum buffer produces per-coordinate effective learning rates whose descent and variance bounds match those used for Adam. The manuscript does not appear to derive explicit bounds on the Lipschitz constant of this transform or its interaction with momentum decay and the dual-norm geometry; without these controls the reduction to the standard rate is not obviously guaranteed.
- [experiments (large-scale Transformer results)] The empirical claim of matching Adam on 124M–235B Transformers while halving memory rests on the assumption that the ℓ_p-derived adaptivity is sufficiently close to 1/√(second-moment) scaling. The experiments section should include an ablation or analysis showing that the effective per-coordinate step sizes remain bounded away from zero and infinity across training, as violation of this would undermine both the parity result and the applicability of the proof.
minor comments (1)
- [abstract] The abstract states that code is available at https://github.com/yaolubrain/PowerStep; the repository link should be verified to contain the exact implementation used for the 235B-scale runs.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of the work's significance and for the constructive major comments. We address each point below and will revise the manuscript accordingly to strengthen the presentation of the convergence analysis and empirical validation.
read point-by-point responses
-
Referee: [convergence theorem (§4)] The convergence theorem (abstract and §4) claims the optimal O(1/√T) rate for non-convex stochastic optimization. However, the analysis requires that the nonlinear transform applied to the momentum buffer produces per-coordinate effective learning rates whose descent and variance bounds match those used for Adam. The manuscript does not appear to derive explicit bounds on the Lipschitz constant of this transform or its interaction with momentum decay and the dual-norm geometry; without these controls the reduction to the standard rate is not obviously guaranteed.
Authors: We appreciate the referee's careful reading of the proof. The analysis in §4 proceeds by showing that the ℓ_p-norm steepest-descent transform induces per-coordinate effective step sizes whose magnitude and variance can be bounded in a manner directly analogous to the standard Adam analysis (via the dual-norm geometry and the momentum update). To make these controls fully explicit, we will add a supporting lemma in the revised §4 that derives the Lipschitz constant of the nonlinear transform (under the chosen p and momentum decay β) and verifies that the resulting descent and variance terms satisfy the conditions needed for the O(1/√T) rate. This addition will clarify the reduction without altering the existing proof structure. revision: yes
-
Referee: [experiments (large-scale Transformer results)] The empirical claim of matching Adam on 124M–235B Transformers while halving memory rests on the assumption that the ℓ_p-derived adaptivity is sufficiently close to 1/√(second-moment) scaling. The experiments section should include an ablation or analysis showing that the effective per-coordinate step sizes remain bounded away from zero and infinity across training, as violation of this would undermine both the parity result and the applicability of the proof.
Authors: We agree that an explicit check on the range of effective per-coordinate step sizes strengthens both the empirical claims and the link to the theory. In the revised manuscript we will add a targeted analysis (new figure or table in §5 and/or the appendix) that reports the min/max/median of the effective learning rates induced by the nonlinear transform on the momentum buffer, computed over the course of training for the 124M–235B Transformer runs. This will confirm that the values remain bounded away from zero and infinity, consistent with the observed parity to Adam and with the assumptions used in the convergence proof. revision: yes
Circularity Check
No circularity: derivation from external ℓ_p geometry is self-contained
full rationale
The paper motivates PowerStep via steepest descent in an ℓ_p-norm geometry applied to a first-moment (momentum) buffer, then applies a nonlinear transform to obtain coordinate-wise adaptivity. This is an external geometric construction, not a parameter fit to target performance or a self-citation chain. The claimed O(1/√T) non-convex stochastic convergence follows from standard descent and variance bounds once the transform is fixed by the geometry; no equation reduces the effective per-coordinate scaling back to a fitted quantity or to the final performance metric by construction. Experiments on Transformer scales are validation only and do not enter the derivation. No load-bearing self-citations, uniqueness theorems imported from the same authors, or ansatzes smuggled via prior work are present in the abstract or described chain. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A nonlinear transform on the momentum buffer yields coordinate-wise adaptivity equivalent to second-moment methods
Reference graph
Works this paper leans on
-
[1]
Why Adam Can Beat SGD: Second-Moment Normalization Yields Sharper Tails
Why Adam Can Beat SGD: Second-Moment Normalization Yields Sharper Tails , author=. arXiv preprint arXiv:2603.03099 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Understanding Quantization of Optimizer States in
Topollai, Kristi and Choromanska, Anna , journal=. Understanding Quantization of Optimizer States in
-
[3]
arXiv preprint arXiv:1905.09899 , year =
Blockwise Adaptivity: Faster Training and Better Generalization in Deep Learning , author =. arXiv preprint arXiv:1905.09899 , year =
-
[4]
International Conference on Learning Representations , year =
Deconstructing What Makes a Good Optimizer for Language Models , author =. International Conference on Learning Representations , year =
-
[5]
Advances in Neural Information Processing Systems , year =
Symbolic Discovery of Optimization Algorithms , author =. Advances in Neural Information Processing Systems , year =
-
[6]
Advances in Neural Information Processing Systems , year =
Adam Can Converge Without Any Modification On Update Rules , author =. Advances in Neural Information Processing Systems , year =
-
[7]
Closing the Gap Between the Upper Bound and Lower Bound of
Bohan Wang and Jingwen Fu and Huishuai Zhang and Nanning Zheng and Wei Chen , journal =. Closing the Gap Between the Upper Bound and Lower Bound of
-
[8]
Haochuan Li and Ali Jadbabaie and Alexander Rakhlin , journal =. Convergence of
-
[9]
Alexandre D. A Simple Convergence Proof of. Transactions on Machine Learning Research , year =
-
[10]
International Conference on Learning Representations , year =
Adaptive Gradient Methods with Dynamic Bound of Learning Rate , author =. International Conference on Learning Representations , year =
-
[11]
Reddi and Satyen Kale and Sanjiv Kumar , journal =
Sashank J. Reddi and Satyen Kale and Sanjiv Kumar , journal =. On the Convergence of
-
[12]
On the convergence of a class of
Chen, Xiangyi and Liu, Sijia and Sun, Ruoyu and Hong, Mingyi , journal=. On the convergence of a class of
-
[13]
Advances in Neural Information Processing Systems , year=
Memory-Efficient Optimizers with 4-Bit States , author=. Advances in Neural Information Processing Systems , year=
- [14]
- [15]
-
[16]
Advances in Neural Information Processing Systems , year=
Why Transformers Need Adam: A Hessian Perspective , author=. Advances in Neural Information Processing Systems , year=
-
[17]
Toward Understanding Why Adam Converges Faster Than
Pan, Yan and Li, Yuanzhi , journal=. Toward Understanding Why Adam Converges Faster Than
-
[18]
Advances in Neural Information Processing Systems , year=
Why are Adaptive Methods Good for Attention Models? , author=. Advances in Neural Information Processing Systems , year=
-
[19]
International Conference on Learning Representations , year=
Noise Is Not the Main Factor Behind the Gap Between SGD and Adam on Transformers, but Sign Descent Might Be , author=. International Conference on Learning Representations , year=
-
[20]
International Conference on Learning Representations , year=
A Convergence Analysis of Adaptive Optimizers under Floating-point Quantization , author=. International Conference on Learning Representations , year=
-
[21]
ICML Workshop on Large Language Models and Cognition , year=
Q-Adam-mini: Memory-Efficient 8-bit Quantized Optimizer for Large Language Model Training , author=. ICML Workshop on Large Language Models and Cognition , year=
-
[22]
Advances in Neural Information Processing Systems , year=
Identifying and attacking the saddle point problem in high-dimensional non-convex optimization , author=. Advances in Neural Information Processing Systems , year=
-
[23]
International Conference on Artificial Intelligence and Statistics , year=
The loss surfaces of multilayer networks , author=. International Conference on Artificial Intelligence and Statistics , year=
-
[24]
Neural Networks: Tricks of the Trade , year=
Efficient Backprop , author=. Neural Networks: Tricks of the Trade , year=
-
[25]
IEEE Transactions on Neural Networks , year=
Learning long-term dependencies with gradient descent is difficult , author=. IEEE Transactions on Neural Networks , year=
-
[26]
arXiv preprint arXiv:2503.12345 , year=
Old Optimizer, New Norm: An Anthology , author=. arXiv preprint arXiv:2503.12345 , year=
-
[27]
Muon: An Optimizer for Hidden Layers in Neural Networks , author=. 2024 , journal =
work page 2024
-
[28]
General Convergence Results for Linear Discriminant Updates , author=. Machine Learning , year=
-
[29]
International Conference on Machine Learning , year=
Stacey: Promoting Stochastic Steepest Descent via Accelerated _p -Smooth Nonconvex Optimization , author=. International Conference on Machine Learning , year=
- [30]
-
[31]
Journal of Machine Learning Research , year =
John Duchi and Elad Hazan and Yoram Singer , title =. Journal of Machine Learning Research , year =
-
[32]
OpenWebText Corpus , author =
-
[33]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model , author=. arXiv preprint arXiv:2405.04434 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
OpenAI Technical Report , year=
Language Models are Unsupervised Multitask Learners , author=. OpenAI Technical Report , year=
-
[35]
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Journal of Machine Learning Research , year=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of Machine Learning Research , year=
-
[37]
Bernstein, Jeremy and Wang, Yu-Xiang and Azizzadenesheli, Kamyar and Anandkumar, Animashree , journal=. sign
-
[38]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[39]
Conference on Empirical Methods in Natural Language Processing , year=
Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[40]
The Robustness of the p-Norm Algorithms , author=. Machine Learning , year=
-
[41]
Problem Complexity and Method Efficiency in Optimization , author=. 1983 , publisher=
work page 1983
- [42]
-
[43]
Operations Research Letters , year=
Mirror descent and nonlinear projected subgradient methods for convex optimization , author=. Operations Research Letters , year=
-
[44]
Untersuchungen zu dynamischen neuronalen Netzen , author=. Diploma, Technische Universit
-
[45]
Gomez and Lukasz Kaiser and Illia Polosukhin , title =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , title =. Advances in Neural Information Processing Systems , year =
-
[46]
Reddi and Devendra Singh Sachan and Satyen Kale and Sanjiv Kumar , title=
Manzil Zaheer and Sashank J. Reddi and Devendra Singh Sachan and Satyen Kale and Sanjiv Kumar , title=. Advances in Neural Information Processing Systems , year=
-
[47]
Yossi Arjevani and Yair Carmon and John C. Duchi and Dylan J. Foster and Nathan Srebro and Blake Woodworth , title =. Mathematical Programming , year =
-
[48]
SIAM Journal on Optimization , year =
Saeed Ghadimi and Guanghui Lan , title =. SIAM Journal on Optimization , year =
-
[49]
Conference on Empirical Methods in Natural Language Processing , year=
Adams: Momentum itself can be a normalizer for llm pretraining and post-training , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[50]
International Conference on Learning Representations , year=
8-bit Optimizers via Block-wise Quantization , author=. International Conference on Learning Representations , year=
-
[51]
International Conference on Machine Learning , year=
Adafactor: Adaptive Learning Rates with Sublinear Memory Cost , author=. International Conference on Machine Learning , year=
-
[52]
International Conference on Machine Learning , year=
Adam-mini: Use Fewer Learning Rates To Gain More , author=. International Conference on Machine Learning , year=
-
[53]
Adam-mini: Use Fewer Learning Rates To Gain More , year =
Zhang, Yushun and Chen, Congliang and Li, Ziniu and Ding, Tian and Wu, Chenwei and Kingma, Diederik (Durk) and Ye, Yinyu and Luo, Zhi-Quan and Sun, Ruoyu , journal =. Adam-mini: Use Fewer Learning Rates To Gain More , year =
-
[54]
International Conference on Learning Representations , year=
Adam: A Method for Stochastic Optimization , author=. International Conference on Learning Representations , year=
-
[55]
IEEE Control Systems Letters , year=
On the powerball method: variants of descent methods for accelerated optimization , author=. IEEE Control Systems Letters , year=
-
[56]
International Joint Conferences on Artificial Intelligence , year=
pbSGD: powered Stochastic gradient descent methods for accelerated nonconvex optimization , author=. International Joint Conferences on Artificial Intelligence , year=
-
[57]
Ussr Computational Mathematics and Mathematical Physics , year=
Some methods of speeding up the convergence of iteration methods , author=. Ussr Computational Mathematics and Mathematical Physics , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.