Recognition: no theorem link
Consistency as a Testable Property: Statistical Methods to Evaluate AI Agent Reliability
Pith reviewed 2026-05-12 04:38 UTC · model grok-4.3
The pith
AI agents often break down on minor task variations despite knowing the answer, and trajectory-level consistency metrics catch these failures better than pass rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using U-statistics to measure output-level reliability and kernel-based metrics to assess trajectory-level stability under semantically preserving perturbations, the approach shows that agents can possess core capability for a task yet lack execution robustness, resulting in strategy breakdowns from minor variations. This separation is demonstrated on three agentic benchmarks, where trajectory consistency metrics prove more diagnostically sensitive than standard pass@1 rates.
What carries the argument
U-statistics for output-level reliability and kernel-based metrics for trajectory-level stability under semantically preserving perturbations, which together isolate execution robustness from core capability.
If this is right
- Trajectory-level metrics identify robustness problems that pass@1 rates overlook in agent evaluations.
- The framework enables pinpointing architectural issues that cause inconsistent agent behavior.
- Agents intended for high-stakes use can be tested for consistency beyond basic task success.
- Minor task variations can expose execution failures even when agents have the required knowledge.
Where Pith is reading between the lines
- These consistency tests could be applied to non-agent systems like language models responding to varied prompts to check general reliability.
- Training methods might incorporate these metrics as optimization targets to build more stable agents.
- Re-evaluating existing agent benchmarks with trajectory metrics could uncover hidden failure patterns not visible in standard scores.
Load-bearing premise
Semantically preserving perturbations can be reliably defined and applied so that the metrics accurately measure execution robustness without introducing unintended biases or altering task meaning.
What would settle it
Applying the metrics to the three benchmarks and finding no greater sensitivity than pass@1 rates, or no evidence of strategy breakdowns under the perturbations.
Figures


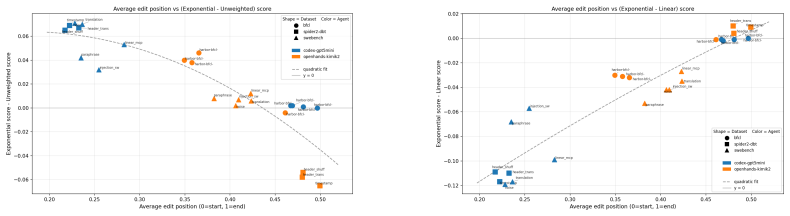
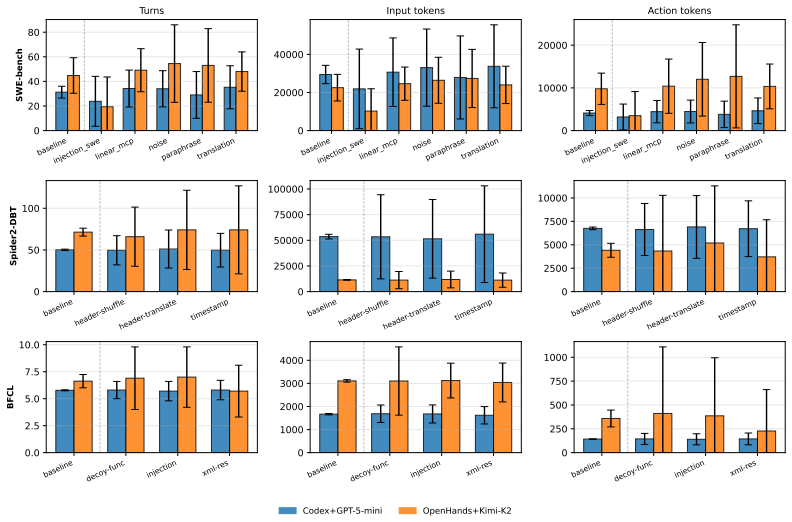
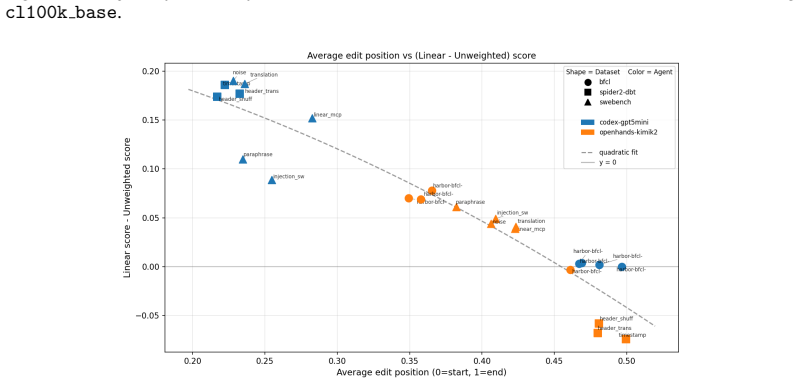
read the original abstract
This paper establishes a rigorous measurement science for AI agent reliability, providing a foundational framework for quantifying consistency under semantically preserving perturbations. By leveraging $U$-statistics for output-level reliability and kernel-based metrics for trajectory-level stability, we offer a principled approach to evaluating agents across diverse operating conditions. Our proposal highlights the important distinction between the core capability and execution robustness of an agent, showing that minor task-level variations can induce complete strategy breakdowns despite the agent possessing the requisite knowledge for the task. We validate our framework through extensive experiments on three agentic benchmarks, demonstrating that trajectory-level consistency metrics provide far greater diagnostic sensitivity than traditional pass@1 rates. By providing the mathematical tools to isolate where and why agents deviate, we enable the identification and rectification of architectural concerns that hinder the deployment of agents in high-stakes, real-world environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a measurement framework for AI agent reliability that treats consistency as a testable statistical property. It applies U-statistics to assess output-level reliability and kernel-based metrics to quantify trajectory-level stability under semantically preserving perturbations. The central claim is that these trajectory-level metrics distinguish core capability from execution robustness more effectively than pass@1 rates, with experiments on three agentic benchmarks demonstrating greater diagnostic sensitivity for detecting strategy breakdowns.
Significance. If the perturbation generation process can be shown to preserve task semantics without introducing unstated biases, the framework would supply a principled way to isolate execution fragility from underlying competence. This could improve reliability assessment beyond binary success metrics and support targeted debugging of agent architectures in high-stakes settings. The use of established statistical tools (U-statistics, kernels) is a positive feature when properly anchored.
major comments (2)
- [Perturbation generation and validation (likely §3–4)] The distinction between core capability and execution robustness, and the superiority claim for trajectory-level kernel metrics over pass@1, rests on the unverified assumption that perturbations preserve task semantics while exposing execution differences. The paper must supply an explicit validation procedure (e.g., human or automated checks that success criteria remain unchanged) and report any failure rates of this preservation; without it, the metrics risk conflating capability shifts with robustness differences.
- [Experiments and results (likely §5)] The abstract states that trajectory-level metrics provide 'far greater diagnostic sensitivity,' yet no quantitative comparison (effect sizes, statistical tests, or confidence intervals) is visible in the provided summary. The experiments section must include direct head-to-head results on the three benchmarks, with error bars and controls for perturbation strength, to substantiate this load-bearing claim.
minor comments (2)
- [Methods] Notation for the kernel metric and U-statistic should be defined with explicit formulas and any hyperparameters (bandwidth, kernel choice) stated clearly to allow reproduction.
- [Related work] The paper should cite prior work on semantic equivalence checking or perturbation robustness in NLP/RL to situate the contribution.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight important aspects of validation and statistical rigor that will strengthen the manuscript. We address each major comment below and will incorporate the suggested revisions in the next version of the paper.
read point-by-point responses
-
Referee: [Perturbation generation and validation (likely §3–4)] The distinction between core capability and execution robustness, and the superiority claim for trajectory-level kernel metrics over pass@1, rests on the unverified assumption that perturbations preserve task semantics while exposing execution differences. The paper must supply an explicit validation procedure (e.g., human or automated checks that success criteria remain unchanged) and report any failure rates of this preservation; without it, the metrics risk conflating capability shifts with robustness differences.
Authors: We agree that an explicit validation procedure is necessary to rigorously support the distinction between core capability and execution robustness. In the revised manuscript, we will add a dedicated subsection to §3 that describes the perturbation generation process and includes both automated validation (via embedding-based semantic similarity thresholds) and human evaluation on a stratified sample of perturbations across the three benchmarks. We will report the observed preservation failure rates (preliminary internal checks indicate rates below 8%). This addition will directly address the risk of conflating capability shifts with robustness differences while preserving the framework's focus on trajectory-level stability. revision: yes
-
Referee: [Experiments and results (likely §5)] The abstract states that trajectory-level metrics provide 'far greater diagnostic sensitivity,' yet no quantitative comparison (effect sizes, statistical tests, or confidence intervals) is visible in the provided summary. The experiments section must include direct head-to-head results on the three benchmarks, with error bars and controls for perturbation strength, to substantiate this load-bearing claim.
Authors: The experiments in §5 already present comparative results across the three benchmarks (AgentBench, WebArena, and ToolBench) showing trajectory-level kernel metrics detect strategy breakdowns where pass@1 does not. To make the quantitative evidence fully explicit, we will revise §5 to include head-to-head tables with effect sizes, paired statistical tests (e.g., Wilcoxon signed-rank), 95% confidence intervals, and error bars from repeated runs with different random seeds. We will also add a control analysis varying perturbation strength (low/medium/high) and reporting metric sensitivity at each level. These changes will substantiate the diagnostic sensitivity claim with the requested statistical detail. revision: yes
Circularity Check
No circularity; standard statistical tools applied directly
full rationale
The paper's core framework applies U-statistics to output-level reliability and kernel-based metrics to trajectory-level stability as direct, off-the-shelf statistical constructions. These are not defined in terms of the target consistency quantities, nor are any parameters fitted to a subset of data and then relabeled as predictions. The distinction between core capability and execution robustness is a conceptual framing rather than a mathematical reduction. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the derivation. The metrics remain independent of the perturbation-generation process they are applied to, satisfying the self-contained benchmark criterion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Spider 2.0: Evaluating language models on real-world enterprise text-to- SQL workflows
R. Cao et al. Spider2-V: How far are multimodal agents from automating data science and engineering workflows?arXiv preprint arXiv:2411.07763, 2024. URLhttps://arxiv. org/abs/2411.07763
- [2]
-
[3]
M. Cuturi, J.-P. Vert, O. Birkenes, and T. Matsui. A kernel for time series based on global align- ments. In2007 IEEE International Conference on Acoustics, Speech and Signal Processing - ICASSP ’07, volume 2, pages II–413–II–416, 2007. doi: 10.1109/ICASSP.2007.366260
-
[4]
Lost in the Middle: How Language Models Use Long Contexts
Y . Elazar, N. Kassner, S. Ravfogel, et al. Measuring and Improving Consistency in Pretrained Language Models.Transactions of the Association for Computational Linguistics, 2021. doi: 10.1162/tacl a 00410
work page internal anchor Pith review doi:10.1162/tacl 2021
- [5]
-
[6]
Harbor: A framework for containerized agent execution.https://github
Harbor Team. Harbor: A framework for containerized agent execution.https://github. com/harbor-framework/harbor, 2024
work page 2024
- [7]
-
[8]
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, C. Zhang, J. Wang, Z. Wang, S. K. S. Yau, Z. Lin, L. Zhou, C. Ran, L. Xiao, C. Wu, and J. Schmidhuber. Metagpt: Meta programming for a multi-agent collaborative framework. 2024. URLhttps://arxiv.org/abs/2308.00352
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan. Swe-bench: Can language models resolve real-world github issues? 2024. URLhttps://arxiv.org/ abs/2310.06770
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Certifying llm safety against adversarial prompting
A. Kumar, C. Agarwal, S. Srinivas, A. J. Li, S. Feizi, and H. Lakkaraju. Certifying llm safety against adversarial prompting. 2025. URLhttps://arxiv.org/abs/2309.02705
-
[11]
Lee.U-Statistics: Theory and Practice
A. Lee.U-Statistics: Theory and Practice. Marcel Dekker, Inc., 1990
work page 1990
-
[12]
Mcp server.https://linear.app/docs/mcp
Linear Team. Mcp server.https://linear.app/docs/mcp. accessed on May 4, 2026
work page 2026
- [13]
-
[14]
M. A. Merrill et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces, 2026. URLhttps://arxiv.org/abs/2601.11868
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
J. Novikova, C. Anderson, B. Blili-Hamelin, D. Rosati, and S. Majumdar. Consistency in language models: Current landscape, challenges, and future directions, 2025. URLhttps: //arxiv.org/abs/2505.00268
-
[16]
S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez. Gorilla: Large language model connected with massive APIs.arXiv preprint arXiv:2305.15334, 2024. URLhttps://arxiv.org/ abs/2305.15334
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
C. Qian, W. Liu, H. Liu, N. Chen, Y . Dang, J. Li, C. Yang, W. Chen, Y . Su, X. Cong, J. Xu, D. Li, Z. Liu, and M. Sun. Chatdev: Communicative agents for software development. 2024. URLhttps://arxiv.org/abs/2307.07924
work page internal anchor Pith review arXiv 2024
-
[18]
Towards a science of ai agent reliability, 2026
S. Rabanser, S. Kapoor, P. Kirgis, K. Liu, S. Utpala, and A. Narayanan. Towards a science of ai agent reliability, 2026. URLhttps://arxiv.org/abs/2602.16666. 10
-
[19]
E. Rabinovich, S. Ackerman, O. Raz, E. Farchi, and A. Anaby Tavor. Predicting question-answering performance of large language models through semantic consistency. In S. Gehrmann, A. Wang, J. Sedoc, E. Clark, K. Dhole, K. R. Chandu, E. Santus, and H. Sedghamiz, editors,Proceedings of the Third Workshop on Natural Language Genera- tion, Evaluation, and Met...
work page 2023
- [20]
- [21]
-
[22]
Deepseek/kimi models produce malformed XML tool calls
r/RooCode Community. Deepseek/kimi models produce malformed XML tool calls. Reddit discussion, Jan. 2025. URLhttps://www.reddit.com/r/RooCode/comments/1rk90b7/ deepseek_kimi_models_produce_malformed_xml_tool/. Accessed May 4, 2025
work page 2025
-
[23]
Y . Ruan, H. Dong, A. Wang, S. Pitis, Y . Zhou, J. Ba, Y . Dubois, C. J. Maddison, and T. Hashimoto. Identifying the risks of lm agents with an lm-emulated sandbox. 2024. URL https://arxiv.org/abs/2309.15817
work page internal anchor Pith review arXiv 2024
-
[24]
S. Sadhuka, D. Prinster, C. Fannjiang, G. Scalia, A. Regev, and H. Wang. E-valuator: Reliable agent verifiers with sequential hypothesis testing, 2025. URLhttps://arxiv.org/abs/ 2512.03109
-
[25]
R. J. Serfling.Approximation Theorems of Mathematical Statistics. John Wiley & Sons, 1980
work page 1980
- [26]
-
[27]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
M. Suzgun, N. Scales, N. Sch ¨arli, S. Gehrmann, Y . Tay, H. W. Chung, A. Chowdhery, Q. V . Le, E. H. Chi, D. Zhou, and J. Wei. Challenging big-bench tasks and whether chain-of-thought can solve them, 2022. URLhttps://arxiv.org/abs/2210.09261
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Swe-bench leaderboard.https://www.swebench.com, 2024
SWE-bench Team. Swe-bench leaderboard.https://www.swebench.com, 2024. Accessed October 2024
work page 2024
-
[29]
Swe-bench live leaderboard.https://www.swebench.com/live, 2025
SWE-bench Team. Swe-bench live leaderboard.https://www.swebench.com/live, 2025. Accessed January 2025
work page 2025
-
[30]
Large language models still can't plan (A benchmark for llms on planning and reasoning about change)
K. Valmeekam, M. Marquez, A. Olmo, S. Sreedharan, and S. Kambhampati. Planbench: An extensible benchmark for evaluating large language models on planning and reasoning about change. 2023. URLhttps://arxiv.org/abs/2206.10498
- [31]
-
[32]
C. Yang, Y . Shi, Q. Ma, M. X. Liu, C. K ¨astner, and T. Wu. What prompts don’t say: Under- standing and managing underspecification in llm prompts, 2025. URLhttps://arxiv.org/ abs/2505.13360
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. React: Synergizing reasoning and acting in language models. 2023. URLhttps://arxiv.org/abs/2210. 03629
work page 2023
-
[34]
S. Yao, N. Shinn, P. Razavi, and K. Narasimhan.τ-bench: A benchmark for tool-agent-user interaction in real-world domains. 2024. URLhttps://arxiv.org/abs/2406.12045
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
K. Zhu, J. Wang, J. Zhou, Z. Wang, H. Chen, Y . Wang, L. Yang, W. Ye, Y . Zhang, N. Z. Gong, and X. Xie. Promptrobust: Towards evaluating the robustness of large language models on adversarial prompts. 2024. URLhttps://arxiv.org/abs/2306.04528. 11 A Proofs A.1 Proof of Theorem 1 Under Assumption 2, the instance-level U-statistics{U m n }M m=1 are independ...
-
[36]
g e t _ b i g f i v e _ s c o r e s
=O p(1)by Theorem 1. ThereforeP H1(TM,n <−z 1−α)→1. A.3 Proof of Theorem 3 By our assumptions, each \MMD 2,m u is an independent realization with common mean E[ \MMD 2,m u ] =δwhereδ= MMD 2(P0,{P j}n j=1)and common varianceσ 2 MMD = V( \MMD 2,m u )∈(0,∞). Under the null hypothesisH tr 0 :P 0 =P 1 =· · ·=P n, we haveδ= 0. The aggregate statistic is: MMD 2 ...
-
[37]
** Query Linear **: Use the Linear MCP tools to re tri ev e issue ‘ django__django -16819 ‘ 22
-
[38]
** Read Issue Details **: Review the issue d e s c r i p t i o n and r e q u i r e m e n t s
-
[39]
** I m p l e m e n t Fix **: Make the n e c e s s a r y code changes to resolve the issue
-
[40]
** Verify **: Ensure your changes work c o r r e c t l y ## A v a i l a b l e MCP Tools - ‘ get_issue ‘: Get a Linear issue by ID - ‘ list_issues ‘: List all issues , o p t i o n a l l y fi lt ere d by project - ‘ search_issues ‘: Search issues by query string - ‘ g e t _ i s s u e _ c o m m e n t s ‘: Get all com me nts for an issue BFCL decoy-func.Inser...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.