Recognition: no theorem link
Thinking with Novel Views: A Systematic Analysis of Generative-Augmented Spatial Intelligence
Pith reviewed 2026-05-12 03:13 UTC · model grok-4.3
The pith
Integrating novel-view synthesis into the reasoning loop improves spatial reasoning accuracy in large multimodal models by 1.3 to 3.9 percentage points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that novel-view generation can be inserted directly into the LMM reasoning loop so that the model identifies spatial ambiguity, requests an alternative viewpoint, and re-examines the scene with the new evidence, yielding consistent accuracy gains of 1.3 to 3.9 percentage points on spatial tasks.
What carries the argument
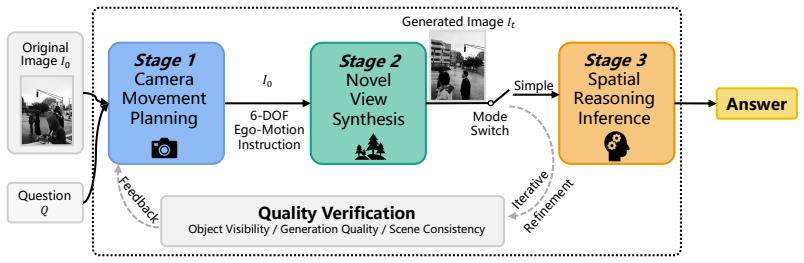
The TwNV loop, in which a Reasoner LMM detects ambiguity and directs a Painter model to synthesize a controlled alternative viewpoint for re-examination.
Load-bearing premise
The synthesized views must supply reliable spatial evidence without misleading artifacts that the reasoner can successfully incorporate into its decisions.
What would settle it
Re-running the spatial tasks with and without the novel-view loop and finding no accuracy improvement, or finding that lower-quality generations produce equal or worse results than the single-view baseline.
Figures







read the original abstract
Current Large Multimodal Models (LMMs) struggle with spatial reasoning tasks requiring viewpoint-dependent understanding, largely because they are confined to a single, static observation. We propose Thinking with Novel Views (TwNV), a paradigm that integrates generative novel-view synthesis into the reasoning loop: a Reasoner LMM identifies spatial ambiguity, instructs a Painter to synthesize an alternative viewpoint, and re-examines the scene with the additional evidence. Through systematic experiments we address three research questions. (1) Instruction format: numerical camera-pose specifications yield more reliable view control than free-form language. (2) Generation fidelity: synthesized view quality is tightly coupled with downstream spatial accuracy. (3) Inference-time visual scaling: iterative multi-turn view refinement further improves performance, echoing recent scaling trends in language reasoning. Across four spatial subtask categories and four LMM architectures (both closed- and open-source), TwNV consistently improves accuracy by +1.3 to +3.9 pp, with the largest gains on viewpoint-sensitive subtasks. These results establish novel-view generation as a practical lever for advancing spatial intelligence of LMMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Thinking with Novel Views (TwNV), a paradigm that augments Large Multimodal Models (LMMs) with generative novel-view synthesis in a multi-turn reasoning loop: a Reasoner LMM detects spatial ambiguity, directs a Painter to generate an alternative viewpoint, and re-evaluates the scene. It systematically evaluates three research questions on instruction formats for view control, the coupling between generation fidelity and accuracy, and iterative multi-turn refinement, reporting consistent accuracy gains of +1.3 to +3.9 pp across four spatial subtask categories and four LMMs (closed- and open-source), with largest benefits on viewpoint-sensitive tasks.
Significance. If the results hold after addressing the isolation of causal factors, the work provides a practical, training-free method to improve spatial reasoning in LMMs by leveraging existing generative models, with potential to generalize to other visual tasks requiring viewpoint invariance. The cross-model and cross-task evaluation offers a useful benchmark for generative augmentation approaches.
major comments (2)
- [Experiments (RQ2)] Abstract and Experiments section (RQ2): The central claim that 'synthesized view quality is tightly coupled with downstream spatial accuracy' is not supported by any per-sample correlation analysis between view fidelity metrics (PSNR, LPIPS, or CLIP similarity to reference views) and per-instance accuracy deltas. Without this, the reported +1.3–3.9 pp gains cannot be attributed to geometric/photometric fidelity rather than multi-turn prompting, extra visual tokens, or instruction effects.
- [§4] Abstract and §4 (experimental setup): No details are provided on baseline comparisons (e.g., multi-turn prompting without novel views, or random view synthesis), statistical significance tests, dataset sizes per subtask, or controls for generation artifacts, which are load-bearing for interpreting the consistent positive results across models and tasks.
minor comments (2)
- [Abstract] The abstract mentions 'four spatial subtask categories' but does not enumerate them explicitly; a table or list in the introduction would improve clarity.
- [Introduction] Notation for the Painter and Reasoner LMM roles is introduced without a formal diagram or pseudocode, making the loop structure harder to follow on first reading.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, providing clarifications on our existing results and outlining revisions that will strengthen the manuscript's rigor and interpretability.
read point-by-point responses
-
Referee: [Experiments (RQ2)] Abstract and Experiments section (RQ2): The central claim that 'synthesized view quality is tightly coupled with downstream spatial accuracy' is not supported by any per-sample correlation analysis between view fidelity metrics (PSNR, LPIPS, or CLIP similarity to reference views) and per-instance accuracy deltas. Without this, the reported +1.3–3.9 pp gains cannot be attributed to geometric/photometric fidelity rather than multi-turn prompting, extra visual tokens, or instruction effects.
Authors: We appreciate the referee's point on establishing a more direct causal attribution. Our RQ2 analysis compares results across generation models of differing fidelity and shows that higher-quality syntheses yield larger aggregate accuracy gains, consistent with the coupling claim. However, we did not include per-sample correlation analysis (e.g., Pearson or Spearman coefficients) between fidelity metrics and per-instance accuracy deltas. We will add this analysis to the revised Experiments section, including scatter plots, correlation values, and discussion of how it helps separate view quality effects from multi-turn prompting or token-count factors. revision: yes
-
Referee: [§4] Abstract and §4 (experimental setup): No details are provided on baseline comparisons (e.g., multi-turn prompting without novel views, or random view synthesis), statistical significance tests, dataset sizes per subtask, or controls for generation artifacts, which are load-bearing for interpreting the consistent positive results across models and tasks.
Authors: We agree these experimental details are necessary for full interpretability and reproducibility. The current version emphasizes the TwNV paradigm and cross-model/task results but does not explicitly report the requested baselines, tests, sizes, or artifact controls. In the revision we will expand §4 to include: (i) baseline comparisons with multi-turn prompting without novel views and with random view synthesis; (ii) statistical significance testing (paired tests with p-values) on the reported gains; (iii) exact dataset sizes per subtask; and (iv) controls for generation artifacts such as quality filtering and per-sample artifact analysis. These additions will better support attribution of the observed improvements. revision: yes
Circularity Check
Empirical evaluation of applied method with no derivations or self-referential reductions
full rationale
The paper describes an empirical paradigm (TwNV) that augments LMM reasoning with generative novel-view synthesis and evaluates it through systematic experiments on four spatial subtasks and four LMM architectures. It reports aggregate accuracy gains (+1.3 to +3.9 pp) but contains no mathematical derivations, fitted parameters, predictions, uniqueness theorems, or ansatzes. No equations or self-citations are presented as load-bearing steps that reduce to inputs by construction. The central claims rest on experimental results rather than any chain that collapses to its own definitions or prior self-references.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, et al. Qwen3- VL technical report. arXiv preprint arXiv:2511.21631, 2025. URL https://arxiv.org/abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Precisecam: Precise camera control for text-to-image generation
Edurne Bernal-Berdun, Ana Serrano, Belen Masia, Matheus Gadelha, Yannick Hold-Geoffroy, Xin Sun, and Diego Gutierrez. Precisecam: Precise camera control for text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2724--2733, 2025
work page 2025
-
[4]
Spatialbot: Precise spatial understanding with vision language models
Wenxiao Cai, Iaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spatialbot: Precise spatial understanding with vision language models. arXiv:2406.13642, 2024
-
[5]
Scaling spatial intelligence with multimodal foundation models.arXiv preprint arXiv:2511.13719, 2025
Zhongang Cai, Ruisi Wang, Chenyang Gu, Fanyi Pu, Junxiang Xu, Yubo Wang, Wanqi Yin, Zhitao Yang, Chen Wei, Qingping Sun, et al. Scaling spatial intelligence with multimodal foundation models. arXiv preprint arXiv:2511.13719, 2025
-
[6]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In CVPR, 2024 a
work page 2024
-
[7]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv:2501.17811, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Geometrically-constrained agent for spatial reasoning.arXiv preprint arXiv:2511.22659, 2025
Zeren Chen, Xiaoya Lu, Zhijie Zheng, Pengrui Li, Lehan He, Yijin Zhou, Jing Shao, Bohan Zhuang, and Lu Sheng. Geometrically-constrained agent for spatial reasoning. arXiv preprint arXiv:2511.22659, 2025 b
-
[9]
Zhangquan Chen, Manyuan Zhang, Xinlei Yu, Xufang Luo, Mingze Sun, Zihao Pan, Yan Feng, Peng Pei, Xunliang Cai, and Ruqi Huang. Think with 3d: Geometric imagination grounded spatial reasoning from limited views. arXiv preprint arXiv:2510.18632, 2025 c
-
[10]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In CVPR, 2024 b
work page 2024
-
[11]
Spatialrgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models. NeurIPS, 2024
work page 2024
-
[13]
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Runjin Chen, Hezhen Hu, Kevin Wang, Huaizhi Qu, Dilin Wang, Zhicheng Yan, et al. Vlm-3r: Vision-language models augmented with instruction-aligned 3d reconstruction. arXiv:2505.20279, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Valentin Gabeur, Shangbang Long, Songyou Peng, Paul Voigtlaender, Shuyang Sun, Yanan Bao, Karen Truong, Zhicheng Wang, Wenlei Zhou, Jonathan T. Barron, Kyle Genova, Nithish Kannen, Sherry Ben, Yandong Li, Mandy Guo, Suhas Yogin, Yiming Gu, Huizhong Chen, Oliver Wang, Saining Xie, Howard Zhou, Kaiming He, Thomas Funkhouser, Jean-Baptiste Alayrac, and Radu ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Gemini Team et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025. URL https://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Nano banana pro: Gemini 3 pro image model
Google DeepMind . Nano banana pro: Gemini 3 pro image model. https://blog.google/technology/ai/nano-banana-pro/, 2025
work page 2025
-
[17]
Ego-Exo4D : Understanding skilled human activity from first- and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, et al. Ego-Exo4D : Understanding skilled human activity from first- and third-person perspectives. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[18]
MVImgNet2.0 : A larger-scale dataset of multi-view images
Xiaoguang Han, Yushuang Wu, Luyue Shi, Haolin Liu, Hongjie Liao, Lingteng Qiu, Weihao Yuan, Xiaodong Gu, Zilong Dong, and Shuguang Cui. MVImgNet2.0 : A larger-scale dataset of multi-view images. ACM Transactions on Graphics (TOG), 43 0 (6), 2024
work page 2024
-
[19]
Thinking with camera: A unified multimodal model for camera-centric understanding and generation
Kang Liao, Size Wu, Zhonghua Wu, Linyi Jin, Chao Wang, Yikai Wang, Fei Wang, Wei Li, and Chen Change Loy. Thinking with camera: A unified multimodal model for camera-centric understanding and generation. arXiv preprint arXiv:2510.08673, 2025
-
[21]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647, 2025 b
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
DL3DV-10K : A large-scale scene dataset for deep learning-based 3D vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, Xuanmao Li, Aniruddha Mukherjee, Rohan Ashok, Xingpeng Sun, Xiangrui Kong, Hao Kang, Tianyi Zhang, Aniket Bera, Gang Hua, and Bedrich Benes. DL3DV-10K : A large-scale scene dataset for deep learning-based 3D vision. In Proceedings of the IEEE/CVF Co...
work page 2024
-
[23]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In NeurIPS, 2024
work page 2024
-
[24]
Zero-1-to-3: Zero-shot one image to 3D object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. Zero-1-to-3: Zero-shot one image to 3D object. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
work page 2023
-
[25]
Abstract 3D Perception for Spatial Intelligence in Vision-Language Models
Yifan Liu, Fangneng Zhan, Kaichen Zhou, Yilun Du, Paul Pu Liang, and Hanspeter Pfister. Abstract 3d perception for spatial intelligence in vision-language models. arXiv preprint arXiv:2511.10946, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
3DSRBench : A comprehensive 3D spatial reasoning benchmark
Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso de Melo, and Alan Yuille. 3DSRBench : A comprehensive 3D spatial reasoning benchmark. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[27]
OpenAI. OpenAI GPT-5 system card. arXiv preprint arXiv:2601.03267, 2025 a . URL https://arxiv.org/abs/2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Introducing our latest image generation model in the API
OpenAI. Introducing our latest image generation model in the API . https://openai.com/index/image-generation-api, April 2025 b
work page 2025
-
[29]
Thomas Sch\" o ps, Johannes L. Sch\" o nberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and Andreas Geiger. A multi-view stereo benchmark with high-resolution images and multi-camera videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017
work page 2017
-
[30]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report. arXiv preprint arXiv:2508.02324, 2025 a . URL https://arxiv.org/abs/2508.02324
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence. arXiv preprint arXiv:2505.23747, 2025 b
-
[32]
Junfei Wu, Jian Guan, Kaituo Feng, Qiang Liu, Shu Wu, Liang Wang, Wei Wu, and Tieniu Tan. Reinforcing spatial reasoning in vision-language models with interwoven thinking and visual drawing. arXiv:2506.09965, 2025 c
-
[33]
RealWorldQA : An image understanding benchmark for real-world spatial reasoning
xAI . RealWorldQA : An image understanding benchmark for real-world spatial reasoning. https://x.ai/news/grok-1.5v, 2024
work page 2024
-
[34]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation. arXiv:2408.12528, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Gpt4tools: Teaching large language model to use tools via self-instruction
Rui Yang, Lin Song, Yanwei Li, Sijie Zhao, Yixiao Ge, Xiu Li, and Ying Shan. Gpt4tools: Teaching large language model to use tools via self-instruction. In NeurIPS, 2024
work page 2024
-
[36]
Visual spatial tuning.arXiv preprint arXiv:2511.05491, 2025
Rui Yang, Ziyu Zhu, Yanwei Li, Jingjia Huang, Shen Yan, Siyuan Zhou, Zhe Liu, Xiangtai Li, Shuangye Li, Wenqian Wang, et al. Visual spatial tuning. arXiv preprint arXiv:2511.05491, 2025
-
[37]
ScanNet++ : A high-fidelity dataset of 3D indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nie ner, and Angela Dai. ScanNet++ : A high-fidelity dataset of 3D indoor scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 12--22, 2023
work page 2023
-
[38]
RSA : Resolving scale ambiguities in monocular depth estimators through language descriptions
Ziyao Zeng, Yangchao Wu, Hyoungseob Park, Daniel Wang, Fengyu Yang, Stefano Soatto, Dong Lao, Byung-Woo Hong, and Alex Wong. RSA : Resolving scale ambiguities in monocular depth estimators through language descriptions. arXiv preprint arXiv:2410.02924, 2024
-
[39]
arXiv preprint arXiv:2511.23127 (2025)
Hongfei Zhang, Kanghao Chen, Zixin Zhang, Harold Haodong Chen, Yuanhuiyi Lyu, Yuqi Zhang, Shuai Yang, Kun Zhou, and Yingcong Chen. Dualcamctrl: Dual-branch diffusion model for geometry-aware camera-controlled video generation. arXiv preprint arXiv:2511.23127, 2025
-
[40]
Think3d: Thinking with space for spatial reasoning
Zaibin Zhang, Yuhan Wu, Lianjie Jia, Yifan Wang, Zhongbo Zhang, Yijiang Li, Binghao Ran, Fuxi Zhang, Zhuohan Sun, Zhenfei Yin, et al. Think3d: Thinking with space for spatial reasoning. arXiv preprint arXiv:2601.13029, 2026
-
[41]
Cov: Chain-of-view prompting for spatial reasoning
Haoyu Zhao, Akide Liu, Zeyu Zhang, Weijie Wang, Feng Chen, Ruihan Zhu, Gholamreza Haffari, and Bohan Zhuang. Cov: Chain-of-view prompting for spatial reasoning. arXiv preprint arXiv:2601.05172, 2026
-
[42]
Stereo magnification: Learning view synthesis using multiplane images
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view synthesis using multiplane images. ACM Transactions on Graphics (Proc. SIGGRAPH), 37 0 (4): 0 1--12, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.