Recognition: no theorem link
When Can Digital Personas Reliably Approximate Human Survey Findings?
Pith reviewed 2026-05-12 04:29 UTC · model grok-4.3
The pith
Digital personas built from past responses and backgrounds improve matches to human survey distributions on stable topics but cannot predict individuals or recover how respondents cluster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
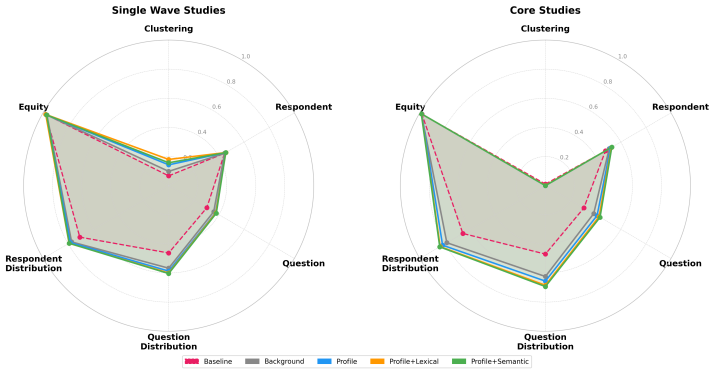
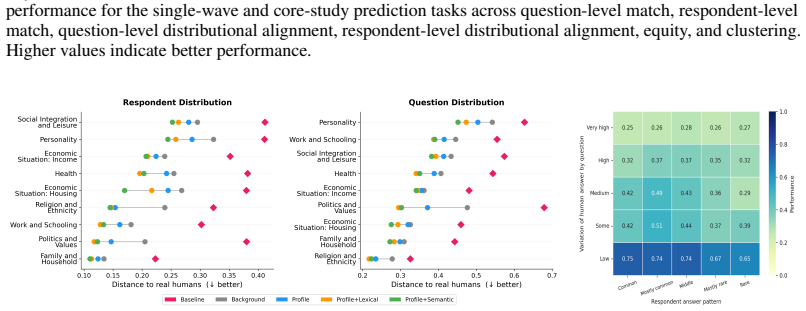
Digital personas improve alignment with human response distributions, especially in domains tied to stable attributes and values, but remain limited for individual prediction and fail to recover multivariate respondent structure. Retrieval-augmented architectures provide the clearest gains, but performance depends more on human response structure than on model choice: personas perform best for low-variability questions and common respondent patterns, and worst for subjective, heterogeneous, or rare responses.
What carries the argument
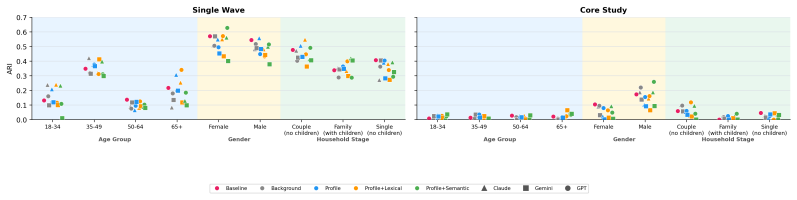
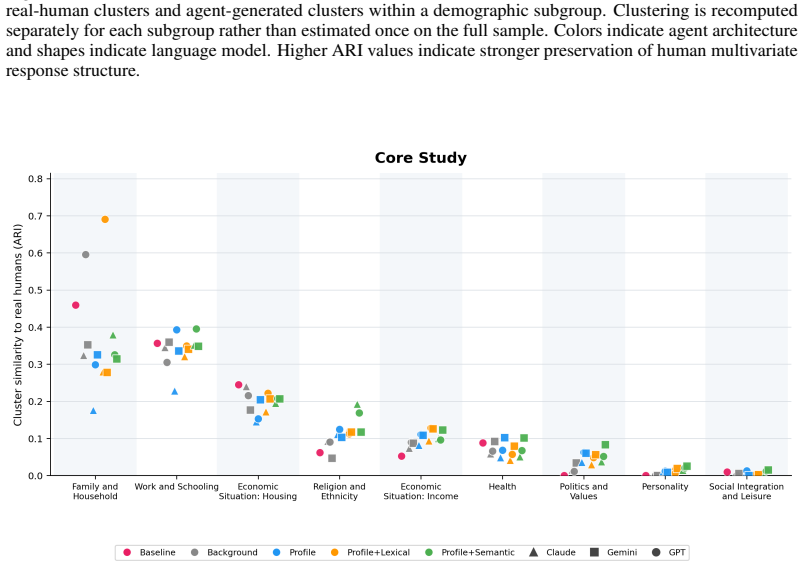
Personas constructed from pre-2023 background variables and survey histories, evaluated against the same respondents' post-cutoff held-out answers at question, individual, distributional, equity, and clustering levels across four architectures and three models.
If this is right
- Personas work best on low-variability questions and common response patterns.
- Retrieval-augmented designs deliver the strongest distributional improvements.
- Human validation stays necessary for subjective, heterogeneous, or rare responses.
- Overall success tracks the structure of human answers more than which language model is used.
- Equity checks across respondent groups show where alignment holds or breaks.
Where Pith is reading between the lines
- Researchers could first run personas on stable demographic questions to screen or supplement samples before committing to full human panels.
- For studies tracking attitudes that shift with events or time, the temporal cutoff in the test design highlights the need for ongoing human calibration.
- The inability to recover respondent clusters implies that persona outputs may flatten the natural diversity present in real populations.
- Future tests could examine whether adding recent calibration data narrows the gap on changeable topics without retraining entire models.
Load-bearing premise
Historical respondent data and background variables let the models generate answers that continue to match future human responses without introducing model-specific biases or population shifts.
What would settle it
Demonstrating that the same personas accurately predict answers on high-variability subjective questions or reconstruct the original human respondent clusters from the data would falsify the claim of limited individual and multivariate performance.
Figures









read the original abstract
Digital personas powered by Large Language Models (LLMs) are increasingly proposed as substitutes for human survey respondents, yet it remains unclear when they can reliably approximate human survey findings. We answer this question using the LISS panel, constructing personas from respondents' background variables and pre-2023 survey histories, then testing them against the same respondents' held-out post-cutoff answers. Across four persona architectures, three LLMs, and two prediction tasks, we assess performance at the question, respondent, distributional, equity, and clustering levels. Digital personas improve alignment with human response distributions, especially in domains tied to stable attributes and values, but remain limited for individual prediction and fail to recover multivariate respondent structure. Retrieval-augmented architectures provide the clearest gains, but performance depends more on human response structure than on model choice: personas perform best for low-variability questions and common respondent patterns, and worst for subjective, heterogeneous, or rare responses. Our results provide practical guidance on when digital personas could be appropriate for survey research and when human validation remains necessary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines when LLM-powered digital personas can reliably approximate human survey responses. Using the LISS panel, it constructs personas from respondents' pre-2023 background variables and survey histories, then evaluates them against the same respondents' held-out post-cutoff answers. Across four persona architectures, three LLMs, and analyses at question, respondent, distributional, equity, and clustering levels, the paper finds that personas improve alignment with human response distributions (especially for stable attributes and values), but are limited for individual-level prediction and fail to recover multivariate respondent structure. Retrieval-augmented methods show the clearest gains, while performance depends more on the structure of human responses (low variability, common patterns) than on model choice.
Significance. If the results hold, this work provides valuable practical guidance on appropriate use cases for digital personas in survey research, distinguishing domains where they may substitute for humans from those requiring validation. The temporal hold-out design with real panel data, multi-level evaluation, and systematic comparison across architectures and LLMs are strengths that allow falsifiable assessment of approximation quality. The emphasis on human response structure as the key driver of performance is a useful insight for the field.
major comments (2)
- [Section 3] Section 3 (Persona Construction and Evaluation Design): The central claim that personas improve distributional alignment depends on the post-cutoff human answers serving as an unbiased benchmark for what the personas approximate. However, the single pre-/post-2023 temporal split does not include non-LLM baselines that use the identical pre-2023 features or explicit controls for temporal population shifts. This makes it difficult to attribute observed gains cleanly to the persona mechanism rather than to response stability or LLM-specific artifacts, which is load-bearing for the title question of 'when' personas can reliably approximate.
- [Section 5] Section 5 (Results): The claims of improved alignment 'especially in domains tied to stable attributes' and that 'retrieval-augmented architectures provide the clearest gains' require supporting quantitative details. The results should report exact metrics (e.g., distributional distances or agreement rates), error bars or confidence intervals, and statistical tests comparing architectures; without these, the magnitude and reliability of the reported patterns remain difficult to assess.
minor comments (2)
- [Abstract] Abstract: Including one or two concrete quantitative results (e.g., specific improvement in alignment metric or percentage gain for retrieval-augmented personas) would make the summary claims more precise and informative.
- [Introduction] Throughout: Ensure consistent and explicit definitions for the four persona architectures when first introduced, to help readers track the comparisons across experiments.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments, which help sharpen the interpretation of our evaluation design and results. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Section 3] Section 3 (Persona Construction and Evaluation Design): The central claim that personas improve distributional alignment depends on the post-cutoff human answers serving as an unbiased benchmark for what the personas approximate. However, the single pre-/post-2023 temporal split does not include non-LLM baselines that use the identical pre-2023 features or explicit controls for temporal population shifts. This makes it difficult to attribute observed gains cleanly to the persona mechanism rather than to response stability or LLM-specific artifacts, which is load-bearing for the title question of 'when' personas can reliably approximate.
Authors: We agree that stronger attribution would benefit from additional contrasts. Our design employs a temporal hold-out so that post-2023 responses are unseen, and we systematically compare four persona architectures that vary in how they use the same pre-2023 information. This already isolates effects attributable to different persona mechanisms within the LLM setting. Nevertheless, we acknowledge that non-LLM baselines (e.g., logistic regression or random forests trained on identical pre-2023 features) would more cleanly separate LLM-specific contributions from general predictability of stable responses. We will add these baselines to the revised Section 3 and 4. We will also expand the discussion of temporal stability in the LISS panel and any implications for the benchmark. revision: yes
-
Referee: [Section 5] Section 5 (Results): The claims of improved alignment 'especially in domains tied to stable attributes' and that 'retrieval-augmented architectures provide the clearest gains' require supporting quantitative details. The results should report exact metrics (e.g., distributional distances or agreement rates), error bars or confidence intervals, and statistical tests comparing architectures; without these, the magnitude and reliability of the reported patterns remain difficult to assess.
Authors: We appreciate the call for greater quantitative precision. The current manuscript reports comparative patterns across architectures and question types, including breakdowns by attribute stability. To make the magnitude and reliability of these patterns fully transparent, we will revise Section 5 to include exact metric values (e.g., specific distributional distances and agreement rates), bootstrapped error bars or confidence intervals, and statistical tests (e.g., paired Wilcoxon or t-tests with p-values) for architecture comparisons. These additions will directly support the statements regarding stable attributes and retrieval-augmented gains. revision: yes
Circularity Check
No circularity; empirical evaluation uses independent held-out human data
full rationale
The paper constructs digital personas exclusively from pre-2023 respondent histories and background variables in the LISS panel, then directly compares their outputs to the same respondents' post-cutoff held-out answers. This setup provides an external benchmark with no derivations, equations, or first-principles results that reduce to fitted parameters or self-referential definitions by construction. Assessments at question, respondent, distributional, equity, and clustering levels rely on straightforward comparisons to human responses rather than any renaming, ansatz smuggling, or self-citation chains. The analysis is self-contained against external benchmarks, with performance differences attributed to observed human response structure rather than internal fitting loops.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can be prompted to simulate individual survey respondents using background variables and historical responses.
- domain assumption The LISS panel provides a representative testbed and the 2023 cutoff cleanly separates training history from held-out evaluation without population drift.
Reference graph
Works this paper leans on
-
[1]
Journal of Classification2(1), 193–218 (1985) https://doi.org/10.1007/BF01908075
doi: 10.1007/BF01908075. URLhttps://doi.org/10.1007/BF01908075. 11 Jessica Hullman, David Broska, Huaman Sun, and Aaron Shaw. This human study did not involve human subjects: Validating LLM simulations as behavioral evidence, 2026. URL https:// arxiv.org/abs/2602.15785. EunJeong Hwang, Bodhisattwa Majumder, and Niket Tandon. Aligning language models to us...
-
[2]
Carolin Kaiser, Jakob Kaiser, Vladimir Manewitsch, Lea Rau, and Rene Schallner
URLhttps://openreview.net/forum?id=6ox8XZGOqP. Carolin Kaiser, Jakob Kaiser, Vladimir Manewitsch, Lea Rau, and Rene Schallner. Simulating human opinions with large language models: Opportunities and challenges for personalized survey data modeling. InAdjunct Proceedings of the 33rd ACM Conference on User Modeling, Adaptation and Personalization, UMAP Adju...
-
[3]
Ang Li, Haozhe Chen, Hongseok Namkoong, and Tianyi Peng
URLhttps://aclanthology.org/2025.emnlp-main.1530/. Ang Li, Haozhe Chen, Hongseok Namkoong, and Tianyi Peng. LLM generated persona is a promise with a catch. InThe Thirty-Ninth Annual Conference on Neural Information Processing Systems Position Paper Track, 2025a. URLhttps://openreview.net/forum?id=qh9eGtMG4H. Chance Jiajie Li, Zhenze Mo, Yuhan Tang, Ao Qu...
-
[4]
You map user profile data to survey answers carefully and transparently
URLhttps://arxiv.org/abs/2511.21722. Joseph Suh, Erfan Jahanparast, Suhong Moon, Minwoo Kang, and Serina Chang. Language model fine-tuning on scaled survey data for predicting distributions of public opinions. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, pages 21147–21170. Association for Computational Linguis...
-
[5]
Values and motivations
-
[6]
Biases and heuristics
-
[7]
Confidence patterns Past Q&A: {history_text} 16 The profile must contain all seven section headers and must not exceed 1,500 words. If either constraint is violated, the call is retried with the validation error appended to the prompt; generation is attempted up to three times before the run aborts. A cached profile is identified by user ID, dataset sourc...
-
[9]
- Use the profile and background data to infer the most likely response
the respondent background data as supporting context Background data: {bg_context} Behavioral profile: {structured_profile} Instructions: - Answer as the person. - Use the profile and background data to infer the most likely response. - If the answer is uncertain, choose the response most consistent with the available evidence. - Provide exactly one answe...
-
[10]
the behavioral profile below
-
[11]
the retrieved prior answers as behavioral evidence
-
[12]
- Use the profile, background data, and retrieved answers to infer the most likely response
the respondent background data as supporting context Background data: {bg_context} Behavioral profile: {structured_profile} Retrieved prior answers (most relevant to this batch): {related_rows_text} Instructions: - Answer as the person. - Use the profile, background data, and retrieved answers to infer the most likely response. - If the answer is uncertai...
-
[13]
Parsing.Optional Markdown code fences are stripped; the remaining text must parse as valid JSON
-
[14]
Schema.The parsed object must contain a predictions array whose entries each carry variable_nameandpredicted_answerkeys
-
[15]
Coverage.The set of returned variable_name values must exactly equal the expected set for the sub-batch; both omissions and unexpected additions are treated as failures
-
[16]
Type and range.Each answer is normalized by declared response type: categorical answers must be a valid category code; numeric answers must fall within the declared range; open- ended answers are accepted as-is. On failure, the invalid response and the associated error message are appended to the prompt, and the call is reissued. Prediction calls are retr...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.