Recognition: unknown
ALAM: Algebraically Consistent Latent Action Model for Vision-Language-Action Models
Pith reviewed 2026-05-14 21:12 UTC · model grok-4.3
The pith
ALAM turns action-free videos into algebraically consistent latent transitions that flow-matching policies can use directly to raise manipulation success rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ALAM learns latent transitions from video frame triplets that satisfy reconstruction while obeying composition and reversal consistency, creating a locally additive transition space; when these structured sequences are supplied as auxiliary targets in a joint flow-matching loss with robot actions, the policy can directly exploit the latent geometry to improve generation without latent-to-action decoding.
What carries the argument
Algebraically consistent latent transitions from frame triplets, regularized for composition and reversal to enforce local additivity while remaining reconstruction-grounded.
If this is right
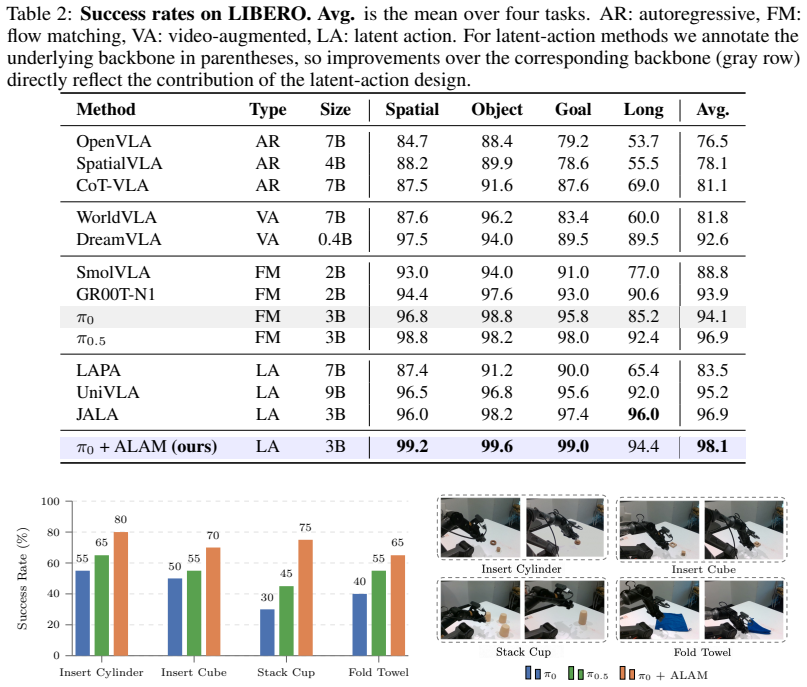
- Average success on MetaWorld MT50 rises from 47.9% to 85.0% and on LIBERO from 94.1% to 98.1% when ALAM latents are used as auxiliary targets.
- Additivity and reversibility errors drop by factors of 25-85 compared with unstructured latent-action models.
- Long-horizon cumulative reconstruction improves because the transition space is locally additive.
- Real-world manipulation tasks show consistent gains once the frozen ALAM encoder supplies the structured sequences.
- The strongest performance lift occurs only when algebraic consistency is combined with joint flow matching.
Where Pith is reading between the lines
- The same consistency regularizers could be applied to other generative policies that operate in latent spaces, such as diffusion-based planners.
- Because the transitions are locally additive, they may support zero-shot composition of novel long-horizon behaviors from short video clips.
- If the additive property holds across domains, the approach might transfer to navigation or multi-agent interaction settings where only passive video is available.
- Removing the need for explicit latent decoding simplifies the training pipeline and could reduce compounding errors in long sequences.
Load-bearing premise
The algebraically consistent latent transitions learned from videos supply useful structure that a flow-matching policy can exploit directly without decoding the latents back to actions.
What would settle it
Train the same flow-matching VLA policy on MetaWorld MT50 using ALAM latents versus an unstructured latent-action baseline; if success rates remain statistically indistinguishable or the consistency ablations produce no drop, the central claim fails.
Figures






read the original abstract
Vision-language-action (VLA) models remain constrained by the scarcity of action-labeled robot data, whereas action-free videos provide abundant evidence of how the physical world changes. Latent action models offer a promising way to extract such priors from videos, but reconstruction-trained latent codes are not necessarily suitable for policy generation: they may predict future observations while lacking the structure needed to be reused or generated coherently with robot actions. We introduce ALAM (Algebraic Latent Action Model), an Algebraically Consistent Latent Action Model that turns temporal relations in action-free video into structural supervision. Given frame triplets, ALAM learns latent transitions that are grounded by reconstruction while being regularized by composition and reversal consistency, encouraging a locally additive transition space. For downstream VLA learning, we freeze the pretrained encoder and use its latent transition sequences as auxiliary generative targets, co-generated with robot actions under a joint flow-matching objective. This couples structured latent transitions with flow-based policy generation, allowing the policy to exploit ALAM's locally consistent transition geometry without requiring latent-to-action decoding. Representation probes show that ALAM reduces additivity and reversibility errors by 25-85 times over unstructured latent-action baselines and improves long-horizon cumulative reconstruction. When transferred to VLA policies, ALAM raises the average success rate from 47.9% to 85.0% on MetaWorld MT50 and from 94.1% to 98.1% on LIBERO, with consistent gains on real-world manipulation tasks. Ablations further confirm that the strongest improvements arise from the synergy between algebraically structured latent transitions and joint flow matching.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ALAM, an Algebraically Consistent Latent Action Model that extracts structured latent transitions from action-free video frame triplets by combining reconstruction with explicit composition and reversal consistency constraints to produce a locally additive latent space. These frozen latents serve as auxiliary targets in a joint flow-matching objective for training vision-language-action policies, allowing the policy to exploit the transition geometry without explicit latent-to-action decoding. Representation probes demonstrate 25-85x reductions in additivity and reversibility errors relative to unstructured baselines, and downstream transfer yields large gains: average success rising from 47.9% to 85.0% on MetaWorld MT50 and from 94.1% to 98.1% on LIBERO, with further real-world improvements. Ablations attribute the gains to the interaction between algebraic structure and joint flow matching.
Significance. If the gains are reproducible, the work offers a practical route to leverage abundant unlabeled video for VLA improvement by imposing algebraic structure on latent transitions rather than relying solely on reconstruction. The avoidance of latent decoding and the joint flow-matching formulation are pragmatic strengths that could improve data efficiency in robotics. The reported synergy between consistency regularization and policy training, if confirmed, would strengthen the case for structured latent priors in sequential decision-making.
major comments (2)
- [Methods (joint flow-matching objective)] The central performance claims rest on the joint flow-matching objective that co-generates latent transitions and robot actions; the exact form of this objective, the weighting between the two generative targets, and how the frozen encoder outputs are injected into the flow network must be specified with equations in the methods section to permit verification of the coupling mechanism.
- [Representation probes and ablations] Representation probes report 25-85x error reductions in additivity and reversibility; the precise definitions of these error metrics, the baseline latent-action models, and the long-horizon cumulative reconstruction protocol should be detailed (including any statistical tests) because these numbers are used to validate that the consistency constraints produce usable structure.
minor comments (2)
- Ensure that all hyperparameters for the consistency regularization weights are reported with their chosen values and any sensitivity analysis, as these are listed among the free parameters.
- Figure captions and table footnotes should explicitly state the number of evaluation episodes or seeds used for the MetaWorld and LIBERO success rates to support the reported averages.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. The comments highlight opportunities to improve clarity in the methods and evaluation sections, which we will address by adding the requested details and equations to the revised manuscript.
read point-by-point responses
-
Referee: [Methods (joint flow-matching objective)] The central performance claims rest on the joint flow-matching objective that co-generates latent transitions and robot actions; the exact form of this objective, the weighting between the two generative targets, and how the frozen encoder outputs are injected into the flow network must be specified with equations in the methods section to permit verification of the coupling mechanism.
Authors: We agree that the joint flow-matching objective requires explicit mathematical specification for full reproducibility and verification. In the revised manuscript, we will expand the Methods section with a new subsection that presents the complete equations for the joint objective, including the precise weighting coefficients between the latent transition and robot action generation terms, as well as the conditioning mechanism that injects the frozen ALAM encoder outputs into the flow network. This will directly address the coupling mechanism and allow independent verification of the reported performance gains. revision: yes
-
Referee: [Representation probes and ablations] Representation probes report 25-85x error reductions in additivity and reversibility; the precise definitions of these error metrics, the baseline latent-action models, and the long-horizon cumulative reconstruction protocol should be detailed (including any statistical tests) because these numbers are used to validate that the consistency constraints produce usable structure.
Authors: We concur that precise definitions and protocols are necessary to substantiate the representation probe results. In the revision, we will augment the Representation Probes and Ablations sections to include: the exact mathematical formulations of the additivity and reversibility error metrics; descriptions of all baseline latent-action models; the full protocol for long-horizon cumulative reconstruction (including sequence lengths and evaluation procedure); and any statistical tests or variance measures (e.g., standard deviations across seeds). These additions will strengthen the evidence that the algebraic consistency constraints yield usable structure. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper explicitly adds composition and reversal consistency terms as regularization to the reconstruction loss on frame triplets, then freezes the encoder and uses the resulting latent transitions as auxiliary targets in a joint flow-matching objective for downstream VLA policies. Performance gains (47.9% to 85.0% on MetaWorld MT50) are measured on independent held-out robot tasks and real-world manipulation, with separate representation probes and ablations isolating the contribution of the algebraic constraints. No equation reduces a claimed prediction to a fitted input by construction, no load-bearing premise rests solely on self-citation, and no ansatz is smuggled in; the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization weights for consistency losses
axioms (1)
- domain assumption Enforcing composition and reversal consistency on latent transitions creates a locally additive transition space suitable for policy generation.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Motus: A Unified Latent Action World Model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, et al. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
π0: A vision-language-action flow model for general robot control, 2026
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. π0: A visi...
work page 2026
-
[6]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[8]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Xi Chen, Ali Ghadirzadeh, Tianhe Yu, Jianhao Wang, Alex Yuan Gao, Wenzhe Li, Liang Bin, Chelsea Finn, and Chongjie Zhang. Lapo: Latent-variable advantage-weighted policy optimization for offline reinforcement learning.Advances in Neural Information Processing Systems, 35:36902–36913, 2022
work page 2022
-
[12]
Xiaoyu Chen, Junliang Guo, Tianyu He, Chuheng Zhang, Pushi Zhang, Derek Cathera Yang, Li Zhao, and Jiang Bian. Igor: Image-goal representations are the atomic control units for foundation models in embodied ai.arXiv preprint arXiv:2411.00785, 2024
-
[13]
Villa-x: enhancing latent action modeling in vision-language-action models,
Xiaoyu Chen, Hangxing Wei, Pushi Zhang, Chuheng Zhang, Kaixin Wang, Yanjiang Guo, Rushuai Yang, Yucen Wang, Xinquan Xiao, Li Zhao, et al. Villa-x: enhancing latent action modeling in vision-language-action models.arXiv preprint arXiv:2507.23682, 2025
-
[14]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
work page 2025
-
[15]
Zichen J Cui, Hengkai Pan, Aadhithya Iyer, Siddhant Haldar, and Lerrel Pinto. Dynamo: In-domain dynamics pretraining for visuo-motor control.Advances in Neural Information Processing Systems, 37:33933–33961, 2024. 10
work page 2024
-
[16]
Gpt-3: Its nature, scope, limits, and consequences
Luciano Floridi and Massimo Chiriatti. Gpt-3: Its nature, scope, limits, and consequences. Minds and machines, 30(4):681–694, 2020
work page 2020
-
[17]
Adaworld: Learning adaptable world models with latent actions.arXiv preprint arXiv:2503.18938, 2025
Shenyuan Gao, Siyuan Zhou, Yilun Du, Jun Zhang, and Chuang Gan. Adaworld: Learning adaptable world models with latent actions.arXiv preprint arXiv:2503.18938, 2025
-
[18]
Vla-0: Building state-of-the-art vlas with zero modification.arXiv preprint arXiv:2510.13054, 2025
Ankit Goyal, Hugo Hadfield, Xuning Yang, Valts Blukis, and Fabio Ramos. Vla-0: Building state-of-the-art vlas with zero modification.arXiv preprint arXiv:2510.13054, 2025
-
[19]
Yanjiang Guo, Yucheng Hu, Jianke Zhang, Yen-Jen Wang, Xiaoyu Chen, Chaochao Lu, and Jianyu Chen. Prediction with action: Visual policy learning via joint denoising process.Ad- vances in Neural Information Processing Systems, 37:112386–112410, 2024
work page 2024
-
[20]
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations.arXiv preprint arXiv:2412.14803, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5 : a vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Joel Jang, Seonghyeon Ye, Zongyu Lin, Jiannan Xiang, Johan Bjorck, Yu Fang, Fengyuan Hu, Spencer Huang, Kaushil Kundalia, Yen-Chen Lin, et al. Dreamgen: Unlocking generalization in robot learning through video world models.arXiv preprint arXiv:2505.12705, 2025
-
[23]
Hierarchical latent action model.arXiv preprint arXiv:2603.05815, 2026
Hanjung Kim, Lerrel Pinto, and Seon Joo Kim. Hierarchical latent action model.arXiv preprint arXiv:2603.05815, 2026
-
[24]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Behavior generation with latent actions.arXiv preprint arXiv:2403.03181, 2024
Seungjae Lee, Yibin Wang, Haritheja Etukuru, H Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. Behavior generation with latent actions.arXiv preprint arXiv:2403.03181, 2024
-
[27]
Causal World Modeling for Robot Control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
arXiv preprint arXiv:2511.04555 (2025)
Tao Lin, Yilei Zhong, Yuxin Du, Jingjing Zhang, Jiting Liu, Yinxinyu Chen, Encheng Gu, Ziyan Liu, Hongyi Cai, Yanwen Zou, et al. Evo-1: Lightweight vision-language-action model with preserved semantic alignment.arXiv preprint arXiv:2511.04555, 2025
-
[30]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Haoyun Liu, Jianzhuang Zhao, Xinyuan Chang, Tianle Shi, Chuanzhang Meng, Jiayuan Tan, Feng Xiong, Tong Lin, Dongjie Huo, Mu Xu, SongLin Dong, Zhiheng Ma, Yihong Gong, and Sheng Zhong. Neural implicit action fields: From discrete waypoints to continuous functions for vision-language-action models, 2026. 11
work page 2026
-
[33]
Joint-aligned latent action: Towards scalable vla pretraining in the wild, 2026
Hao Luo, Ye Wang, Wanpeng Zhang, Haoqi Yuan, Yicheng Feng, Haiweng Xu, Sipeng Zheng, and Zongqing Lu. Joint-aligned latent action: Towards scalable vla pretraining in the wild, 2026
work page 2026
-
[34]
Zentner, Ryan Julian, J K Terry, Isaac Woungang, Nariman Farsad, and Pablo Samuel Castro
Reginald McLean, Evangelos Chatzaroulas, Luc McCutcheon, Frank Röder, Tianhe Yu, Zhan- peng He, K.R. Zentner, Ryan Julian, J K Terry, Isaac Woungang, Nariman Farsad, and Pablo Samuel Castro. Meta-world+: An improved, standardized, RL benchmark. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Bench- marks Track, 2025
work page 2025
-
[35]
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
work page 2022
-
[36]
arXiv preprint arXiv:2512.00903 (2025)
Chaojun Ni, Cheng Chen, Xiaofeng Wang, Zheng Zhu, Wenzhao Zheng, Boyuan Wang, Tianrun Chen, Guosheng Zhao, Haoyun Li, Zhehao Dong, et al. Swiftvla: Unlocking spatiotemporal dynamics for lightweight vla models at minimal overhead.arXiv preprint arXiv:2512.00903, 2025
-
[37]
Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
work page 2024
-
[38]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Masked world models for visual control
Younggyo Seo, Danijar Hafner, Hao Liu, Fangchen Liu, Stephen James, Kimin Lee, and Pieter Abbeel. Masked world models for visual control. InConference on Robot Learning, pages 1332–1344. PMLR, 2023
work page 2023
-
[40]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Jingwen Sun, Wenyao Zhang, Zekun Qi, Shaojie Ren, Zezhi Liu, Hanxin Zhu, Guangzhong Sun, Xin Jin, and Zhibo Chen. Vla-jepa: Enhancing vision-language-action model with latent world model.arXiv preprint arXiv:2602.10098, 2026
-
[42]
Vlascd: A visual language action model for simultaneous chatting and decision making
Zuojin Tang, Bin Hu, Chenyang Zhao, De Ma, Gang Pan, and Bin Liu. Vlascd: A visual language action model for simultaneous chatting and decision making. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 9223–9243, 2025
work page 2025
-
[43]
One token per frame: Reconsidering visual bandwidth in world models for vla policy, 2026
Zuojin Tang, Shengchao Yuan, Xiaoxin Bai, Zhiyuan Jin, De Ma, Gang Pan, and Bin Liu. One token per frame: Reconsidering visual bandwidth in world models for vla policy, 2026
work page 2026
-
[44]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118, 2024. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
work page 2017
-
[48]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Learning Additively Compositional Latent Actions for Embodied AI
Hangxing Wei, Xiaoyu Chen, Chuheng Zhang, Tim Pearce, Jianyu Chen, Alex Lamb, Li Zhao, and Jiang Bian. Learning additively compositional latent actions for embodied ai.arXiv preprint arXiv:2604.03340, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation
Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video generative pre-training for visual robot manipulation.arXiv preprint arXiv:2312.13139, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
World-Env: Leveraging World Model as a Virtual Environment for VLA Post-Training
Junjin Xiao, Yandan Yang, Xinyuan Chang, Ronghan Chen, Feng Xiong, Mu Xu, Wei-Shi Zheng, and Qing Zhang. World-env: Leveraging world model as a virtual environment for vla post-training.arXiv preprint arXiv:2509.24948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning
Yandan Yang, Shuang Zeng, Tong Lin, Xinyuan Chang, Dekang Qi, Junjin Xiao, Haoyun Liu, Ronghan Chen, Yuzhi Chen, Dongjie Huo, et al. Abot-m0: Vla foundation model for robotic manipulation with action manifold learning.arXiv preprint arXiv:2602.11236, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
Latent Action Pretraining from Videos
Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Sejune Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, et al. Latent action pretraining from videos.arXiv preprint arXiv:2410.11758, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
What do latent action models actually learn?arXiv preprint arXiv:2506.15691, 2025
Chuheng Zhang, Tim Pearce, Pushi Zhang, Kaixin Wang, Xiaoyu Chen, Wei Shen, Li Zhao, and Jiang Bian. What do latent action models actually learn?arXiv preprint arXiv:2506.15691, 2025
-
[57]
Jianke Zhang, Yanjiang Guo, Yucheng Hu, Xiaoyu Chen, Xiang Zhu, and Jianyu Chen. Up-vla: A unified understanding and prediction model for embodied agent.arXiv preprint arXiv:2501.18867, 2025
-
[58]
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
Renrui Zhang, Jiaming Han, Chris Liu, Peng Gao, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, and Yu Qiao. Llama-adapter: Efficient fine-tuning of language models with zero-init attention.arXiv preprint arXiv:2303.16199, 2023
work page Pith review arXiv 2023
-
[59]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreason- able effectiveness of deep features as a perceptual metric, 2018
work page 2018
-
[60]
arXiv preprint arXiv:2507.04447 (2025) 3, 7, 14
Wenyao Zhang, Hongsi Liu, Zekun Qi, Yunnan Wang, Xinqiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, Fan Lu, He Wang, et al. Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge.arXiv preprint arXiv:2507.04447, 2025
-
[61]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 13 A Implementation Details A.1 ALAM pretraining The relational encoder E maps a frame...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.