Recognition: 2 theorem links
· Lean TheoremVariational Inference for L\'evy Process-Driven SDEs via Neural Tilting
Pith reviewed 2026-05-12 03:23 UTC · model grok-4.3
The pith
Neural networks exponentially tilt the Lévy measure to create a tractable variational family that preserves jumps in SDE inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By exponentially reweighting the Lévy measure using neural networks, we construct a variational family for Lévy-driven SDEs that preserves the jump structure of the underlying process while remaining computationally tractable. A quadratic neural parametrization yields closed-form normalization of the tilted measure, a conditional Gaussian representation facilitates simulation for stable processes, and symmetry-aware Monte Carlo estimators enable scalable optimization. The approach yields reliable posterior inference in regimes where Gaussian-based variational methods fail, as shown on both synthetic and real-world datasets.
What carries the argument
Neural exponential tilting of the Lévy measure: a neural network that exponentially reweights the intensity of jumps to define the variational posterior while preserving the original jump structure.
If this is right
- The method enables accurate capture of jump dynamics in predictive models for domains with extreme events.
- Posterior inference becomes reliable for Lévy-driven SDEs where Gaussian variational approaches fail due to discontinuities.
- Optimization scales via the developed Monte Carlo estimators while maintaining the process's jump characteristics.
- Closed-form normalization from the quadratic parametrization removes the need for additional approximation steps in the evidence lower bound.
Where Pith is reading between the lines
- The tilting construction could be extended to other non-Gaussian driving noises such as Hawkes processes or marked point processes.
- In safety-critical settings the approach may yield better-calibrated uncertainty for rare but high-impact jumps.
- Testing on higher-dimensional or multivariate Lévy-driven systems would reveal whether the symmetry-aware estimators generalize without additional cost.
Load-bearing premise
The quadratic neural parametrization produces a closed-form normalization constant for the tilted measure and the symmetry-aware Monte Carlo estimators accurately approximate the posterior for scalable optimization.
What would settle it
Apply the method to synthetic Lévy-driven SDE data with known true parameters and check whether the inferred posterior recovers the correct jump intensities and sizes more accurately than Gaussian variational baselines; failure to improve would indicate the claim does not hold.
Figures

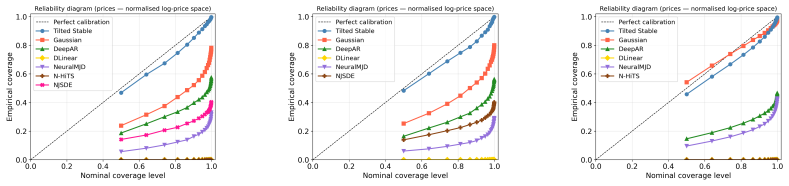

read the original abstract
Modelling extreme events and heavy-tailed phenomena is central to building reliable predictive systems in domains such as finance, climate science, and safety-critical AI. While L\'evy processes provide a natural mathematical framework for capturing jumps and heavy tails, Bayesian inference for L\'evy-driven stochastic differential equations (SDEs) remains intractable with existing methods: Monte Carlo approaches are rigorous but lack scalability, whereas neural variational inference methods are efficient but rely on Gaussian assumptions that fail to capture discontinuities. We address this tension by introducing a neural exponential tilting framework for variational inference in L\'evy-driven SDEs. Our approach constructs a flexible variational family by exponentially reweighting the L\'evy measure using neural networks. This parametrization preserves the jump structure of the underlying process while remaining computationally tractable. To enable efficient inference, we develop a quadratic neural parametrization that yields closed-form normalization of the tilted measure, a conditional Gaussian representation for stable processes that facilitates simulation, and symmetry-aware Monte Carlo estimators for scalable optimization. Empirically, we demonstrate that the method accurately captures jump dynamics and yields reliable posterior inference in regimes where Gaussian-based variational approaches fail, on both synthetic and real-world datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a neural exponential tilting framework for variational inference in Lévy-driven SDEs. It constructs a flexible variational family by exponentially reweighting the Lévy measure using neural networks, preserving the jump structure while aiming for computational tractability. Key elements include a quadratic neural parametrization claimed to yield closed-form normalization of the tilted measure, a conditional Gaussian representation for stable processes, and symmetry-aware Monte Carlo estimators for scalable optimization. The method is asserted to accurately capture jump dynamics and provide reliable posterior inference on synthetic and real-world datasets in regimes where Gaussian-based variational approaches fail.
Significance. If the technical claims hold, the work could advance scalable Bayesian inference for processes with jumps and heavy tails, relevant to finance, climate modeling, and safety-critical applications. It attempts to combine the rigor of Lévy processes with the efficiency of neural variational methods, potentially offering a useful alternative to existing Monte Carlo or Gaussian-restricted approaches. No mention is made of machine-checked proofs, reproducible code, or parameter-free derivations.
major comments (2)
- Abstract: The claims of empirical success ('accurately captures jump dynamics and yields reliable posterior inference' where Gaussian methods fail) are stated without any metrics, baseline comparisons, dataset descriptions, or quantitative results, making it impossible to assess whether the central empirical contribution is supported.
- Abstract: The quadratic neural parametrization is asserted to deliver 'closed-form normalization of the tilted measure' and to enable 'symmetry-aware Monte Carlo estimators,' but no equations, assumptions on the Lévy measure, or derivation steps are supplied, preventing verification of these load-bearing technical properties.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below, providing clarifications and indicating revisions where appropriate.
read point-by-point responses
-
Referee: Abstract: The claims of empirical success ('accurately captures jump dynamics and yields reliable posterior inference' where Gaussian methods fail) are stated without any metrics, baseline comparisons, dataset descriptions, or quantitative results, making it impossible to assess whether the central empirical contribution is supported.
Authors: We agree that the abstract presents a high-level summary of the empirical results without quantitative details. The main text contains the full experimental evaluation, including specific metrics, baseline comparisons against Gaussian variational methods, and descriptions of the synthetic and real-world datasets. To address this, we will revise the abstract to include key quantitative highlights supporting the claims of improved performance on jump dynamics. revision: yes
-
Referee: Abstract: The quadratic neural parametrization is asserted to deliver 'closed-form normalization of the tilted measure' and to enable 'symmetry-aware Monte Carlo estimators,' but no equations, assumptions on the Lévy measure, or derivation steps are supplied, preventing verification of these load-bearing technical properties.
Authors: The abstract is designed to be concise and does not include equations or derivations, which is standard practice. The quadratic neural parametrization, the closed-form normalization result under the stated assumptions on the Lévy measure, and the symmetry-aware Monte Carlo estimators are fully derived and presented in the main body of the manuscript (Sections 3 and 4). We will consider adding a brief clarifying phrase in the abstract to better signpost these technical elements. revision: partial
Circularity Check
No significant circularity identified from abstract
full rationale
Only the abstract is available, which describes a new neural exponential tilting framework constructed via neural reweighting of the Lévy measure, quadratic parametrization for closed-form normalization, and symmetry-aware Monte Carlo estimators. No equations, derivation steps, fitted parameters renamed as predictions, or self-citations are present that could reduce any claim to its inputs by construction. The approach is presented as addressing gaps in existing Gaussian-based methods through first-principles parametrizations, making the derivation self-contained on the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights for tilting
axioms (1)
- domain assumption Lévy processes provide a framework for modeling jumps and heavy tails in SDEs
invented entities (1)
-
neural-tilted Lévy measure
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
quadratic neural parametrization that yields closed-form normalization of the tilted measure... Ht(x, y) = exp(At(2xy + y²) + Bty)
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
neural exponential tilting framework... tilted Lévy measure ˜ν(dy, t, Xt) = e^{ϕt(Xt+y)−ϕt(Xt)} ντ(dy)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cambridge university press, 2009
David Applebaum.Lévy processes and stochastic calculus. Cambridge university press, 2009
work page 2009
-
[2]
yfinance: Download market data from Yahoo! Finance’s API, 2019
Ran Aroussi. yfinance: Download market data from Yahoo! Finance’s API, 2019
work page 2019
-
[3]
Søren Asmussen and Jan Rosi´nski. Approximations of small jumps of Lévy processes with a view towards simulation.Journal of Applied Probability, 38(2):482–493, 2001
work page 2001
-
[4]
David Berghaus, Kostadin Cvejoski, Patrick Seifner, César Ojeda, and Ramsés J. Sánchez. Foundation inference models for Markov jump processes. InAdvances in Neural Information Processing Systems, volume 37, 2024
work page 2024
-
[5]
J. Bertoin.Lévy Processes. Cambridge Tracts in Mathematics. Cambridge University Press, 1996
work page 1996
-
[6]
JAX: composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Yash Katariya, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman- Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018
work page 2018
-
[7]
Lévy-driven CARMA processes.Annals of the Institute of Statistical Mathematics, 53(1):113–124, 2001
Peter J Brockwell. Lévy-driven CARMA processes.Annals of the Institute of Statistical Mathematics, 53(1):113–124, 2001
work page 2001
-
[8]
Cristian Challu, Kin G. Olivares, Boris N. Oreshkin, Federico Garza, Max Mergenthaler- Canseco, and Artur Dubrawski. N-HiTS: Neural hierarchical interpolation for time series forecasting. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, 2023
work page 2023
-
[9]
Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018
work page 2018
-
[10]
R Cont and P Tankov.Financial Modelling with Jump Processes. Chapman & Hall/CRC, 2003
work page 2003
-
[11]
Variational inference for sdes driven by fractional noise
Rembert Daems, Manfred Opper, Guillaume Crevecoeur, and Tolga Birdal. Variational inference for sdes driven by fractional noise. InThe Twelfth International Conference on Learning Representations (ICLR 2024), 2024
work page 2024
-
[12]
Efficient Training of Neural SDEs Using Stochastic Optimal Control
Rembert Daems, Manfred Opper, Guillaume Crevecoeur, and Tolga Birdal. Efficient Training of Neural SDEs Using Stochastic Optimal Control. InEuropean Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN), 2025
work page 2025
-
[13]
Min Dai, Jinqiao Duan, Jianyu Hu, and Xiangjun Wang. Variational inference of the drift func- tion for stochastic differential equations driven by Lévy processes.Chaos: An Interdisciplinary Journal of Nonlinear Science, 32(6):061103, 2022
work page 2022
-
[14]
The DeepMind JAX Ecosystem, 2020
DeepMind, Igor Babuschkin, Kate Baumli, Alison Bell, Surya Bhupatiraju, Jake Bruce, Peter Buchlovsky, David Budden, Trevor Cai, Aidan Clark, Ivo Danihelka, Antoine Dedieu, Claudio Fantacci, Jonathan Godwin, Chris Jones, Ross Hemsley, Tom Hennigan, Matteo Hessel, Shaobo Hou, Steven Kapturowski, Thomas Keck, Iurii Kemaev, Michael King, Markus Kunesch, Lena ...
work page 2020
-
[15]
Steffen Dereich and Felix Heidenreich. A multilevel Monte Carlo algorithm for Lévy-driven stochastic differential equations.Stochastic Processes and their Applications, 121(7):1565– 1587, 2011
work page 2011
-
[16]
Entropic matching for expectation propagation of Markov jump processes
Yannick Eich, Bastian Alt, and Heinz Koeppl. Entropic matching for expectation propagation of Markov jump processes. InProceedings of the 28th International Conference on Artificial Intelligence and Statistics (AISTATS), 2025
work page 2025
-
[17]
Simulation and approximation of Lévy-driven stochastic differential equations
Nicolas Fournier. Simulation and approximation of Lévy-driven stochastic differential equations. ESAIM: Probability and Statistics, 15:233–248, 2011
work page 2011
-
[18]
Neural Non-Stationary Merton Jump Diffusion for Time Series Prediction
Yuanpei Gao, Qi Yan, Yan Leng, and Renjie Liao. Neural Non-Stationary Merton Jump Diffusion for Time Series Prediction. InAdvances in Neural Information Processing Systems, volume 38, 2025
work page 2025
-
[19]
Boris Vladimirovich Gnedenko and Andrey Nikolaevich Kolmogorov.Limit distributions for sums of independent random variables, volume 2420. Addison-wesley, 1968
work page 1968
-
[20]
Simon Godsill, Ioannis Kontoyiannis, and Marcos Tapia Costa. Generalised shot-noise repre- sentations of stochastic systems driven by non-Gaussian Lévy processes.Advances in Applied Probability, 56(4):1215–1250, 2024
work page 2024
-
[21]
Simon Godsill, Marina Riabiz, and Ioannis Kontoyiannis. The Lévy State Space Model. In 2019 53rd Asilomar Conference on Signals, Systems, and Computers, pages 487–494, 2019
work page 2019
-
[22]
Exact gradients for stochastic spiking neural networks driven by rough signals
Christian Holberg and Cristopher Salvi. Exact gradients for stochastic spiking neural networks driven by rough signals. InAdvances in Neural Information Processing Systems, volume 37, 2024
work page 2024
-
[23]
Springer Science & Business Media, 2013
Jean Jacod and Albert Shiryaev.Limit theorems for stochastic processes, volume 288. Springer Science & Business Media, 2013
work page 2013
-
[24]
Ajay Jasra, Kody JH Law, and Prince Peprah Osei. Multilevel particle filters for Lévy-driven stochastic differential equations.Statistics and Computing, 29(4):775–789, 2019
work page 2019
-
[25]
Junteng Jia and Austin R Benson. Neural jump stochastic differential equations.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[26]
Kallenberg.Foundations of Modern Probability
O. Kallenberg.Foundations of Modern Probability. Springer-Verlag, 2nd edition, 2002
work page 2002
-
[27]
Cambridge University Press, 1999
Sato Ken-Iti.Lévy Processes and Infinitely Divisible Distributions, volume 68. Cambridge University Press, 1999
work page 1999
-
[28]
Patrick Kidger, James Morrill, James Foster, and Terry Lyons. Neural controlled differential equations for irregular time series.Advances in neural information processing systems, 33:6696– 6707, 2020
work page 2020
-
[29]
Yaman Kındap and Simon Godsill. Generalised hyperbolic state-space models for inference in dynamic systems.IEEE Open Journal of Signal Processing, 5:132–139, 2023
work page 2023
-
[30]
David Kleinhans and Rudolf Friedrich. Continuous-time random walks: Simulation of con- tinuous trajectories.Physical Review E—Statistical, Nonlinear, and Soft Matter Physics, 76(6):061102, 2007
work page 2007
-
[31]
Arturo Kohatsu-Higa and Peter Tankov. Jump-adapted discretization schemes for Lévy-driven SDEs.Stochastic Processes and their Applications, 120(11):2258–2285, 2010
work page 2010
-
[32]
Tatjana Lemke, Marina Riabiz, and Simon J Godsill. Fully bayesian inference for α-stable distributions using a poisson series representation.Digital Signal Processing, 47:96–115, 2015
work page 2015
-
[33]
Xuechen Li, Ting-Kam Leonard Wong, Ricky T. Q. Chen, and David Duvenaud. Scalable gra- dients for stochastic differential equations. InProceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS), 2020. 11
work page 2020
-
[34]
Yang Li and Jinqiao Duan. Extracting stochastic dynamical systems with α-stable Lévy noise from data.Journal of Statistical Mechanics: Theory and Experiment, 2022(2):023405, 2022
work page 2022
-
[35]
Yubin Lu and Jinqiao Duan. Discovering transition phenomena from data of stochastic dy- namical systems with Lévy noise.Chaos: An Interdisciplinary Journal of Nonlinear Science, 30(9):093110, 2020
work page 2020
-
[36]
Scoring rules for continuous probability distributions
James E Matheson and Robert L Winkler. Scoring rules for continuous probability distributions. Management science, 22(10):1087–1096, 1976
work page 1976
-
[37]
Gabriel Nobis, Maximilian Springenberg, Marco Aversa, Michael Detzel, Rembert Daems, Roderick Murray-Smith, Shinichi Nakajima, Sebastian Lapuschkin, Stefano Ermon, Tolga Birdal, et al. Generative fractional diffusion models.Advances in neural information processing systems, 37:25469–25509, 2024
work page 2024
-
[38]
Fractional diffusion bridge models
Gabriel Nobis, Maximilian Springenberg, Arina Belova, Rembert Daems, Christoph Knochen- hauer, Manfred Opper, Tolga Birdal, and Wojciech Samek. Fractional diffusion bridge models. InAdvances in neural information processing systems, 2025
work page 2025
-
[39]
Variational inference for stochastic differential equations.Annalen der Physik, 531(3):1800233, 2019
Manfred Opper. Variational inference for stochastic differential equations.Annalen der Physik, 531(3):1800233, 2019
work page 2019
-
[40]
Approximate inference in continu- ous time Gaussian-jump processes
Manfred Opper, Andreas Ruttor, and Guido Sanguinetti. Approximate inference in continu- ous time Gaussian-jump processes. InAdvances in Neural Information Processing Systems, volume 23, 2010
work page 2010
-
[41]
On the exact andε-strong simulation of (jump) diffusions.Bernoulli, 22(2):794–856, 2016
Murray Pollock, Adam M Johansen, and Gareth O Roberts. On the exact andε-strong simulation of (jump) diffusions.Bernoulli, 22(2):794–856, 2016
work page 2016
-
[42]
Philip Protter and Denis Talay. The Euler scheme for Lévy driven stochastic differential equations.The Annals of Probability, 25(1):393–423, 1997
work page 1997
-
[43]
Autoregressive denoising diffusion models for multivariate probabilistic time series forecasting
Kashif Rasul, Calvin Seward, Ingmar Schuster, and Roland V ollgraf. Autoregressive denoising diffusion models for multivariate probabilistic time series forecasting. InProceedings of the 38th International Conference on Machine Learning (ICML), 2021
work page 2021
-
[44]
Multivariate probabilistic time series forecasting via conditioned normalizing flows
Kashif Rasul, Abdul-Saboor Sheikh, Ingmar Schuster, Urs Bergmann, and Roland V ollgraf. Multivariate probabilistic time series forecasting via conditioned normalizing flows. InThe Ninth International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[45]
Cambridge university press, 2000
L Chris G Rogers and David Williams.Diffusions, Markov processes, and martingales, volume 2. Cambridge university press, 2000
work page 2000
-
[46]
Series representations of Lévy processes from the perspective of point processes
Jan Rosi´nski. Series representations of Lévy processes from the perspective of point processes. InLévy processes: theory and applications, pages 401–415. Birkhäuser Boston Boston, MA, 2001
work page 2001
-
[47]
Tempering stable processes.Stochastic processes and their applications, 117(6):677–707, 2007
Jan Rosi ´nski. Tempering stable processes.Stochastic processes and their applications, 117(6):677–707, 2007
work page 2007
-
[48]
Stephen McGough, and Dennis Prangle
Thomas Ryder, Andrew Golightly, A. Stephen McGough, and Dennis Prangle. Black-box varia- tional inference for stochastic differential equations. InProceedings of the 35th International Conference on Machine Learning (ICML), 2018
work page 2018
-
[49]
David Salinas, Valentin Flunkert, Jan Gasthaus, and Tim Januschowski. DeepAR: Probabilistic forecasting with autoregressive recurrent networks.International Journal of Forecasting, 36(3):1181–1191, 2020
work page 2020
-
[50]
Patrick Seifner and Ramsés J. Sánchez. Neural Markov jump processes. InProceedings of the 40th International Conference on Machine Learning (ICML), 2023
work page 2023
-
[51]
Denoising Lévy probabilistic models
Dario Shariatian, Umut Simsekli, and Alain Oliviero Durmus. Denoising Lévy probabilistic models. InThe Thirteenth International Conference on Learning Representations, 2025. 12
work page 2025
-
[52]
Alaa, and Mihaela van der Schaar
Kamil˙e Stankeviˇci¯ut˙e, Ahmed M. Alaa, and Mihaela van der Schaar. Conformal time-series forecasting. InAdvances in Neural Information Processing Systems, volume 34, 2021
work page 2021
-
[53]
CSDI: Conditional score-based diffusion models for probabilistic time series imputation
Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. CSDI: Conditional score-based diffusion models for probabilistic time series imputation. InAdvances in Neural Information Processing Systems, volume 34, 2021
work page 2021
-
[54]
Learning fractional white noises in neural stochastic differential equations
Anh Tong, Thanh Nguyen-Tang, Toan Tran, and Jaesik Choi. Learning fractional white noises in neural stochastic differential equations. InAdvances in Neural Information Processing Systems, volume 35, 2022
work page 2022
-
[55]
Belinda Tzen and Maxim Raginsky. Neural stochastic differential equations: Deep latent Gaussian models in the diffusion limit.arXiv preprint arXiv:1905.09883, 2019
-
[56]
Conformal prediction interval for dynamic time-series
Chen Xu and Yao Xie. Conformal prediction interval for dynamic time-series. InProceedings of the 38th International Conference on Machine Learning (ICML), 2021
work page 2021
-
[57]
Eun Bi Yoon, Keehun Park, Sungwoong Kim, and Sungbin Lim. Score-based generative models with Lévy processes.Advances in Neural Information Processing Systems, 36:40694–40707, 2023
work page 2023
-
[58]
Diffusion-TS: Interpretable diffusion for general time series generation
Xinyu Yuan and Yan Qiao. Diffusion-TS: Interpretable diffusion for general time series generation. InThe Twelfth International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[59]
Adaptive conformal predictions for time series
Margaux Zaffran, Olivier Féron, Yannig Goude, Julie Josse, and Aymeric Dieuleveut. Adaptive conformal predictions for time series. InProceedings of the 39th International Conference on Machine Learning (ICML), 2022
work page 2022
-
[60]
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting? InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, 2023
work page 2023
-
[61]
Neural jump-diffusion temporal point processes
Shuai Zhang, Chuan Zhou, Yang Liu, Peng Zhang, Xixun Lin, and Zhi-Ming Ma. Neural jump-diffusion temporal point processes. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024. 13 Appendix A Variational derivation of the optimal Markov posterior Both Theorem 4.1 and its Corollary derive from a single key object: theoptimal l...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.