Recognition: no theorem link
MambaNetBurst: Direct Byte-level Network Traffic Classification without Tokenization or Pretraining
Pith reviewed 2026-05-13 00:50 UTC · model grok-4.3
The pith
A compact Mamba-2 model classifies network traffic directly from raw packet bytes without tokenization or pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
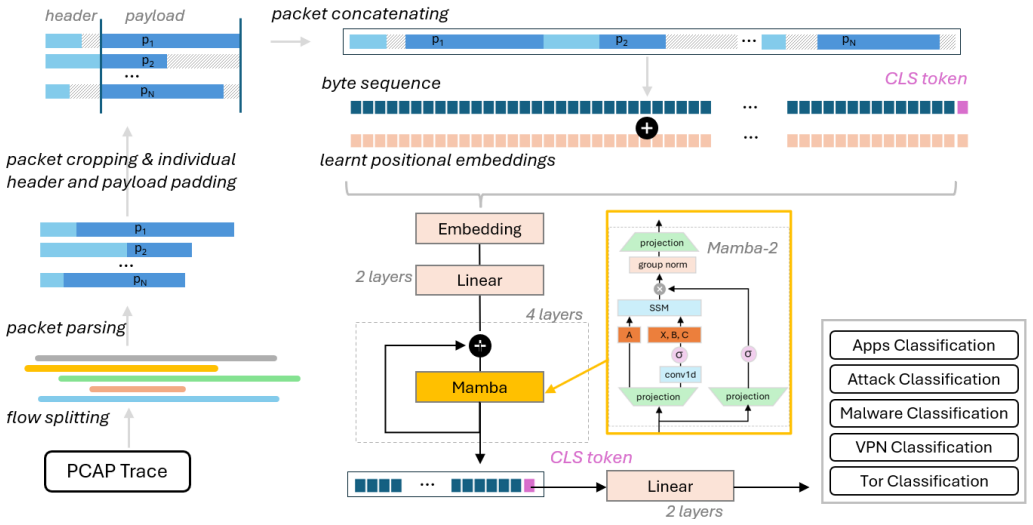
MambaNetBurst takes the first few packets of a flow, concatenates their bytes into a fixed-length sequence, appends a learnable CLS token, and passes the result through residual pre-normalized Mamba-2 blocks to produce class predictions, achieving competitive accuracy on six public benchmarks without any pre-training step.
What carries the argument
Mamba-2 selective state space model blocks that process the raw byte sequence with a constrained transition structure while preserving full temporal resolution.
If this is right
- Preserving full byte-level resolution improves performance compared with early striding or downsampling.
- Mamba-2 delivers faster training than optimized linear attention while remaining effective for byte sequences.
- Moderate state sizes in the model are sufficient to generalize across diverse traffic classification benchmarks.
- The method works without multimodal feature engineering or self-supervised pre-training stages.
Where Pith is reading between the lines
- The same direct-byte approach could be tested on streaming traffic where bursts arrive incrementally rather than as fixed prefixes.
- Removing pre-training may allow smaller teams to experiment with custom traffic classifiers on limited hardware.
- Performance on very long flows or tasks that depend on protocol state across many packets remains an open question for the method.
Load-bearing premise
A fixed-length burst taken from the first few packets of each flow contains enough information to classify the flow correctly on all six tasks.
What would settle it
A clear accuracy drop when the same model is tested on flows that require information from packets beyond the initial burst or on tasks that need features from later parts of the connection.
Figures

read the original abstract
We present MambaNetBurst, a compact tokenizer-free byte-level sequence classifier for network burst classification based on a Mamba-2 backbone. In contrast to most recent strong traffic-classification and intrusion-detection approaches, our method operates directly on raw packet bytes, avoids tokenization, patching, and heavy engineered multimodal representations, and does not require any self-supervised pre-training stage. Given a packet flow, we form a fixed-length burst from the first few packets, embed the resulting byte sequence appending a learnable CLS token, and process it with a stack of residual pre-normalized Mamba-2 blocks for end-to-end supervised classification. Across six public benchmarks spanning encrypted mobile app identification, VPN/Tor traffic classification, malware traffic classification, and IoT attack traffic, MambaNetBurst achieves consistently strong results and is competitive with, or outperforms, substantially heavier and often pre-trained baselines. Our ablation study shows that preserving byte-level temporal resolution is critical, that early downsampling through striding is consistently harmful, and that moderate state sizes are sufficient for robust generalization. We further show that Mamba-2, despite its more constrained transition structure relative to Mamba-1, remains highly effective for packet-byte modeling while providing clear efficiency advantages, particularly in training speed. Overall, our results demonstrate that direct **undiluted** byte-to-classification learning with compact selective state space models is a practical, effective and novel direction for efficient, deployable traffic analysis that bypasses the complexity of pre-training pipelines even over highly optimized linear attention architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MambaNetBurst, a tokenizer-free byte-level sequence classifier built on a compact Mamba-2 backbone. Given a flow, it constructs a fixed-length burst from the first few packets, embeds the raw byte sequence with a learnable CLS token, and performs end-to-end supervised classification via residual pre-normalized Mamba-2 blocks. It reports competitive or superior results on six public benchmarks (encrypted mobile app identification, VPN/Tor classification, malware traffic, IoT attacks) without any self-supervised pre-training, and includes ablations showing that byte-level resolution is critical while moderate state sizes suffice.
Significance. If the empirical results hold and the initial-burst assumption is validated, the work offers a practical, efficient alternative to pre-trained transformer or multimodal pipelines for deployable traffic analysis. The demonstration that Mamba-2 remains effective despite its constrained transitions, together with the training-speed advantages and the clear ablation on striding versus byte resolution, constitutes a useful contribution to efficient sequence modeling in security applications.
major comments (2)
- [§3.1] §3.1 (Burst construction): The central claim that a fixed-length burst from the first few packets supplies sufficient discriminative information for all six tasks is load-bearing, yet no sensitivity analysis on burst length, packet count, or comparison against full-flow or timing-augmented inputs is provided. If later packets carry critical signals on any benchmark (e.g., malware or IoT attack detection), the 'practical and effective' assertion for deployable analysis is weakened.
- [§4.2, Table 1] §4.2, Table 1 (Main results): Performance is reported as single-point accuracies or F1 scores without error bars, multiple random seeds, or statistical significance tests against the baselines. This makes it impossible to assess whether the claimed competitiveness is robust or could be explained by run-to-run variance.
minor comments (2)
- [Abstract / §1] The abstract and §1 could more explicitly list the exact six benchmarks and their public sources to aid reproducibility.
- [§3.2] Notation for the CLS token embedding and the precise byte-sequence length after padding should be clarified in §3.2 for readers implementing the model.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the empirical claims.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Burst construction): The central claim that a fixed-length burst from the first few packets supplies sufficient discriminative information for all six tasks is load-bearing, yet no sensitivity analysis on burst length, packet count, or comparison against full-flow or timing-augmented inputs is provided. If later packets carry critical signals on any benchmark (e.g., malware or IoT attack detection), the 'practical and effective' assertion for deployable analysis is weakened.
Authors: We agree that a sensitivity analysis on burst length and packet count would strengthen the central claim. In the revised version we will add experiments that vary the number of initial packets (e.g., 1–5) and the resulting byte length while keeping the same model and training protocol, reporting accuracy/F1 on all six benchmarks. We will also include a direct comparison against full-flow inputs on the same splits where memory permits, explicitly noting that our design targets early, low-latency classification. Regarding timing-augmented inputs, our scope is strictly byte-level without hand-crafted features; we will add a short discussion of this design choice and its relation to prior multimodal baselines. The existing ablation on striding versus byte resolution already shows that temporal fidelity matters, but the new experiments will directly test whether later packets add critical signal. revision: yes
-
Referee: [§4.2, Table 1] §4.2, Table 1 (Main results): Performance is reported as single-point accuracies or F1 scores without error bars, multiple random seeds, or statistical significance tests against the baselines. This makes it impossible to assess whether the claimed competitiveness is robust or could be explained by run-to-run variance.
Authors: We acknowledge that single-run point estimates limit the ability to judge robustness. We will rerun all main experiments with at least five independent random seeds, report mean and standard deviation in the revised Table 1, and add error bars to the corresponding figures. We will also include statistical significance tests (paired t-test or Wilcoxon signed-rank test with Bonferroni correction) against the strongest baselines to quantify whether observed differences are significant. These changes will be reflected in both the experimental section and the table caption. revision: yes
Circularity Check
No circularity detected in empirical model evaluation
full rationale
The paper is an empirical ML study: it defines a Mamba-2 architecture, forms fixed-length byte bursts from the first packets of flows, trains the model end-to-end on six public benchmarks, and reports accuracy/F1 against external baselines. No mathematical derivation chain, first-principles prediction, or fitted parameter is presented that reduces to its own inputs by construction. The central claim (practical byte-level classification without tokenization or pre-training) rests on direct experimental results rather than any self-referential equation or self-citation load-bearing step. Minor citations to the original Mamba work are external and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pert: Payload encoding representation from transformer for encrypted traffic classification,
H. Y . He, Z. G. Yang, and X. N. Chen, “Pert: Payload encoding representation from transformer for encrypted traffic classification,” in2020 ITU Kaleidoscope: Industry-Driven Digital Transformation (ITU K). IEEE, 2020, pp. 1–8
work page 2020
-
[3]
R. Zhao, M. Zhan, X. Deng, Y . Wang, Y . Wang, G. Gui, and Z. Xue, “Yet another traffic classifier: A masked autoencoder based traffic transformer with multi-level flow representation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 4, 2023, pp. 5420–5427
work page 2023
-
[4]
Z. Hang, Y . Lu, Y . Wang, and Y . Xie, “Flow-mae: Leveraging masked autoencoder for accurate, efficient and robust malicious traffic classification,” inProceedings of the 26th International Symposium on Research in Attacks, Intrusions and Defenses, 2023, pp. 297–314
work page 2023
-
[5]
Netgpt: Generative pretrained transformer for network traffic,
X. Meng, C. Lin, Y . Wang, and Y . Zhang, “Netgpt: Generative pretrained transformer for network traffic,” arXiv preprint arXiv:2304.09513, 2023
-
[6]
Lens: A foundation model for network traffic in cybersecurity,
Q. Wang, C. Qian, X. Li, Z. Yao, and H. Shao, “Lens: A foundation model for network traffic in cybersecurity,” arXiv e-prints, arXiv:2402, 2024
work page 2024
-
[7]
Netmamba: Efficient network traffic classification via pre- training unidirectional mamba,
T. Wang, X. Xie, W. Wang, C. Wang, Y . Zhao, and Y . Cui, “Netmamba: Efficient network traffic classification via pre- training unidirectional mamba,” in2024 IEEE 32nd International Conference on Network Protocols (ICNP). IEEE, 2024, pp. 1–11
work page 2024
-
[8]
——, “Netmamba+: A framework of pre-trained models for efficient and accurate network traffic classification,” 2026. [Online]. Available: https://arxiv.org/abs/2601.21792
-
[9]
X. Lin, G. Xiong, G. Gou, Z. Li, J. Shi, and J. Yu, “Et-bert: A contextualized datagram representation with pre-training transformers for encrypted traffic classification,” inProceedings of the ACM Web Conference 2022, 2022, pp. 633–642
work page 2022
-
[10]
R. Zhao, M. Zhan, X. Deng, Y . Wang, Y . Wang, G. Gui, and Z. Xue, “Yet another traffic classifier: A masked autoencoder based traffic transformer with multi-level flow representation,” inProceedings of the AAAI Conference on Artificial Intelligence (AAAI), vol. 37, no. 4, 2023, pp. 5420–5427. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/artic...
work page 2023
-
[11]
Trafficformer: an efficient pre-trained model for traffic data,
G. Zhou, X. Guo, Z. Liu, T. Li, Q. Li, and K. Xu, “Trafficformer: an efficient pre-trained model for traffic data,” in2025 IEEE Symposium on Security and Privacy (SP). IEEE, 2025, pp. 1844–1860
work page 2025
-
[12]
Transformers are rnns: Fast autoregressive transformers with linear attention,
A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret, “Transformers are rnns: Fast autoregressive transformers with linear attention,” inInternational conference on machine learning. PMLR, 2020, pp. 5156–5165
work page 2020
-
[13]
Byte latent transformer: Patches scale better than tokens,
A. Pagnoni, R. Pasunuru, P. Rodriguez, J. Nguyen, B. Muller, M. Li, C. Zhou, L. Yu, J. E. Weston, L. Zettlemoyeret al., “Byte latent transformer: Patches scale better than tokens,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 9238–9258
work page 2025
-
[14]
Byt5: Towards a token-free future with pre-trained byte-to-byte models,
L. Xue, A. Barua, N. Constant, R. Al-Rfou, S. Narang, M. Kale, A. Roberts, and C. Raffel, “Byt5: Towards a token-free future with pre-trained byte-to-byte models,”Transactions of the Association for Computational Linguistics, vol. 10, pp. 291–306, 2022
work page 2022
-
[15]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
T. Dao and A. Gu, “Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality,” 2024. [Online]. Available: https://arxiv.org/abs/2405.21060
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Mambabyte: Token-free selective state space model,
J. Wang, T. Gangavarapu, J. N. Yan, and A. M. Rush, “Mambabyte: Token-free selective state space model,”arXiv preprint arXiv:2401.13660, 2024, published at COLM 2024
-
[18]
Xg-bot: An explainable deep graph neural network for botnet detection and forensics,
W. W. Lo, G. Kulatilleke, M. Sarhan, S. Layeghy, and M. Portmann, “Xg-bot: An explainable deep graph neural network for botnet detection and forensics,”Internet of Things, vol. 22, p. 100747, 2023
work page 2023
-
[19]
Doc-nad: a hybrid deep one-class classifier for network anomaly detection,
M. Sarhan, G. Kulatilleke, W. W. Lo, S. Layeghy, and M. Portmann, “Doc-nad: a hybrid deep one-class classifier for network anomaly detection,” in2023 IEEE/ACM 23rd International Symposium on Cluster, Cloud and Internet Computing Workshops (CCGridW). IEEE, 2023, pp. 1–7
work page 2023
-
[21]
Towards the development of a realistic multidimensional iot profiling dataset,
S. Dadkhah, H. Mahdikhani, P. K. Danso, A. Zohourian, K. A. Truong, and A. A. Ghorbani, “Towards the development of a realistic multidimensional iot profiling dataset,” in2022 19th Annual International Conference on Privacy, Security & Trust (PST), 2022, pp. 1–11
work page 2022
-
[22]
Multimodal llms for zero-shot intrusion detection using netflow visualisations,
M. Luay, S. Layeghy, Y . Pandey, G. Kulatilleke, and M. Portmann, “Multimodal llms for zero-shot intrusion detection using netflow visualisations,” in2025 IEEE 50th Conference on Local Computer Networks (LCN). IEEE, 2025, pp. 1–7
work page 2025
-
[23]
Flowtransformer: A transformer framework for flow-based network intrusion detection systems,
L. D. Manocchio, S. Layeghy, W. W. Lo, G. K. Kulatilleke, M. Sarhan, and M. Portmann, “Flowtransformer: A transformer framework for flow-based network intrusion detection systems,”Expert Systems with Applications, vol. 241, p. 122564, 2024
work page 2024
-
[24]
Ptu: Pre-trained model for network traffic understanding,
L. Peng, X. Xie, S. Huang, Z. Wang, and Y . Cui, “Ptu: Pre-trained model for network traffic understanding,” in32nd IEEE International Conference on Network Protocols, ICNP 2024, Charleroi, Belgium, October 28-31, 2024. IEEE, 2024, pp. 1–12. [Online]. Available: https://doi.org/10.1109/ICNP61940.2024.10858503
-
[25]
End-to-end encrypted traffic classification with one-dimensional convolution neural networks,
W. Wang, M. Zhu, J. Wang, X. Zeng, and Z. Yang, “End-to-end encrypted traffic classification with one-dimensional convolution neural networks,” in2017 IEEE International Conference on Intelligence and Security Informatics, ISI 2017, Beijing, China, July 22-24, 2017. IEEE, 2017, pp. 43–48. [Online]. Available: https://doi.org/10.1109/ISI.2017.8004872
-
[26]
H. Zhang, L. Yu, X. Xiao, Q. Li, F. Mercaldo, X. Luo, and Q. Liu, “Tfe-gnn: A temporal fusion encoder using graph neural networks for fine-grained encrypted traffic classification,” inProceedings of the ACM Web Conference 2023, ser. WWW ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 2066–2075. [Online]. Available: https://doi.org/1...
-
[27]
Ebsnn: Extended byte segment neural network for network traffic classification,
X. Xiao, W. Xiao, R. Li, X. Luo, H. Zheng, and S. Xia, “Ebsnn: Extended byte segment neural network for network traffic classification,”IEEE Transactions on Dependable and Secure Computing, vol. 19, no. 5, pp. 3521–3538, 2022
work page 2022
-
[28]
Packet representation learning for traffic classification,
X. Meng, Y . Wang, R. Ma, H. Luo, X. Li, and Y . Zhang, “Packet representation learning for traffic classification,” in Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2022, pp. 3546–3554
work page 2022
-
[29]
Quantifying the privacy implications of high-fidelity synthetic network traffic,
V . Tran, S. Liu, T. Li, and N. Feamster, “Quantifying the privacy implications of high-fidelity synthetic network traffic,” arXiv preprint arXiv:2511.20497, 2025
-
[30]
Flow-based encrypted network traffic classification with graph neural networks,
T.-L. Huoh, Y . Luo, P. Li, and T. Zhang, “Flow-based encrypted network traffic classification with graph neural networks,” IEEE Transactions on Network and Service Management, vol. 20, no. 2, pp. 1224–1237, 2022
work page 2022
-
[31]
Et-mamba: A mamba model for encrypted traffic classification,
J. Xu, L. Chen, W. Xu, L. Dai, C. Wang, and L. Hu, “Et-mamba: A mamba model for encrypted traffic classification,” Information, vol. 16, no. 4, p. 314, 2025
work page 2025
-
[32]
S. B. Atitallah, M. Driss, and W. Boulila, “Ids–graphmamba: A markov-enhanced graph mamba framework for real-time intrusion detection in iomt edge networks,”Computer Networks, p. 111933, 2025
work page 2025
-
[33]
Scgc: Self-supervised contrastive graph clustering,
G. K. Kulatilleke, M. Portmann, and S. S. Chandra, “Scgc: Self-supervised contrastive graph clustering,”arXiv preprint arXiv:2204.12656, 2022
-
[34]
Efficient block contrastive learning via parameter-free meta-node approximation,
——, “Efficient block contrastive learning via parameter-free meta-node approximation,”Neurocomputing, vol. 561, p. 126850, 2023
work page 2023
-
[35]
Time matters: Temporal netflow features for ml-based network intrusion detection,
M. Luay, S. Layeghy, N. Noorbin, M. Sarhan, G. Kulatilleke, N. Moustafa, and M. Portmann, “Time matters: Temporal netflow features for ml-based network intrusion detection,”IEEE Access, 2026
work page 2026
-
[36]
Sok: Decoding the enigma of encrypted network traffic classifiers,
N. Wickramasinghe, A. Shaghaghi, G. Tsudik, and S. Jha, “Sok: Decoding the enigma of encrypted network traffic classifiers,” in2025 IEEE Symposium on Security and Privacy (SP). IEEE, 2025, pp. 1825–1843
work page 2025
-
[37]
Characterization of encrypted and vpn traffic using time-related features,
G. Draper-Gil, A. Habibi Lashkari, M. S. I. Mamun, and A. A. Ghorbani, “Characterization of encrypted and vpn traffic using time-related features,” inProceedings of the 2nd International Conference on Information Systems Security and Privacy (ICISSP), 2016, pp. 407–414
work page 2016
-
[38]
Characterization of tor traffic using time based features,
A. H. Lashkari, G. D. Gil, M. S. I. Mamun, and A. A. Ghorbani, “Characterization of tor traffic using time based features,” inProceedings of the 3rd International Conference on Information Systems Security and Privacy - Volume 1: ICISSP, INSTICC. SciTePress, 2017, pp. 253–262
work page 2017
-
[39]
Malware traffic classification using convolutional neural network for representation learning,
W. Wang, M. Zhu, X. Zeng, X. Ye, and Y . Sheng, “Malware traffic classification using convolutional neural network for representation learning,” in2017 International conference on information networking (ICOIN). IEEE, 2017, pp. 712–717
work page 2017
-
[40]
Robust smartphone app identification via encrypted network traffic analysis,
V . F. Taylor, R. Spolaor, M. Conti, and I. Martinovic, “Robust smartphone app identification via encrypted network traffic analysis,”IEEE Transactions on Information Forensics and Security, vol. 13, no. 1, pp. 63–78, 2017
work page 2017
-
[41]
Flowprint: Semi-supervised mobile-app fingerprinting on encrypted network traffic,
T. Van Ede, R. Bortolameotti, A. Continella, J. Ren, D. J. Dubois, M. Lindorfer, D. Choffnes, M. Van Steen, and A. Peter, “Flowprint: Semi-supervised mobile-app fingerprinting on encrypted network traffic,” inNetwork and Distributed System Security Symposium (NDSS), vol. 27, 2020
work page 2020
-
[42]
Fs-net: A flow sequence network for encrypted traffic classification,
C. Liu, L. He, G. Xiong, Z. Cao, and Z. Li, “Fs-net: A flow sequence network for encrypted traffic classification,” in IEEE INFOCOM 2019 - IEEE Conference on Computer Communications. IEEE, 2019, pp. 1171–1179
work page 2019
-
[43]
H. Zhang, L. Yu, X. Xiao, Q. Li, F. Mercaldo, X. Luo, and Q. Liu, “Tfe-gnn: A temporal fusion encoder using graph neural networks for fine-grained encrypted traffic classification,” inProceedings of the ACM Web Conference 2023, 2023, pp. 2066–2075
work page 2023
-
[44]
A. Vaswani, “Attention is all you need,” arXiv preprint arXiv:1706.03762, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
An international view of privacy risks for mobile apps,
J. Ren, D. Dubois, and D. Choffnes, “An international view of privacy risks for mobile apps,” 2019
work page 2019
-
[46]
Towards the development of a realistic multidimensional iot profiling dataset,
S. Dadkhah, H. Mahdikhani, P. K. Danso, A. Zohourian, K. A. Truong, and A. A. Ghorbani, “Towards the development of a realistic multidimensional iot profiling dataset,” in2022 19th Annual International Conference on Privacy, Security & Trust (PST). IEEE, 2022, pp. 1–11
work page 2022
-
[47]
Characterization of tor traffic using time based features,
A. H. Lashkari, G. D. Gil, M. S. I. Mamun, and A. A. Ghorbani, “Characterization of tor traffic using time based features,” inInternational conference on information systems security and privacy, vol. 2. SciTePress, 2017, pp. 253–262
work page 2017
-
[48]
Characterization of encrypted and vpn traffic using time- related features,
G. D. Gil, A. H. Lashkari, M. Mamun, and A. A. Ghorbani, “Characterization of encrypted and vpn traffic using time- related features,” inProceedings of the 2nd international conference on information systems security and privacy (ICISSP 2016). SciTePress, 2016, pp. 407–414. APPENDIX TABLE VI: Scaling Comparison: Mamba-1 vs Mamba-2 at Larger Batch Sizes.d ...
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.