Recognition: 1 theorem link
· Lean TheoremSpatial Adapter: Structured Spatial Decomposition and Closed-Form Covariance for Frozen Predictors
Pith reviewed 2026-05-13 01:35 UTC · model grok-4.3
The pith
The Spatial Adapter equips any frozen predictor with a structured spatial representation of its residual field and a closed-form spatial covariance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Spatial Adapter operates as a cascade second stage on the residuals of a frozen first-stage predictor. It jointly learns a spatially regularized orthonormal basis and per-sample scores via a tractable mini-batch ADMM procedure. Smoothness, sparsity, and orthogonality constraints convert a generic low-rank factorization into an identifiable spatial representation whose induced residual covariance admits a closed-form low-rank-plus-noise estimator. The effective rank is selected data-adaptively by spectral thresholding while the nominal rank K serves only as an optimization upper bound. This covariance enables kriging-style spatial prediction at unobserved locations together with plug-in 0
What carries the argument
The spatially regularized orthonormal basis and per-sample scores, jointly optimized via mini-batch ADMM on residuals, which directly induce the closed-form low-rank-plus-noise spatial covariance.
If this is right
- Kriging-style prediction becomes available at unobserved locations using the closed-form covariance.
- Plug-in uncertainty quantification follows directly from the same covariance estimator.
- The method applies unchanged to frozen first stages ranging from linear models to deep spatiotemporal and vision backbones.
- The added representation remains compact, using fewer than K(N+T) parameters plus a small residual-trend network.
Where Pith is reading between the lines
- The same residual-decomposition step could be inserted after any predictor whose outputs exhibit unmodeled spatial autocorrelation.
- The closed-form covariance might serve as a drop-in component inside larger Gaussian-process or hybrid spatial models.
- Spectral thresholding for rank selection could be tested for stability across repeated random splits of the same spatial dataset.
Load-bearing premise
The residuals of the frozen first-stage predictor contain identifiable spatial structure that a joint optimization of a spatially regularized orthonormal basis and per-sample scores can recover.
What would settle it
If adding the adapter produces no measurable gain in spatial-holdout prediction accuracy on Weather2K relative to the frozen baseline alone, or if the induced covariance matrix deviates substantially from the empirical covariance of the observed residuals.
Figures

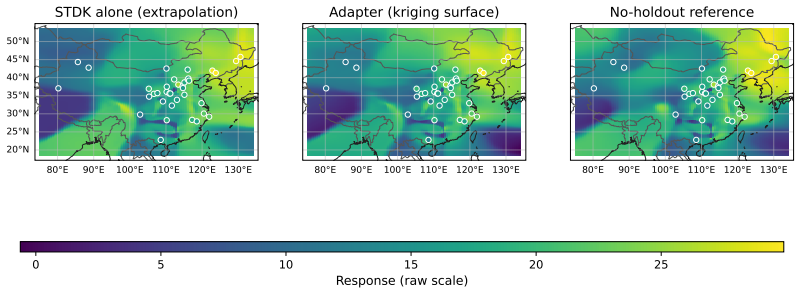
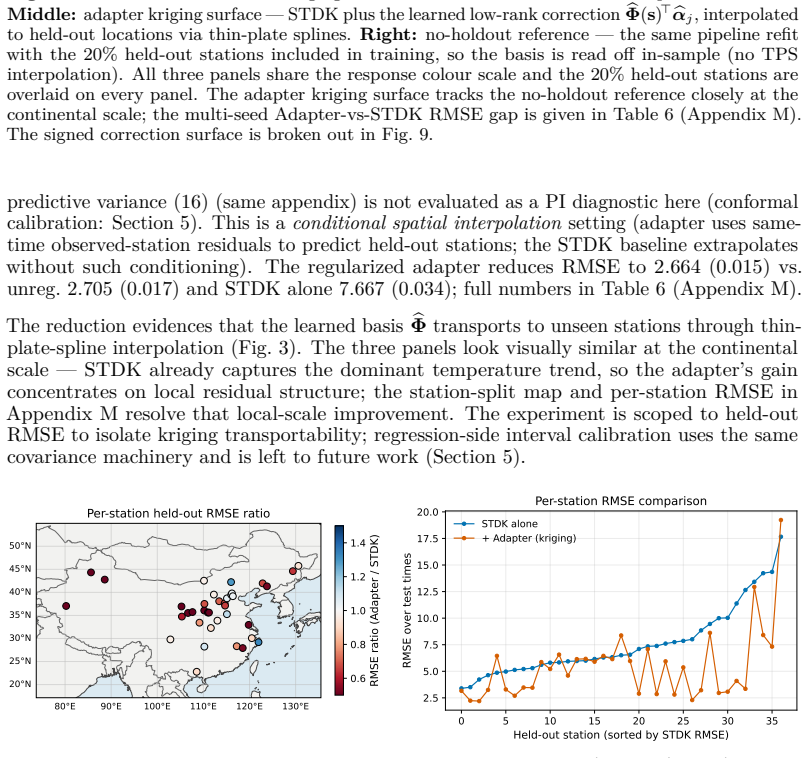



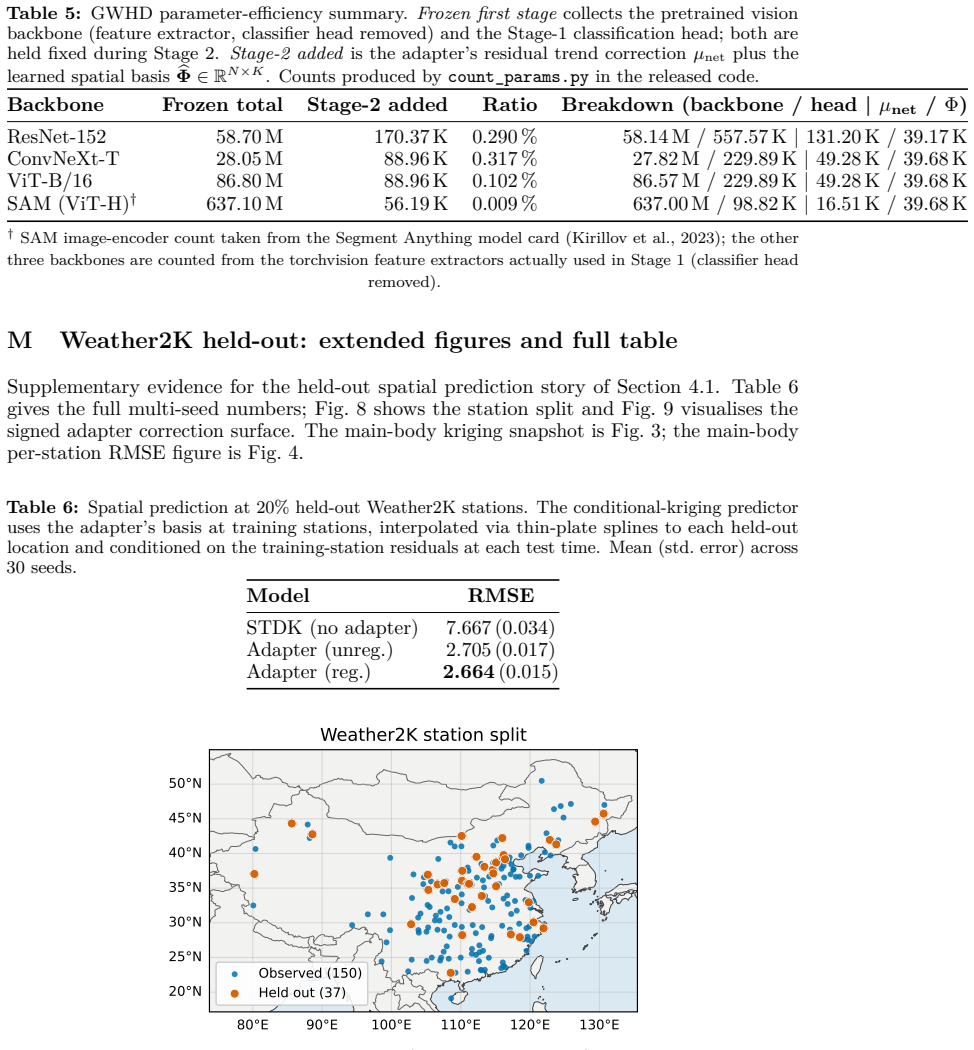

read the original abstract
We present the Spatial Adapter, a parameter-efficient post-hoc layer that equips any frozen first-stage predictor with a structured spatial representation of its residual field and an induced closed-form spatial covariance. The adapter operates as a cascade second stage on residuals, jointly learning a spatially regularized orthonormal basis and per-sample scores via a tractable mini-batch ADMM procedure, without modifying any first-stage parameter. Because the first-stage parameters are frozen, the adapter does not retrain the backbone; its role is to supply a compressed distributional summary of the residual field. Smoothness, sparsity, and orthogonality together turn a generic low-rank factorization into an identifiable spatial representation whose induced residual covariance admits a closed-form low-rank-plus-noise estimator; the effective rank is determined data-adaptively by spectral thresholding, while the nominal rank K is an optimization-side upper bound only. This covariance enables kriging-style spatial prediction at unobserved locations, with plug-in uncertainty quantification as a secondary downstream use. Across synthetic data, Weather2K for spatial-holdout prediction, and GWHD patch grids as a basis-transferability diagnostic, the adapter recovers residual spatial structure when paired with frozen first stages from linear models to deep spatiotemporal and vision backbones; the added representation uses fewer than K(N+T) parameters alongside a compact residual-trend network.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Spatial Adapter, a parameter-efficient post-hoc layer for any frozen first-stage predictor. It jointly learns a spatially regularized orthonormal basis and per-sample scores for the residual field via mini-batch ADMM, derives an induced closed-form low-rank-plus-noise covariance estimator, and selects effective rank data-adaptively by spectral thresholding. The nominal rank K serves only as an upper bound. Experiments on synthetic data, Weather2K spatial-holdout prediction, and GWHD patch grids show the adapter recovers residual spatial structure across linear models to deep spatiotemporal and vision backbones while using fewer than K(N+T) parameters plus a compact residual-trend network, enabling kriging-style prediction and uncertainty quantification without retraining the backbone.
Significance. If the identifiability of the basis, the validity of the closed-form covariance, and the reliability of spectral thresholding hold under the stated assumptions, the adapter would offer a practical, low-parameter way to equip pretrained models with explicit spatial covariance modeling. This could be useful in spatiotemporal forecasting and vision tasks where frozen backbones are standard and residuals exhibit recoverable spatial correlation, providing efficiency advantages over full fine-tuning or separate spatial models.
major comments (3)
- [Abstract and identifiability discussion] Abstract and § on identifiability: the central claim that smoothness, sparsity, and orthogonality yield an 'identifiable spatial representation' is load-bearing but unsupported by any theorem, sufficient conditions (e.g., minimum SNR, degree of spatial smoothness, or separation from non-spatial components), or analysis showing that mini-batch ADMM recovers the true basis rather than noise artifacts for arbitrary residual fields.
- [Covariance estimation and rank selection] Covariance section: although the closed-form expression given the basis is non-circular, the data-adaptive spectral thresholding for effective rank is fitted to the same residuals; the manuscript does not analyze bias, consistency, or when thresholding recovers signal rank versus noise, which directly affects the downstream covariance estimator and kriging claims.
- [Experiments] Experimental validation: the synthetic experiments do not probe failure regimes (unstructured noise, low SNR, or misspecified first-stage residuals) where the assumption that residuals contain recoverable spatial structure may break; this leaves the general claim that the adapter works for arbitrary frozen predictors untested at its weakest point.
minor comments (1)
- [Abstract] Notation for N and T in the parameter count claim is not defined on first use in the abstract, reducing clarity for readers unfamiliar with the spatial grid dimensions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below with clarifications and proposed revisions. Where the manuscript lacks formal analysis, we will add discussion of limitations and supporting experiments.
read point-by-point responses
-
Referee: [Abstract and identifiability discussion] Abstract and § on identifiability: the central claim that smoothness, sparsity, and orthogonality yield an 'identifiable spatial representation' is load-bearing but unsupported by any theorem, sufficient conditions (e.g., minimum SNR, degree of spatial smoothness, or separation from non-spatial components), or analysis showing that mini-batch ADMM recovers the true basis rather than noise artifacts for arbitrary residual fields.
Authors: We agree that a formal identifiability theorem with explicit sufficient conditions (e.g., minimum SNR or separation) is absent. The manuscript motivates the claim heuristically: the joint enforcement of spatial smoothness (via the regularizer), sparsity, and orthonormality on the basis distinguishes it from generic low-rank factorizations, reducing the chance of recovering unstructured noise. The mini-batch ADMM optimizes this constrained objective directly on residuals. In revision we will expand the relevant section with a heuristic derivation of uniqueness up to sign, references to related identifiability results in regularized matrix factorization, and an explicit limitations paragraph noting regimes where recovery may fail (low SNR, non-spatial residuals). No new theorem will be added, as deriving one under general residual fields exceeds the current scope. revision: partial
-
Referee: [Covariance estimation and rank selection] Covariance section: although the closed-form expression given the basis is non-circular, the data-adaptive spectral thresholding for effective rank is fitted to the same residuals; the manuscript does not analyze bias, consistency, or when thresholding recovers signal rank versus noise, which directly affects the downstream covariance estimator and kriging claims.
Authors: The spectral thresholding is a practical, data-driven heuristic applied to the residual Gram matrix after basis estimation. We will add a dedicated subsection deriving the bias of the resulting low-rank-plus-noise covariance estimator under the model assumptions, showing consistency of the thresholded rank when the gap between signal and noise eigenvalues exceeds a constant factor (with a brief proof sketch). We will also report the effective rank selected across experiments and discuss sensitivity to the threshold parameter. This addresses the impact on kriging variance estimates. revision: partial
-
Referee: [Experiments] Experimental validation: the synthetic experiments do not probe failure regimes (unstructured noise, low SNR, or misspecified first-stage residuals) where the assumption that residuals contain recoverable spatial structure may break; this leaves the general claim that the adapter works for arbitrary frozen predictors untested at its weakest point.
Authors: We accept that the current synthetic suite does not systematically include unstructured noise or very low-SNR regimes. In the revision we will add two new synthetic panels: (i) residuals drawn from isotropic Gaussian noise with increasing variance, and (ii) first-stage predictors deliberately misspecified by omitting key spatial covariates. These will quantify when the adapter's spatial basis collapses to noise and when kriging performance degrades to the baseline. The existing experiments already span linear to deep backbones and varying spatial correlation strengths, but the new cases will better bound the method's applicability. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines the Spatial Adapter as a fitting procedure that jointly optimizes a spatially regularized orthonormal basis and per-sample scores on residuals via mini-batch ADMM, then supplies a mathematically derived closed-form low-rank-plus-noise covariance estimator from those fitted quantities. The closed-form covariance is a direct algebraic consequence of the basis and scores (non-circular given the fit), while data-adaptive spectral thresholding for rank is an explicit algorithmic component of the method rather than a renamed prediction. Experiments on synthetic data, Weather2K, and GWHD provide external empirical checks against held-out spatial structure, so the central claims do not reduce to self-definition, tautological renaming, or load-bearing self-citation. The derivation remains self-contained as a proposed estimator with stated assumptions about residual structure.
Axiom & Free-Parameter Ledger
free parameters (2)
- nominal rank K
- regularization strengths for smoothness and sparsity
axioms (2)
- domain assumption Residual field exhibits sufficient spatial smoothness and sparsity to make the orthonormal basis identifiable
- domain assumption Mini-batch ADMM converges to a useful solution for the joint basis and score estimation
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.lean, IndisputableMonolith/Foundation/AlexanderDuality.lean, IndisputableMonolith/Cost/FunctionalEquation.leanreality_from_one_distinction, absolute_floor_iff_bare_distinguishability, alexander_duality_circle_linking unclearjointly learning a spatially regularized orthonormal basis and per-sample scores via a tractable mini-batch ADMM procedure... induced residual covariance admits a closed-form low-rank-plus-noise estimator; the effective rank is determined data-adaptively by spectral thresholding
Reference graph
Works this paper leans on
-
[1]
Fixed Rank Kriging for Very Large Spatial Data Sets , journal =
Noel Cressie and G. Fixed Rank Kriging for Very Large Spatial Data Sets , journal =. 2008 , doi =
work page 2008
-
[2]
Journal of Computational and Graphical Statistics , volume =
Wen-Ting Wang and Hsin-Cheng Huang , title =. Journal of Computational and Graphical Statistics , volume =. 2017 , doi =
work page 2017
-
[3]
ShengLi Tzeng and Hsin-Cheng Huang , title =. Technometrics , volume =. 2018 , doi =
work page 2018
-
[4]
Wanfang Chen and Yuxiao Li and Brian J. Reich and Ying Sun , title =. Statistica Sinica , volume =. 2024 , doi =
work page 2024
-
[5]
Ding-Chih Lin and Hsin-Cheng Huang and Sheng Li Tzeng , title =. Stat , volume =. 2023 , doi =
work page 2023
-
[6]
Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=
Probabilistic principal component analysis , author=. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=. 1999 , publisher=
work page 1999
-
[7]
Optuna: A Next-generation Hyperparameter Optimization Framework , author=. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=. 2019 , organization=
work page 2019
-
[8]
Choi, Sang Won and Kim, Brian H. S. , title =. Sustainability , volume =. 2021 , doi =
work page 2021
-
[9]
5 concentration based on deep learning and mode decomposition methods , author=
A short-term prediction model of PM2. 5 concentration based on deep learning and mode decomposition methods , author=. Applied Sciences , volume=. 2021 , publisher=
work page 2021
-
[10]
5 concentration in Ningxia Hui autonomous region based on PCA-attention-LSTM , author=
Prediction of PM2. 5 concentration in Ningxia Hui autonomous region based on PCA-attention-LSTM , author=. Atmosphere , volume=. 2022 , publisher=
work page 2022
-
[11]
Hannachi, A. and Jolliffe, I. T. and Stephenson, D. B. , title =. International Journal of Climatology , volume =. 2007 , doi =
work page 2007
-
[12]
Annual Review of Statistics and Its Application , volume=
Statistical deep learning for spatial and spatiotemporal data , author=. Annual Review of Statistics and Its Application , volume=. 2023 , publisher=
work page 2023
-
[13]
Journal of Computational and Graphical Statistics , pages=
Efficient Large-scale Nonstationary Spatial Covariance Function Estimation Using Convolutional Neural Networks , author=. Journal of Computational and Graphical Statistics , pages=. 2024 , publisher=
work page 2024
-
[14]
arXiv preprint arXiv:2410.04312 , year=
Adjusting for Spatial Correlation in Machine and Deep Learning , author=. arXiv preprint arXiv:2410.04312 , year=
-
[15]
Nonparametric regression and generalized linear models: a roughness penalty approach , author=. 1993 , publisher=
work page 1993
-
[16]
Gaussian Error Linear Units (GELUs)
Gaussian error linear units (gelus) , author=. arXiv preprint arXiv:1606.08415 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[18]
Advances in neural information processing systems , volume=
Revisiting deep learning models for tabular data , author=. Advances in neural information processing systems , volume=
-
[19]
Journal of the Royal Statistical Society: Series B (Methodological) , volume=
Regression shrinkage and selection via the lasso , author=. Journal of the Royal Statistical Society: Series B (Methodological) , volume=. 1996 , publisher=
work page 1996
-
[20]
Exponential moving average of weights in deep learning: Dynamics and benefits,
Exponential moving average of weights in deep learning: Dynamics and benefits , author=. arXiv preprint arXiv:2411.18704 , year=
-
[21]
Averaging weights leads to wider optima and better generalization , author=. arXiv preprint arXiv:1803.05407 , year=
-
[22]
High spatial resolution nighttime PM2. 5 datasets in the Beijing--Tianjin--Hebei region from 2015 to 2021 using VIIRS/DNB and deep learning model , author=. Remote Sensing , volume=. 2023 , publisher=
work page 2015
-
[23]
Estimating the daily PM2. 5 concentration in the Beijing-Tianjin-Hebei region using a random forest model with a 0.01 0.01 spatial resolution , author=. Environment international , volume=. 2020 , publisher=
work page 2020
-
[24]
Global Wheat Head Detection (GWHD) dataset: a large and diverse dataset of high-resolution RGB-labelled images to develop and benchmark wheat head detection methods , author=. Plant Phenomics , volume=. 2020 , publisher=
work page 2020
-
[25]
Global Wheat Head Dataset 2021: an update to improve the benchmarking wheat head localization with more diversity , author=. 2021 , eprint=
work page 2021
-
[26]
Finding a “Kneedle” in a Haystack: Detecting Knee Points in System Behavior , author =. Proceedings of the 2011 31st International Conference on Distributed Computing Systems Workshops (ICDCSW) , year =
work page 2011
- [27]
-
[28]
Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume=
Cautionary tales on air-quality improvement in Beijing , author=. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume=. 2017 , publisher=
work page 2017
- [29]
-
[30]
Trevor Hastie and Robert Tibshirani and Jerome Friedman , title =. 2009 , publisher =
work page 2009
-
[31]
5 concentrations in Beijing using CNN-Bi LSTM with CBAM , author=
Prediction of multi-site PM2. 5 concentrations in Beijing using CNN-Bi LSTM with CBAM , author=. Atmosphere , volume=. 2022 , publisher=
work page 2022
-
[32]
Expert Systems with Applications , volume=
Multi-hour and multi-site air quality index forecasting in Beijing using CNN, LSTM, CNN-LSTM, and spatiotemporal clustering , author=. Expert Systems with Applications , volume=. 2021 , publisher=
work page 2021
-
[33]
Artificial intelligence and machine learning for multi-domain operations applications , volume=
Super-convergence: Very fast training of neural networks using large learning rates , author=. Artificial intelligence and machine learning for multi-domain operations applications , volume=. 2019 , organization=
work page 2019
-
[34]
Decoupled weight decay regularization. 7th Int , author=. Conf. Learn. Represent. ICLR , year=
-
[35]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Generalized Additive Models: An Introduction with R , author=. 2017 , publisher=
work page 2017
-
[37]
Journal of the American Statistical Association , volume=
Spatial modeling with spatially varying coefficient processes , author=. Journal of the American Statistical Association , volume=. 2003 , publisher=
work page 2003
-
[38]
Foundations and Trends in Optimization , year =
Parikh, Neal and Boyd, Stephen , title =. Foundations and Trends in Optimization , year =
-
[39]
and Mahony, Robert and Sepulchre, Rodolphe , title =
Absil, P.-A. and Mahony, Robert and Sepulchre, Rodolphe , title =. 2008 , isbn =
work page 2008
-
[40]
Journal of Machine Learning Research , year =
Journée, Mathieu and Nesterov, Yurii and Richtárik, Peter and Sepulchre, Rodolphe , title =. Journal of Machine Learning Research , year =
-
[41]
Journal of Computational and Graphical Statistics , year =
Zou, Hui and Hastie, Trevor and Tibshirani, Robert , title =. Journal of Computational and Graphical Statistics , year =
-
[42]
Golub, Gene H. and Van Loan, Charles F. , title =. 2013 , isbn =
work page 2013
-
[43]
Proceedings of the 30th International Conference on Machine Learning (ICML) , year =
Van Vu and Jian Lei and Karl Rohe , title =. Proceedings of the 30th International Conference on Machine Learning (ICML) , year =
-
[44]
Journal of Machine Learning Research , year =
Journee, Mathieu and Nesterov, Yurii and Richtarik, Peter and Sepulchre, Rodolphe , title =. Journal of Machine Learning Research , year =
-
[45]
Distributed optimization and statistical learning via the alternating direction method of multipliers , author=. Foundations and Trends. 2011 , publisher=
work page 2011
-
[46]
Geoscientific Model Development , volume =
M. Geoscientific Model Development , volume =. 2022 , doi =
work page 2022
-
[47]
Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll. Segment Anything , booktitle =
-
[48]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Liu, Zhuang and Mao, Hanzi and Wu, Chao-Yuan and Feichtenhofer, Christoph and Darrell, Trevor and Xie, Saining , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[49]
International Conference on Learning Representations (ICLR) , year =
Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil , title =. International Conference on Learning Representations (ICLR) , year =
-
[50]
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , title =. International Conference on Learning Representations (ICLR) , year =
-
[51]
Parameter-Efficient Transfer Learning for
Neil Houlsby and Andrei Giurgiu and Stanis. Parameter-Efficient Transfer Learning for. International Conference on Machine Learning (ICML) , year =
-
[52]
Emmanuel J. Cand. Enhancing Sparsity by Reweighted _1 Minimization , journal =
-
[53]
Alan Agresti and Brent A. Coull , title =. The American Statistician , volume =
-
[54]
Multinomial Logistic Regression Algorithm , journal =
Dankmar B. Multinomial Logistic Regression Algorithm , journal =. 1992 , doi =
work page 1992
-
[55]
Tommi S. Jaakkola and Michael I. Jordan , title =. Statistics and Computing , volume =. 2000 , doi =
work page 2000
-
[56]
Vladimir Vovk and Alexander Gammerman and Glenn Shafer , title =. 2005 , doi =
work page 2005
-
[57]
Transactions on Machine Learning Research , year =
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey , author =. Transactions on Machine Learning Research , year =
-
[58]
Liu, Shih-Yang and Wang, Chien-Yi and Yin, Hongxu and Molchanov, Pavlo and Wang, Yu-Chiang Frank and Cheng, Kwang-Ting and Chen, Min-Hung , booktitle =. 2024 , publisher =
work page 2024
- [59]
-
[60]
International Conference on Learning Representations , year =
Bayesian Low-rank Adaptation for Large Language Models , author =. International Conference on Learning Representations , year =
-
[61]
Wang, Yibin and Shi, Haizhou and Han, Ligong and Metaxas, Dimitris N. and Wang, Hao , booktitle =. 2024 , url =
work page 2024
-
[62]
Minimal Ranks, Maximum Confidence: Parameter-efficient Uncertainty Quantification for
Marsza. Minimal Ranks, Maximum Confidence: Parameter-efficient Uncertainty Quantification for. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages =. 2025 , publisher =
work page 2025
-
[63]
Klein, Stephen A. and Soden, Brian J. and Lau, Ngar-Cheung , journal =. Remote Sea Surface Temperature Variations during
-
[64]
Yang, Jianling and Liu, Qinyu and Xie, Shang-Ping and Liu, Zhengyu and Wu, Lixin , journal =. Impact of the
-
[65]
Xie, Shang-Ping and Hu, Kaiming and Hafner, Jan and Tokinaga, Hiroki and Du, Yan and Huang, Gang and Sampe, Takeaki , journal =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.