Recognition: 2 theorem links
· Lean TheoremTaming Extreme Tokens: Covariance-Aware GRPO with Gaussian-Kernel Advantage Reweighting
Pith reviewed 2026-05-13 01:59 UTC · model grok-4.3
The pith
Covariance-aware GRPO down-weights extreme token updates with a Gaussian kernel to stabilize entropy and improve reasoning benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
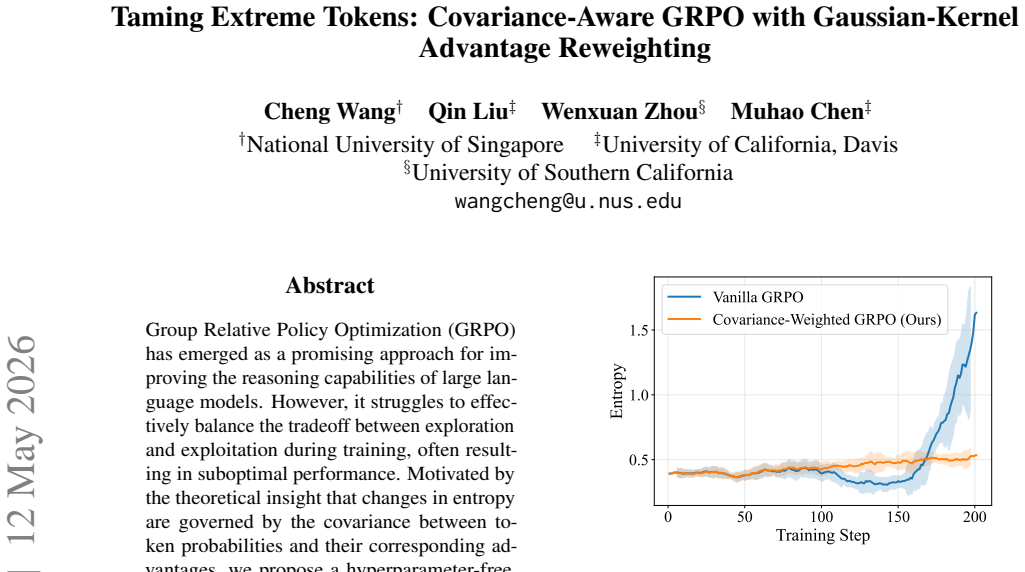
The authors argue that entropy changes in GRPO are governed by the covariance between token probabilities and their corresponding advantages, and that a covariance-weighted Gaussian kernel applied to advantage reweighting creates a stable optimization method that tames extreme token-level updates, preserves informative learning signals, improves performance on reasoning benchmarks, and keeps entropy stable as training proceeds.
What carries the argument
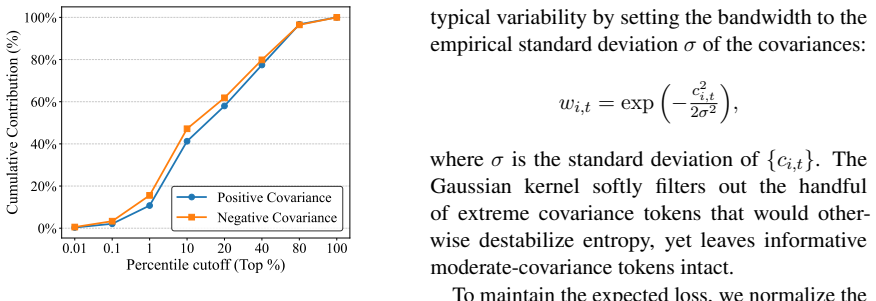
Covariance-weighted Gaussian-kernel advantage reweighting, which dynamically scales token updates according to their covariance with advantages to suppress extremes.
If this is right
- Downstream performance on reasoning benchmarks improves relative to standard GRPO.
- Entropy remains stable rather than fluctuating as training progresses.
- The exploration-exploitation tradeoff is managed automatically without manual hyperparameter search.
- Informative learning signals from tokens are retained while extreme updates are suppressed.
Where Pith is reading between the lines
- The same covariance-driven reweighting idea might extend to other policy-gradient or RL methods used for language model alignment.
- If entropy stabilization holds, fewer auxiliary regularizers may be needed to prevent collapse or divergence in long training runs.
- Applying the method across model scales and task families beyond the reported benchmarks could test whether the gains are architecture- or domain-specific.
Load-bearing premise
Entropy changes during training are governed by the covariance between token probabilities and advantages in a way that permits a stable, hyperparameter-free reweighting.
What would settle it
Running the proposed method and baseline GRPO on the same reasoning benchmarks and finding neither performance gains nor entropy stabilization.
Figures


read the original abstract
Group Relative Policy Optimization (GRPO) has emerged as a promising approach for improving the reasoning capabilities of large language models. However, it struggles to effectively balance the tradeoff between exploration and exploitation during training, often resulting in suboptimal performance. Motivated by the theoretical insight that changes in entropy are governed by the covariance between token probabilities and their corresponding advantages, we propose a hyperparameter-free, covariance-weighted optimization method that dynamically down-weights extreme token-level updates via a Gaussian kernel. This approach automatically reduces the instability caused by exploration-exploitation trade-off while preserving informative learning signals. Extensive empirical evaluations show that our approach improves downstream performance across reasoning benchmarks compared with GRPO, and effectively stablizes entropy as training progresses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a covariance-aware variant of Group Relative Policy Optimization (GRPO) that applies Gaussian-kernel reweighting to token-level advantages. The method is motivated by the asserted insight that entropy changes during training are governed by the covariance between token probabilities and advantages; this is used to dynamically down-weight extreme updates in a claimed hyperparameter-free manner. Empirical evaluations are said to demonstrate improved performance on reasoning benchmarks relative to GRPO together with stabilized entropy trajectories.
Significance. If the covariance-entropy relationship can be rigorously derived and shown to imply the specific Gaussian-kernel form without hidden parameters, the approach would supply a principled, tuning-free mechanism for controlling exploration-exploitation balance in token-level RL for LLMs, potentially yielding more stable training dynamics and stronger reasoning performance.
major comments (2)
- [Abstract and §2] Abstract and §2 (theoretical motivation): the claim that 'changes in entropy are governed by the covariance between token probabilities and their corresponding advantages' is presented without derivation, lemma, or even a sketch of the relationship. Absent this step, it is impossible to verify whether the Gaussian-kernel reweighting implements the stated mechanism or merely functions as an ad-hoc stabilizer.
- [Abstract and §3] Abstract and §3 (method): the assertion that the reweighting scheme is 'hyperparameter-free' cannot be assessed without the explicit definition of the Gaussian kernel (including any bandwidth or covariance-estimation procedure) and confirmation that no implicit constants remain. If the kernel width depends on data statistics in a non-trivial way, the hyperparameter-free claim is contradicted.
minor comments (1)
- [Abstract] Abstract: 'stablizes' is a typo and should read 'stabilizes'.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our theoretical motivation and methodological details. We address each point below and will revise the manuscript accordingly to strengthen the exposition.
read point-by-point responses
-
Referee: [Abstract and §2] Abstract and §2 (theoretical motivation): the claim that 'changes in entropy are governed by the covariance between token probabilities and their corresponding advantages' is presented without derivation, lemma, or even a sketch of the relationship. Absent this step, it is impossible to verify whether the Gaussian-kernel reweighting implements the stated mechanism or merely functions as an ad-hoc stabilizer.
Authors: We agree that the current manuscript lacks an explicit derivation of the covariance-entropy relationship. In the revised version, we will insert a new lemma in Section 2 that starts from the definition of Shannon entropy for the token distribution and the GRPO advantage estimator, then derives the first-order change in entropy as proportional to the covariance between log-probabilities and advantages. This lemma will directly motivate the form of the Gaussian-kernel reweighting as a covariance-aware stabilizer. revision: yes
-
Referee: [Abstract and §3] Abstract and §3 (method): the assertion that the reweighting scheme is 'hyperparameter-free' cannot be assessed without the explicit definition of the Gaussian kernel (including any bandwidth or covariance-estimation procedure) and confirmation that no implicit constants remain. If the kernel width depends on data statistics in a non-trivial way, the hyperparameter-free claim is contradicted.
Authors: The Gaussian kernel is defined with bandwidth equal to the empirical standard deviation of the group-wise advantages, which is computed on-the-fly from the current batch without any user-specified constants or tunable values. The covariance term is likewise estimated directly from the token probabilities and advantages in the same batch. We will add the complete mathematical definition, including the exact kernel formula and estimation procedure, to Section 3 together with pseudocode to confirm the absence of hidden hyperparameters. revision: yes
Circularity Check
No significant circularity; derivation is empirical and self-contained.
full rationale
The paper asserts a theoretical motivation regarding covariance governing entropy changes and proposes a Gaussian-kernel reweighting presented as hyperparameter-free, followed by empirical evaluations on reasoning benchmarks. No equations, lemmas, or self-citations are exhibited that reduce the central method or its performance claims to a fitted parameter, self-defined quantity, or prior author result by construction. The empirical results stand as independent validation against external benchmarks, satisfying the default expectation of non-circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Changes in entropy during GRPO training are governed by the covariance between token probabilities and advantages.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
changes in entropy are governed by the covariance between token log-probabilities and advantages: ΔH ≈ −η·Cov(log πθ(ot|q,o<t), Âi)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
wi,t = exp(−c²i,t / 2σ²) … hyperparameter-free
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. 2025a. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617. Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, We...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: In- centivizing reasoning capability in llms via reinforce- ment learning.arXiv preprint arXiv:2501.12948. Zhezheng Hao, Hong Wang, Haoyang Liu, Jian Luo, Jiarui Yu, Hande Dong, Qiang Lin, Can Wang, and Jiawei Chen
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Rethinking Entropy Interventions in RLVR: An Entropy Change Perspective
Rethinking entropy interven- tions in rlvr: An entropy change perspective.arXiv preprint arXiv:2510.10150. Andre He, Daniel Fried, and Sean Welleck
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Re- warding the unlikely: Lifting grpo beyond distribu- tion sharpening.arXiv preprint arXiv:2506.02355. Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yu- jie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun
-
[5]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical prob- lem solving with the math dataset.arXiv preprint arXiv:2103.03874. Sham M Kakade
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
s1: Simple test-time scaling.arXiv preprint arXiv:2501.19393. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Proximal Policy Optimization Algorithms
Proxi- mal policy optimization algorithms.arXiv preprint arXiv:1707.06347. Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Rewarding progress: Scaling automated process veri- fiers for llm reasoning. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. 2024a. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300. Zhihong Shao, Peiyi Wang, Qihao Zhu...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Reinforcement learning for reasoning in large language models with one training example, 2025
Scaling llm test-time compute optimally can be more effective than scaling model parameters. Chen Wang, Lai Wei, Yanzhi Zhang, Chenyang Shao, Zedong Dan, Weiran Huang, Yuzhi Zhang, and Yue Wang. 2025a. Eframe: Deeper reasoning via exploration-filter-replay reinforcement learning framework. Yiping Wang, Qing Yang, Zhiyuan Zeng, Liliang Ren, Liyuan Liu, Bao...
-
[10]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Qwen2.5-math tech- nical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122. Jian Zhao, Runze Liu, Kaiyan Zhang, Zhimu Zhou, Junqi Gao, Dong Li, Jiafei Lyu, Zhouyi Qian, Biqing Qi, Xiu Li, and Bowen Zhou
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Genprm: Scal- ing test-time compute of process reward models via generative reasoning. A Datasets Information We use Open-RS dataset as the training set, which is curated by Dang and Ngo (2025), totaling 7,000 samples: 3,000 from the Open-s1 dataset (Dang and Ngo,
work page 2025
-
[12]
dataset (math- ematics problems from AIME, AMC, and Omni- MATH (Gao et al., 2024)), and 1,000 easier prob- lems from the DeepScaleR (Guo and DeepSeek- AI,
work page 2024
-
[13]
Both models are trained on the Open-RS dataset
dataset. Both models are trained on the Open-RS dataset. For evaluation, we select five datasets: AIME24, MATH-500 (Hendrycks et al., 2021; Lightman et al., 2023), AMC23, Min- erva (Lewkowycz et al.,
work page 2021
-
[14]
More information is pre- sented in Table
and Olympiad- Bench (He et al., 2024). More information is pre- sented in Table
work page 2024
-
[15]
Reinforcement Learning for Reasoning Tasks
pro- posed that effective process rewards should mea- sure progress by evaluating likelihood changes be- fore and after each reasoning step. Reinforcement Learning for Reasoning Tasks. Reinforcement Learning with Verifiable Rewards (RLVR) has rapidly become the dominant route for eliciting step-by-step reasoning in LLMs. Shao 1https://github.com/huggingfa...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.