Recognition: no theorem link
Fill-Side Non-Retail Trading on Polymarket: An Empirical Study of Behavioral Tiers and Microstructure Signatures Under Quote-Attribution Constraints
Pith reviewed 2026-05-13 01:19 UTC · model grok-4.3
The pith
Polymarket's non-retail trading exhibits uni-modal fill-side behavior, allowing tier-based separation of dominant participants.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that fill-side behavior on Polymarket is uni-modal under the available six-feature vector, as DBSCAN clustering consistently identifies one dense cluster contradicting the hypothesis of four-to-five separable archetypes, while feature-tier stratification independently achieves robust retail versus non-retail separation with the top tiers holding 81.4 percent of total notional across 12.6 percent of addresses.
What carries the argument
The six-feature fill-side vector extracted from OrderFilled events, used for both DBSCAN clustering to test multi-modality and independent tier stratification to identify non-retail participants.
If this is right
- Address-level claims regarding market-making and liquidity provision are invalid due to the absence of quote-lifecycle data.
- Prediction market microstructure analysis must rely on fill-side metrics or external data sources when quote information is off-chain.
- Non-retail participants can be identified through volume-based tiers without requiring clustering.
- Concentrated notional volume in a small percentage of addresses suggests market dominance by sophisticated traders.
- Future empirical work on similar platforms should account for structural data limitations like the quote-lifecycle failure.
Where Pith is reading between the lines
- Similar constraints likely apply to other prediction market platforms using off-chain order books, limiting detailed behavioral studies.
- Combining fill data with market-level book diagnostics could enable better detection of manipulation strategies.
- Testing the uni-modal result across longer time periods or different market conditions would strengthen or challenge the finding.
- The tier method could be applied to other trading venues to compare non-retail participation patterns.
Load-bearing premise
The six-feature fill-side vector is adequate to detect or rule out distinct behavioral archetypes and to enable meaningful tier separation despite the loss of quote information.
What would settle it
Finding multiple clusters or noise points in the DBSCAN analysis of fill-side features from an independent Polymarket data window would falsify the uni-modal conclusion.
Figures
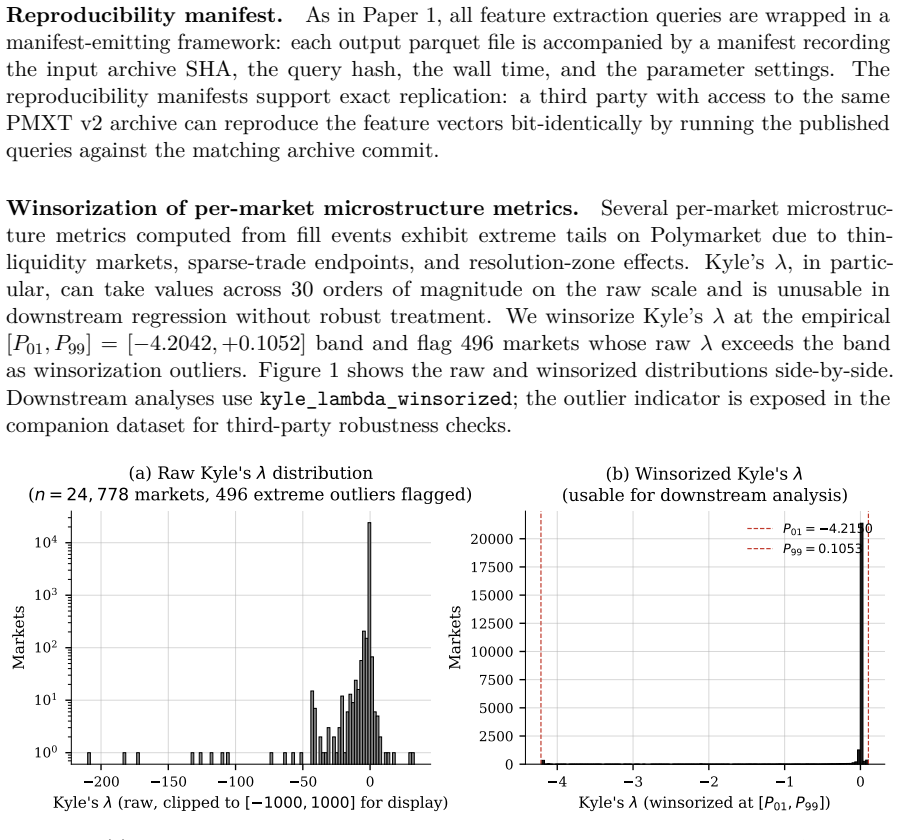
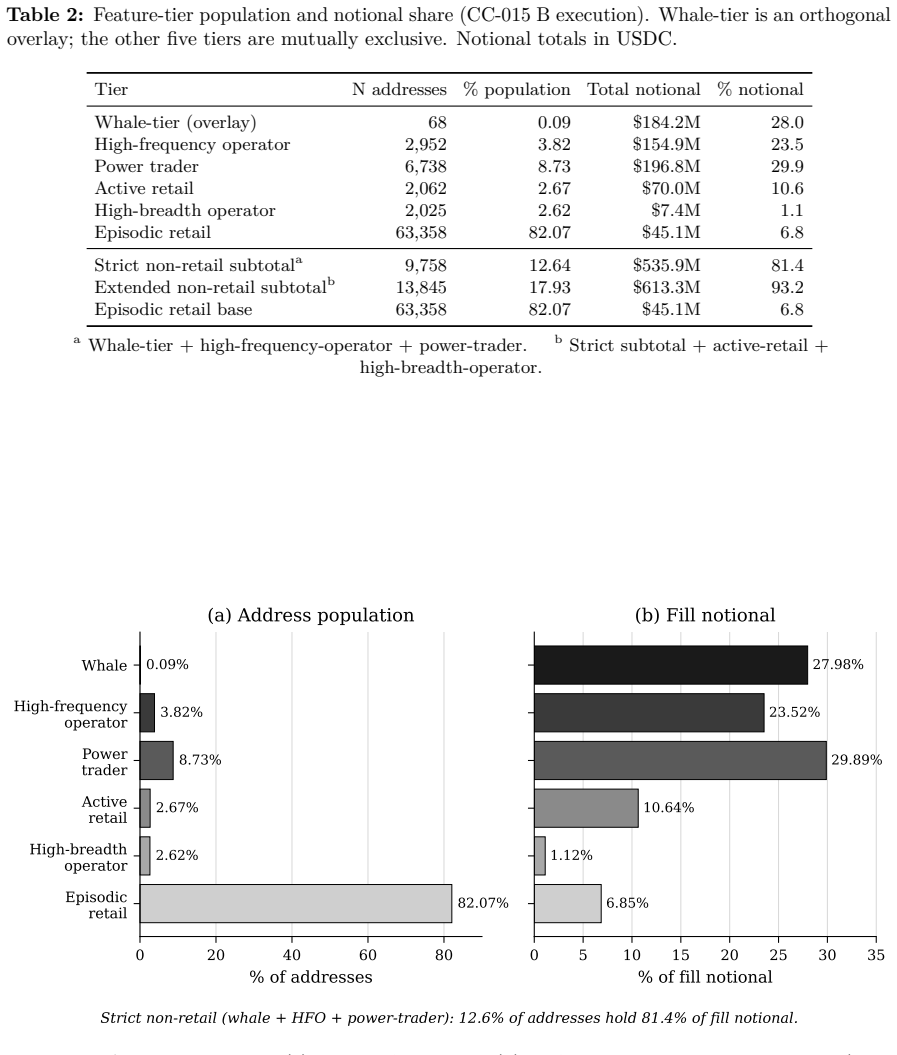

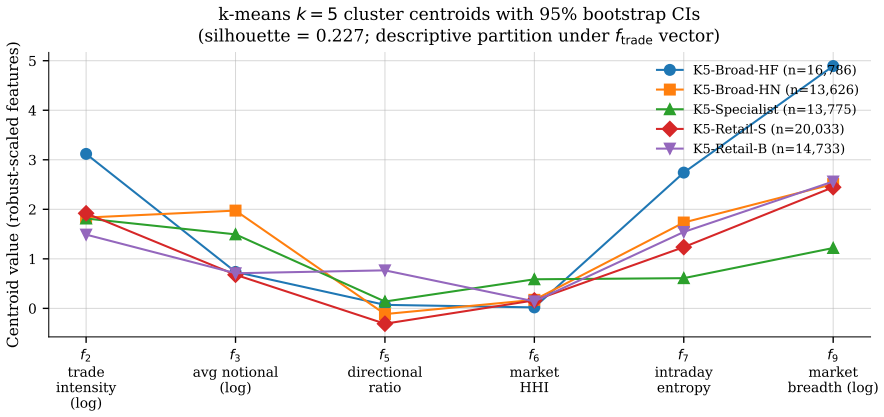
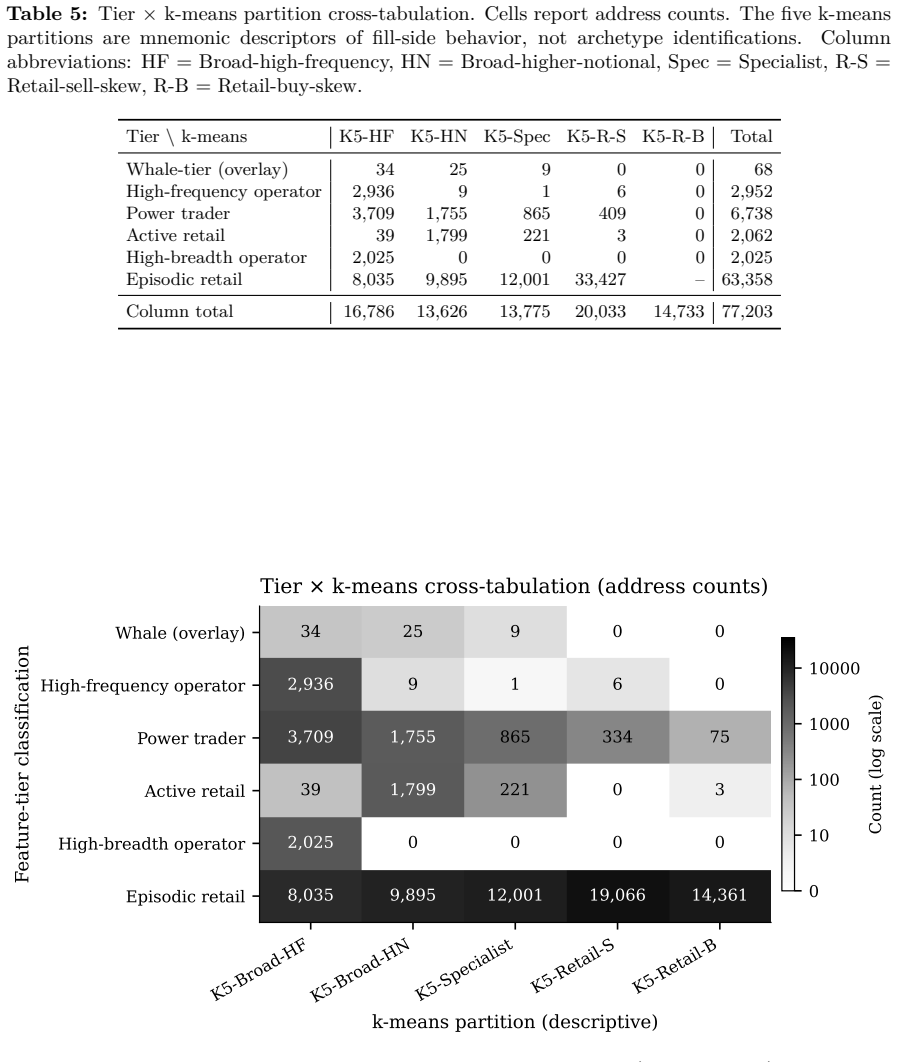

read the original abstract
Prediction markets cannot exist without market makers, arbitrageurs, and other non-retail liquidity providers, yet the supply-side microstructure of Polymarket-class venues has not been characterized at on-chain pseudonymous-address scale. This paper studies non-retail participation on Polymarket using an empirical run on the PMXT v2 archive over 2026-04-21 through 2026-04-27 (13,356,931 OrderFilled events; 77,204 addresses with five+ fills; 43,116 markets). We report three findings. First, Polymarket's off-chain CLOB architecture renders address-level quote-lifecycle attribution permanently unavailable: OrderPlaced and OrderCancelled events are off-chain and absent from public archives, so quote-intensity, two-sided-ratio, and posted-spread features cannot be built at address level. We document this as a structural validity-gate failure (G-QUOTE-LIFE universal fail) and restrict analysis to a six-feature fill-side vector. Second, density-based clustering (DBSCAN, fifteen sensitivity configurations) on the fill-side vector produces a single dense cluster with zero noise: fill-side behavior in the empirical window is uni-modal under the six-feature vector, contradicting the pre-registered hypothesis of four-to-five separable archetypes. Third, robust retail vs non-retail separation is achievable through clustering-independent feature-tier stratification: whale-tier, high-frequency-operator, and power-trader tiers jointly hold 81.4% of total notional across 12.6% of addresses. Address-level market-making and liquidity-provision claims are withdrawn per the G-QUOTE-LIFE failure; spoof-by-non-fill manipulation detection is downgraded to market-level book diagnostics. A privacy-respecting derived-dataset deposit accompanies the paper as Bundle 3 of the PMXT family. Fourth paper in a four-paper programme on event-linked perpetuals and leveraged prediction-market microstructure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines non-retail trading on Polymarket via an empirical analysis of 13,356,931 OrderFilled events across 77,204 addresses and 43,116 markets from 2026-04-21 to 2026-04-27. It documents a structural failure (G-QUOTE-LIFE) preventing address-level quote-lifecycle attribution due to off-chain OrderPlaced and OrderCancelled events, restricting analysis to a six-feature fill-side vector. DBSCAN clustering (15 sensitivity configurations) yields a single dense cluster with zero noise, indicating uni-modal fill-side behavior that contradicts the pre-registered hypothesis of four-to-five archetypes. Clustering-independent feature-tier stratification shows whale, high-frequency-operator, and power-trader tiers holding 81.4% of notional volume across 12.6% of addresses. Address-level market-making claims are withdrawn, and a derived dataset is deposited.
Significance. If the results hold, the work offers useful empirical evidence on liquidity concentration in prediction markets and the constraints of on-chain microstructure data, with the 81.4% notional concentration finding being particularly robust and reproducible via the public dataset deposit. The explicit reporting of DBSCAN outcomes across configurations strengthens the uni-modality observation. However, the significance of the contradiction to the pre-registered hypothesis is limited by the reduced feature set.
major comments (2)
- [Abstract and hypothesis section] Abstract and the section on pre-registered hypothesis: The claim that the single DBSCAN cluster on the six-feature fill-side vector contradicts the pre-registered hypothesis of four-to-five separable archetypes is undermined because the hypothesis was formulated including quote-related features (intensity, two-sided ratio, posted spread) that are unavailable due to the G-QUOTE-LIFE failure. The observed uni-modality may reflect collapsed distinctions from the reduced vector rather than true behavioral homogeneity, weakening the contradiction and the robustness of the subsequent retail/non-retail separation.
- [Tier stratification section] Section on tier stratification: The clustering-independent feature-tier stratification defining whale-tier, high-frequency-operator, and power-trader tiers lacks explicit cutoff definitions for the features and any robustness checks against variations in those thresholds. This is load-bearing for the claim that these tiers jointly hold 81.4% of total notional across 12.6% of addresses, especially since feature cutoffs are identified as free parameters.
minor comments (1)
- [Methods] Methods section: While the paper reports fifteen DBSCAN sensitivity configurations and the consistent single-cluster outcome, providing the specific eps and min_samples values tested and a table summarizing results across configurations would enhance transparency and reproducibility.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We address the major comments point by point below, agreeing where revisions are needed to strengthen the presentation of our findings on the constraints of on-chain data and the observed trading behaviors.
read point-by-point responses
-
Referee: [Abstract and hypothesis section] Abstract and the section on pre-registered hypothesis: The claim that the single DBSCAN cluster on the six-feature fill-side vector contradicts the pre-registered hypothesis of four-to-five separable archetypes is undermined because the hypothesis was formulated including quote-related features (intensity, two-sided ratio, posted spread) that are unavailable due to the G-QUOTE-LIFE failure. The observed uni-modality may reflect collapsed distinctions from the reduced vector rather than true behavioral homogeneity, weakening the contradiction and the robustness of the subsequent retail/non-retail separation.
Authors: We thank the referee for highlighting this important nuance. The pre-registered hypothesis was indeed formulated under the assumption of full quote-lifecycle data availability. However, upon discovering the G-QUOTE-LIFE structural failure, we restricted our analysis to the fill-side vector and observed uni-modality across multiple DBSCAN configurations. While this does qualify the strength of the contradiction to the original hypothesis, the finding of uni-modal fill-side behavior remains a key empirical result under the available data constraints. We will revise the abstract and hypothesis section to explicitly state that the pre-registered archetypes anticipated quote features, and clarify that the observed uni-modality pertains to the reduced six-feature vector. This revision will also reinforce the robustness of the subsequent tier-based retail/non-retail separation, which is independent of clustering. revision: yes
-
Referee: [Tier stratification section] Section on tier stratification: The clustering-independent feature-tier stratification defining whale-tier, high-frequency-operator, and power-trader tiers lacks explicit cutoff definitions for the features and any robustness checks against variations in those thresholds. This is load-bearing for the claim that these tiers jointly hold 81.4% of total notional across 12.6% of addresses, especially since feature cutoffs are identified as free parameters.
Authors: We agree that explicit cutoff definitions and robustness checks are necessary for transparency. In the revised manuscript, we will include precise definitions of the feature thresholds used to define the whale-tier, high-frequency-operator, and power-trader tiers. Additionally, we will conduct and report sensitivity analyses by varying these thresholds within reasonable ranges to demonstrate that the 81.4% notional concentration and 12.6% address share remain stable. The derived dataset deposit allows for independent verification of these stratifications. revision: yes
Circularity Check
No significant circularity in empirical derivation chain
full rationale
The paper conducts a data-driven empirical analysis on Polymarket fill events using a six-feature fill-side vector after acknowledging the G-QUOTE-LIFE structural data limitation that removes quote-lifecycle features. DBSCAN clustering (across sensitivity configurations) is applied directly to the observed data and reports a single dense cluster outcome that contradicts the pre-registered hypothesis; tier stratification for retail/non-retail separation is explicitly described as clustering-independent and consists of reporting notional concentration statistics (81.4% in 12.6% of addresses) from the same empirical distribution. No equations, fitted parameters presented as predictions, self-citations, or ansatzes are invoked in a load-bearing way that reduces any claim to its inputs by construction. The chain remains self-contained against the archive data and pre-registered elements without tautological reduction.
Axiom & Free-Parameter Ledger
free parameters (2)
- DBSCAN eps and min_samples values
- Feature cutoffs for whale, high-frequency-operator, and power-trader tiers
axioms (1)
- domain assumption The six fill-side features adequately proxy behavioral archetypes despite permanent loss of quote-lifecycle attribution.
Reference graph
Works this paper leans on
-
[1]
The Adoption of Blockchain-based Decentralized Exchanges
Capponi, Agostino and Ruizhe Jia (2021). “The Adoption of Blockchain-based Decentralized Exchanges”. In:Working paper. 50 Dubach (2026). “Polymarket Anatomy”. Working paper / preprint, 2026; cited in Paper 1 for depth profile geometric grid distribution. Complete citation pending venue identification at camera-ready
work page 2021
-
[2]
A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise
Ester, Martin, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu (1996). “A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise”. In:Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD- 96), pp. 226–231. ForesightFlow (2026).ForesightFlow Datasets. Online repository, accessed 2026...
work page 1996
-
[3]
Strategic Trading When Agents Forecast the Forecasts of Others
Foster, F. Douglas and S. Viswanathan (1996). “Strategic Trading When Agents Forecast the Forecasts of Others”. In:Journal of Finance51.4, pp. 1437–1478
work page 1996
-
[4]
Bid, Ask and Transaction Prices in a Specialist Market with Heterogeneously Informed Traders
Glosten, Lawrence R. and Paul R. Milgrom (1985). “Bid, Ask and Transaction Prices in a Specialist Market with Heterogeneously Informed Traders”. In:Journal of Financial Economics14.1, pp. 71–100
work page 1985
-
[5]
Combinatorial Information Market Design
Hanson, Robin (2003). “Combinatorial Information Market Design”. In:Information Systems Frontiers5.1, pp. 107–119
work page 2003
-
[6]
Hasbrouck, Joel (2007).Empirical Market Microstructure: The Institutions, Economics, and Econometrics of Securities Trading. Oxford University Press
work page 2007
-
[7]
(2020).BlockSci: Design and Applications of a Blockchain Analysis Platform
Kalodner, Harry et al. (2020).BlockSci: Design and Applications of a Blockchain Analysis Platform
work page 2020
-
[8]
Continuous Auctions and Insider Trading
Kyle, Albert S. (1985). “Continuous Auctions and Insider Trading”. In:Econometrica53.6, pp. 1315–1335
work page 1985
-
[9]
Lehar, Alfred and Christine A. Parlour (2022). “Decentralized Exchanges”. In:Working paper
work page 2022
-
[10]
Interpreting the Predictions of Prediction Markets
Manski, Charles F. (2006). “Interpreting the Predictions of Prediction Markets”. In:Economics Letters91.3, pp. 425–429
work page 2006
-
[11]
A Fistful of Bitcoins: Characterizing Payments Among Men with No Names
Meiklejohn, Sarah, Marjori Pomarole, Grant Jordan, Kirill Levchenko, Damon McCoy, Geoffrey M. Voelker, and Stefan Savage (2013). “A Fistful of Bitcoins: Characterizing Payments Among Men with No Names”. In:Internet Measurement Conference (IMC)
work page 2013
-
[12]
Empirical Evaluation of Deadline-Resolved Information Leakage on Documented Polymarket Insider Cases
Nechepurenko, Maksym (2026a). “A Taxonomy of Event-Linked Perpetual Futures: Variant Designs Beyond the Single-Market Binary Case”. Paper 2, four-paper Event-Linked Perpet- uals programme. Working paper, Devnull Research. Available at SSRN:https://papers. ssrn.com/abstract=6748298.url:https://papers.ssrn.com/abstract=6748298. — (2026b). “Empirical Evaluat...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605
-
[13]
Nechepurenko, Maksym (2026h). “Resolution-Aware Perpetual Futures on Binary Prediction Markets: An Empirical Risk-Design Framework Using Polymarket Data”. Paper 1, four- paper Event-Linked Perpetuals programme. Working paper, Devnull Research. Available at SSRN: https://papers.ssrn.com/abstract=6748278.url: https://papers.ssrn. com/abstract=6748278. — (20...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.27041 2019
-
[14]
Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis
Rousseeuw, Peter J. (1987). “Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis”. In:Journal of Computational and Applied Mathematics20, pp. 53–65
work page 1987
-
[15]
Inferring the Components of the Bid-Ask Spread: Theory and Empirical Tests
Stoll, Hans R. (1989). “Inferring the Components of the Bid-Ask Spread: Theory and Empirical Tests”. In:Journal of Finance44.1, pp. 115–134
work page 1989
-
[16]
Wolfers, Justin and Eric Zitzewitz (2004). “Prediction Markets”. In:Journal of Economic Perspectives18.2, pp. 107–126. 52
work page 2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.