Recognition: 2 theorem links
· Lean TheoremAgentDisCo: Towards Disentanglement and Collaboration in Open-ended Deep Research Agents
Pith reviewed 2026-05-13 05:33 UTC · model grok-4.3
The pith
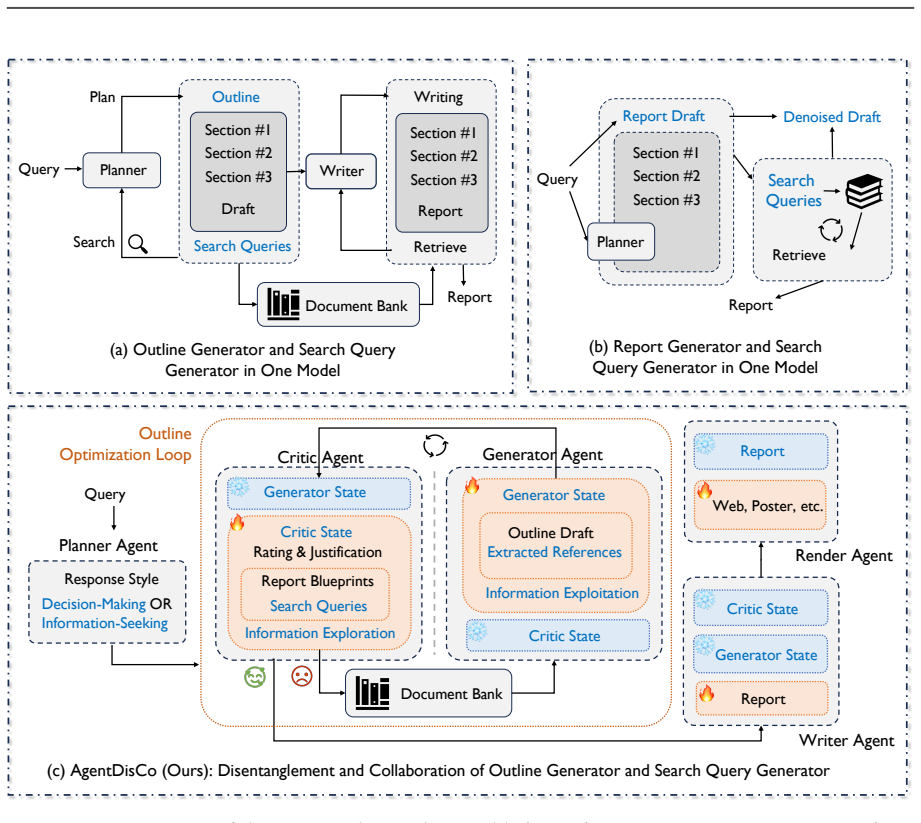
AgentDisCo separates exploration and exploitation into critic and generator agents that iteratively refine outlines before a report writer synthesizes them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
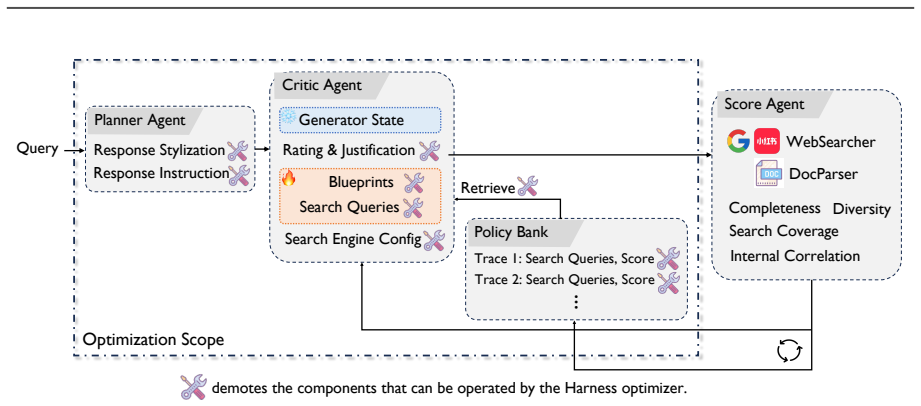
AgentDisCo formulates deep research as an adversarial optimization problem between information exploration and exploitation. It employs a critic agent to evaluate generated outlines and refine search queries and a generator agent to retrieve updated results and revise outlines accordingly. The iteratively refined outline is passed to a downstream report writer that synthesizes a comprehensive research report. The workflow supports both handcrafted and automatically discovered design strategies via a meta-optimization harness in which the generator is repurposed as a scoring agent to evaluate critic outputs and generate quality signals, enabling construction of a policy bank of reusable agent
What carries the argument
The critic-generator adversarial loop that alternates outline evaluation and revision, supported by a meta-optimization harness that builds a policy bank of design strategies.
Load-bearing premise
That splitting exploration and exploitation into separate agents and letting them optimize against each other produces better research outlines than handling both tasks inside a single module.
What would settle it
A direct comparison on the same benchmarks in which an otherwise identical single-module agent produces outlines and reports of equal or higher measured quality.
Figures






read the original abstract
In this paper, we present AgentDisCo, a novel Disentangled and Collaborative agentic architecture that formulates deep research as an adversarial optimization problem between information exploration and exploitation. Unlike existing approaches that conflate these two processes into a single module, AgentDisCo employs a critic agent to evaluate generated outlines and refine search queries, and a generator agent to retrieve updated results and revise outlines accordingly. The iteratively refined outline is then passed to a downstream report writer that synthesizes a comprehensive research report. The overall workflow supports both handcrafted and automatically discovered design strategies via a meta-optimization harness, in which the generator agent is repurposed as a scoring agent to evaluate critic outputs and generate quality signals. Powerful code-generation agents (e.g., Claude-Code, Codex) systematically explore agent configurations and construct a policy bank, a structured repository of reusable design strategies, enabling the framework to self-refine without extensive human intervention. We evaluate AgentDisCo on three established deep research benchmarks (DeepResearchBench, DeepConsult, DeepResearchGym) using Gemini-2.5-Pro, achieving performance comparable to or surpassing leading closed-source systems. Observing that existing benchmarks inadequately reflect real-world user needs, we introduce GALA (General AI Life Assistants), a benchmark that mines latent research interests from users' historical browsing behavior. We further develop a rendering agent that converts research reports into visually rich poster presentations, and demonstrate an end-to-end product, AutoResearch Your Interest, which delivers personalized deep research recommendations derived from individual browsing histories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentDisCo, a multi-agent architecture that disentangles deep research into a critic agent (for outline evaluation and query refinement) and a generator agent (for result retrieval and outline revision) framed as adversarial optimization between exploration and exploitation. The refined outline feeds a report writer; a meta-optimization harness repurposes the generator to score critic outputs and discover strategies via code-generation agents that populate a policy bank. The system is evaluated on DeepResearchBench, DeepConsult, and DeepResearchGym (claiming parity or superiority to closed-source models with Gemini-2.5-Pro), introduces the GALA benchmark derived from user browsing histories, and includes a rendering agent for poster presentations plus an end-to-end product demo.
Significance. If the central claims hold, the work would demonstrate that explicit separation of exploration/exploitation roles plus automated strategy discovery can improve open-ended research agents over monolithic designs, with the GALA benchmark and policy bank offering reusable contributions for personalized research systems. The meta-optimization approach and end-to-end product are concrete strengths that could influence practical agentic workflows.
major comments (3)
- [Experiments / Evaluation] The experimental evaluation (presumably §4 or §5) reports performance only for the full AgentDisCo system against closed-source baselines but provides no ablation or controlled comparison to a single-module baseline that merges critic and generator roles into one iterative agent while holding model, iteration count, and prompting fixed. This directly undermines the central claim that the disentangled adversarial formulation yields superior outlines and reports.
- [Experiments / Evaluation] No quantitative breakdown (tables, error bars, or statistical tests) isolates the contribution of the meta-optimization harness and policy bank versus standard iterative prompting with the same base model. The abstract states competitive results on three benchmarks, yet without these controls it remains unclear whether gains derive from the proposed architecture or simply from Gemini-2.5-Pro plus iteration.
- [Benchmark / GALA] The GALA benchmark is introduced as addressing limitations of prior benchmarks, but the manuscript does not report inter-annotator agreement, coverage statistics, or a direct comparison showing that GALA better correlates with real-world user satisfaction than DeepResearchBench et al.
minor comments (2)
- [Architecture] Notation for the adversarial loop (critic-generator interaction) and the meta-optimization scoring function should be formalized with equations or pseudocode for reproducibility.
- [Abstract / Experiments] The abstract claims 'comparable to or surpassing' closed-source systems; the main text should include the exact metrics, model versions, and run counts used for each benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening our experimental validation and benchmark justification. We address each major comment below and have revised the manuscript to incorporate the requested analyses.
read point-by-point responses
-
Referee: [Experiments / Evaluation] The experimental evaluation (presumably §4 or §5) reports performance only for the full AgentDisCo system against closed-source baselines but provides no ablation or controlled comparison to a single-module baseline that merges critic and generator roles into one iterative agent while holding model, iteration count, and prompting fixed. This directly undermines the central claim that the disentangled adversarial formulation yields superior outlines and reports.
Authors: We agree that a controlled ablation against a merged single-agent baseline is essential to substantiate the value of disentanglement. In the revised manuscript, we have added this comparison in Section 4, implementing a single iterative agent that combines critic and generator roles while fixing the base model (Gemini-2.5-Pro), iteration count, and prompting. Results show measurable gains in outline quality and report scores for the disentangled design, directly supporting our central claim. These findings are summarized in a new table. revision: yes
-
Referee: [Experiments / Evaluation] No quantitative breakdown (tables, error bars, or statistical tests) isolates the contribution of the meta-optimization harness and policy bank versus standard iterative prompting with the same base model. The abstract states competitive results on three benchmarks, yet without these controls it remains unclear whether gains derive from the proposed architecture or simply from Gemini-2.5-Pro plus iteration.
Authors: We acknowledge the need to isolate these contributions. The revised version includes a quantitative breakdown in Section 4.3 with tables comparing the full AgentDisCo system, a version without the policy bank, and a standard iterative prompting baseline using the identical model. We report error bars across runs and include statistical tests (e.g., paired t-tests) confirming the incremental benefits of meta-optimization and the policy bank. revision: yes
-
Referee: [Benchmark / GALA] The GALA benchmark is introduced as addressing limitations of prior benchmarks, but the manuscript does not report inter-annotator agreement, coverage statistics, or a direct comparison showing that GALA better correlates with real-world user satisfaction than DeepResearchBench et al.
Authors: We appreciate this request for additional validation of GALA. In the revision, we have incorporated inter-annotator agreement metrics, coverage statistics on the mined browsing interests, and a comparative user study demonstrating stronger correlation with real-world satisfaction than prior benchmarks. These details are now reported in Section 5 to better justify GALA's introduction. revision: yes
Circularity Check
No circularity: architecture and benchmarks are independent design and evaluation choices
full rationale
The paper introduces AgentDisCo as an explicit architectural proposal that separates critic (exploration/refinement) and generator (exploitation/revision) agents, then evaluates the full system empirically on DeepResearchBench, DeepConsult, DeepResearchGym and the new GALA benchmark using Gemini-2.5-Pro. No equations, fitted parameters, or self-citations appear in the provided text that would reduce claimed performance to inputs by construction. The meta-optimization harness and policy bank are presented as methodological contributions rather than tautological re-labelings of results. The derivation chain therefore consists of design decisions followed by external benchmark measurements and remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Separating exploration and exploitation into distinct critic and generator agents improves research report quality over conflated approaches.
invented entities (3)
-
Critic agent
no independent evidence
-
Generator agent
no independent evidence
-
GALA benchmark
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
formulates deep research as an adversarial optimization problem between information exploration and exploitation... critic agent... generator agent... meta-optimization harness... policy bank
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
iteratively refined outline... downstream report writer
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2507.16075. LangChain, Inc. LangChain: Building applications with LLMs through composability, 2023. URL https://python.langchain.com/. Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. Meta- harness: End-to-end optimization of model harnesses.arXiv preprint arXiv:2603.28052, 2026. Yu Lei, Shuzhe...
-
[2]
Background Context (1–2 sentences) Describe a real user scenario, clearly stating the user’s goal or confusion, such as: 19 • I’m planning to purchase . . . • I’m planning to . . . • I’m considering whether to . . . • I’m torn between the following options
-
[3]
Research Subjects Clearly list the specific subjects to be researched, using numbered format: (1) . . . (2) . . . (3) . . . Research subjects can be: products / brands / solutions / locations / platforms / strategies
-
[4]
Research Questions (3–5) Use numbered format to list questions that require research to answer, such as:
-
[5]
What are real user reviews and reputation like
-
[6]
Does actual experience match the advertised claims
-
[7]
How is the price and value for money
-
[8]
What are common issues or usage risks
-
[9]
How high is the long-term usage cost or maintenance difficulty Research questions must be: specific, searchable, comparable, and analyzable
-
[10]
Constraints (2–4) Clearly state the user’s limiting conditions, such as: • Budget constraint: total budget not exceeding XXX • Usage scenario: mainly for commuting / suitable for southern climate / no drilling allowed in rental • Personal preference: prioritizes durability / dislikes complex maintenance • Time condition: needs to make a decision soon
-
[11]
Which is more suitable for me, XX or XX? Compare from XX dimen- sions
Research Goal Clearly state the action conclusion the user hopes to obtain, such as: • Provide a ranked recommendation • Determine whether it is worth purchasing • Choose the optimal solution • Formulate a specific action plan ## Step 3 — Query Depth Requirements Each query must satisfy: • Requires at least 3 different information sources to answer • Requ...
-
[12]
Output only the category name — do not add any explanation, punctuation, or extra text
-
[13]
Must select from the categories listed above — do not create new categories
-
[14]
The detailed prompt is listed as follows
Choose the category that most closely matches the core intent of the query A.3 Prompt for Planner Agent As described in Section 2, the primary objective of our planner agent is to interpret user intent and generate corresponding guidance cues and response style specifications to direct the subsequent agents accordingly. The detailed prompt is listed as fo...
-
[15]
X vs Y”, “difference between X and Y
Comparison & Selection • Core signals: “X vs Y”, “difference between X and Y”, “X or Y”, “difference between”, “com- pared to” — two or more entities explicitly placed side by side • Response content: The opening section must include a one-sentence conclusion; then dynami- cally select the most relevant dimensions based on the topic (e.g., performance / p...
-
[16]
Recommendations & Suggestions • Core signals: “recommend”, “best”, “what’s a good”, “best X”, “top X for Y” — seeking advice with no specific candidates in mind • Response content: The opening section must provide a recommendation overview (e.g., top pick, runner-up, best value); then offer a comparison of the recommended options, which may include core h...
-
[17]
How-to Guide • Core signals: “how to do”, “how to”, “tutorial”, “getting started”, “step by step” — action- oriented, expecting operational steps • Response content: The opening section must cover prerequisites (environment/requirements), core steps, and estimated time; subsequent sections must detail each step’s description and common issues
-
[18]
Travel Planning • Core signals: “travel to X”, “X travel guide”, “X days”, “travel guide”, “itinerary” — location + travel-related terms • Response content: The opening section must provide 2–3 sentences of overview; then provide a Day 1–Day X itinerary including must-visit attractions, dining recommendations, transporta- tion guide, accommodation suggest...
-
[19]
Purchase Decision • Core signals: “how much does X cost”, “is X worth buying”, “which model is better”, “worth it”, “should I buy” — price / purchase intent • Response content: The opening section must provide 2–3 sentences covering: whether it is recommended + who it suits + the single most important reason; then present a product overview table with rea...
-
[20]
Fact Query • Core signals: “what is”, “what does X mean”, “Define” — expecting a definitive answer • Response content: The opening section must answer with a concise, accurate core definition; include 2–5 of the most important key points based on the topic
-
[21]
Status & Progress • Core signals: “latest developments”, “what’s happening with X now”, “X update”, “X latest” — contains time-indicative words • Response content: Pay attention to information recency; the opening section must present a recent update timeline with concise timestamps, events, and brief descriptions
-
[22]
News & Information • Core signals: “X news”, “X this week” — explicitly news / current-events oriented • Response content: The opening section must list the most important news headlines with 2–3 objective summary sentences; subsequent content follows reverse chronological order with clear, verifiable timestamps
-
[23]
Deep Exploration • Core signals: “deep dive into”, “X ecosystem”, “ecosystem”, “everything about” — open- ended, no clearly defined scope • Response content: The opening section must provide 2–3 sentences of general framing: what the topic is, why it is worth exploring, and its current significance
-
[24]
Resource Locating 23 • Core signals: “X official website”, “X documentation”, “X GitHub”, “official site”, “documen- tation” — looking for specific links or resources • Response content: The opening section must list the core links; subsequent sections may provide additional extended resources # Output Format Output JSON directly with no extra content, us...
-
[25]
Zero-score situations:Empty outlines, malicious content (empty answers, meaningless text, score manipulation, etc.) receive 0 directly
-
[26]
Strict standards:Each dimension is scored independently (0–10), and the total score is the average of all dimensions
-
[27]
High-score threshold:A score of 8 or above is only awarded to outlines that perform exceptionally in that dimension; 7 is good, 6 is acceptable, and below 5 is unacceptable Evaluation Dimensions (0–10 points each) 1.Instruction Adherence (0–10) • 9–10: Perfectly follows all user requirements (topic, audience, purpose, format, length, etc.), with clear hie...
-
[28]
Non-empty list:Supplement and optimize based on the current user query, with a focus on reinforcing missing dimensions
-
[29]
Empty list:Generate a comprehensive list of key point content based on the user query, producing a key points list that covers the core elements
-
[30]
Update principles:Prioritize addition and rewriting logic; avoid simply deleting existing reasonable content. Ensure content breadth (covering multiple relevant dimensions) and depth (specific analysis points for each dimension). Address weaknesses identified in the evaluation dimensions in a targeted manner
-
[31]
List length:Flexibly determined based on the complexity and coverage scope of the user query; simple questions may be appropriately condensed, complex questions should be fully expanded; generally recommended to stay within{max blueprints len} { Search Term Generation Guidelines (Xiaohongshu / Knowledge):
-
[32]
Extract all core topic words, proper nouns, and important attributes from the user’s question
-
[33]
Each search term must be specific, clear, and closely aligned with the user’s needs, suitable for use on the Xiaohongshu platform; it is strictly prohibited to introduce irrelevant, vague, or redundant information
-
[34]
If the user’s question involves details such as time, location, person, or scenario, extract and incorporate them reasonably into the keywords; if not explicitly mentioned, there is no need to force their inclusion
-
[35]
Ensure diversity of keyword expression, covering different synonymous expressions or important subcategories under the same topic
-
[36]
Keywords within each search term group should be separated by spaces (example: skincare hydrating mask); different search term groups should be separated by English commas. Each search term may be a single word or a multi-word combination, but the overall expression should always remain concise and targeted
-
[37]
Assess whether the user’s original input already contains expressions suitable for use as search terms; if so, retain and include them directly in the result list
-
[38]
Do not output any explanations, descriptions, or formatting symbols; output only the final list of search term groups
-
[39]
Generated search terms should be in Chinese
-
[43]
{ { Search Term Generation Guidelines (Google):
Note: Prioritize the user’s requirements when deciding the number of search terms to generate for each outline target list item; in general, it is recommended to keep the number of search terms within{max query len}. { { Search Term Generation Guidelines (Google):
-
[44]
Precisely extract core topic words, proper nouns, and important information from the user’s input
-
[45]
Q3 2024” should be written as “Third Quarter of 2024
Time information must be identified and completed: extract explicit time references directly (e.g., “Q3 2024” should be written as “Third Quarter of 2024”); implicit time references must be converted into specific intervals (e.g., “last quarter” requires automatic calculation of the previous quarter’s start and end dates based on today’s date:{{curr date}}) 26
work page 2024
-
[46]
Keyword priority order: proper nouns (brands, companies, products, policies, etc.) > metrics or characteristics (figures, sales volumes, new products, technological breakthroughs, etc.) > key actions (releases, rises/falls, mergers, experiences, etc.) > regions or scenarios (cities, countries, specific locations)
-
[47]
Expressions must be concise: remove interrogative words (“how”, “whether”, etc.), subjective descriptors (“amazing”, “ultra-powerful”, etc.), and vague expressions (“some”, “various”, etc.); retain only content with actual retrieval significance
-
[48]
For special scenarios, such as comparative questions, retain both sides of the comparison and highlight them with “vs” or “comparison”
-
[49]
If a historical search terms list exists, avoid duplicating historical search terms
Note: Search terms must ensure broad and diverse coverage; they do not need to be strongly related to the user’s question, as long as they provide incremental value. If a historical search terms list exists, avoid duplicating historical search terms
-
[50]
Note: Search term generation should aim for depth and should not be empty where possible
-
[51]
Note: When the input outline content is non-empty, search term generation should explore the content depth lacking in each sub-heading of the outline as much as possible, striving to enrich the depth of outline content
-
[52]
rating":`float`- Score for the given outline,
Note: Prioritize the user’s requirements when deciding the number of search terms to generate for each outline target list item; in general, it is recommended to keep the number of search terms within{max query len}. { ## Output Format Please strictly output in the following JSON format: { "rating":`float`- Score for the given outline, "justification":`st...
-
[53]
how to completely answer the user’s query,
Query-first response:The overall organizational logic of the outline must center on directly responding to the user’s query. All chapter divisions and sub-topic settings must revolve around “how to completely answer the user’s query,” avoiding generalized expansions that deviate from the user’s core needs
-
[54]
Response style:Follow the style to cover and arrange the key points of the outline content. Prioritize responding to the user’s primary intent and cover the user’s secondary intent in specific sections
-
[55]
Ensure required components are included and avoid deviating from user expectations
Instruction adherence:Generate the outline strictly according to the requirements of the user’s query, including subject scope, audience positioning, level of detail, tone and style, as well as any formatting or structural requirements. Ensure required components are included and avoid deviating from user expectations
-
[56]
Content depth:Based on the outline key points list, ensure the outline possesses analytical depth. An excellent outline not only contains generalizing headings but should also include: specific analysis points, key argumentation logic, mechanisms and causal relationships, methodological frameworks, evaluation metrics, dependency analysis, and evidence and...
-
[57]
Perspective balance:Ensure fairness and objectivity of the outline. For complex or controversial issues, multiple perspectives and differing viewpoints should be planned, content space should be allocated fairly, and neutral, non-leading language should be used. Explicitly include sections for trade-off analysis, discussion of limitations, and considerati...
-
[58]
Coverage should be broad and purposeful, avoiding irrelevant digressions
Coverage breadth:Based on the outline key points list, ensure coverage of multiple relevant dimensions, such as: historical background, policies and regulations, market economics, tech- nical operations, social culture, geographic comparisons, stakeholder analysis, risk assessment, and implementation pathways. Coverage should be broad and purposeful, avoi...
-
[59]
Evidence support:Systematically plan the evidence framework and sources. Precisely add citation markers <cite>document ID</cite> after relevant content, ensuring citation diversity to enhance the credibility and comprehensiveness of the argumentation. Fabricating citation information is strictly prohibited
-
[60]
Insight value:Go beyond common templates by providing original structural frameworks, high- lighting non-obvious connections, and rationally sequencing sections to efficiently reveal key insights. Ensure recommendations and analyses are specific and actionable, explicitly identifying specific cases, comparative studies, and appropriate presentation method...
-
[61]
Structural logic:Build clear hierarchical relationships with distinct responsibilities for headings at each level and smooth logical flow. When a section at a given level requires subdivision, it should contain 2 or more sub-headings to ensure reasonable and complete categorization. Focus on overall structural coherence, logical relationships between sect...
-
[62]
Citation diversity:Cite as many different document IDs as possible to enhance evidence support through diversified sources and provide multi-perspective viewpoints. ### Special Requirements
-
[63]
Open with a direct substantive answer (preamble and background explanations are absolutely prohibited): • Thefirst chapter of the report(i.e., the ## heading) must cut straight to the point and provide thefinal substantive answerto the user’s query. • It isstrictly prohibitedto write vacuous preamble content such as “Executive Summary,” “Background Introd...
-
[64]
how does this section serve the answering of the user’s query
Content self-consistency:Ensure the outline covers the complete scope of the topic, with each section corresponding to and echoing the others to form a complete closed loop. Content should have no repetition, no omissions, no conflicts, and must be practical and readable. All sections must be able to clearly answer the question “how does this section serv...
-
[65]
Deep exploration:On the premise of ensuring logic and consistency, generate more levels of sub-headings to ensure each section is explored in depth, avoiding superficial generalizations
-
[66]
Iterative optimization:If the previous round outline content is non-empty, conduct systematic iteration based on the previous round outline, fully incorporating the improvement suggestions from the evaluation
-
[67]
Section richness:To improve overall information coverage, multiple core sections ( ##) should be used in the outline. On the premise of ensuring logical relationships between sections, divide into as many core sections as possible to cover the content of the outline key points list. In general, the number of core sections should be no fewer than 7–10 (inc...
-
[68]
High citation coverage:To improve overall information coverage, externally sourced search results should be utilized as fully as possible. Any content relevant to the user’s query and outline key points list should be cited wherever possible. In general, the number of externally sourced search content citations should be no fewer than 100–200. ## Citation...
-
[69]
Format standard:Use the <cite>document ID</cite> format, e.g., <cite>turn_0_4, turn_1_8</cite>
-
[70]
Positional accuracy:Immediately follow the relevant information, ensuring citations correspond precisely to content
-
[71]
Prohibition principle:Fabricating cited document information or fictitious document IDs is strictly prohibited. ## Output Format
-
[72]
Please output only the final answer outline; do not repeat the user’s question and do not output any opening remarks or explanatory statements
-
[73]
Strictly follow the above rules and structure, ensuring clarity of organization, richness of content, and elegance of expression
-
[74]
## Chapter 2 [Specific Discussion / Dimensional Breakdown...]
Strictly output using the following Markdown hierarchical structure: # [Overall Report Title] ## Chapter 1 [Core Conclusion That Directly Answers the Query] ### 1.1 [Declarative sentence heading for Conclusion Dimension 1] ### 1.2 [Declarative sentence heading for Conclusion Dimension 2] ... ## Chapter 2 [Specific Discussion / Dimensional Breakdown...] .....
-
[75]
Strictly follow the outline framework:Use the heading structure of the input outline as the sole skeleton, filling in corresponding content under each heading. It is strictly prohibited to independently add, delete, merge, or split any heading level. The organizational logic of section content must fully correspond to the outline’s hierarchical structure;...
-
[76]
Write around the user’s query:While filling in the outline framework, every paragraph of content must clearly serve the answering of the user’s query. Before writing, first clarify the role this section plays in answering the user’s query (background setting, core argumentation, data support, conclusions and recommendations, etc.), and use this as the gui...
-
[77]
Content supplementation:Remain faithful to the outline framework; supplement the details of the outline by combining search document content, focusing exclusively on the sections designated in the outline; it is strictly prohibited to supplement the content of preceding or following sections
-
[78]
Logical optimization:Ensure the report structure is clear, well-layered, thoroughly argued, and professionally expressed
-
[79]
Citation standards:Strictly maintain the <cite>document ID</cite> format; it is prohibited to fabricate document content or fictitious document IDs. 6.Quality assurance:Apply the “Let’s think step by step” approach; content must be well-reasoned and evidence-based, avoiding vague statements and ensuring information accuracy
-
[80]
Formatting aesthetics:Based on the question type of the user’s query, adopt an appropriate and readable format (such as paragraphs, numbered lists, tables, etc.) to enhance readability
-
[81]
Information integration:Synthesize the content of multiple relevant search results; the same externally sourced search document content must not be cited repeatedly. Fully extract and integrate key information, responding in a multi-perspective, thorough, in-depth, and creative manner
-
[82]
Language consistency:Unless the user specifically requests otherwise, respond in the same lan- guage as the user’s query
-
[83]
Consistency and self-coherence:Ensure that every key point is answered in a self-consistent, substantive, and professional manner; for example, a weekly meal plan must list a complete seven-day menu
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.