Recognition: 2 theorem links
· Lean TheoremOne-Step Generative Modeling via Wasserstein Gradient Flows
Pith reviewed 2026-05-13 07:41 UTC · model grok-4.3
The pith
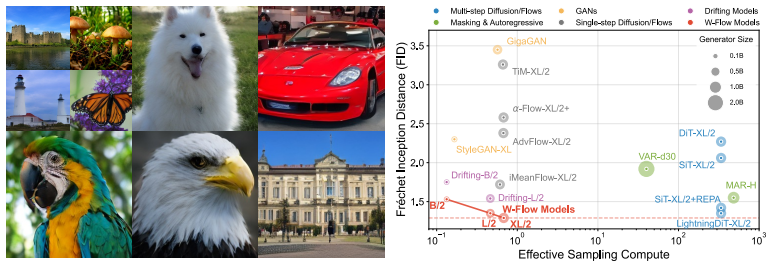
W-Flow achieves one-step ImageNet 256x256 generation at 1.29 FID by training a neural network to compress a Wasserstein gradient flow.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
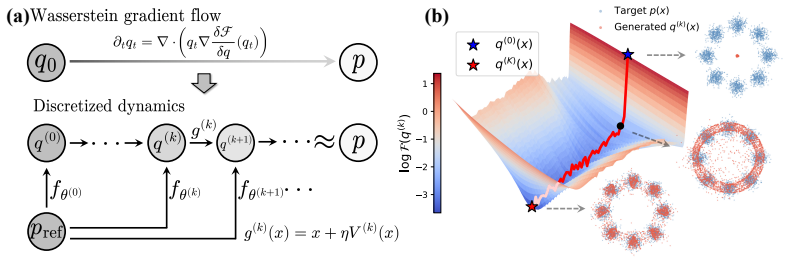
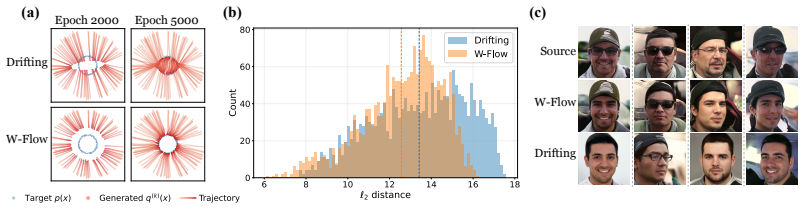
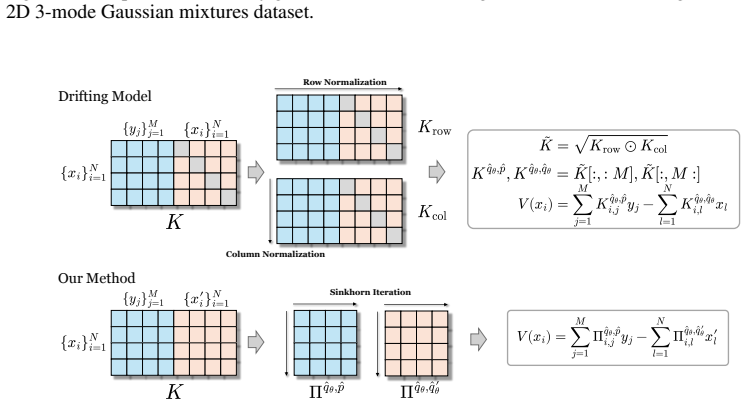
W-Flow defines an evolution from reference to target distribution through a Wasserstein gradient flow minimizing the Sinkhorn divergence energy functional, then trains a static neural generator to realize this entire evolution in one step. The finite-sample training dynamics converge to the continuous-time distributional dynamics under suitable assumptions. Empirically the resulting model reaches 1.29 FID on one-step ImageNet 256x256 generation, improves mode coverage and domain transfer, and yields approximately 100 times faster sampling than multi-step diffusion models with similar FID scores.
What carries the argument
The Wasserstein gradient flow of the Sinkhorn divergence energy functional, compressed into a single forward pass by a static neural generator.
Load-bearing premise
Finite-sample training dynamics converge to the continuous-time Wasserstein gradient flow dynamics under suitable assumptions.
What would settle it
A direct comparison showing that samples from the trained one-step generator deviate from the distribution reached by running the full multi-step Wasserstein flow on the same reference inputs.
Figures










read the original abstract
Diffusion models and flow-based methods have shown impressive generative capability, especially for images, but their sampling is expensive because it requires many iterative updates. We introduce W-Flow, a framework for training a generator that transforms samples from a simple reference distribution into samples from a target data distribution in a single step. This is achieved in two steps: we first define an evolution from the reference distribution to the target distribution through a Wasserstein gradient flow that minimizes an energy functional; second, we train a static neural generator to compress this evolution into one-step generation. We instantiate the energy functional with the Sinkhorn divergence, which yields an efficient optimal-transport-based update rule that captures global distributional discrepancy and improves coverage of the target distribution. We further prove that the finite-sample training dynamics converge to the continuous-time distributional dynamics under suitable assumptions. Empirically, W-Flow sets a new state of the art for one-step ImageNet 256$\times$256 generation, achieving 1.29 FID, with improved mode coverage and domain transfer. Compared to multi-step diffusion models with similar FID scores, our method yields approximately 100$\times$ faster sampling. These results show that Wasserstein gradient flows provide a principled and effective foundation for fast and high-fidelity generative modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces W-Flow, a two-stage framework that first evolves samples from a reference distribution to a target data distribution via a Wasserstein gradient flow minimizing a Sinkhorn-divergence energy functional, then trains a static neural generator to compress this continuous evolution into a single forward pass. It asserts a convergence result for finite-sample training dynamics to the continuous-time flow under suitable assumptions, and reports new state-of-the-art one-step performance on ImageNet 256×256 (1.29 FID) together with improved mode coverage, domain transfer, and roughly 100× faster sampling than multi-step diffusion models of comparable FID.
Significance. If the convergence result can be made rigorous and the empirical gains hold under controlled ablations, the work would supply a principled optimal-transport route to high-fidelity one-step generation that improves upon both diffusion and existing one-step baselines in coverage and speed, with potential impact on downstream tasks requiring fast sampling.
major comments (1)
- [Abstract and convergence theorem] Abstract and theoretical development: the central claim that the trained one-step generator faithfully realizes the Wasserstein flow rests on a convergence statement for finite-sample dynamics that is conditioned on unspecified 'suitable assumptions.' Because the 1.29 FID result is presented as evidence that the discrete network compresses the continuous dynamics, the precise conditions (regularity of the energy functional, Lipschitz bounds on the velocity field, uniform convergence rates of empirical measures, or control of discretization error in 256×256 image space) must be stated explicitly and shown to be satisfied; without them the link between theory and the reported FID remains unverified.
minor comments (2)
- [Method section] The precise definition of the Sinkhorn-regularized energy functional and the architecture/hyper-parameters of the one-step generator should be moved from supplementary material into the main text to support reproducibility of the 1.29 FID number.
- [Experiments] Figure captions and experimental tables should explicitly report the number of function evaluations and wall-clock time per sample when claiming the 100× speedup relative to diffusion baselines.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The feedback on clarifying the convergence result is well-taken and will strengthen the manuscript. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract and convergence theorem] Abstract and theoretical development: the central claim that the trained one-step generator faithfully realizes the Wasserstein flow rests on a convergence statement for finite-sample dynamics that is conditioned on unspecified 'suitable assumptions.' Because the 1.29 FID result is presented as evidence that the discrete network compresses the continuous dynamics, the precise conditions (regularity of the energy functional, Lipschitz bounds on the velocity field, uniform convergence rates of empirical measures, or control of discretization error in 256×256 image space) must be stated explicitly and shown to be satisfied; without them the link between theory and the reported FID remains unverified.
Authors: We agree that the assumptions require explicit statement to make the theoretical-empirical connection rigorous. In the revision we will expand the theorem (Section 3) to list them verbatim: (i) the Sinkhorn energy is λ-convex and C²-smooth w.r.t. the 2-Wasserstein metric for ε>0; (ii) the resulting velocity field is globally L-Lipschitz; (iii) the empirical measures satisfy a uniform Glivenko–Cantelli property with rate O(n^{-1/2} log n) under the covering numbers of the RKHS induced by the kernel; (iv) the Euler–Maruyama discretization error is O(Δt) uniformly on compact time intervals when the velocity is bounded. We will add a short verification paragraph showing that (i)–(iii) hold for the entropic Sinkhorn divergence on the image manifold (citing standard OT regularity results) and that (iv) is controlled by our chosen step-size schedule. The 1.29 FID remains an empirical illustration of practical performance; the revised theorem will now make the approximation guarantee precise rather than conditional on unspecified assumptions. revision: yes
Circularity Check
No circularity detected in the derivation chain
full rationale
The paper defines an evolution via Wasserstein gradient flow minimizing an energy functional instantiated with Sinkhorn divergence, then trains a neural generator to compress the flow into one step. This is a standard two-stage procedure using established optimal transport geometry and neural approximation; the claimed one-step generator is optimized against the flow rather than defined to equal it by construction. The convergence of finite-sample dynamics is asserted under suitable assumptions without any equation reducing the reported FID or sampling speed directly to a fitted internal parameter. No load-bearing self-citation, uniqueness theorem imported from prior author work, or ansatz smuggled via citation appears in the provided text. The ImageNet results are presented as empirical outcomes, not forced predictions.
Axiom & Free-Parameter Ledger
free parameters (1)
- Sinkhorn regularization strength
axioms (1)
- domain assumption Finite-sample training dynamics converge to continuous-time distributional dynamics under suitable assumptions
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) unclearWe model the evolution of {q(k)} via a WGF... V_t(x) = -∇ δF/δq (q_t)(x) ... instantiate ... Sinkhorn divergence ... prove finite-sample training dynamics converge ... under suitable assumptions (Assumption A.1)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearTheorem 3.1 (Informal) ... sup W2(bqN,M,η_t , q_t) → 0 as η→0, N,M→∞
Reference graph
Works this paper leans on
-
[1]
Building Normalizing Flows with Stochastic Interpolants
Michael S Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants.arXiv preprint arXiv:2209.15571, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
LightSBB-M: Bridging Schr\"odinger and Bass for Generative Diffusion Modeling
Alexandre Alouadi, Pierre Henry-Labordère, Grégoire Loeper, Othmane Mazhar, Huyên Pham, and Nizar Touzi. Lightsbb-m: Bridging schrödinger and bass for generative diffusion modeling. 11 arXiv preprint arXiv:2601.19312, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Wasserstein generative adversarial networks
Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. InInternational conference on machine learning, pages 214–223. Pmlr, 2017. 2, 3
work page 2017
-
[4]
Nicholas M Boffi, Michael S Albergo, and Eric Vanden-Eijnden. How to build a consistency model: Learning flow maps via self-distillation.arXiv preprint arXiv:2505.18825, 2025. 3
-
[5]
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale GAN training for high fidelity natural image synthesis.arXiv preprint arXiv:1809.11096, 2018. 9
work page internal anchor Pith review arXiv 2018
-
[6]
Jiarui Cao, Zixuan Wei, and Yuxin Liu. Gradient flow drifting: Generative modeling via wasserstein gradient flows of kde-approximated divergences.arXiv preprint arXiv:2603.10592,
-
[7]
Maskgit: Masked generative image transformer
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11315–11325, 2022. 9
work page 2022
-
[8]
Scalable Wasserstein gradient flow for generative modeling through unbalanced optimal transport
Jaemoo Choi, Jaewoong Choi, and Myungjoo Kang. Scalable Wasserstein gradient flow for generative modeling through unbalanced optimal transport. InProceedings of the 41st Inter- national Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 8629–8650. PMLR, 21–27 Jul 2024. 3, 29
work page 2024
-
[9]
Valentin De Bortoli, James Thornton, Jeremy Heng, and Arnaud Doucet. Diffusion schrödinger bridge with applications to score-based generative modeling.arXiv preprint arXiv:2106.01357,
-
[10]
ImageNet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. InCVPR, pages 248–255. Ieee, 2009. 8
work page 2009
-
[11]
Generative Modeling via Drifting
Mingyang Deng, He Li, Tianhong Li, Yilun Du, and Kaiming He. Generative modeling via drifting.arXiv preprint arXiv:2602.04770, 2026. 2, 3, 4, 6, 8, 9, 10, 26, 28, 29, 30, 32
work page internal anchor Pith review arXiv 2026
-
[12]
Diffusion models beat GANs on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat GANs on image synthesis. NeurIPS, 34:8780–8794, 2021. 8, 9
work page 2021
-
[13]
Variational wasser- stein gradient flow.arXiv preprint arXiv:2112.02424, 2021
Jiaojiao Fan, Qinsheng Zhang, Amirhossein Taghvaei, and Yongxin Chen. Variational wasser- stein gradient flow.arXiv preprint arXiv:2112.02424, 2021. 3
-
[14]
Interpolating between optimal transport and mmd using sinkhorn divergences
Jean Feydy, Thibault Séjourné, François-Xavier Vialard, Shun-ichi Amari, Alain Trouvé, and Gabriel Peyré. Interpolating between optimal transport and mmd using sinkhorn divergences. InThe 22nd international conference on artificial intelligence and statistics, pages 2681–2690. PMLR, 2019. 6
work page 2019
-
[15]
One step diffusion via shortcut models.arXiv preprint arXiv:2410.12557, 2024
Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel. One step diffusion via shortcut models.arXiv preprint arXiv:2410.12557, 2024. 9
-
[16]
Drift-Based Policy Optimization: Native One-Step Policy Learning for Online Robot Control
Yuxuan Gao, Yedong Shen, Shiqi Zhang, Wenhao Yu, Yifan Duan, Jiajia Wu, Jiajun Deng, Yanyong Zhang, et al. Drift-based policy optimization: Native one-step policy learning for online robot control.arXiv preprint arXiv:2604.03540, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Learning generative models with sinkhorn divergences
Aude Genevay, Gabriel Peyré, and Marco Cuturi. Learning generative models with sinkhorn divergences. InInternational Conference on Artificial Intelligence and Statistics, pages 1608–
- [18]
-
[19]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025. 3, 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Improved Mean Flows: On the Challenges of Fastforward Generative Models
Zhengyang Geng, Yiyang Lu, Zongze Wu, Eli Shechtman, J Zico Kolter, and Kaiming He. Improved mean flows: On the challenges of fastforward generative models.arXiv preprint arXiv:2512.02012, 2025. 3, 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Generative adversarial nets.NeurIPS, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.NeurIPS, 2014. 2, 3 12
work page 2014
-
[22]
Improved training of wasserstein gans.Advances in neural information processing systems, 30,
Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C Courville. Improved training of wasserstein gans.Advances in neural information processing systems, 30,
-
[23]
Mathis Hardion and Théo Lacombe. The wasserstein gradient flow of the sinkhorn divergence between gaussian distributions.arXiv preprint arXiv:2602.10726, 2026. 5
-
[24]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InCVPR, pages 770–778, 2016. 10
work page 2016
-
[25]
Sinkhorn-drifting generative models.arXiv preprint arXiv:2603.12366, 2026
Ping He, Om Khangaonkar, Hamed Pirsiavash, Yikun Bai, and Soheil Kolouri. Sinkhorn-drifting generative models.arXiv preprint arXiv:2603.12366, 2026. 3
-
[26]
GANs trained by a two time-scale update rule converge to a local nash equilibrium.NeurIPS,
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local nash equilibrium.NeurIPS,
-
[27]
Denoising diffusion probabilistic models.NeurIPS, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.NeurIPS, 33:6840–6851, 2020. 1, 2
work page 2020
-
[28]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 8
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Richard Jordan, David Kinderlehrer, and Felix Otto. The variational formulation of the fokker– planck equation.SIAM journal on mathematical analysis, 29(1):1–17, 1998. 3
work page 1998
-
[30]
Scaling up GANs for text-to-image synthesis
Minguk Kang, Jun-Yan Zhu, Richard Zhang, Jaesik Park, Eli Shechtman, Sylvain Paris, and Taesung Park. Scaling up GANs for text-to-image synthesis. InCVPR, pages 10124–10134,
-
[31]
Marlowe: Stanford’s gpu-based computational instrument, 2025
Craig Kapfer, Kurt Stine, Balasubramanian Narasimhan, Christopher Mentzel, and Emmanuel Candes. Marlowe: Stanford’s gpu-based computational instrument, 2025. 11
work page 2025
-
[32]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019. 10
work page 2019
-
[33]
A unified view of drifting and score-based models.arXiv preprint arXiv:2603.07514, 2026
Chieh-Hsin Lai, Bac Nguyen, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yuki Mitsufuji, Stefano Ermon, and Molei Tao. A unified view of drifting and score-based models.arXiv preprint arXiv:2603.07514, 2026. 3
-
[34]
Autoregressive image generation without vector quantization.NeurIPS, 37:56424–56445, 2024
Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. Autoregressive image generation without vector quantization.NeurIPS, 37:56424–56445, 2024. 9
work page 2024
-
[35]
Generative moment matching networks
Yujia Li, Kevin Swersky, and Rich Zemel. Generative moment matching networks. InICML, pages 1718–1727. PMLR, 2015. 5, 30
work page 2015
-
[36]
Generative Drifting for Conditional Medical Image Generation
Zirong Li, Siyuan Mei, Weiwen Wu, Andreas Maier, Lina Gölz, and Yan Xia. Generative drifting for conditional medical image generation.arXiv preprint arXiv:2604.19736, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Shanchuan Lin, Ceyuan Yang, Zhijie Lin, Hao Chen, and Haoqi Fan. Adversarial flow models. arXiv preprint arXiv:2511.22475, 2025. 3, 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022. 1, 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022. 1, 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models
Cheng Lu and Yang Song. Simplifying, stabilizing and scaling continuous-time consistency models.arXiv preprint arXiv:2410.11081, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[41]
Jin Ma, Ying Tan, and Renyuan Xu. Schrödinger bridge for generative ai: Soft-constrained formulation and convergence analysis.arXiv preprint arXiv:2510.11829, 2025. 3 13
-
[42]
SiT: Exploring flow and diffusion-based generative models with scalable interpolant transformers
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. SiT: Exploring flow and diffusion-based generative models with scalable interpolant transformers. InECCV, pages 23–40. Springer, 2024. 9, 31, 32
work page 2024
-
[43]
Petr Mokrov, Alexander Korotin, Lingxiao Li, Aude Genevay, Justin M Solomon, and Evgeny Burnaev. Large-scale wasserstein gradient flows.Advances in Neural Information Processing Systems, 34:15243–15256, 2021. 3
work page 2021
-
[44]
Entropic optimal transport: Convergence of potentials
Marcel Nutz and Johannes Wiesel. Entropic optimal transport: Convergence of potentials. Probability Theory and Related Fields, 184(1):401–424, 2022. 6
work page 2022
-
[45]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InCVPR, pages 4195–4205, 2023. 8, 9
work page 2023
-
[46]
Now Foundations and Trends, 2019
Gabriel Peyré and Marco Cuturi.Computational optimal transport: With applications to data science. Now Foundations and Trends, 2019. 6
work page 2019
-
[47]
Adversarial latent autoen- coders
Stanislav Pidhorskyi, Donald A Adjeroh, and Gianfranco Doretto. Adversarial latent autoen- coders. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14104–14113, 2020. 10
work page 2020
-
[48]
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks.arXiv preprint arXiv:1511.06434, 2015. 2, 3
work page internal anchor Pith review arXiv 2015
-
[49]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InCVPR, pages 10684–10695, 2022. 8
work page 2022
-
[50]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[51]
Multistep distillation of diffusion models via moment matching.NeurIPS, 37:36046–36070, 2024
Tim Salimans, Thomas Mensink, Jonathan Heek, and Emiel Hoogeboom. Multistep distillation of diffusion models via moment matching.NeurIPS, 37:36046–36070, 2024. 2
work page 2024
-
[52]
StyleGAN-XL: Scaling StyleGAN to large diverse datasets
Axel Sauer, Katja Schwarz, and Andreas Geiger. StyleGAN-XL: Scaling StyleGAN to large diverse datasets. InSIGGRAPH, pages 1–10, 2022. 9
work page 2022
-
[53]
Richard Sinkhorn and Paul Knopp. Concerning nonnegative matrices and doubly stochastic matrices.Pacific Journal of Mathematics, 21(2):343–348, 1967. 7
work page 1967
-
[54]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InICML, pages 2256–2265. pmlr, 2015. 1, 2
work page 2015
-
[55]
Improved Tech- niques for Training Consistency Models
Yang Song and Prafulla Dhariwal. Improved techniques for training consistency models.arXiv preprint arXiv:2310.14189, 2023. 2, 9
-
[56]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. 2023. 2, 3
work page 2023
-
[57]
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019. 1
work page 2019
-
[58]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[59]
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.NeurIPS, 37:84839–84865,
-
[60]
Wasserstein auto- encoders.arXiv preprint arXiv:1711.01558, 2017
Ilya Tolstikhin, Olivier Bousquet, Sylvain Gelly, and Bernhard Schoelkopf. Wasserstein auto- encoders.arXiv preprint arXiv:1711.01558, 2017. 3 14
-
[61]
Erkan Turan and Maks Ovsjanikov. Generative drifting is secretly score matching: a spectral and variational perspective.arXiv preprint arXiv:2603.09936, 2026. 3
-
[62]
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Pro- lificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. Advances in neural information processing systems, 36:8406–8441, 2023. 2
work page 2023
-
[63]
Zidong Wang, Yiyuan Zhang, Xiaoyu Yue, Xiangyu Yue, Yangguang Li, Wanli Ouyang, and Lei Bai. Transition models: Rethinking the generative learning objective.arXiv preprint arXiv:2509.04394, 2025. 9
-
[64]
Yao Xie and Xiuyuan Cheng. Flow-based generative models as iterative algorithms in probability space.arXiv preprint arXiv:2502.13394, 2025. 3
-
[65]
Jingfeng Yao, Bin Yang, and Xinggang Wang. Reconstruction vs. generation: Taming opti- mization dilemma in latent diffusion models. InCVPR, pages 15703–15712, 2025. 9, 31, 32
work page 2025
-
[66]
Improved distribution matching distillation for fast image synthesis
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T Freeman. Improved distribution matching distillation for fast image synthesis. Advances in neural information processing systems, 37:47455–47487, 2024. 2
work page 2024
-
[67]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In CVPR, pages 6613–6623, 2024. 2
work page 2024
-
[68]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think.arXiv preprint arXiv:2410.06940, 2024. 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
AlphaFlow: Understanding and improving MeanFlow models
Huijie Zhang, Aliaksandr Siarohin, Willi Menapace, Michael Vasilkovsky, Sergey Tulyakov, Qing Qu, and Ivan Skorokhodov. AlphaFlow: Understanding and improving MeanFlow models. arXiv preprint arXiv:2510.20771, 2025. 9
-
[70]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representation autoencoders.arXiv preprint arXiv:2510.11690, 2025. 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Linqi Zhou, Stefano Ermon, and Jiaming Song. Inductive moment matching.arXiv preprint arXiv:2503.07565, 2025. 2, 3, 30 15 Appendix Table of Contents A Proofs 16 A.1 Complete statement and the proof of Theorem 3.1 . . . . . . . . . . . . . . . . 16 B Additional discussions 22 B.1 Wasserstein gradient flows of energy functionals . . . . . . . . . . . . . . ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.