Recognition: 2 theorem links
· Lean TheoremEvoNav: Evolutionary Reward Function Design for Robot Navigation with Large Language Models
Pith reviewed 2026-05-13 05:15 UTC · model grok-4.3
The pith
EvoNav uses large language models to evolve reward functions that produce more effective robot navigation policies than manual designs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
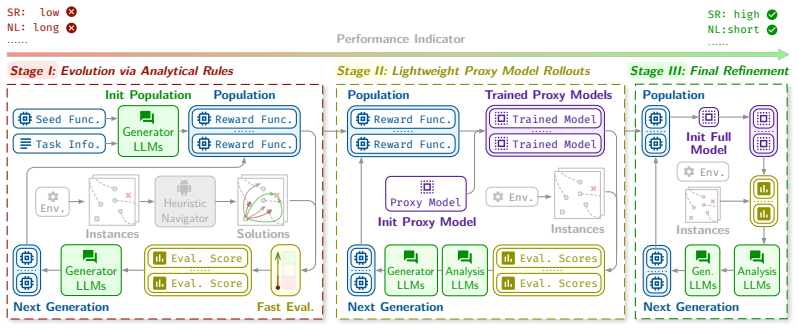
EvoNav is an evolutionary framework that leverages large language models to generate and refine reward functions for robot navigation tasks. Candidate rewards are evaluated through a progressive three-stage warm-up-boost procedure that moves from cheap analytical surrogates and small datasets to lightweight simulations and finally to complete policy training only for high-ranking proposals. This yields navigation policies that achieve higher effectiveness than those obtained from hand-crafted rewards or existing state-of-the-art reward design methods.
What carries the argument
Evolutionary search over LLM-proposed reward functions, ranked by a three-stage warm-up-boost evaluation that advances from analytic proxies to full reinforcement learning training.
If this is right
- Robot navigation policies reach higher success rates in dynamic human environments without manual reward tuning.
- The computational cost of exploring reward designs drops because most candidates are discarded before full training.
- Reward functions become easier to adapt when the environment or robot changes, since new candidates can be proposed and filtered by the same staged process.
- Fewer instances of suboptimal policies arise from hidden inductive biases that are hard to audit in hand-crafted rewards.
Where Pith is reading between the lines
- The same staged evaluation idea could reduce compute in other reinforcement learning domains where reward specification is the main bottleneck.
- If large language models tend to propose similar reward structures, the evolutionary mutations would still allow broader exploration than static hand-design.
- Real-robot deployment would provide a direct test of whether simulation-based rankings from the three stages transfer to physical performance.
Load-bearing premise
The three-stage evaluation procedure accurately ranks reward candidates so that strong early-stage performance predicts strong performance after full policy training.
What would settle it
Observe whether a reward function that ranks in the top tier after the warm-up and boost stages still produces low-success navigation policies when used for complete reinforcement learning training.
Figures




read the original abstract
Robot navigation is a crucial task with applications to social robots in dynamic human environments. While Reinforcement Learning (RL) has shown great promise for this problem, the policy quality is highly sensitive to the specification of reward functions. Hand-crafted rewards require substantial domain expertise and embed inductive biases that are difficult to audit or adapt, limiting their effectiveness and leading to suboptimal performance. In this paper, we propose EvoNav, an evolutionary framework that automates the design of robot navigation reward functions via large language models (LLMs). To overcome prohibitively costly policy training, EvoNav evaluates each candidate proposal from the LLM via a progressive three-stage warm-up-boost procedure. EvoNav advances from analytical proxies with low-cost surrogates, such as small datasets and analytic rules, to lightweight rollouts and, finally, to full policy training, enabling computationally efficient exploration under effective feedback. Experiment results show that EvoNav produces more effective navigation policies than manually designed RL rewards and state-of-the-art reward design methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EvoNav, an evolutionary framework that leverages large language models to automatically design reward functions for reinforcement learning in robot navigation tasks. It introduces a progressive three-stage warm-up-boost evaluation procedure—starting with low-cost analytical proxies and small datasets, advancing to lightweight rollouts, and culminating in full policy training—to enable efficient search over reward candidates. The central claim is that this approach yields more effective navigation policies than manually designed RL rewards and state-of-the-art reward design methods.
Significance. If the experimental superiority holds after proper validation of the evaluation stages, the work could meaningfully advance automated reward engineering in robotics RL, a persistent bottleneck that currently demands substantial domain expertise. The combination of LLM-driven proposal generation with a staged surrogate evaluation is a practical contribution that could reduce manual tuning while improving policy quality in dynamic environments.
major comments (2)
- [Abstract] Abstract: the assertion that 'Experiment results show that EvoNav produces more effective navigation policies than manually designed RL rewards and state-of-the-art reward design methods' supplies no quantitative metrics, baselines, statistical tests, or experimental details, rendering it impossible to judge whether the data support the central claim.
- [Methods (three-stage procedure)] Three-stage warm-up-boost procedure (described in the abstract and methods): the evolutionary search depends on early-stage proxies (analytical rules, small datasets, lightweight rollouts) producing rankings that correlate with final performance after full RL policy training. No correlation coefficients, rank-preservation statistics, or ablation results are reported to confirm that top-k candidates after stage 2 remain top-k after stage 3; without this evidence the reported superiority could be an artifact of proxy misalignment.
minor comments (1)
- [Abstract] Abstract: a brief statement of the specific navigation environments or tasks used for evaluation would help readers assess the scope of the claimed improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the presentation and validation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'Experiment results show that EvoNav produces more effective navigation policies than manually designed RL rewards and state-of-the-art reward design methods' supplies no quantitative metrics, baselines, statistical tests, or experimental details, rendering it impossible to judge whether the data support the central claim.
Authors: We agree that the abstract would be strengthened by including concise quantitative support for the central claim. In the revised version, we will update the abstract to briefly report key metrics such as average success rate improvements (e.g., +X% over baselines), navigation efficiency gains, and the specific baselines compared, while keeping the abstract within standard length limits. This will provide readers with immediate evidence to assess the results without requiring full experimental details. revision: yes
-
Referee: [Methods (three-stage procedure)] Three-stage warm-up-boost procedure (described in the abstract and methods): the evolutionary search depends on early-stage proxies (analytical rules, small datasets, lightweight rollouts) producing rankings that correlate with final performance after full RL policy training. No correlation coefficients, rank-preservation statistics, or ablation results are reported to confirm that top-k candidates after stage 2 remain top-k after stage 3; without this evidence the reported superiority could be an artifact of proxy misalignment.
Authors: The referee correctly notes that explicit validation of the proxy ranking correlation is missing from the current manuscript. While the three-stage procedure is described and final results are reported, we did not include correlation analysis or rank-preservation ablations. In the revision, we will add a dedicated analysis (in the methods or an appendix) reporting Spearman's rank correlation coefficients between stage-2 lightweight rollout rankings and stage-3 full-training outcomes, along with statistics on how frequently top-k candidates are preserved. We will also include ablation results showing the impact of omitting early stages. These additions will directly address the concern about potential proxy misalignment. revision: yes
Circularity Check
No significant circularity in empirical search framework
full rationale
The paper describes an evolutionary algorithm that uses LLMs to propose reward functions for RL-based robot navigation and evaluates them via a three-stage warm-up-boost procedure. No equations, first-principles derivations, or predictions are presented that reduce to their own inputs by construction. The method is an empirical search procedure whose claims rest on experimental comparisons rather than self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations. The three-stage evaluation is a computational heuristic for ranking candidates; its soundness is an empirical question addressed by the reported results, not a tautology.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearEvoNav evaluates each candidate proposal from the LLM via a progressive three-stage warm-up-boost procedure... analytical proxies... lightweight rollouts... full policy training
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclearScore1(rθ) = 1/M Σ Corr(rank_rules, rank_rθ) (Spearman rank correlation on pre-collected trajectories)
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Matteo Biagiola and Paolo Tonella. Testing of deep reinforcement learning agents with surrogate models.arXiv preprint arXiv:2305.12751, 2023
-
[3]
Changan Chen, Yuejiang Liu, Sven Kreiss, and Alexandre Alahi. Crowd-robot interaction: Crowd-aware robot navigation with attention-based deep reinforcement learning. In2019 International Conference on Robotics and Automation (ICRA), pages 6015–6022. IEEE, 2019
work page 2019
-
[4]
Yifang Chen, Shuohang Wang, Ziyi Yang, Hiteshi Sharma, Nikos Karampatziakis, Donghan Yu, Kevin Jamieson, Simon Shaolei Du, and Yelong Shen. Cost-effective proxy reward model construction with on-policy and active learning.arXiv preprint arXiv:2407.02119, 2024
-
[5]
Reinforcement learning and the reward engineering principle.2014 AAAI Spring Symposium Series, 2014
Daniel Dewey. Reinforcement learning and the reward engineering principle.2014 AAAI Spring Symposium Series, 2014
work page 2014
-
[6]
Gabriel Dulac-Arnold, Nir Levine, Daniel J Mankowitz, Jerry Li, Cosmin Paduraru, Sven Gowal, and Todd Hester. Challenges of real-world reinforcement learning: definitions, benchmarks and analysis.Machine Learning, 110:2419–2468, 2021
work page 2021
-
[7]
Motion planning among dynamic, decision- making agents with deep reinforcement learning
Michael Everett, Yu Fan Chen, and Jonathan P How. Motion planning among dynamic, decision- making agents with deep reinforcement learning. In2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3052–3059. IEEE, 2018
work page 2018
-
[8]
Engineering design via surrogate modelling: a practical guide.John Wiley & Sons, 2008
Alexander Forrester, Andras Sobester, and Andy Keane. Engineering design via surrogate modelling: a practical guide.John Wiley & Sons, 2008
work page 2008
-
[9]
Connecting large language models with evolutionary algorithms yields powerful prompt optimizers
Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, and Yujiu Yang. Connecting large language models with evolutionary algorithms yields powerful prompt optimizers. InICLR, 2024
work page 2024
-
[10]
Dylan Hadfield-Menell, Stuart J Russell, Pieter Abbeel, and Anca Dragan. Cooperative inverse reinforcement learning.Advances in neural information processing systems, 29, 2016
work page 2016
-
[11]
Social force model for pedestrian dynamics.Physical Review E, 51(5):4282–4286, May 1995
Dirk Helbing and Péter Molnár. Social force model for pedestrian dynamics.Physical Review E, 51(5):4282–4286, May 1995. ISSN 1095-3787
work page 1995
-
[12]
Deep reinforcement learning that matters
Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, and David Meger. Deep reinforcement learning that matters. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[13]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
VRPAgent: LLM-driven discovery of heuristic operators for vehicle routing problems
André Hottung, Federico Berto, Chuanbo Hua, Nayeli Gast Zepeda, Daniel Wetzel, Michael Römer, Haoran Ye, Davide Zago, Michael Poli, Stefano Massaroli, Jinkyoo Park, and Kevin Tierney. VRPAgent: LLM-driven discovery of heuristic operators for vehicle routing problems. arXiv preprint arXiv:2510.07073, 2025. URLhttps://arxiv.org/abs/2510.07073
-
[15]
Liu Huajian, Dong Wei, Mao Shouren, Wang Chao, and Gao Yongzhuo. Sample-efficient learning-based dynamic environment navigation with transferring experience from optimization- based planner.IEEE Robotics and Automation Letters, 9(8):7055–7062, 2024
work page 2024
-
[16]
Xing Hui Jing, Xin Xiong, Fu Hao Li, Tao Zhang, and Long Zeng. A two-stage reinforcement learning approach for robot navigation in long-range indoor dense crowd environments. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5489–5496. IEEE, 2024. 10
work page 2024
-
[17]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[18]
Reward design with language models.arXiv preprint arXiv:2303.00001, 2023
Minae Kwon, Sang Michael Xie, Kalesha Bullard, and Dorsa Sadigh. Reward design with language models.arXiv preprint arXiv:2303.00001, 2023
-
[19]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles, SOSP ’23, page 611–626. Association for Computing Machinery, 2023. URLhttps://doi....
-
[20]
Anh Vu Le et al. A comprehensive review of mobile robot navigation using deep reinforcement learning algorithms in crowded environments.Journal of Intelligent & Robotic Systems, 90: 1–23, 2024
work page 2024
-
[21]
Auto mc-reward: Automated dense reward design with large language models for minecraft
Hao Li, Xue Yang, Zhaokai Wang, Xizhou Zhu, Jie Zhou, Yu Qiao, Xiaogang Wang, Hongsheng Li, Lewei Lu, and Jifeng Dai. Auto mc-reward: Automated dense reward design with large language models for minecraft. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16426–16435, 2024
work page 2024
-
[22]
Jiachen Li, Chuanbo Hua, Jinkyoo Park, Hengbo Ma, Victoria Dax, and Mykel J. Kochenderfer. EvolveHypergraph: Group-aware dynamic relational reasoning for trajectory prediction.arXiv preprint arXiv:2208.05470, 2022. URLhttps://arxiv.org/abs/2208.05470
-
[23]
Jiachen Li, Chuanbo Hua, Jianpeng Yao, Hengbo Ma, Jinkyoo Park, Victoria Dax, and Mykel J. Kochenderfer. Multi-agent dynamic relational reasoning for social robot navigation.arXiv preprint arXiv:2401.12275, 2024. URLhttps://arxiv.org/abs/2401.12275
-
[24]
Subin Lin and Chuanbo Hua. BuildEvo: Designing building energy consumption forecasting heuristics via LLM-driven evolution.arXiv preprint arXiv:2507.12207, 2025. URL https: //arxiv.org/abs/2507.12207
-
[25]
Fei Liu, Xialiang Tong, Mingxuan Yuan, Xi Lin, Fu Luo, Zhenkun Wang, Zhichao Lu, and Qingfu Zhang. Evolution of heuristics: Towards efficient automatic algorithm design using large language model.International Conference on Machine Learning, 2024
work page 2024
-
[26]
Llm4ad: A platform for algorithm design with large language model
Fei Liu, Rui Zhang, Zhuoliang Xie, Rui Sun, Kai Li, Xi Lin, Zhenkun Wang, Zhichao Lu, and Qingfu Zhang. Llm4ad: A platform for algorithm design with large language model. 2024. URLhttps://arxiv.org/abs/2412.17287
-
[27]
Decentralized structural-rnn for robot crowd navigation with deep reinforcement learning
Shuijing Liu, Peixin Chang, Weihang Liang, Neeloy Chakraborty, and Katherine Driggs- Campbell. Decentralized structural-rnn for robot crowd navigation with deep reinforcement learning. In2021 IEEE international conference on robotics and automation (ICRA), pages 3517–3524. IEEE, 2021
work page 2021
-
[28]
Livingston McPherson, Junyi Geng, and Katherine Driggs-Campbell
Shuijing Liu, Peixin Chang, Zhe Huang, Neeloy Chakraborty, Kaiwen Hong, Weihang Liang, D. Livingston McPherson, Junyi Geng, and Katherine Driggs-Campbell. Intention aware robot crowd navigation with attention-based interaction graph, 2023. URL https://arxiv.org/ abs/2203.01821
-
[29]
Eureka: Human-Level Reward Design via Coding Large Language Models
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Eureka: Human-level reward design via coding large language models.arXiv preprint arXiv:2310.12931, 2023
work page internal anchor Pith review arXiv 2023
-
[30]
Kohei Matsumoto, Yuki Hyodo, and Ryo Kurazume. Crowd-aware robot navigation with switching between learning-based and rule-based methods using normalizing flows. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4823–4830. IEEE, 2024
work page 2024
-
[31]
Core challenges of social robot navigation: A survey, 2021
Christoforos Mavrogiannis, Francesca Baldini, Allan Wang, Dapeng Zhao, Pete Trautman, Aaron Steinfeld, and Jean Oh. Core challenges of social robot navigation: A survey, 2021. URL https://arxiv.org/abs/2103.05668. 11
-
[32]
Julio Montero et al. Memory-driven deep-reinforcement learning for autonomous robot naviga- tion in partially observable environments.Engineering Science and Technology, an International Journal, 2025
work page 2025
-
[33]
Fernandez, Swayamjit Saha, Sudip Mittal, Jingdao Chen, Nisha Pillai, and Shahram Rahimi
Subash Neupane, Shaswata Mitra, Ivan A. Fernandez, Swayamjit Saha, Sudip Mittal, Jingdao Chen, Nisha Pillai, and Shahram Rahimi. Security considerations in ai-robotics: A survey of current methods, challenges, and opportunities, 2024. URL https://arxiv.org/abs/2310. 08565
work page 2024
-
[34]
Policy invariance under reward transforma- tions: Theory and application to reward shaping
Andrew Y Ng, Daishi Harada, and Stuart Russell. Policy invariance under reward transforma- tions: Theory and application to reward shaping. InIcml, volume 99, pages 278–287. Citeseer, 1999
work page 1999
-
[35]
Benjamin Peherstorfer, Karen Willcox, and Max Gunzburger. Survey of multifidelity methods in uncertainty propagation, inference, and optimization.Siam Review, 60(3):550–591, 2018
work page 2018
-
[36]
Rethinking social robot navigation: Leveraging the best of two worlds
Amir Hossain Raj, Zichao Hu, Haresh Karnan, Rohan Chandra, Amirreza Payandeh, Luisa Mao, Peter Stone, Joydeep Biswas, and Xuesu Xiao. Rethinking social robot navigation: Leveraging the best of two worlds. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 16330–16337. IEEE, 2024
work page 2024
-
[37]
Phani Teja Singamaneni, Pilar Bachiller-Burgos, Luis J Manso, Anaïs Garrell, Alberto Sanfeliu, Anne Spalanzani, and Rachid Alami. A survey on socially aware robot navigation: Taxonomy and future challenges.The International Journal of Robotics Research, 2024
work page 2024
-
[38]
Defining and characterizing reward hacking.arXiv preprint arXiv:2209.13085, 2022
Joar Skalse, Nikolaus Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and characterizing reward hacking.arXiv preprint arXiv:2209.13085, 2022
-
[39]
Shengjie Sun, Runze Liu, Jiafei Lyu, Jing-Wen Yang, Liangpeng Zhang, and Xiu Li. A large language model-driven reward design framework via dynamic feedback for reinforcement learning.Knowledge-Based Systems, 326:114065, 2025
work page 2025
-
[40]
HiMAP: Learning heuristics-informed policies for large-scale multi-agent pathfinding
Huijie Tang, Federico Berto, Zihan Ma, Chuanbo Hua, Kyuree Ahn, and Jinkyoo Park. HiMAP: Learning heuristics-informed policies for large-scale multi-agent pathfinding. InProceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems (AAMAS),
- [41]
-
[42]
Reciprocal velocity obstacles for real-time multi-agent navigation
Jur Van den Berg, Ming Lin, and Dinesh Manocha. Reciprocal velocity obstacles for real-time multi-agent navigation. In2008 IEEE International Conference on Robotics and Automation, pages 1928–1935. IEEE, 2008
work page 1928
-
[43]
Guy, Ming Lin, and Dinesh Manocha
Jur van den Berg, Stephen J. Guy, Ming Lin, and Dinesh Manocha. Reciprocal n-body collision avoidance. In Cédric Pradalier, Roland Siegwart, and Gerhard Hirzinger, editors,Robotics Research, pages 3–19, Berlin, Heidelberg, 2011. Springer Berlin Heidelberg. ISBN 978-3-642- 19457-3
work page 2011
-
[44]
Reciprocal n-body collision avoidance
Jur Van den Berg, Stephen J Guy, Ming Lin, and Dinesh Manocha. Reciprocal n-body collision avoidance. InRobotics Research, pages 3–19. Springer, 2011
work page 2011
-
[45]
Tianbao Xie, Siheng Zhao, Chen Henry Wu, Yitao Liu, Qian Luo, Victor Zhong, Yanchao Yang, and Tao Yu. Text2reward: Reward shaping with language models for reinforcement learning. arXiv preprint arXiv:2309.11489, 2023
-
[46]
Haoran Ye, Jiarui Wang, Zhiguang Cao, Federico Berto, Chuanbo Hua, Haeyeon Kim, Jinkyoo Park, and Guojie Song. Reevo: Large language models as hyper-heuristics with reflective evolution.Advances in neural information processing systems, 37:43571–43608, 2024
work page 2024
-
[47]
Language to rewards for robotic skill synthesis
Wenhao Yu, Nimrod Gileadi, Chuyuan Fu, Sean Kirmani, Kuang-Huei Lee, Montse Gonzalez Arenas, Hao-Tien Lewis Chiang, Tom Erez, Leonard Hasenclever, Jan Humplik, et al. Language to rewards for robotic skill synthesis.arXiv preprint arXiv:2306.08647, 2023
-
[48]
Zhikai Zhao, Chuanbo Hua, Federico Berto, Kanghoon Lee, Zihan Ma, Jiachen Li, and Jinkyoo Park. TrajEvo: Trajectory prediction heuristics design via LLM-driven evolution.arXiv preprint arXiv:2508.05616, 2025. URLhttps://arxiv.org/abs/2508.05616. 12
-
[49]
Xinyu Zhou, Songhao Piao, Wenzheng Chi, Liguo Chen, and Wei Li. Her-drl: Heterogeneous relational deep reinforcement learning for single-robot and multi-robot crowd navigation.IEEE Robotics and Automation Letters, 2025
work page 2025
-
[50]
"" Args: - inst: single instance, with the shape of - traj: single trajectory
Yuanyang Zhu, Zhi Wang, Chunlin Chen, and Daoyi Dong. Rule-based reinforcement learning for efficient robot navigation with space reduction.IEEE/ASME Transactions on Mechatronics, 27(2):846–857, 2021. 13 A Algorithm Algorithm 1EvoNav Framework 1: Input:LLM, seed function, dataset D, population size N, Stage I generations G1, Stage II roundsG 2, Stage III ...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.