Recognition: no theorem link
When Policy Entropy Constraint Fails: Preserving Diversity in Flow-based RLHF via Perceptual Entropy
Pith reviewed 2026-05-13 05:45 UTC · model grok-4.3
The pith
In flow-based RLHF for text-to-image models, policy entropy remains constant while perceptual diversity collapses, requiring perceptual entropy constraints to restore balance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
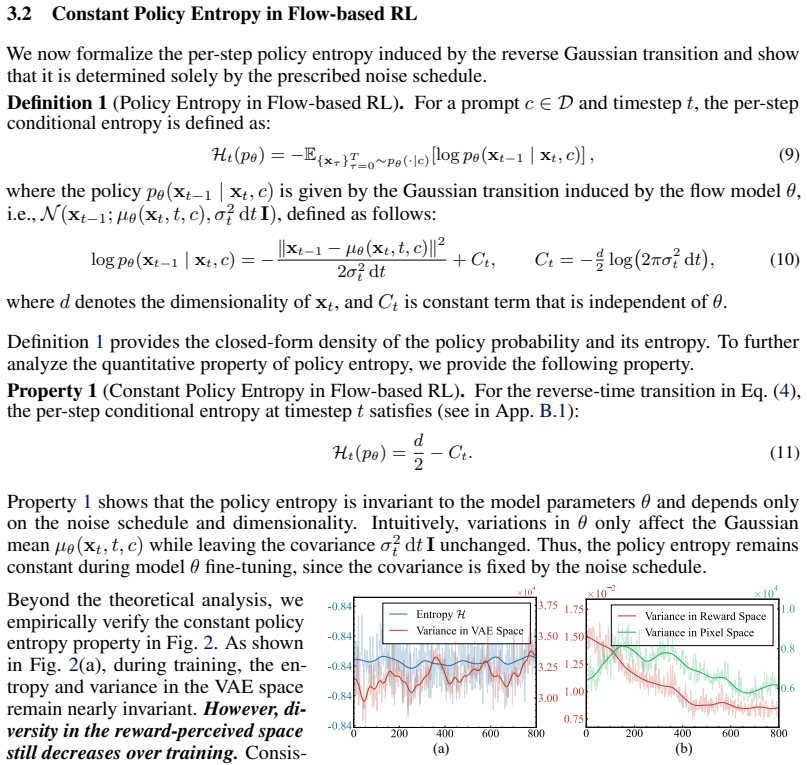
The central discovery is that policy entropy in flow models does not change during RLHF because of the fixed noise schedule, even as the generated images lose perceptual diversity through mode-seeking optimization. Perceptual entropy is proposed as an alternative that tracks diversity in perceptual spaces while satisfying entropy axioms. This leads to two methods, Perceptual Entropy Constraint and Perceptual Constraints on Generation Space, which are shown to enhance both quality and diversity metrics in practice.
What carries the argument
Perceptual entropy, computed as the entropy of the policy distribution projected or evaluated in a perceptual embedding space.
If this is right
- Perceptual Entropy Constraint yields the highest quality-diversity score of 0.734 compared to the baseline of 0.366.
- Combining it with other constraints achieves an average diversity of 0.989 against the baseline's 0.047.
- The gains hold consistently for two different base models, both neural and rule-based reward models, and three perceptual spaces.
- Standard policy entropy regularization cannot prevent the model from converging to narrow high-reward regions in perceptual space.
Where Pith is reading between the lines
- Similar constant-entropy behavior may limit standard regularization in other flow or diffusion generative models during preference alignment.
- Extending perceptual spaces to include semantic or stylistic features could further tailor diversity preservation to specific applications.
Load-bearing premise
The chosen perceptual spaces will continue to reflect meaningful diversity that aligns with human preferences across different tasks and models without causing unintended reductions in other qualities.
What would settle it
Training the model with the proposed perceptual constraints and measuring no corresponding increase in diversity according to independent perceptual metrics or human studies would show that the constraints do not achieve the intended preservation.
Figures





read the original abstract
RLHF is widely used to align flow-matching text-to-image models with human preferences, but often leads to severe diversity collapse after fine-tuning. In RL, diversity is often assumed to correlate with policy entropy, motivating entropy regularization. However, we show this intuition breaks in flow models: policy entropy remains constant, even while perceptual diversity collapses. We explain this mismatch both theoretically and empirically: the constant entropy arises from the fixed, pre-defined noise schedule, while the diversity collapse is driven by the mode-seeking nature of policy gradients. As a result, policy entropy fails to prevent the model from converging to a narrow high-reward region in the perceptual space. To this end, we introduce perceptual entropy that captures diversity in a perceptual space and maintains the property of standard entropy. Building upon this insight, we propose two entropy-regularized strategies, Perceptual Entropy Constraint and Perceptual Constraints on Generation Space, to preserve perceptual diversity and improve the quality. Experiments across two base models, neural and rule-based rewards, and three perceptual spaces demonstrate consistent gains in the quality-diversity trade-off; PEC achieves the best overall score of 0.734 (vs. baseline's 0.366); a complementary setting of PEC further reaches a diversity average of 0.989 (vs. baseline's 0.047). Our project page (https://xiaofeng-tan.github.io/projects/PEC) is publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that standard policy entropy regularization fails to preserve diversity in flow-matching text-to-image RLHF because policy entropy remains constant (due to the fixed pre-defined noise schedule) while perceptual diversity collapses (due to mode-seeking policy gradients). It introduces perceptual entropy as a diversity measure in perceptual spaces that preserves standard entropy properties, and proposes two regularization strategies—Perceptual Entropy Constraint (PEC) and Perceptual Constraints on Generation Space—to improve the quality-diversity trade-off, with experiments across two base models, neural/rule-based rewards, and three perceptual spaces reporting gains such as 0.734 vs. baseline 0.366 overall score and 0.989 vs. 0.047 diversity average.
Significance. If the claimed mismatch between constant policy entropy and collapsing perceptual diversity is rigorously established and the perceptual entropy constraints generalize without side effects, the work would be significant for RLHF in flow-based generative models, offering a targeted fix for diversity collapse that standard entropy regularization cannot address. The multi-setting empirical evaluation and public project page provide some support for practical utility and reproducibility.
major comments (2)
- [Abstract / theoretical analysis] Abstract and theoretical explanation: The central claim that policy entropy remains constant due to the fixed noise schedule does not engage with the change-of-variables formula for differential entropy under a learned flow. In flow-matching models the output entropy equals base entropy plus the integral of the divergence of the time-dependent vector field along trajectories; RLHF updates to the vector field should therefore alter output entropy unless the divergence is provably invariant, which is not shown.
- [Method] Method section on perceptual entropy: The definition of perceptual entropy is stated to 'capture diversity in a perceptual space and maintain the property of standard entropy,' yet no explicit functional form, proof of non-negativity or concavity, or comparison to the standard differential entropy appears. Without these, it is unclear whether the quantity is independent of the reward model or reduces to a fitted heuristic, weakening the justification for the proposed constraints.
minor comments (2)
- [Experiments] Experiments: Reported aggregate scores (0.734 vs. 0.366; 0.989 vs. 0.047) are given without error bars, number of random seeds, or statistical tests, making it impossible to judge whether the quality-diversity improvements are reliable.
- [Abstract] Abstract: The two proposed strategies are named but not briefly characterized, which would improve immediate readability for readers scanning the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below with clarifications on our theoretical analysis and definitions. Where the comments identify gaps in rigor or explicitness, we indicate that revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract / theoretical analysis] Abstract and theoretical explanation: The central claim that policy entropy remains constant due to the fixed noise schedule does not engage with the change-of-variables formula for differential entropy under a learned flow. In flow-matching models the output entropy equals base entropy plus the integral of the divergence of the time-dependent vector field along trajectories; RLHF updates to the vector field should therefore alter output entropy unless the divergence is provably invariant, which is not shown.
Authors: We appreciate the referee's observation regarding the change-of-variables formula. In our analysis, 'policy entropy' specifically denotes the entropy of the fixed base noise distribution at the input to the flow, which is invariant because the noise schedule is pre-defined and unchanged by RLHF updates to the vector field. The perceptual diversity collapse, by contrast, arises from the mode-seeking behavior of the policy gradient in the output space. We acknowledge that a full accounting of output differential entropy must incorporate the divergence integral. In the revised manuscript we will expand the theoretical section to explicitly reference the change-of-variables formula, derive the relationship between input entropy and perceptual-space diversity under our RLHF objective, and discuss why the divergence term does not counteract the observed mode collapse in practice. This will strengthen the justification for why standard policy-entropy regularization is insufficient. revision: yes
-
Referee: [Method] Method section on perceptual entropy: The definition of perceptual entropy is stated to 'capture diversity in a perceptual space and maintain the property of standard entropy,' yet no explicit functional form, proof of non-negativity or concavity, or comparison to the standard differential entropy appears. Without these, it is unclear whether the quantity is independent of the reward model or reduces to a fitted heuristic, weakening the justification for the proposed constraints.
Authors: We thank the referee for noting the need for greater formality. Perceptual entropy is defined as the differential entropy of the push-forward distribution of generated samples under a fixed perceptual embedding map (e.g., CLIP or VGG features). Its explicit form is H_perp = -E_{x~p_gen}[log p_perp(f(x))], where f is the embedding function and p_perp is the density estimated in the perceptual space; because the embedding is fixed and independent of the reward model, the quantity inherits non-negativity and concavity from standard differential entropy on the embedded manifold. In the revised method section we will state this functional form explicitly, include a short derivation confirming the inherited properties, and add a comparison paragraph showing that it reduces to ordinary differential entropy when the perceptual map is the identity. These additions will clarify that the measure is not a fitted heuristic and directly supports the proposed PEC and generation-space constraints. revision: yes
Circularity Check
No significant circularity; central claims rest on model structure and new perceptual measure rather than self-referential fits or citations
full rationale
The paper's derivation of constant policy entropy from the fixed noise schedule in flow-matching models is presented as a direct consequence of the generative process definition (base distribution plus learned transport), not a renaming or fit of the target diversity quantity. Perceptual entropy is introduced as an explicit new functional on chosen perceptual embeddings that is stated to preserve entropy-like properties; this is a definitional extension rather than a reduction of the output to the input by construction. No load-bearing self-citation chains, uniqueness theorems from the same authors, or fitted parameters relabeled as predictions appear in the abstract or described chain. Experiments across models and spaces supply independent empirical content. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Policy entropy in flow models remains constant due to the fixed pre-defined noise schedule
- domain assumption Diversity collapse is driven by the mode-seeking nature of policy gradients
invented entities (1)
-
perceptual entropy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Average-reward soft actor-critic,
Jacob Adamczyk, V olodymyr Makarenko, Stas Tiomkin, and Rahul V Kulkarni. Average-reward reinforcement learning with entropy regularization.arXiv preprint arXiv:2501.09080, 2025
-
[2]
Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12248–12267, 2024
work page 2024
-
[3]
Isabela Albuquerque, Ira Ktena, Olivia Wiles, Ivana Kaji´c, Amal Rannen-Triki, Cristina Vas- concelos, and Aida Nematzadeh. Benchmarking diversity in image generation via attribute- conditional human evaluation.arXiv preprint arXiv:2511.10547, 2025
-
[4]
Improving image generation with better captions
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions. OpenAI Technical Report, 2023
work page 2023
-
[5]
Forking paths in neural text generation.arXiv preprint arXiv:2412.07961, 2024
Eric Bigelow, Ari Holtzman, Hidenori Tanaka, and Tomer Ullman. Forking paths in neural text generation.arXiv preprint arXiv:2412.07961, 2024
-
[6]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning.arXiv preprint arXiv:2305.13301, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Qi Cai, Jingwen Chen, Yang Chen, Yehao Li, Fuchen Long, Yingwei Pan, Zhaofan Qiu, Yiheng Zhang, Fengbin Gao, Peihan Xu, et al. Hidream-i1: A high-efficient image generative foundation model with sparse diffusion transformer.arXiv preprint arXiv:2505.22705, 2025
-
[8]
Emerging Properties in Self-Supervised Vision Transformers.arXiv:2104.14294 [cs], May 2021
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers.CoRR, abs/2104.14294, 2021. URLhttps://arxiv.org/abs/2104.14294
-
[9]
DIME: Diffusion-based maximum entropy reinforcement learning
Onur Celik, Zechu Li, Denis Blessing, Ge Li, Daniel Palenicek, Jan Peters, Georgia Chalvatzaki, and Gerhard Neumann. DIME: Diffusion-based maximum entropy reinforcement learning. InProceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research, pages 6958–6977. PMLR, 13–19 Jul 2025. URL https:/...
work page 2025
-
[10]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Reasoning with exploration: An entropy perspective.arXiv preprint arXiv:2506.14758, 2025
Daixuan Cheng, Shaohan Huang, Xuekai Zhu, Bo Dai, Wayne Xin Zhao, Zhenliang Zhang, and Furu Wei. Reasoning with exploration: An entropy perspective.arXiv preprint arXiv:2506.14758, 2025
-
[12]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Flow density control: Generative optimization beyond entropy-regularized fine-tuning
Riccardo De Santi, Marin Vlastelica, Ya-Ping Hsieh, Zebang Shen, Niao He, and Andreas Krause. Flow density control: Generative optimization beyond entropy-regularized fine-tuning. Advances in Neural Information Processing Systems, 2025. URL https://openreview.net/ forum?id=ELk7sylH7g
work page 2025
-
[14]
Provable maximum entropy manifold exploration via diffusion models
Riccardo De Santi, Marin Vlastelica, Ya-Ping Hsieh, Zebang Shen, Niao He, and Andreas Krause. Provable maximum entropy manifold exploration via diffusion models. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 12739–12761. PMLR, 13–19 Jul 2025. URL https: //proceedings.ml...
work page 2025
-
[15]
Aesthetic-Predictor-v2-5: Siglip-based aesthetic score predictor
Discus0434. Aesthetic-Predictor-v2-5: Siglip-based aesthetic score predictor. https:// github.com/discus0434/aesthetic-predictor-v2-5, 2024
work page 2024
-
[16]
Image generation diversity issues and how to tame them
Mischa Dombrowski, Weitong Zhang, Sarah Cechnicka, Hadrien Reynaud, and Bernhard Kainz. Image generation diversity issues and how to tame them. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3029–3039, 2025
work page 2025
-
[17]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transform- ers for high-resolution image synthesis.arXiv preprint arXiv:2403.03206, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InInternational Conference on Machine Learning, 2024
work page 2024
-
[19]
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023
work page 2023
-
[20]
Dan Friedman and Adji Bousso Dieng. The vendi score: A diversity evaluation metric for machine learning.Transactions on Machine Learning Research, 2023
work page 2023
-
[21]
Xiaolong Fu, Lichen Ma, Zipeng Guo, Gaojing Zhou, Chongxiao Wang, ShiPing Dong, Shizhe Zhou, Ximan Liu, Jingling Fu, Tan Lit Sin, et al. Dynamic-treerpo: Breaking the independent trajectory bottleneck with structured sampling.arXiv preprint arXiv:2509.23352, 2025
-
[22]
Flow matching policy with entropy regularization.arXiv preprint arXiv:2603.17685, 2026
Ting Gao, Stavros Orfanoudakis, Nan Lin, and Elvin Isufi. Flow matching policy with entropy regularization.arXiv preprint arXiv:2603.17685, 2026
-
[23]
Will Grathwohl, Ricky T. Q. Chen, Jesse Bettencourt, Ilya Sutskever, and David Duvenaud. FFJORD: Free-form continuous dynamics for scalable reversible generative models. InInterna- tional Conference on Learning Representations (ICLR), 2019
work page 2019
-
[24]
Reinforcement learning with deep energy-based policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies. InInternational conference on machine learning, pages 1352–1361. PMLR, 2017
work page 2017
-
[25]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. PMLR, 2018
work page 2018
-
[26]
Tempflow-grpo: When timing matters for grpo in flow models.arXiv preprint arXiv:2508.04324,
Xiaoxuan He, Siming Fu, Yuke Zhao, Wanli Li, Jian Yang, Dacheng Yin, Fengyun Rao, and Bo Zhang. Tempflow-grpo: When timing matters for grpo in flow models.arXiv preprint arXiv:2508.04324, 2025
-
[27]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY , USA, 2020. Curran Associates Inc. ISBN 9781713829546
work page 2020
-
[28]
Reinforce++: A simple and efficient approach for aligning large language models
Jian Hu. Reinforce++: A simple and efficient approach for aligning large language models. arXiv e-prints, pages arXiv–2501, 2025
work page 2025
-
[29]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Haozhe Ji, Cheng Lu, Yilin Niu, Pei Ke, Hongning Wang, Jun Zhu, Jie Tang, and Minlie Huang. Towards efficient exact optimization of language model alignment.arXiv preprint arXiv:2402.00856, 2024
-
[31]
Rethinking entropy regularization in large reasoning models.arXiv preprint arXiv:2509.25133, 2025
Yuxian Jiang, Yafu Li, Guanxu Chen, Dongrui Liu, Yu Cheng, and Jing Shao. Rethinking entropy regularization in large reasoning models.arXiv preprint arXiv:2509.25133, 2025
-
[32]
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in Neural Information Processing Systems, 36:36652–36663, 2023
work page 2023
-
[33]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
work page 2024
-
[34]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Miles Yang, and Zhao Zhong. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802, 2025
work page internal anchor Pith review arXiv 2025
-
[35]
arXiv preprint arXiv:2509.06040 (2025) 2, 3
Yuming Li, Yikai Wang, Yuying Zhu, Zhongyu Zhao, Ming Lu, Qi She, and Shanghang Zhang. Branchgrpo: Stable and efficient grpo with structured branching in diffusion models.arXiv preprint arXiv:2509.06040, 2025
-
[36]
Zhimin Li, Jianwei Zhang, Qin Lin, Jiangfeng Fang, Xiaobo Wang, Wenhao Wang, Zhenyu Yang, Jiawei Li, Xianfang Shi, Hao Zhang, et al. Hunyuan-dit: A powerful multi-resolution diffusion transformer with fine-grained chinese understanding, 2024. 11
work page 2024
-
[37]
Magic3d: High-resolution text-to-3d content creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. InIEEE Conference on Computer Vision and Pattern Recognition, 2023
work page 2023
-
[38]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Alignment of diffusion models: Fundamentals, challenges, and future
Buhua Liu, Shitong Shao, Bao Li, Lichen Bai, Zhiqiang Xu, Haoyi Xiong, James Kwok, Sumi Helal, and Zeke Xie. Alignment of diffusion models: Fundamentals, challenges, and future. ACM Computing Surveys, 2026
work page 2026
-
[40]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Miao Liu, Shizhe Diao, Xiaotian Lu, Jiachen Hu, Xishan Dong, Yejin Choi, Jan Kautz, and Yuxiao Dong. Prorl: Prolonged reinforcement learning expands reasoning boundaries in large language models.arXiv preprint arXiv:2505.24864, 2025
-
[42]
Runtao Liu, Chen I Chieh, Jindong Gu, Jipeng Zhang, Renjie Pi, Qifeng Chen, Philip Torr, Ashkan Khakzar, and Fabio Pizzati. Safetydpo: Scalable safety alignment for text-to-image generation.arXiv preprint arXiv:2412.10493, 2024
-
[43]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Yiyang Ma, Xingchao Liu, Xiaokang Chen, Wen Liu, Chengyue Wu, Zhiyu Wu, Zizheng Pan, Zhenda Xie, Haowei Zhang, Liang Zhao, et al. Janusflow: Harmonizing autoregres- sion and rectified flow for unified multimodal understanding and generation.arXiv preprint arXiv:2411.07975, 2024
-
[45]
Entropy-controlled flow matching.arXiv preprint arXiv:2602.22265, 2026
Chika Maduabuchi. Entropy-controlled flow matching.arXiv preprint arXiv:2602.22265, 2026
-
[46]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. InInternational Conference on Learning Representations, 2023
work page 2023
-
[48]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, pages 8748–8763. PMLR, 2021
work page 2021
-
[49]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[50]
Ren, Justin Dinh, and Hanjun Dai
Allen Z. Ren, Justin Dinh, and Hanjun Dai. Diffusion policies as an expressive policy class for offline reinforcement learning.arXiv preprint arXiv:2408.18257, 2024
-
[51]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022
work page 2022
-
[52]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[53]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv.org/abs/ 2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Exploring data scaling trends and effects in reinforcement learning from human feedback
Wei Shen, Guanlin Liu, Zheng Wu, Ruofei Zhu, Qingping Yang, Chao Xin, Yu Yue, and Lin Yan. Exploring data scaling trends and effects in reinforcement learning from human feedback. arXiv preprint arXiv:2503.22230, 2025
-
[55]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021. URL https://openreview. net/forum?id=PxTIG12RRHS. 12
work page 2021
-
[56]
Kolors Team. Kolors: Effective training of diffusion model for photorealistic text-to-image synthesis.Technical report, 2024. URL https://github.com/Kwai-Kolors/Kolors/. Project release; no arXiv identifier is listed in the official repository
work page 2024
-
[57]
Masatoshi Uehara, Yulai Zhao, Tommaso Biancalani, and Sergey Levine. Understanding reinforcement learning-based fine-tuning of diffusion models: A tutorial and review.arXiv preprint arXiv:2407.13734, 2024
-
[58]
Abdullah Vanlioglu. Entropy-guided sequence weighting for efficient exploration in rl-based llm fine-tuning.arXiv preprint arXiv:2503.22456, 2025
-
[59]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024
work page 2024
-
[60]
Coefficients-preserving sampling for reinforcement learning with flow matching
Feng Wang and Zihao Yu. Coefficients-preserving sampling for reinforcement learning with flow matching.arXiv preprint arXiv:2509.05952, 2025
-
[61]
GRPO-Guard: Mitigating implicit over-optimization in flow matching via regulated clipping, 2025
Jing Wang, Jiajun Liang, Jie Liu, Henglin Liu, Gongye Liu, Jun Zheng, Wanyuan Pang, Ao Ma, Zhenyu Xie, Xintao Wang, et al. Grpo-guard: Mitigating implicit over-optimization in flow matching via regulated clipping.arXiv preprint arXiv:2510.22319, 2025
-
[62]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.01939, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
Xinzhou Wang, Yikai Wang, Junliang Ye, Fuchun Sun, Zhengyi Wang, Ling Wang, Pengkun Liu, Kai Sun, Xintong Wang, Fangfu Liu, and Bin He. Animatabledreamer: Text-guided non-rigid 3d model generation and reconstruction with canonical score distillation. InEuropean Conference on Computer Vision, 2024
work page 2024
-
[65]
Unified Reward Model for Multimodal Understanding and Generation
Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, and Jiaqi Wang. Unified reward model for multimodal understanding and generation.arXiv preprint arXiv:2503.05236, 2025
work page internal anchor Pith review arXiv 2025
-
[66]
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Pro- lificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[67]
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8:229–256, 1992
work page 1992
-
[68]
Qwen-image technical report, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, An Yang, Bin Bai, Bo Zhang, Bowen Zheng, Bowen Yu, Chengpeng Chen, Dayiheng Huang, et al. Qwen-image technical report, 2025
work page 2025
-
[69]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[70]
Enze Xie, Junsong Chen, Yuyang Zhao, Jincheng Yu, Ligeng Zhu, Yujun Lin, Zhekai Zhang, Muyang Li, Junyu Chen, Han Cai, et al. Sana 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer.arXiv preprint arXiv:2501.18427, 2025
-
[71]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single trans- former to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[72]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems, 36:15903–15935, 2023
work page 2023
-
[73]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Zhiyuan Yan, Junyan Ye, Weijia Li, Zilong Huang, Shenghai Yuan, Xiangyang He, Kaiqing Lin, Jun He, Conghui He, and Li Yuan. Gpt-imgeval: A comprehensive benchmark for diagnosing gpt-4o in image generation.arXiv preprint arXiv:2504.02782, 2025
-
[75]
Using human feedback to fine-tune diffusion models without any reward model
Kai Yang, Jian Tao, Jiafei Lyu, Chunjiang Ge, Jiaxin Chen, Weihan Shen, Xiaolong Zhu, and Xiu Li. Using human feedback to fine-tune diffusion models without any reward model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8941–8951, 2024
work page 2024
-
[76]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. Diffusionnft: Online diffusion reinforcement with forward process.arXiv preprint arXiv:2509.16117, 2025
work page internal anchor Pith review arXiv 2025
-
[79]
Xinyu Zhu, Mengzhou Xia, Zhepei Wei, Wei-Lin Chen, Danqi Chen, and Yu Meng. The surprising effectiveness of negative reinforcement in llm reasoning, 2025.arXiv preprint arXiv:2506.01347, 2025
-
[80]
Maximum entropy inverse reinforcement learning
Brian D Ziebart, Andrew L Maas, J Andrew Bagnell, Anind K Dey, et al. Maximum entropy inverse reinforcement learning. InAAAI, volume 8, pages 1433–1438. Chicago, IL, USA, 2008. 14 When Policy Entropy Constraint Fails: Preserving Diversity in Flow-based RLHF via Perceptual Entropy Supplementary Material w/ PEC (Ours) Flow-GRPO w/ PEC (Ours) Flow-GRPO w/ PE...
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.