Recognition: 2 theorem links
· Lean TheoremStories in Space: In-Context Learning Trajectories in Conceptual Belief Space
Pith reviewed 2026-05-13 05:10 UTC · model grok-4.3
The pith
Large language models update beliefs by tracing trajectories through a low-dimensional conceptual belief space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
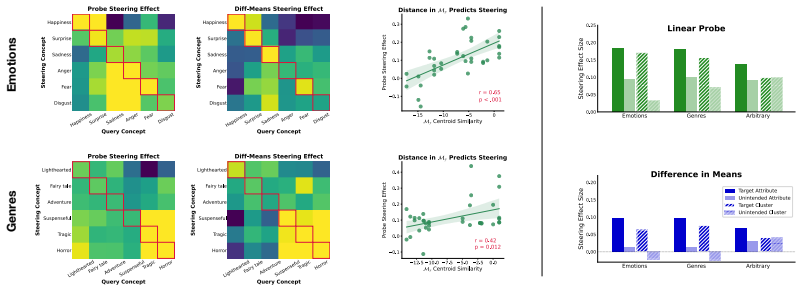
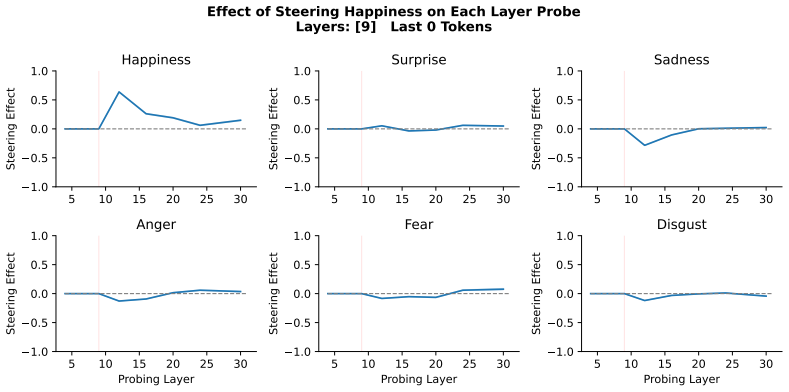
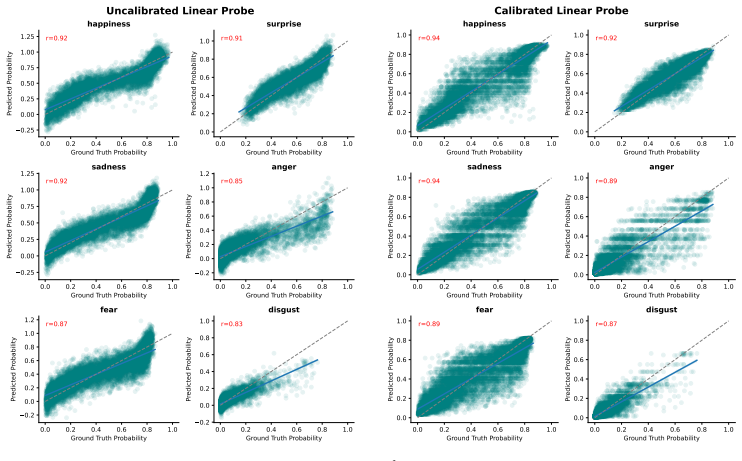
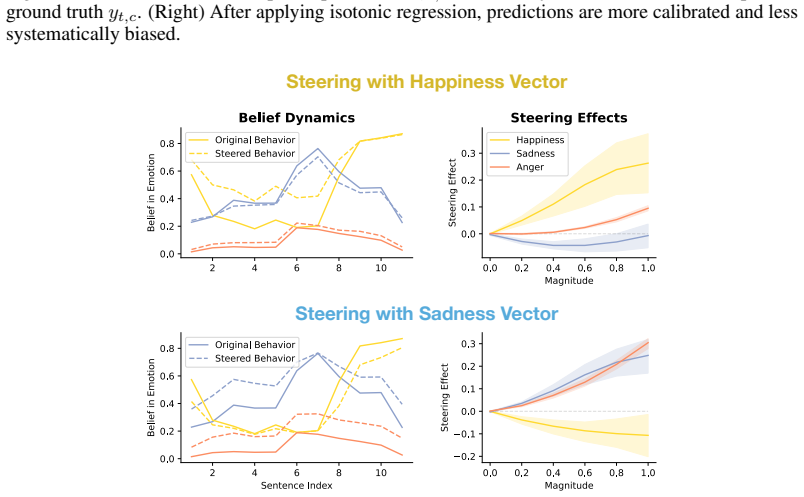
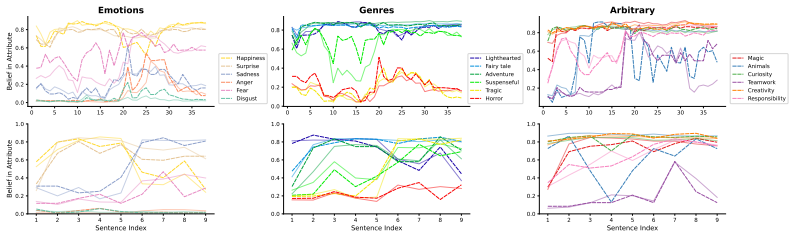
Large language models assign beliefs over a low-dimensional geometric space, a conceptual belief space, and in-context learning corresponds to a trajectory through this space as beliefs are updated over time. Using story understanding as a setting for dynamic belief updating, belief updates are well-described as trajectories on low-dimensional, structured manifolds. This structure is reflected consistently in both model behavior and internal representations and can be decoded with simple linear probes to predict behavior. Interventions on these representations causally steer belief trajectories, with effects that can be predicted from the geometry of the conceptual space.
What carries the argument
Conceptual belief space: the low-dimensional geometric manifold in which LLMs represent beliefs and along which in-context learning moves as a trajectory.
If this is right
- Belief changes during reading can be tracked and visualized as continuous paths rather than discrete flips.
- Linear probes applied to hidden states can forecast how a model will interpret later parts of a story.
- Targeted edits to representations can steer belief paths toward or away from specific conclusions in a geometry-governed way.
- The same geometric description links observable outputs to the underlying representational changes.
Where Pith is reading between the lines
- The same trajectory view could be tested on non-narrative tasks such as multi-step reasoning or dialogue to see whether belief space remains low-dimensional.
- If the geometry is stable, it might support methods that monitor and correct drifting beliefs in deployed systems without retraining.
- The framework invites comparison between model trajectories and human belief updating when people read the same stories.
Load-bearing premise
The low-dimensional structure and linear decodability reflect an intrinsic geometric organization of beliefs rather than an artifact of the particular stories, models, or measurement methods chosen.
What would settle it
If editing the identified directions in the model's internal representations fails to shift subsequent story judgments in the directions predicted by the geometry, or if the low-dimensional manifolds disappear under new story sets or different models.
Figures
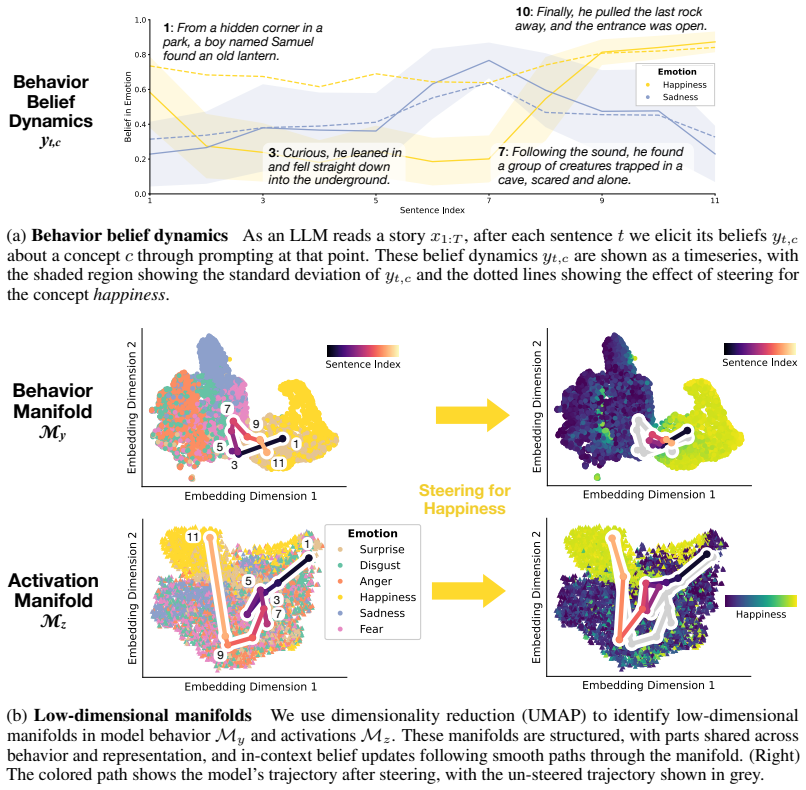

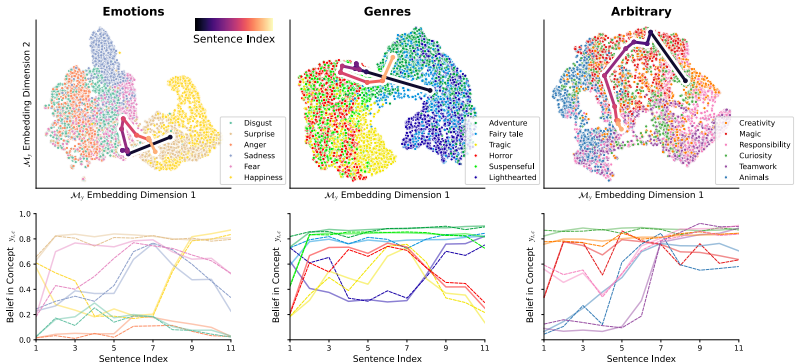
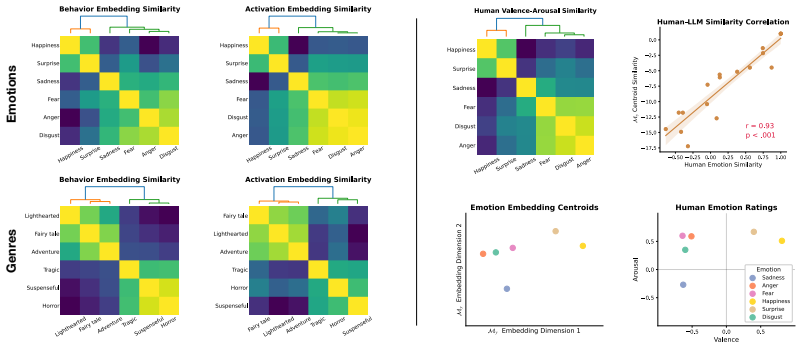
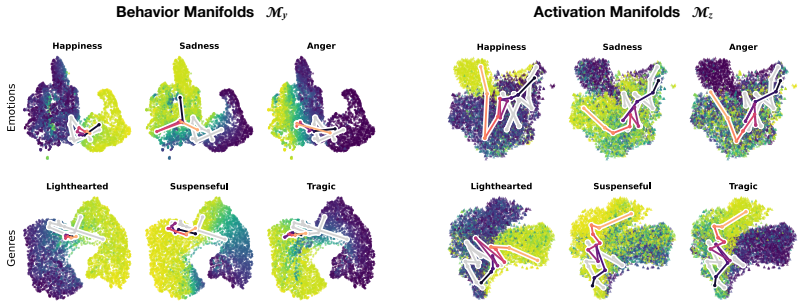










read the original abstract
Large Language Models (LLMs) update their behavior in context, which can be viewed as a form of Bayesian inference. However, the structure of the latent hypothesis space over which this inference operates remains unclear. In this work, we propose that LLMs assign beliefs over a low-dimensional geometric space - a conceptual belief space - and that in-context learning corresponds to a trajectory through this space as beliefs are updated over time. Using story understanding as a natural setting for dynamic belief updating, we combine behavioral and representational analyses to study these trajectories. We find that (1) belief updates are well-described as trajectories on low-dimensional, structured manifolds; (2) this structure is reflected consistently in both model behavior and internal representations and can be decoded with simple linear probes to predict behavior; and (3) interventions on these representations causally steer belief trajectories, with effects that can be predicted from the geometry of the conceptual space. Together, our results provide a geometric account of belief dynamics in LLMs, grounding Bayesian interpretations of in-context learning in structured conceptual representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs update beliefs during in-context learning by traversing trajectories on low-dimensional, structured manifolds in a conceptual belief space. Using story comprehension tasks to induce dynamic belief updates, it combines behavioral analyses, representational geometry from model activations, linear probes for decoding, and causal interventions to show that these trajectories are consistent across behavior and internals, predictable via simple linear methods, and steerable in ways aligned with the space's geometry.
Significance. If the central claims hold after addressing methodological concerns, this provides a geometric grounding for Bayesian interpretations of in-context learning, linking observable behavior to internal representations with causal evidence. The integration of behavioral, representational, and interventional methods is a strength, as is the attempt to make predictions from the geometry itself. It could inform more interpretable models of LLM belief dynamics if the low-dimensional structure proves intrinsic rather than stimulus-specific.
major comments (3)
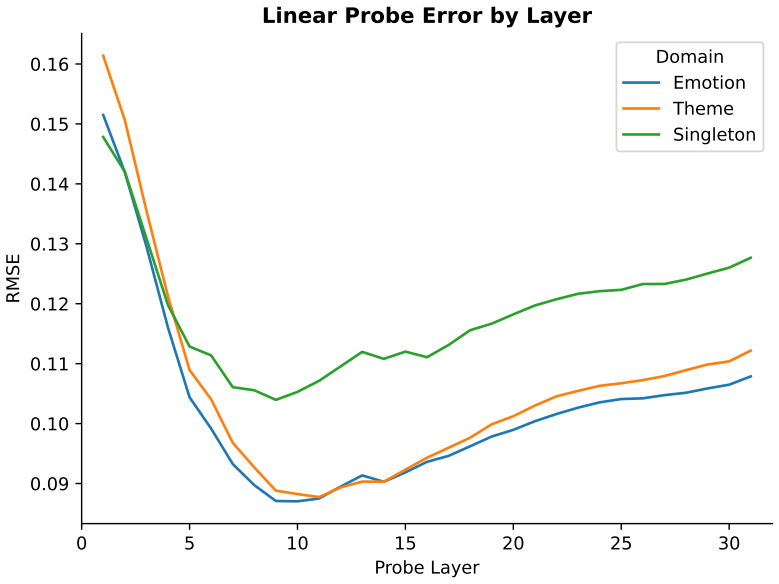
- [§3.2] §3.2 (Dimensionality reduction): The dimensionality of the conceptual belief space is selected post-hoc based on variance explained in the activations from the fixed story set. This directly bears on the central claim of an intrinsic low-dimensional manifold; without pre-specification, cross-validation across held-out story collections, or testing on varied narrative axes, the recovered structure risks being an artifact of the low-rank input distribution rather than a property of the model's hypothesis space.
- [§5] §5 (Interventions): The causal interventions on representations are reported to steer belief trajectories with geometrically predictable effects, but the section lacks controls such as intervention magnitude matching, sham perturbations, or comparisons to directions orthogonal to the conceptual space. This is load-bearing for the claim that effects follow from the geometry rather than generic activation changes.
- [§4.3] §4.3 (Linear probes): The probes decode the conceptual space from activations to predict behavior, yet the space itself is derived from the same activations used for both probing and intervention. This circularity risk (noted in the stress-test) undermines independence; the paper should report performance on activations from a separate model or task to verify the structure is not analysis-defined.
minor comments (2)
- [Figure 3] Figure 3: The manifold visualization axes are not labeled with respect to the principal components or conceptual dimensions; clarify what each axis represents to aid interpretability.
- [Abstract] The abstract and introduction use 'parameter-free' for the geometric account, but the dimensionality choice introduces a free parameter; revise for precision.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments, which highlight important methodological considerations for strengthening our claims about the structure of conceptual belief spaces in LLMs. We address each major comment point by point below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Dimensionality reduction): The dimensionality of the conceptual belief space is selected post-hoc based on variance explained in the activations from the fixed story set. This directly bears on the central claim of an intrinsic low-dimensional manifold; without pre-specification, cross-validation across held-out story collections, or testing on varied narrative axes, the recovered structure risks being an artifact of the low-rank input distribution rather than a property of the model's hypothesis space.
Authors: We selected the dimensionality using the standard approach of identifying the elbow in the variance explained curve from PCA applied to the model activations. This is not entirely post-hoc as it follows established practices in analyzing representational geometry. Nevertheless, to directly address the concern about potential artifacts from the fixed story set, we will incorporate cross-validation in the revised version: specifically, we will partition the stories into training and held-out sets, derive the dimensionality and principal components from the training set, and then evaluate the consistency of the low-dimensional trajectories and structure on the held-out stories. We will also extend the analysis to include stories varying along additional narrative dimensions to test generalizability beyond the original set. revision: partial
-
Referee: [§5] §5 (Interventions): The causal interventions on representations are reported to steer belief trajectories with geometrically predictable effects, but the section lacks controls such as intervention magnitude matching, sham perturbations, or comparisons to directions orthogonal to the conceptual space. This is load-bearing for the claim that effects follow from the geometry rather than generic activation changes.
Authors: We concur that additional controls are essential to substantiate that the observed steering effects arise from the geometry of the conceptual space rather than nonspecific activation perturbations. Accordingly, we will revise §5 to include the following: sham interventions using random vectors in the activation space with magnitudes matched to the conceptual interventions; explicit reporting of magnitude matching across all conditions; and interventions along directions orthogonal to the primary conceptual axes, with comparisons of their effects on belief trajectories. These controls will demonstrate the specificity of the geometric predictions. revision: yes
-
Referee: [§4.3] §4.3 (Linear probes): The probes decode the conceptual space from activations to predict behavior, yet the space itself is derived from the same activations used for both probing and intervention. This circularity risk (noted in the stress-test) undermines independence; the paper should report performance on activations from a separate model or task to verify the structure is not analysis-defined.
Authors: The manuscript includes a stress-test to partially address independence by applying the probes to different story collections. However, we recognize the value of further validation using separate models or tasks. In the revision, we will add results from linear probes trained and tested on activations from a distinct model variant (such as a different size or family) performing analogous story comprehension tasks. This will help confirm that the decoded conceptual structure is not solely an artifact of the analysis on the primary model. We note that while full separation is ideal, the core claims are supported by the convergence of behavioral, representational, and interventional evidence. revision: partial
Circularity Check
No significant circularity in empirical analysis of belief trajectories
full rationale
The paper reports experimental results from inducing belief updates via stories in LLMs, followed by dimensionality reduction on activations to identify manifolds, linear probes to decode behavior, and targeted interventions to test causal effects. These steps rely on data-driven measurements and statistical methods applied to model outputs and internal states rather than any self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation that reduces the central claims to the inputs by construction. The geometric account is presented as an empirical finding supported by the observed consistency across behavior, representations, and interventions, without equations or derivations that equate outputs to inputs tautologically.
Axiom & Free-Parameter Ledger
free parameters (1)
- dimensionality of conceptual belief space
axioms (1)
- domain assumption In-context learning can be viewed as Bayesian inference over a latent hypothesis space
invented entities (1)
-
conceptual belief space
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearbelief updates are well-described as trajectories on low-dimensional, structured manifolds; this structure is reflected consistently in both model behavior and internal representations and can be decoded with simple linear probes
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearsteering entanglement can be predicted based on the structure of our learned manifold My … correlated with the distance between their centroids in My (r=.65)
Reference graph
Works this paper leans on
-
[1]
Visual pigments in single rods and cones of the human retina , author=. Science , volume=. 1964 , publisher=
work page 1964
-
[2]
Frontiers in psychology , volume=
Neurotransmitters and emotions , author=. Frontiers in psychology , volume=. 2020 , publisher=
work page 2020
-
[3]
arXiv preprint arXiv:2511.01805 , year=
Accumulating context changes the beliefs of language models , author=. arXiv preprint arXiv:2511.01805 , year=
-
[4]
arXiv preprint arXiv:2601.22364 , year=
Context Structure Reshapes the Representational Geometry of Language Models , author=. arXiv preprint arXiv:2601.22364 , year=
-
[5]
arXiv preprint arXiv:2511.01836 , year=
Priors in Time: Missing Inductive Biases for Language Model Interpretability , author=. arXiv preprint arXiv:2511.01836 , year=
-
[6]
arXiv preprint arXiv:2505.14685 , year=
Language models use lookbacks to track beliefs , author=. arXiv preprint arXiv:2505.14685 , year=
-
[7]
Philosophical Transactions of the Royal Society B: Biological Sciences , volume=
Re-evaluating theory of mind evaluation in large language models , author=. Philosophical Transactions of the Royal Society B: Biological Sciences , volume=. 2025 , publisher=
work page 2025
-
[8]
First Workshop on Theory of Mind in Communicating Agents , year=
Do LLMs selectively encode the goal of an agent's reach? , author=. First Workshop on Theory of Mind in Communicating Agents , year=
- [9]
-
[10]
Valence-Arousal Subspace in LLMs: Circular Emotion Geometry and Multi-Behavioral Control
Valence-Arousal Subspace in LLMs: Circular Emotion Geometry and Multi-Behavioral Control , author=. arXiv preprint arXiv:2604.03147 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Advances in Neural Information Processing Systems , volume=
Confidence regulation neurons in language models , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
MINT: Foundation Model Interventions , year=
Semantic entropy neurons: Encoding semantic uncertainty in the latent space of llms , author=. MINT: Foundation Model Interventions , year=
-
[13]
Reasoning theater: Disentangling model beliefs from chain-of- thought, 2026
Reasoning theater: Disentangling model beliefs from chain-of-thought , author=. arXiv preprint arXiv:2603.05488 , year=
-
[14]
Manifold Steering Reveals the Shared Geometry of Neural Network Representation and Behavior
Manifold Steering Reveals the Shared Geometry of Neural Network Representation and Behavior , author=. arXiv preprint arXiv:2605.05115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
arXiv preprint arXiv:2402.03563 , year=
Distinguishing the knowable from the unknowable with language models , author=. arXiv preprint arXiv:2402.03563 , year=
-
[16]
IEEE Transactions on Visualization and Computer Graphics , year=
Story Ribbons: Reimagining Storyline Visualizations with Large Language Models , author=. IEEE Transactions on Visualization and Computer Graphics , year=
-
[18]
Linearly mapping from image to text space.arXiv preprint arXiv:2209.15162,
Linearly mapping from image to text space , author=. arXiv preprint arXiv:2209.15162 , year=
-
[19]
arXiv preprint arXiv:2402.00795 , year=
LLMs learn governing principles of dynamical systems, revealing an in-context neural scaling law , author=. arXiv preprint arXiv:2402.00795 , year=
-
[20]
Transactions of the Association for Computational Linguistics , author =
A. Transactions of the Association for Computational Linguistics , author =. 2016 , note =. doi:10.1162/tacl_a_00106 , urldate =
-
[21]
Emergent linear representations in world models of self-supervised sequence models
Nanda, Neel and Lee, Andrew and Wattenberg, Martin , month = sep, year =. Emergent. doi:10.48550/arXiv.2309.00941 , abstract =
- [22]
-
[23]
Batchtopk sparse autoencoders, 2024
Batchtopk sparse autoencoders , author=. preprint arXiv:2412.06410 , year=
-
[24]
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
work page 2023
-
[25]
arXiv preprint arXiv:2507.23220 , year=
Model Directions, Not Words: Mechanistic Topic Models Using Sparse Autoencoders , author=. arXiv preprint arXiv:2507.23220 , year=
-
[26]
arXiv preprint arXiv:2506.03093 , year=
From Flat to Hierarchical: Extracting Sparse Representations with Matching Pursuit , author=. arXiv preprint arXiv:2506.03093 , year=
-
[27]
arXiv preprint arXiv:2402.18496 , year=
Language models represent beliefs of self and others , author=. arXiv preprint arXiv:2402.18496 , year=
-
[28]
arXiv preprint arXiv:2406.07882 , year=
Designing a dashboard for transparency and control of conversational AI , author=. arXiv preprint arXiv:2406.07882 , year=
-
[29]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
arXiv preprint arXiv:2410.17245 , year=
Towards reliable evaluation of behavior steering interventions in llms , author=. arXiv preprint arXiv:2410.17245 , year=
-
[31]
arXiv preprint arXiv:2202.12837 , year=
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? , author=. arXiv preprint arXiv:2202.12837 , year=
-
[32]
Advances in Neural Information Processing Systems , volume=
Pretraining task diversity and the emergence of non-bayesian in-context learning for regression , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
In- Context Language Learning : Architectures and Algorithms , 2024
In-context language learning: Architectures and algorithms , author=. arXiv preprint arXiv:2401.12973 , year=
-
[34]
arXiv preprint arXiv:1801.08930 , year=
Recasting gradient-based meta-learning as hierarchical bayes , author=. arXiv preprint arXiv:1801.08930 , year=
-
[35]
arXiv preprint arXiv:2410.16531 , year=
Bayesian scaling laws for in-context learning , author=. arXiv preprint arXiv:2410.16531 , year=
-
[36]
arXiv preprint arXiv:2305.19420 , year=
What and how does in-context learning learn? bayesian model averaging, parameterization, and generalization , author=. arXiv preprint arXiv:2305.19420 , year=
-
[37]
In-Context Learning through the Bayesian Prism , author=. 2024 , eprint=
work page 2024
-
[38]
ICML workshop on actionable interpretability , year=
Are language models aware of the road not taken? Token-level uncertainty and hidden state dynamics , author=. ICML workshop on actionable interpretability , year=
-
[39]
arXiv preprint arXiv:2406.02550 , year=
Learning to grok: Emergence of in-context learning and skill composition in modular arithmetic tasks , author=. arXiv preprint arXiv:2406.02550 , year=
-
[40]
Palm-e: An embodied multimodal language model , author=. 2023 , eprint=
work page 2023
-
[41]
arXiv preprint arXiv:2410.12782 , year=
In-Context Learning Enables Robot Action Prediction in LLMs , author=. arXiv preprint arXiv:2410.12782 , year=
-
[42]
arXiv preprint arXiv:2410.01280 , year=
Sparse autoencoders reveal temporal difference learning in large language models , author=. arXiv preprint arXiv:2410.01280 , year=
-
[43]
arXiv preprint arXiv:2212.10559 , year=
Why can gpt learn in-context? language models implicitly perform gradient descent as meta-optimizers , author=. arXiv preprint arXiv:2212.10559 , year=
-
[44]
International Conference on Machine Learning , pages=
Transformers learn in-context by gradient descent , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[45]
The Thirteenth International Conference on Learning Representations , year=
ICLR: In-Context Learning of Representations , author=. The Thirteenth International Conference on Learning Representations , year=
-
[46]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
The mechanistic basis of data dependence and abrupt learning in an in-context classification task , author=. 2023 , eprint=
work page 2023
-
[48]
Differential learning kinetics govern the transition from memorization to generalization during in-context learning , author=. 2024 , eprint=
work page 2024
-
[49]
Advances in Neural Information Processing Systems , volume=
Data distributional properties drive emergent in-context learning in transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[50]
Advances in neural information processing systems , volume=
Bayesian modeling of human concept learning , author=. Advances in neural information processing systems , volume=
-
[51]
Advances in neural information processing systems , volume=
Rules and similarity in concept learning , author=. Advances in neural information processing systems , volume=
-
[52]
Trends in Cognitive Sciences , year=
Physics versus graphics as an organizing dichotomy in cognition , author=. Trends in Cognitive Sciences , year=
-
[53]
Journal of Open Psychology Data , volume=
A large dataset of generalization patterns in the number game , author=. Journal of Open Psychology Data , volume=
- [54]
-
[55]
In-context learning dynamics with random binary sequences , author=. ICLR , year=
-
[56]
Advances in Neural Information Processing Systems , volume=
Human-like few-shot learning via bayesian reasoning over natural language , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
A rational analysis of rule-based concept learning , author=. Cognitive science , volume=. 2008 , publisher=
work page 2008
- [58]
-
[59]
arXiv preprint arXiv:1912.11554 , year=
Composable effects for flexible and accelerated probabilistic programming in NumPyro , author=. arXiv preprint arXiv:1912.11554 , year=
- [60]
-
[61]
Many-Shot In-Context Learning , author =
-
[62]
Learning with Latent Language , author =. 2017 , month = nov, number =. doi:10.48550/arXiv.1711.00482 , urldate =. arXiv , langid =:1711.00482 , primaryclass =
-
[63]
Many-Shot Jailbreaking , author =
-
[64]
Refusal in Language Models Is Mediated by a Single Direction
Refusal in Language Models Is Mediated by a Single Direction , author =. 2024 , month = oct, number =. doi:10.48550/arXiv.2406.11717 , urldate =. arXiv , langid =:2406.11717 , primaryclass =
work page internal anchor Pith review doi:10.48550/arxiv.2406.11717 2024
-
[65]
Ball, Sarah and Kreuter, Frauke and Panickssery, Nina , year =. Understanding Jailbreak Success: A Study of Latent Space Dynamics in Large Language Models , shorttitle =. doi:10.48550/arXiv.2406.09289 , urldate =. arXiv , langid =:2406.09289 , primaryclass =
-
[66]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting Latent Predictions from Transformers with the Tuned Lens , author =. 2023 , month = nov, number =. doi:10.48550/arXiv.2303.08112 , urldate =. arXiv , langid =:2303.08112 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08112 2023
-
[67]
Mechanistic Interpretability for AI Safety -- A Review , author =. 2024 , month = aug, number =. doi:10.48550/arXiv.2404.14082 , urldate =. arXiv , langid =:2404.14082 , primaryclass =
-
[68]
and Bridgers, Sophie and Gopnik, Alison and Tenenbaum, Joshua B
Bonawitz, Elizabeth and Ullman, Tomer D. and Bridgers, Sophie and Gopnik, Alison and Tenenbaum, Joshua B. , year =. Sticking to the Evidence? A Behavioral and Computational Case Study of Micro-Theory Change in the Domain of Magnetism , shorttitle =. Cognitive Science , volume =. doi:10.1111/cogs.12765 , urldate =
-
[69]
Local Search and the Evolution of World Models , author =. 2023 , month = oct, journal =. doi:10.1111/tops.12703 , urldate =
-
[70]
Discovering latent knowledge in language models without supervision
Discovering Latent Knowledge in Language Models Without Supervision , author =. 2024 , month = mar, number =. doi:10.48550/arXiv.2212.03827 , urldate =. arXiv , langid =:2212.03827 , primaryclass =
-
[71]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
Chen, Runjin and Arditi, Andy and Sleight, Henry and Evans, Owain and Lindsey, Jack , year =. Persona Vectors: Monitoring and Controlling Character Traits in Language Models , shorttitle =. doi:10.48550/arXiv.2507.21509 , urldate =. arXiv , langid =:2507.21509 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.21509
-
[72]
Plug and Play Language Models: A Simple Approach to Controlled Text Generation , shorttitle =
Dathathri, Sumanth and Madotto, Andrea and Lan, Janice and Hung, Jane and Frank, Eric and Molino, Piero and Yosinski, Jason and Liu, Rosanne , year =. Plug and Play Language Models: A Simple Approach to Controlled Text Generation , shorttitle =. doi:10.48550/arXiv.1912.02164 , urldate =. arXiv , langid =:1912.02164 , primaryclass =
-
[73]
Human-like Few-Shot Learning via Bayesian Reasoning over Natural Language , author =
-
[74]
A Primer on the Inner Workings of Transformer-based Language Models , author =. 2024 , month = oct, number =. doi:10.48550/arXiv.2405.00208 , urldate =. arXiv , langid =:2405.00208 , primaryclass =
-
[75]
A Unified Understanding and Evaluation of Steering Methods , author =. 2025 , month = feb, number =. doi:10.48550/arXiv.2502.02716 , urldate =. arXiv , langid =:2502.02716 , primaryclass =
-
[76]
Jain, Samyak and Lubana, Ekdeep Singh and Oksuz, Kemal and Joy, Tom and Torr, Philip H. S. and Sanyal, Amartya and Dokania, Puneet K. , year =. What Makes and Breaks Safety Fine-tuning? A Mechanistic Study , shorttitle =. doi:10.48550/arXiv.2407.10264 , urldate =. arXiv , langid =:2407.10264 , primaryclass =
-
[77]
On the Origins of Linear Representations in Large Language Models , author =. 2024 , month = mar, number =. doi:10.48550/arXiv.2403.03867 , urldate =. arXiv , langid =:2403.03867 , primaryclass =
-
[78]
What Features in Prompts Jailbreak LLMs? Investigating the Mechanisms Behind Attacks , shorttitle =
Kirch, Nathalie Maria and Field, Severin and Casper, Stephen , year =. What Features in Prompts Jailbreak LLMs? Investigating the Mechanisms Behind Attacks , shorttitle =. doi:10.48550/arXiv.2411.03343 , urldate =. arXiv , langid =:2411.03343 , primaryclass =
-
[79]
Learning by Thinking in Natural and Artificial Minds , author =. 2024 , month = sep, journal =. doi:10.1016/j.tics.2024.07.007 , urldate =
-
[80]
Ma, Avery and Pan, Yangchen and Farahmand, Amir-massoud , year =. PANDAS: Improving Many-shot Jailbreaking via Positive Affirmation, Negative Demonstration, and Adaptive Sampling , shorttitle =. doi:10.48550/arXiv.2502.01925 , urldate =. arXiv , langid =:2502.01925 , primaryclass =
-
[81]
Distilling Symbolic Priors for Concept Learning into Neural Networks , author =. 2024 , month = feb, number =. arXiv , langid =:2402.07035 , primaryclass =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.