Recognition: no theorem link
ToolCUA: Towards Optimal GUI-Tool Path Orchestration for Computer Use Agents
Pith reviewed 2026-05-13 03:42 UTC · model grok-4.3
The pith
ToolCUA learns optimal selection between GUI actions and tool calls by scaling synthetic hybrid trajectories and applying staged reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
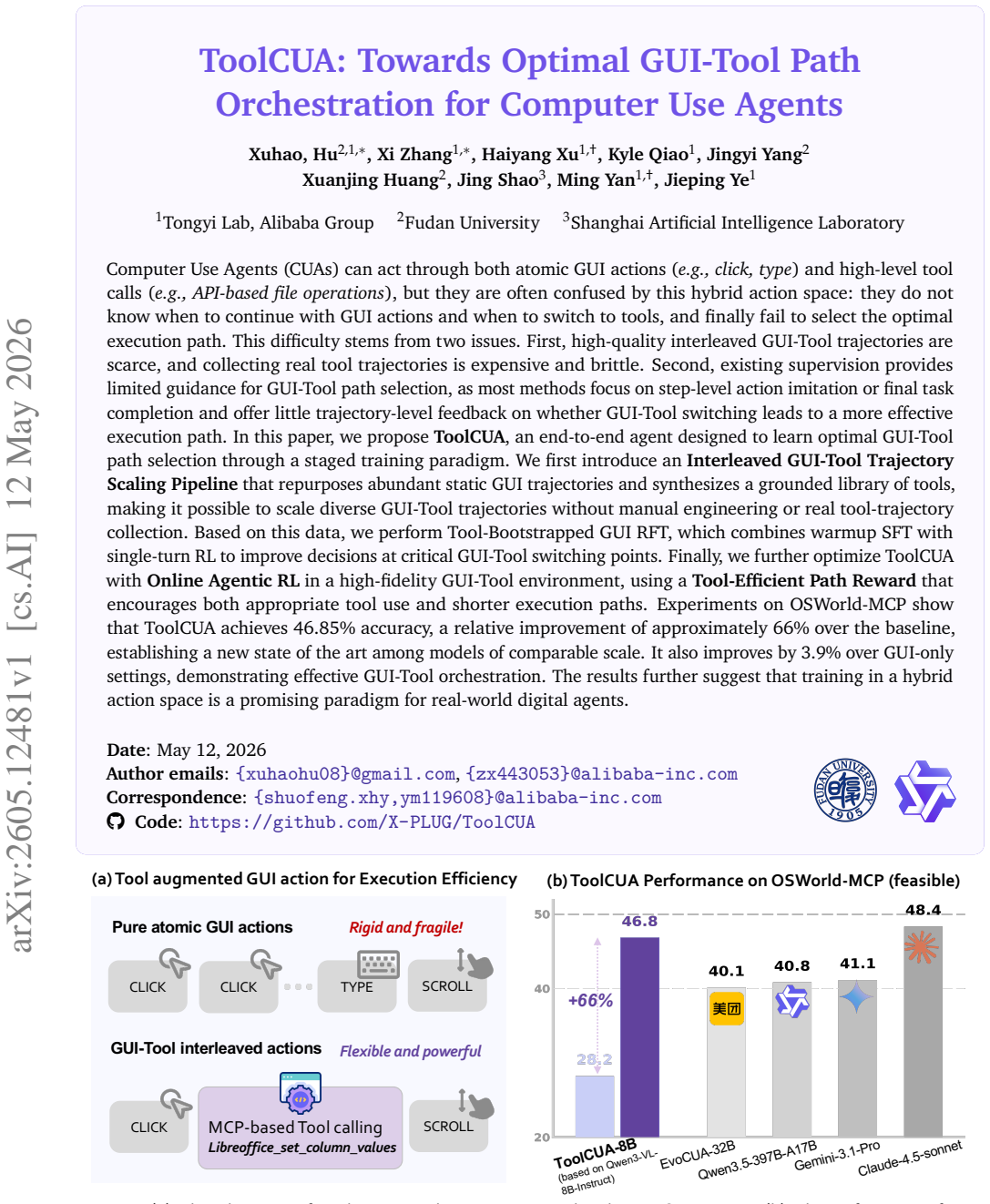
The paper claims that an end-to-end agent trained through a staged paradigm—repurposing static GUI trajectories to synthesize interleaved GUI-Tool data, followed by Tool-Bootstrapped GUI RFT and then Online Agentic RL with a reward that favors appropriate tool use and shorter paths—can learn to select more effective execution paths in a hybrid action space, achieving 46.85 percent accuracy on OSWorld-MCP with a 66 percent relative improvement over the baseline and a 3.9 percent gain over GUI-only settings.
What carries the argument
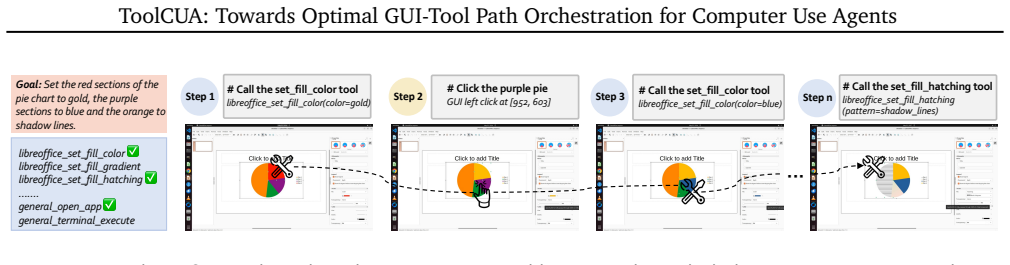
The staged training paradigm that combines the Interleaved GUI-Tool Trajectory Scaling Pipeline, Tool-Bootstrapped GUI RFT, and Online Agentic RL with a Tool-Efficient Path Reward.
Load-bearing premise
The synthesized interleaved trajectories match the distribution of real user tasks closely enough that policies trained on them transfer without major distribution shift or bias from the synthesis process.
What would settle it
A large drop in accuracy when ToolCUA is evaluated on a set of real human-collected interleaved GUI-tool trajectories compared with its performance on the synthetic data would show the assumption does not hold.
Figures


read the original abstract
Computer Use Agents (CUAs) can act through both atomic GUI actions, such as click and type, and high-level tool calls, such as API-based file operations, but this hybrid action space often leaves them uncertain about when to continue with GUI actions or switch to tools, leading to suboptimal execution paths. This difficulty stems from the scarcity of high-quality interleaved GUI-Tool trajectories, the cost and brittleness of collecting real tool trajectories, and the lack of trajectory-level supervision for GUI-Tool path selection. In this paper, we propose ToolCUA, an end-to-end agent designed to learn optimal GUI-Tool path selection through a staged training paradigm. We first introduce an Interleaved GUI-Tool Trajectory Scaling Pipeline that repurposes abundant static GUI trajectories and synthesizes a grounded tool library, enabling diverse GUI-Tool trajectories without manual engineering or real tool-trajectory collection. We then perform Tool-Bootstrapped GUI RFT, combining warmup SFT with single-turn RL to improve decisions at critical GUI-Tool switching points. Finally, we optimize ToolCUA with Online Agentic RL in a high-fidelity GUI-Tool environment, guided by a Tool-Efficient Path Reward that encourages appropriate tool use and shorter execution paths. Experiments on OSWorld-MCP show that ToolCUA achieves 46.85% accuracy, a relative improvement of approximately 66% over the baseline, establishing a new state of the art among models of comparable scale. It also improves by 3.9% over GUI-only settings, demonstrating effective GUI-Tool orchestration. The results further suggest that training in a hybrid action space is a promising paradigm for real-world digital agents. Open-sourced here: https://x-plug.github.io/ToolCUA/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
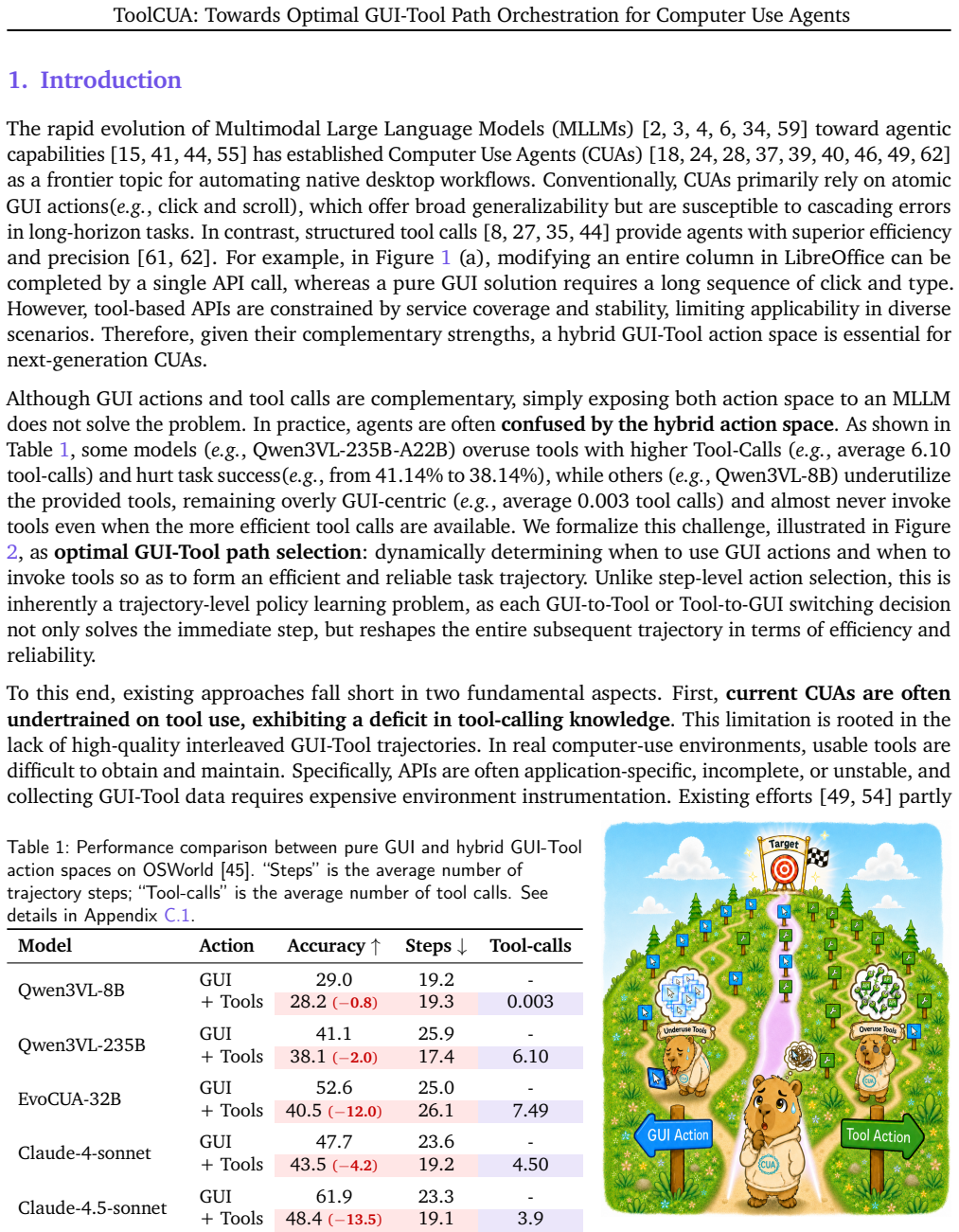
Summary. The paper proposes ToolCUA, an end-to-end Computer Use Agent for optimal orchestration between atomic GUI actions and high-level tool calls. It introduces an Interleaved GUI-Tool Trajectory Scaling Pipeline that repurposes static GUI trajectories and synthesizes a tool library to generate diverse interleaved trajectories, followed by a staged training process consisting of warmup SFT, Tool-Bootstrapped GUI RFT, and Online Agentic RL guided by a Tool-Efficient Path Reward that penalizes inefficient paths. On the OSWorld-MCP benchmark, ToolCUA reports 46.85% accuracy (approximately 66% relative improvement over baseline and +3.9% over GUI-only), claiming a new SOTA among models of comparable scale and demonstrating the benefits of hybrid action spaces.
Significance. If the synthetic trajectories match real task distributions, the work provides a practical, scalable approach to training hybrid GUI-tool agents without expensive real tool-trajectory collection and shows that staged RL with path-efficiency rewards can improve switching decisions. The open-sourcing of the model and pipeline is a positive contribution for reproducibility in the CUA field.
major comments (3)
- [§3] §3 (Interleaved GUI-Tool Trajectory Scaling Pipeline): The pipeline is load-bearing for all transfer and SOTA claims, yet the manuscript provides no quantitative distributional validation (e.g., KS tests, EMD on action histograms, switching-point statistics, or tool-call frequency comparisons) against held-out real user trajectories. Without such checks, it remains possible that reported gains optimize for synthesis artifacts rather than genuine GUI-tool orchestration.
- [§4] §4 (Experiments and OSWorld-MCP results): The headline numbers (46.85% accuracy, ~66% relative gain, +3.9% over GUI-only) are presented without ablations isolating the contribution of each training stage, without error bars or statistical significance, and without explicit confirmation that baselines use identical model scale and evaluation protocol. These omissions make it difficult to attribute gains specifically to the proposed orchestration method.
- [§4.2–4.3] §4.2–4.3 (Tool-Bootstrapped GUI RFT and Online Agentic RL): The Tool-Efficient Path Reward is defined externally in terms of tool usage and path length; the paper does not show that this reward correlates with human-judged task success or that the learned policy generalizes beyond the synthetic distribution, which is required to support the claim of “optimal GUI-Tool path selection.”
minor comments (2)
- [Abstract] Abstract: The exact baseline accuracy used for the “approximately 66%” relative improvement is not stated, forcing readers to consult tables to verify the claim.
- [§3.1] Notation and reproducibility: The precise mathematical form of the Tool-Efficient Path Reward and the details of the tool-library synthesis procedure should be given as numbered equations or pseudocode in the main text rather than only in appendices.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We value the constructive criticism and have prepared detailed responses to each major comment. We believe the revisions outlined will address the concerns and improve the clarity and rigor of the manuscript.
read point-by-point responses
-
Referee: [§3] The pipeline is load-bearing for all transfer and SOTA claims, yet the manuscript provides no quantitative distributional validation (e.g., KS tests, EMD on action histograms, switching-point statistics, or tool-call frequency comparisons) against held-out real user trajectories. Without such checks, it remains possible that reported gains optimize for synthesis artifacts rather than genuine GUI-tool orchestration.
Authors: We agree that providing quantitative validation of the synthetic trajectories against real distributions would strengthen the claims. Although the original manuscript focused on end-to-end performance on the real OSWorld-MCP benchmark to demonstrate transfer, we will revise §3 to include distributional analyses. Specifically, we will report Kolmogorov-Smirnov tests, Earth Mover's Distance on action histograms, switching-point statistics, and tool-call frequency comparisons using held-out real trajectories. This addition will help confirm that the Interleaved GUI-Tool Trajectory Scaling Pipeline generates data aligned with real user behaviors. revision: yes
-
Referee: [§4] The headline numbers (46.85% accuracy, ~66% relative gain, +3.9% over GUI-only) are presented without ablations isolating the contribution of each training stage, without error bars or statistical significance, and without explicit confirmation that baselines use identical model scale and evaluation protocol. These omissions make it difficult to attribute gains specifically to the proposed orchestration method.
Authors: We acknowledge these omissions in the experimental presentation. In the revised version, we will expand §4 with detailed ablations for each component of the staged training (warmup SFT, Tool-Bootstrapped GUI RFT, and Online Agentic RL). We will also include error bars from multiple evaluation runs, report p-values for statistical significance, and explicitly confirm that all compared baselines were run with identical model scales and under the same evaluation protocol on OSWorld-MCP. These changes will better isolate the contributions of our orchestration approach. revision: yes
-
Referee: [§4.2–4.3] The Tool-Efficient Path Reward is defined externally in terms of tool usage and path length; the paper does not show that this reward correlates with human-judged task success or that the learned policy generalizes beyond the synthetic distribution, which is required to support the claim of “optimal GUI-Tool path selection.”
Authors: The Tool-Efficient Path Reward combines task success signals with penalties for inefficient tool usage and longer paths, and is applied during online RL in a high-fidelity environment that mirrors real GUI-Tool interactions. While we did not include a separate human correlation study, the final evaluation on the real-world OSWorld-MCP benchmark demonstrates generalization beyond synthetic data, with improvements over GUI-only baselines indicating effective path selection. To further address this, we will add in the revision a discussion of how the reward design aligns with task success and include additional experiments on held-out real tasks to show generalization. We maintain that the SOTA results support the optimality claims. revision: partial
Circularity Check
No circularity: empirical pipeline with external benchmark evaluation.
full rationale
The paper's chain consists of (1) a data-generation pipeline that repurposes static GUI trajectories to synthesize interleaved GUI-Tool data, (2) staged training (SFT + single-turn RL + online agentic RL) using an externally defined Tool-Efficient Path Reward based on tool usage and path length, and (3) direct measurement of accuracy on the held-out OSWorld-MCP benchmark. None of these steps reduce by construction to their inputs; the synthesis is a standard augmentation method, the reward is not fitted from model outputs, and the headline numbers are empirical results rather than self-predictions or self-citations. No uniqueness theorems, ansatzes smuggled via prior work, or renaming of known results appear in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Saaket Agashe, Kyle Wong, Vincent Tu, Jiachen Yang, Ang Li, and Xin Eric Wang. Agent s2: A compo- sitional generalist-specialist framework for computer use agents.arXiv preprint arXiv:2504.00906, 2025
-
[2]
Anthropic. Claude opus 4.5, 2026. URL https://www.anthropic.com/news/ claude-opus-4-5. Accessed: 2026-04-20
work page 2026
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report, 2025.URL https://arxiv. org/abs/2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, et al. Windows agent arena: Evaluating multi-modal os agents at scale.arXiv preprint arXiv:2409.08264, 2024
-
[6]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
work page 2024
-
[7]
Tool-star: Empowering llm-brained multi-tool reasoner via reinforcement learning
Guanting Dong, Yifei Chen, Xiaoxi Li, Jiajie Jin, Hongjin Qian, Yutao Zhu, Hangyu Mao, Guorui Zhou, Zhicheng Dou, and Ji-Rong Wen. Tool-star: Empowering llm-brained multi-tool reasoner via reinforcement learning.arXiv preprint arXiv:2505.16410, 2025
-
[8]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. Retool: Reinforcement learning for strategic tool use in llms.arXiv preprint arXiv:2504.11536, 2025
work page internal anchor Pith review arXiv 2025
-
[9]
Gonzalo Gonzalez-Pumariega, Vincent Tu, Chih-Lun Lee, Jiachen Yang, Ang Li, and Xin Eric Wang. The unreasonable effectiveness of scaling agents for computer use.arXiv preprint arXiv:2510.02250, 2025
-
[10]
Gemini: The most capable and general model we’ve built, 2026
Google DeepMind. Gemini: The most capable and general model we’ve built, 2026. URLhttps: //deepmind.google/models/gemini/pro/. Accessed: 2026-04-28
work page 2026
-
[11]
Deepeyesv2: Toward agentic multimodal model
Jack Hong, Chenxiao Zhao, ChengLin Zhu, Weiheng Lu, Guohai Xu, and Xing Yu. Deepeyesv2: Toward agentic multimodal model.arXiv preprint arXiv:2511.05271, 2025
-
[12]
Hongrui Jia, Jitong Liao, Xi Zhang, Haiyang Xu, Tianbao Xie, Chaoya Jiang, Ming Yan, Si Liu, Wei Ye, and Fei Huang. Osworld-mcp: Benchmarking mcp tool invocation in computer-use agents.arXiv preprint arXiv:2510.24563, 2025
-
[13]
Xiangru Jian, Shravan Nayak, Kevin Qinghong Lin, Aarash Feizi, Kaixin Li, Patrice Bechard, Spandana Gella, and Sai Rajeswar. Cua-suite: Massive human-annotated video demonstrations for computer-use agents.arXiv preprint arXiv:2603.24440, 2026
-
[14]
Pengxiang Li, Zechen Hu, Zirui Shang, Jingrong Wu, Yang Liu, Hui Liu, Zhi Gao, Chenrui Shi, Bofei Zhang, Zihao Zhang, et al. Efficient multi-turn rl for gui agents via decoupled training and adaptive data curation.arXiv preprint arXiv:2509.23866, 2025. 12 ToolCUA: Towards Optimal GUI-Tool Path Orchestration for Computer Use Agents
-
[15]
Shilong Li, Xingyuan Bu, Wenjie Wang, Jiaheng Liu, Jun Dong, Haoyang He, Hao Lu, Haozhe Zhang, ChenchenJing, ZhenLi, etal. Mm-browsecomp: Acomprehensivebenchmarkformultimodalbrowsing agents.arXiv preprint arXiv:2508.13186, 2025
-
[16]
Haowei Liu, Xi Zhang, Haiyang Xu, Yuyang Wanyan, Junyang Wang, Ming Yan, Ji Zhang, Chunfeng Yuan,ChangshengXu,WeimingHu,etal. Pc-agent: Ahierarchicalmulti-agentcollaborationframework for complex task automation on pc.arXiv preprint arXiv:2502.14282, 2025
-
[17]
Autoglm: Autonomous foundation agents for guis.arXiv preprint arXiv:2411.00820, 2024
Xiao Liu, Bo Qin, Dongzhu Liang, Guang Dong, Hanyu Lai, Hanchen Zhang, Hanlin Zhao, Iat Long Iong, Jiadai Sun, Jiaqi Wang, et al. Autoglm: Autonomous foundation agents for guis.arXiv preprint arXiv:2411.00820, 2024
-
[18]
ZhaoyangLiu,JingJingXie,ZichenDing,ZehaoLi,BowenYang,ZhenyuWu,XuehuiWang,QiushiSun, Shi Liu, Weiyun Wang, et al. Scalecua: Scaling open-source computer use agents with cross-platform data.arXiv preprint arXiv:2509.15221, 2025
-
[19]
Visual-RFT: Visual Reinforcement Fine-Tuning
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual-rft: Visual reinforcement fine-tuning.arXiv preprint arXiv:2503.01785, 2025
work page internal anchor Pith review arXiv 2025
-
[20]
Fanbin Lu, Zhisheng Zhong, Shu Liu, Chi-Wing Fu, and Jiaya Jia. Arpo: End-to-end policy optimization for gui agents with experience replay.arXiv preprint arXiv:2505.16282, 2025
-
[21]
Zhengxi Lu, Yuxiang Chai, Yaxuan Guo, Xi Yin, Liang Liu, Hao Wang, Guanjing Xiong, and Hongsheng Li. Ui-r1: Enhancing action prediction of gui agents by reinforcement learning.arXiv preprint arXiv:2503.21620, 1(2):3, 2025
-
[22]
Run Luo, Lu Wang, Wanwei He, Longze Chen, Jiaming Li, and Xiaobo Xia. Gui-r1: A generalist r1-style vision-language action model for gui agents.arXiv preprint arXiv:2504.10458, 2025
-
[23]
Gui-360: A comprehensive dataset and benchmark for computer- using agents.To appear, 2025
Jian Mu, Chaoyun Zhang, Chiming Ni, Lu Wang, Bo Qiao, Kartik Mathur, Qianhui Wu, Yuhang Xie, Xiaojun Ma, Mengyu Zhou, et al. Gui-360: A comprehensive dataset and benchmark for computer- using agents.To appear, 2025
work page 2025
-
[24]
OpenAI. Introducing operator, 2026. URL https://openai.com/index/ introducing-operator/. Accessed: 2026-04-20
work page 2026
-
[25]
OpenClaw. Openclaw, 2026. URLhttps://github.com/openclaw/openclaw. Accessed: 2026- 04-20
work page 2026
-
[26]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis, 2023.URL https://arxiv. org/abs/2305.15334, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. Ui-tars: Pioneering automated gui interaction with native agents. arXiv preprint arXiv:2501.12326, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URLhttps://qwen. ai/blog?id=qwen3.5. 13 ToolCUA: Towards Optimal GUI-Tool Path Orchestration for Computer Use Agents
work page 2026
-
[30]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
CoAct-1: Computer-using agents with coding as actions.arXiv preprint arXiv:2508.03923, 2025
Linxin Song, Yutong Dai, Viraj Prabhu, Jieyu Zhang, Taiwei Shi, Li Li, Junnan Li, Silvio Savarese, Zeyuan Chen, Jieyu Zhao, et al. Coact-1: Computer-using agents with coding as actions.arXiv preprint arXiv:2508.03923, 2025
-
[33]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, et al. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers.arXiv preprint arXiv:2506.23918, 2025
work page internal anchor Pith review arXiv 2025
-
[34]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Tongyi deepresearch technical report.arXiv preprint arXiv:2510.24701, 2025
Tongyi DeepResearch Team, Baixuan Li, Bo Zhang, Dingchu Zhang, Fei Huang, Guangyu Li, Guoxin Chen, Huifeng Yin, Jialong Wu, Jingren Zhou, et al. Tongyi deepresearch technical report.arXiv preprint arXiv:2510.24701, 2025
-
[36]
AdaTooler-V: Adaptive Tool-Use for Images and Videos
Chaoyang Wang, Kaituo Feng, Dongyang Chen, Zhongyu Wang, Zhixun Li, Sicheng Gao, Meng Meng, Xu Zhou, Manyuan Zhang, Yuzhang Shang, et al. Adatooler-v: Adaptive tool-use for images and videos.arXiv preprint arXiv:2512.16918, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxiang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, et al. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning.arXiv preprint arXiv:2509.02544, 2025
work page internal anchor Pith review arXiv 2025
-
[38]
Acting less is reasoning more! teaching model to act efficiently, 2025
Hongru Wang, Cheng Qian, Wanjun Zhong, Xiusi Chen, Jiahao Qiu, Shijue Huang, Bowen Jin, Mengdi Wang, Kam-Fai Wong, and Heng Ji. Acting less is reasoning more! teaching model to act efficiently. arXiv preprint arXiv:2504.14870, 2025
-
[39]
Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent-v2: Mobile device operation assistant with effective navigation via multi-agent collaboration.arXiv preprint arXiv:2406.01014, 2024
-
[40]
Opencua: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025
Xinyuan Wang, Bowen Wang, Dunjie Lu, Junlin Yang, Tianbao Xie, Junli Wang, Jiaqi Deng, Xiaole Guo, Yiheng Xu, Chen Henry Wu, et al. Opencua: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025
-
[41]
OpenClaw-RL: Train Any Agent Simply by Talking
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang. Openclaw-rl: Train any agent simply by talking.arXiv preprint arXiv:2603.10165, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Yinjie Wang, Tianbao Xie, Ke Shen, Mengdi Wang, and Ling Yang. Rlanything: Forge environment, policy, and reward model in completely dynamic rl system.arXiv preprint arXiv:2602.02488, 2026
-
[43]
Zhenhailong Wang, Haiyang Xu, Junyang Wang, Xi Zhang, Ming Yan, Ji Zhang, Fei Huang, and Heng Ji. Mobile-agent-e: Self-evolving mobile assistant for complex tasks.arXiv preprint arXiv:2501.11733, 2025. 14 ToolCUA: Towards Optimal GUI-Tool Path Orchestration for Computer Use Agents
-
[44]
Agentic-MME: What Agentic Capability Really Brings to Multimodal Intelligence?
Qianshan Wei, Yishan Yang, Siyi Wang, Jinglin Chen, Binyu Wang, Jiaming Wang, Shuang Chen, ZechenLi, YangShi, YuqiTang, etal. Agentic-mme: Whatagenticcapabilityreallybringstomultimodal intelligence?arXiv preprint arXiv:2604.03016, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
work page 2024
-
[46]
Haiyang Xu, Xi Zhang, Haowei Liu, Junyang Wang, Zhaozai Zhu, Shengjie Zhou, Xuhao Hu, Feiyu Gao, Junjie Cao, Zihua Wang, et al. Mobile-agent-v3. 5: Multi-platform fundamental gui agents.arXiv preprint arXiv:2602.16855, 2026
-
[47]
Mobilerl: Online agentic reinforcement learning for mobile gui agents
Yifan Xu, Xiao Liu, Xinghan Liu, Jiaqi Fu, Hanchen Zhang, Bohao Jing, Shudan Zhang, Yuting Wang, Wenyi Zhao, and Yuxiao Dong. Mobilerl: Online agentic reinforcement learning for mobile gui agents. arXiv preprint arXiv:2509.18119, 2025
-
[48]
Taofeng Xue, Chong Peng, Mianqiu Huang, Linsen Guo, Tiancheng Han, Haozhe Wang, Jianing Wang, Xiaocheng Zhang, Xin Yang, Dengchang Zhao, et al. Evocua: Evolving computer use agents via learning from scalable synthetic experience.arXiv preprint arXiv:2601.15876, 2026
-
[49]
Step-gui technical report.arXiv preprint arXiv:2512.15431, 2025
Haolong Yan, Jia Wang, Xin Huang, Yeqing Shen, Ziyang Meng, Zhimin Fan, Kaijun Tan, Jin Gao, Lieyu Shi, Mi Yang, et al. Step-gui technical report.arXiv preprint arXiv:2512.15431, 2025
-
[50]
Yunhe Yan, Shihe Wang, Jiajun Du, Yexuan Yang, Yuxuan Shan, Qichen Qiu, Xianqing Jia, Xinge Wang, Xin Yuan, Xu Han, et al. Mcpworld: A unified benchmarking testbed for api, gui, and hybrid computer use agents.arXiv preprint arXiv:2506.07672, 2025
-
[51]
Bowen Yang, Kaiming Jin, Zhenyu Wu, Zhaoyang Liu, Qiushi Sun, Zehao Li, JingJing Xie, Zhoumianze Liu, Fangzhi Xu, Kanzhi Cheng, et al. Os-symphony: A holistic framework for robust and generalist computer-using agent.arXiv preprint arXiv:2601.07779, 2026
-
[52]
Zerogui: Automating online gui learning at zero human cost.arXiv preprint arXiv:2505.23762, 2025
Chenyu Yang, Shiqian Su, Shi Liu, Xuan Dong, Yue Yu, Weijie Su, Xuehui Wang, Zhaoyang Liu, Jinguo Zhu, Hao Li, et al. Zerogui: Automating online gui learning at zero human cost.arXiv preprint arXiv:2505.23762, 2025
-
[53]
Yan Yang, Dongxu Li, Yutong Dai, Yuhao Yang, Ziyang Luo, Zirui Zhao, Zhiyuan Hu, Junzhe Huang, Amrita Saha, Zeyuan Chen, et al. Gta1: Gui test-time scaling agent.arXiv preprint arXiv:2507.05791, 2025
-
[54]
Yuhao Yang, Zhen Yang, Zi-Yi Dou, Anh Nguyen, Keen You, Omar Attia, Andrew Szot, Michael Feng, Ram Ramrakhya, Alexander Toshev, et al. Ultracua: A foundation model for computer use agents with hybrid action.arXiv preprint arXiv:2510.17790, 2025
-
[55]
Claw-Eval: Towards Trustworthy Evaluation of Autonomous Agents
Bowen Ye, Rang Li, Qibin Yang, Yuanxin Liu, Linli Yao, Hanglong Lv, Zhihui Xie, Chenxin An, Lei Li, Lingpeng Kong, et al. Claw-eval: Toward trustworthy evaluation of autonomous agents.arXiv preprint arXiv:2604.06132, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
Mobile-agent-v3: Fundamental agents for gui automation.arXiv preprint arXiv:2508.15144, 2025
Jiabo Ye, Xi Zhang, Haiyang Xu, Haowei Liu, Junyang Wang, Zhaoqing Zhu, Ziwei Zheng, Feiyu Gao, Junjie Cao, Zhengxi Lu, et al. Mobile-agent-v3: Fundamental agents for gui automation.arXiv preprint arXiv:2508.15144, 2025. 15 ToolCUA: Towards Optimal GUI-Tool Path Orchestration for Computer Use Agents
-
[57]
Agentfold: Long-horizon web agents with proactive context management.CoRR, abs/2510.24699, 2025
Rui Ye, Zhongwang Zhang, Kuan Li, Huifeng Yin, Zhengwei Tao, Yida Zhao, Liangcai Su, Liwen Zhang, Zile Qiao, Xinyu Wang, et al. Agentfold: Long-horizon web agents with proactive context management.arXiv preprint arXiv:2510.24699, 2025
-
[58]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
Tongui: Internet-scale trajectories from multimodal web tutorials for generalized gui agents
Bofei Zhang, Zirui Shang, Zhi Gao, Wang Zhang, Rui Xie, Xiaojian Ma, Tao Yuan, Xinxiao Wu, Song-Chun Zhu, and Qing Li. Tongui: Internet-scale trajectories from multimodal web tutorials for generalized gui agents. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 12367–12375, 2026
work page 2026
-
[61]
Chaoyun Zhang, Shilin He, Liqun Li, Si Qin, Yu Kang, Qingwei Lin, Saravan Rajmohan, and Dongmei Zhang. Api agents vs. gui agents: Divergence and convergence.arXiv preprint arXiv:2503.11069, 2025
-
[62]
Ufo3: Weaving the digital agent galaxy.arXiv preprint arXiv:2511.11332, 2025
Chaoyun Zhang, Liqun Li, He Huang, Chiming Ni, Bo Qiao, Si Qin, Yu Kang, Minghua Ma, Qingwei Lin, Saravan Rajmohan, et al. Ufo3: Weaving the digital agent galaxy.arXiv preprint arXiv:2511.11332, 2025
-
[63]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing" thinking with images" via reinforcement learning.arXiv preprint arXiv:2505.14362, 2025. 16 ToolCUA: Towards Optimal GUI-Tool Path Orchestration for Computer Use Agents Appendix A. Limitations and Future Works Although ToolCUA demonstra...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Which application, window, or web page is visible
-
[65]
The main interactive UI elements that are visible, such as buttons, menus, tabs, tables, forms, inputs, dialogs, or side panels
-
[66]
Do not invent details that are not visible in the screenshot
The primary content currently shown on screen Write 2-4 sentences. Do not invent details that are not visible in the screenshot. Return plain text only, not JSON. JOINT GENERATION PROMPT ## Role You are a trajectory generator, not a real agent. You must simulate how a smart and efficient agent would complete exactly the current step of a computer-using ta...
- [67]
-
[68]
Do not call wait-like tools more than once in a row
-
[69]
Do not call wait-like tools unless there is a clear error condition
-
[70]
Every step must make progress toward the task goal
-
[71]
Do not wait for loading unless the state explicitly requires it
Assume the network, application, and desktop environment are functioning normally. Do not wait for loading unless the state explicitly requires it
-
[72]
Choose only a tool action that can plausibly move the current state to a later real state in the recorded trajectory
-
[73]
Do not call terminate unless the task has already reached the final recorded state. ## Task goal {goal} ## Trajectory history {history} ## Current screenshot description {screenshot_description} ## Current virtual world state {world_state} ## Available tools for this task {tools} Generate the complete output for the current step, including:
-
[74]
Tool Response ## Rules for generating the Step - The observation should reflect the current screenshot description, especial attention to important region. - Thougt must demonstrate the agent's real thinking progress advancing the task given current step. - Action must be a natural-language description of the intended tool call action, it should be a simp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.